
地面无人平台视觉导航定位技术研究
2019-07-11 04:59付梦印宋文杰王美玲
导航定位与授时 2019年4期
付梦印,宋文杰,杨 毅,王美玲
(1.北京理工大学,北京 100081; 2.南京理工大学,南京 210094)
0 引言
地面无人平台(Unmanned Ground Vehicle, UGV)是一个集环境感知、规划决策、多等级辅助驾驶等功能于一体的综合系统,其具备的自动驾驶功能能够实现车辆在结构化道路、非结构化道路、非道路区域下连续、实时地自动驾驶。自20世纪80年代开始,以美国国防部高级研究规划局举办的地面无人系统挑战赛为标志,地面无人平台相关技术取得了较大的研究进展[1-3]。而我国近些年来连续举办的多届中国智能车未来挑战赛和跨越险阻陆上无人系统挑战赛也极大地推动了国内地面无人平台技术的发展[4-5]。虽然相关技术经过了近10年的高速发展,但在复杂的交通场景下实现完全的自动驾驶仍面临着多项重大挑战。其一,复杂多变的动态随机场景要求地面无人平台具有更高水平的自主学习能力;其二,多种类、长时间、高标准的任务需求要求地面无人平台能够更加准确地获得复杂环境中多类信息并实现自身的精确定位;其三,大范围、高密度的使用频率要求地面无人平台拥有低成本、高可靠性的传感器来辅助其实现相应功能。机器视觉作为环境感知的重要技术手段,在信息丰富度和环境适应性上具有较大优势,是目前地面无人平台实现自主导航与实时定位的重要研究方向。以机器视觉为基础,加州大学伯克利分校、德国戴姆勒研发中心、芝加哥大学丰田技术研究院等顶级研究机构分别发布BAIR[6]、Cityscape[7]、KITTI[8]等数据集,是目前地面无人平台领域权威的算法开发及性能评测工具。Andreas Geiger[9]、Hermann Winner[10]、Reinhard Klette[11]、Stefan Milz[12]等机器视觉专家根据多类数据集对地面无人平台自主导航及定位技术的最新研究进展进行了详细对比分析,对本领域研究工作具有一定的指导意义和参考价值。
典型的地面无人平台视觉定位与地图构建系统架构如图 1所示,主要包括图像信息预处理、视觉里程计、回环检测、全局位姿优化和地图构建等5个基本模块,各模块的实现手段则包括了多类关键技术。本文主要以该系统架构为基础,针对各模块所涉及的关键技术,总结了近些年来国内外主流的研究成果,对比分析了各关键技术中主流方法的性能,并对地面无人平台视觉导航及定位技术的发展方向进行了展望。
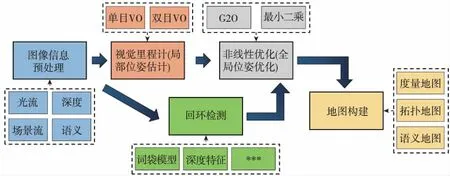
图1 视觉定位与地图构建系统框图Fig.1 Block diagram of vision-based positioning and mapping system
1 图像信息预处理
地面无人平台常用的视觉传感器主要包括单目相机、双目或多目相机、全景相机、深度相机等。在这些传感器原始数据的基础上,研究人员通常通过不同的处理方法,提取光流、深度、场景流、语义等元素信息,以辅助地面无人平台进行自主导航与定位。
1.1 光流计算
光流(Optical Flow, OF)是在图像坐标系下表征2幅图像之间亮度模式二维运动的一种矢量簇,可以为场景理解、姿态估计、目标跟踪等任务提供重要信息。该问题的研究始于几十年前,Horn和Schunck[13]在假设一段时间内一个像素的亮度是恒定的前提下,首先利用变分公式计算获得了光流信息。目前常见的光流场计算方法主要是在亮度恒定、小运动、空间一致等约束条件下实现的,一般分为基于梯度、基于匹配、基于能量、基于相位、基于神经动力学、基于深度神经网络等机器学习方法六类[14]。而光流的使用形式主要有稀疏光流和稠密光流两种,其中稀疏光流仅包含主要特征点的运动矢量信息,而稠密光流则包含了每个像素的运动矢量信息,如图 2所示。

(a)稀疏光流

(b)稠密光流图2 稀疏光流与稠密光流计算结果[15]Fig.2 Calculation results of sparse and dense optical flow
KITTI[7]作为目前地面无人平台研究中最为流行的测评数据集,对目前自动驾驶功能中稠密光流的计算方法进行了定量对比和排名。本文以KITTI2015数据集提供的光流计算方法排名为准,列出了目前主流方法的性能对比情况,如表1所示。其中,各方法的表现性能主要使用车辆运动过程中背景信息平均光流离异值(Outliers)百分比(Fl-bg)、前景信息平均光流离异值百分比(Fl-fg)、全部像素平均光流离异值百分比(Fl-all)、计算时间(Runtime)和计算平台(Environment)进行表述。
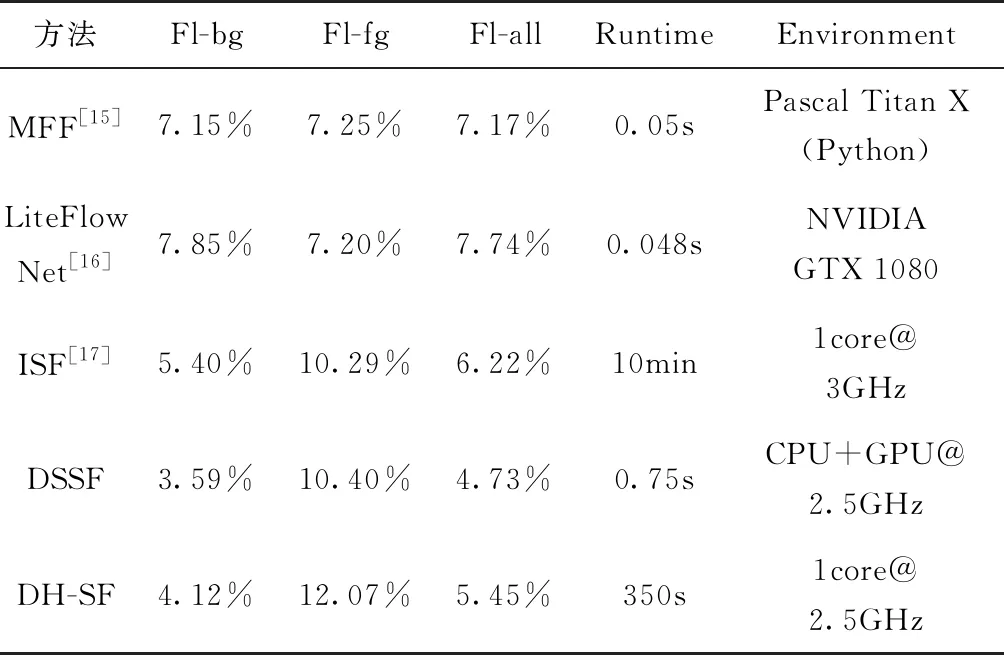
表1 目前主流的稠密光流计算方法对比
1.2 图像深度信息估计
图像深度信息通常可以通过两种方式获得:利用Kinect、Realsense等深度相机直接获取[18-19]和通过立体匹配或其他深度估计方法获得视差图或深度图[20-26],如图 3所示。然而,深度相机由于探测距离近(3~5m)且在户外易受干扰,并不适用于地面无人系统。因此,目前研究人员主要采用第二种方式获得城市交通场景的实时深度信息。传统立体匹配算法主要分为基于区域的立体匹配[20]、基于特征的立体匹配[21]和基于相位的立体匹配[22]等。其中,基于区域匹配的SGM[23]是目前应用于户外环境中最受研究者青睐的立体匹配算法。基于该算法,越来越多更为有效的立体匹配方法也被相继提出,例如iSGM[24]、SORT-SGM[25]、rSGM[26]等。近些年,随着深度学习技术的广泛应用,越来越多的研究者开始利用双目图像[27-28]或者甚至仅利用单目图像[29]作为深度卷积神经网络的输入进行训练,直接获得更为精确的稠密视差图。本文以KITTI2015数据集提供的视差图和深度图估计方法的排名为基础,列出了目前主流方法的性能对比情况,如表2所示。其中,各方法的表现性能主要使用车辆运动过程中背景信息平均视差离异值(Outliers)百分比(D1-bg)、前景信息平均视差离异值百分比(Dl-fg)、全部像素平均视差离异值百分比(Dl-all)、计算时间(Runtime)和计算平台(Environment)进行表述。

(a)视差图估计

(b)深度图估计图3 图像深度信息估计[27]Fig.3 Image depth information estimation
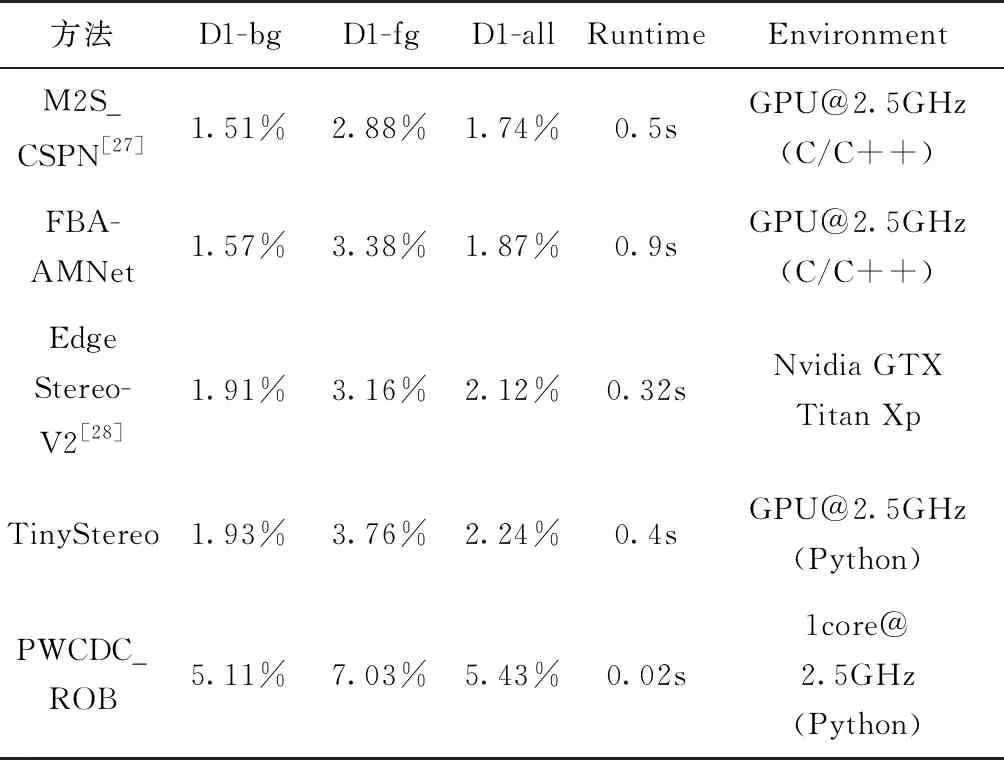
方法D1-bgD1-fgD1-allRuntimeEnvironmentM2S_CSPN[27]1.51%2.88%1.74%0.5sGPU@2.5GHz(C/C++)FBA-AMNet1.57%3.38%1.87%0.9sGPU@2.5GHz(C/C++)EdgeStereo-V2[28]1.91%3.16%2.12%0.32sNvidia GTX Titan XpTinyStereo1.93%3.76%2.24%0.4sGPU@2.5GHz(Python)PWCDC_ROB5.11%7.03%5.43%0.02s1core@2.5GHz(Python)
1.3 图像场景流提取
场景流(Scene Flow,SF)是场景的密集或半密集3D运动场,用于表征场景中三维物体相对于相机的运动情况,可以用于周围物体的运动预测,或是改进已有的视觉预测与即时定位与地图构建(Simultaneous Localization and Mapping,SLAM)算法。双目或多目相机立体匹配虽然可以获得当前帧图像的深度信息,却无法表达任何运动信息。而单目相机通过前后帧匹配虽然可以获得光流等运动特征,但由于缺少深度信息,仍无法较好地解析出连续图像帧的场景流特征。在地面无人平台自主导航过程中,实现三维世界内运动物体的分割及运动场景解析对于规划、决策与控制等模块均具有重要作用。场景流主要是将光流信息推广到三维空间,或将稠密深度信息推广到时间维度上。因此,场景流是建立在三维物理世界和时间维相结合的四维空间内。其目标是在给定连续图像序列的基础上,通过空间维度和时间维度的稠密匹配估计三维运动场,即场景中每个可见表面上每一点的三维运动向量,所得场景流效果图如图4所示[30]。基于图像场景流估计的最小系统是由2个连续立体图像对搭建的,如图5所示[31]。以KITTI2015数据集提供的场景流计算方法排名为准,列出了目前主流方法的性能对比情况,如表3所示。其中,各方法的表现性能主要使用车辆运动过程中背景信息平均场景流离异值(Outliers)百分比(SF-bg)、前景信息平均场景流离异值百分比(SF-fg)、全部像素平均场景流离异值百分比(SF-all)、计算时间(Runtime)和计算平台(Environment)进行表述。

图4 连续立体图像帧估计场景流[30]Fig.4 Scene flow estimation by continuous stereo images
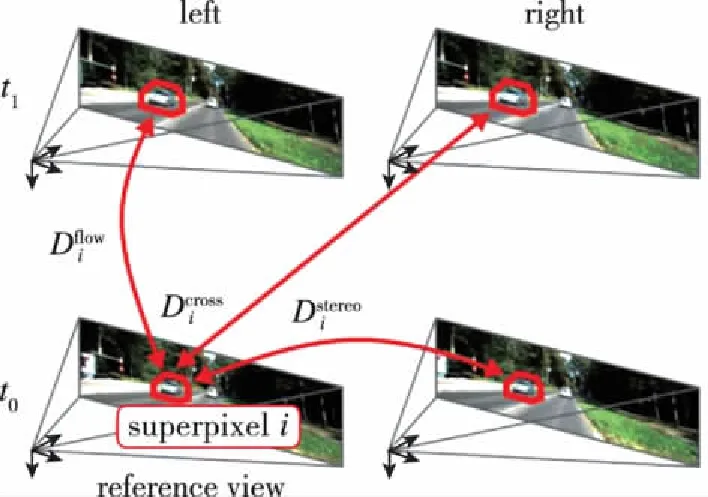
图5 双目相机场景流估计最小系统[31]Fig.5 Minimal setup for image-based scene flow estimation
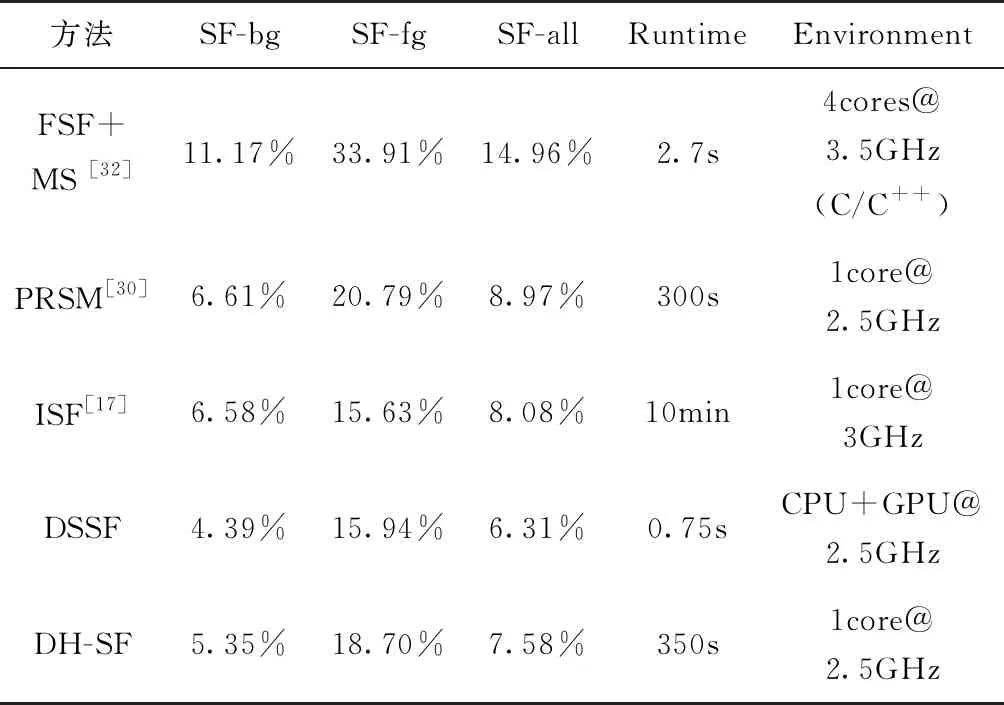
方法SF-bgSF-fgSF-allRuntimeEnvironmentFSF+MS [32]11.17%33.91%14.96%2.7s4cores@3.5GHz(C/C++)PRSM[30]6.61%20.79%8.97%300s1core@2.5GHzISF[17]6.58%15.63%8.08%10min1core@3GHzDSSF4.39%15.94%6.31%0.75sCPU+GPU@2.5GHzDH-SF5.35%18.70%7.58%350s1core@2.5GHz
1.4 图像语义信息分类
图像语义分割(Semantic Segmentation)是一类能够获取图像中的每个像素所对应物体标签的像素级分割方法的统称。在深度学习出现以前,早期的图像分割方法大多仅能通过像素与像素间的关系进行不包含语义信息的二分类,例如N-Cut[33]和在此基础上发展出的包含人工干预的Grab Cut[34]等。而随着深度学习的迅速发展,全卷积神经网络[35]的出现为像素级图像语义分割(Pixel-level semantic segmentation)提供了一种全新的方法:通过将卷积神经网络(Convolutional Neural Networks,CNN)的全连接层替换为卷积层,利用反卷积方法实现了像素级的语义划分。随后,空洞卷积核[36]和条件随机场[37]方法进一步解决了原网络对细节不敏感的问题。在此基础上,实例级的语义分割(Instance-level semantic segmentation)同样在快速发展,其能够在实现像素级语义划分的基础上,进一步分割出图像中同一种类的不同物体,如图6所示。以KITTI2015数据集提供的像素级语义分割与实例级语义分割方法的排名为基础,列出了目前主流方法的性能对比情况,如表4和表5所示。其中,像素级语义分割各方法的表现性能主要使用车辆运动过程中每个类或类别重叠区域占联合区域的百分比(IoU class/category)、根据平均实例大小获得的每个类或类别的加权重叠区域占联合区域的百分比(IoU class/category)、计算时间(Runtime)和计算平台(Environment)进行表述。实例级语义分割各方法的表现性能主要使用车辆运动过程中每个类区域级别IoU的平均准确率(AP)、重叠值50%以上每个类区域级别IoU的平均准确率(AP 50%)、计算时间(Runtime)和计算平台(Environment)进行表述。

(a) 像素级语义分割

(b) 实例级语义分割图6 像素级与实例级语义分割结果[8]Fig.6 Semantic segmentation results of pixel-level and instance-level
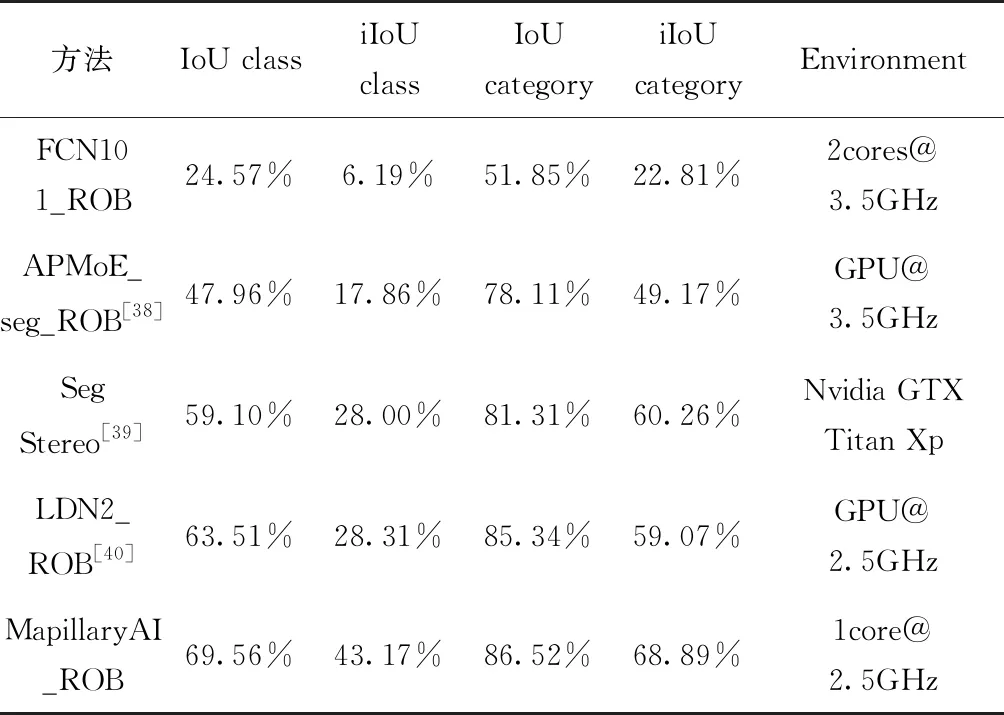
表4 目前主流的像素级语义分割方法对比
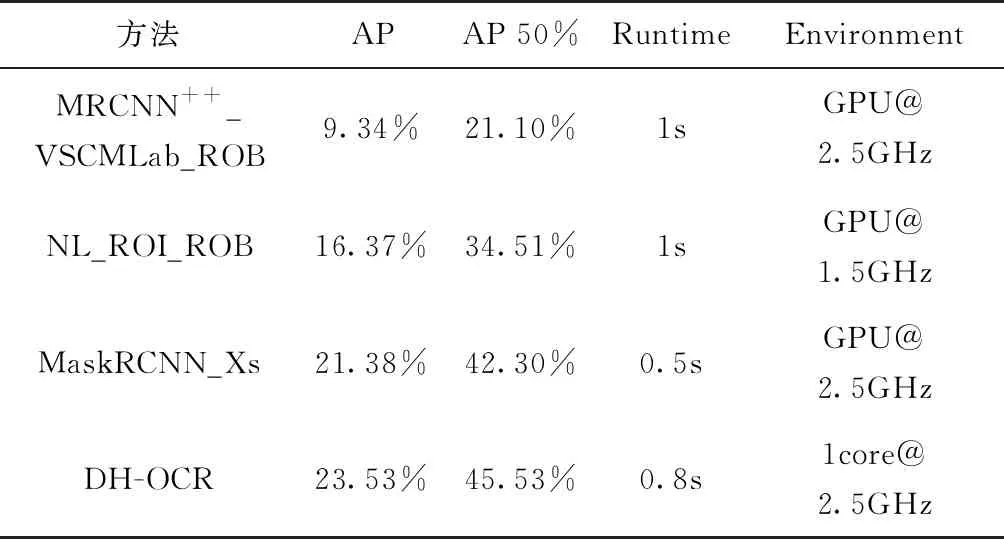
表5 目前主流的实例级语义分割方法对比
2 视觉里程计
视觉里程计(Visual Odometry,VO)是指利用连续图像计算或记录一个或多个相机运动轨迹的一种航位推算方法。该方法主要是通过估计连续图像帧的相机位置之间相对转换,并随着时间推移积累所有转换,以恢复完整的轨迹增量,其推算方式如图7所示。从计算方法的角度分析,视觉里程计一般可以分为特征匹配法和直接公式推导法。一般而言,特征匹配法通常适用于直线、角点等特征信息丰富的环境。相比而言,直接公式推导法利用了整个图像的梯度信息,因此这类方法在关键点较少的环境中可以获得较高的精度和鲁棒性。而从传感器类型的角度分析,一般可以分为单目视觉里程计和双目视觉里程计两类。
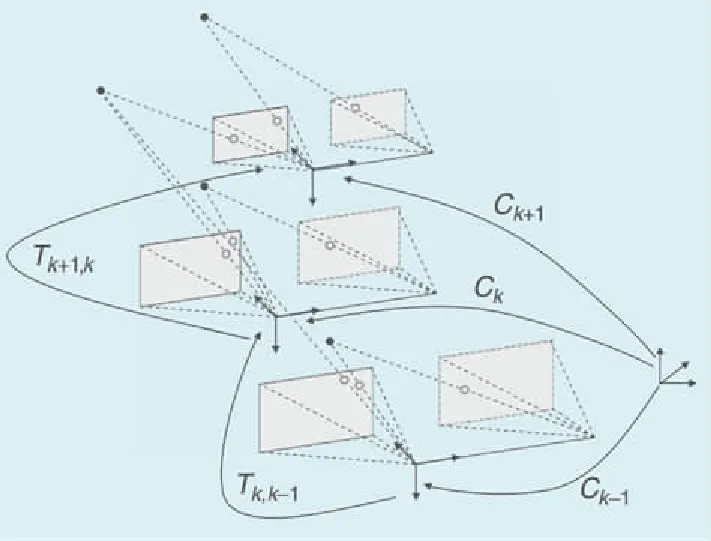
图7 视觉里程计航位推算流程[68]Fig.7 Process flow of visual odometer
2.1 单目视觉里程计
单目视觉里程计由于缺少尺度信息,通常只能恢复一个维度上的运动信息。然后,可以通过计算场景中物体的大小、根据运动约束或与其他传感器集成来确定绝对尺度。早期最为经典的单目相机运动估计方法是Longuet-Higgins提出的八点法[41],但该方法噪声较大,尤其是相机矫正不准确的情况下表现较差。Mirabdollah等利用八点法研究了基本矩阵的二阶统计量,使用泰勒二阶展开式得到协方差矩阵以及共面性方程以减少估计误差[42]。但由于缺乏深度信息,该方法的漂移问题仍然尤为突出。随后,他们又提出了一种基于迭代五点法的实时、鲁棒的单目视觉里程计方法[43]。利用概率三角形获取不确定地标的位置,并对地面上具有低质量特征的运动尺度进行估计,以获得更加准确的定位效果。基于KITTI测试集提供的单目视觉里程计方法排名为基准,本文列出了目前主流方法的性能对比情况,如表6所示。其中,Translation为各方法在三轴方向上的平均平移误差,Rotation为各方法在三轴方向上的平均旋转误差。
2.2 双目视觉里程计
相比单目视觉里程计,双目视觉里程计对于图像中像素的深度信息可以通过相机内外参数进行解算,因此不存在尺度估计的问题。同时,双目视觉里程计往往可以融合自身运动估计和地图构建来解决漂移问题。所以,目前在KITTI测试集提供的视觉里程计性能排名中,双目视觉里程计的表现普遍是优于单目视觉里程计的。本文列出了目前主流的双目视觉里程计方法的性能对比情况,如表7所示。其中,Engel等[47]提出了一种实时、大规模的直接双目视觉里程计算法,该算法将多视角立体图像与静态立体图像进行耦合,从而实现了静态立体图像下实时深度估计,避免了使用多视角立体图像造成的尺度漂移,该算法实现效果如图8所示。而ORB-SLAM2[48]则是从图像中提取ORB特征,根据历史帧进行位姿估计,然后跟踪已经重建的局部地图进行位姿优化。
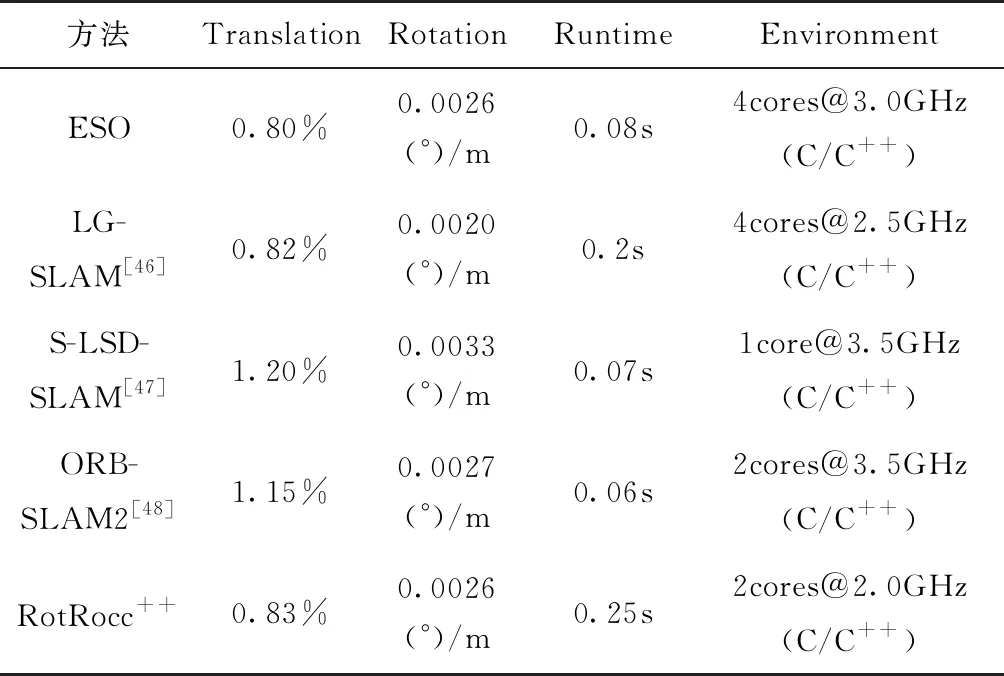
表7 目前主流的双目视觉里程计方法对比
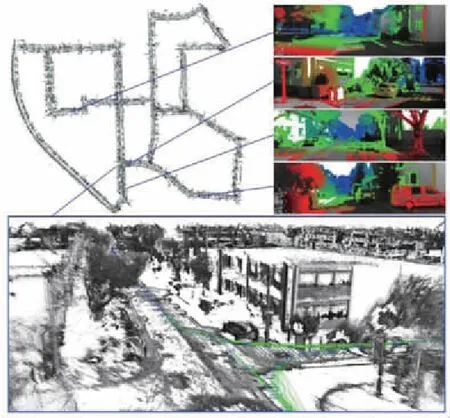
图8 LSD-SLAM双目视觉里程计位姿 估计及半稠密地图构建[47]Fig.8 Pose estimation and semi-dense map construction in LSD-SLAM
3 回环检测及全局优化
由于SLAM系统的位姿误差随着时间推移不断累积,产生漂移现象,因此需要通过回环检测模块识别出曾经到达过的场景,从而在地图中得到一个回环路径以便进行全局优化。
为了实现回环检测,通常需要通过某种方式在历史数据库中寻找与当前采集的图像相似的图像,进而求取2幅图像的相机位姿变换关系实现闭环。目前主流的回环检测方法可以大致分为基于全局特征和基于局部特征两种。其中,基于全局特征的回环检测方法通过对整幅图像或部分图像提取特征, 较典型的全局特征是GIST特征[49]。基于局部特征的回环检测方法则是提取图像中的关键点,并提取关键点的局部描述子,例如SIFT[49]、SURF[50]、FAST[51]、ORB[52]等。由于图像中的特征点数量较多,因此通常采用BoW[53]、VLAD[54]等方法对特征点进行聚类,增加存储效率和查找效率。与局部特征相比,全局特征倾向于概括整个场景的内容,对于场景的整体光照变化较鲁棒,但是对于相机视角的变化比较敏感。随着深度学习技术的发展,基于深度学习的回环检测方法也不断涌现,例如Gao X等[55]利用降噪自编码器对闭环检测采用的特征点进行无监督学习;Arandjelovic R[56]在传统VLAD算法的基础上,提出了一个新的广义VLAD层来得到特征向量,该层可以嵌入到已有的神经网络中进行训练,该方法对光照和视角变化有一定的鲁棒性;Chen Z[57]等则在已有神经网络上进行修改,使其输出多尺度视角不变的特征。
4 地图构建
地面无人平台构建的地图是对其运动过程中所感知环境模型的表征。在实际使用中,由于应用需求不同,构建的地图类型也不同,主要分为度量地图[58]、拓扑地图[59]与语义地图[60]三种。
度量地图注重精确地表示地图中环境物体的位置关系,图9所示为二维度量地图,其以占据栅格的形式表征,允许地面无人平台在所处环境中精确定位。度量地图可通过SLAM方法在线获取[61],也可通过数据采集后离线生成地图,再集成到地面无人平台的系统中。例如Google的街景项目通过采集世界各地城市的全景图像对场景进行度量地图重构[62]。

图9 二维度量地图[69]Fig.9 2D metric map
相比于度量地图的精确性,拓扑地图则以环境区域编码为节点,更强调地图元素的独立性以及元素之间的连通关系,图10所示为具有拓扑节点和弧的2D拓扑地图。拓扑地图的构建方法分为在线和离线两种途径,Vorinoi图法[63]是一种在线创建拓扑地图的方法,但该方法需要很长的计算时间。虽然拓扑地图对环境信息的表达更加紧凑,但其忽略了地图的细节,不适用于复杂结构环境下地面无人平台的导航[64]。
不同于度量地图和拓扑地图,语义地图基于环境语义信息与度量地图的融合,旨在赋予地面无人平台对周围环境的场景理解能力,可以为地面无人平台提供特定任务所需的环境信息,如图11所示的包含停车区域信息的语义地图能够辅助地面无人平台完成自主泊车功能[65]。环境语义信息可通过概率图模型来得到,如Vineet等使用条件随机场(Conditional Random Fields, CRFs),提出了一种基于Hash和CRFs的大规模语义地图创建算法[66],适用于室外大规模稠密语义地图重建。近年来研究者们开始结合深度学习方法与SLAM技术创建面向对象的语义地图,如Yang等利用CNN进行语义分割,构建了一种三维滑动语义占据栅格地图[67]。
5 结论与展望
随着计算机科学、信息科学、人工智能等技术的深入发展,地面无人平台视觉导航定位技术得到了越来越广泛的应用。通过构建不同类型的地图并实现自身的实时精确定位,地面无人平台已在边境巡逻、军事侦察、楼宇探测、灾后救援、矿井维护、室内服务等多个重要领域产生了积极影响,能够代替人类完成高温、高压、剧毒等恶劣环境下的危险工作和高密度、长周期、大流量等复杂场景下的繁琐作业。不过,由于该技术尚处于初级阶段,在实际导航定位过程中仍面临着诸多问题。第一,车载视觉信息的应用条件往往较为苛刻,在光照变化剧烈、遮挡严重、高速移动等情况下,该类信息的感知鲁棒性较低。因此,如何在算法设计上克服此类因素的影响,在硬件设计上研制一批静动态成像特性好且成本低廉的视觉传感器将是未来视觉导航定位技术的研究重点;如何将视觉感知信息与毫米波雷达、激光雷达等其他形式的车载传感器信息进行有机融合将是地面无人平台视觉导航定位技术得到有力补充的关键。第二,现有的视觉导航算法虽然可以获得较高精度的构图及定位效果,但其计算成本往往很高,大部分算法需要依赖高性能处理器甚至专用芯片。因此,如何在保证算法精度和稳定性的前提下,降低视觉导航的运算成本也是本领域接下来的一个重点研究方向。第三,目前大部分视觉导航技术只是关注全局静态地图构建与定位,对于多语义目标的动态特性考虑不足,从而导致地面无人平台在实际导航过程中对于移动障碍物的处理能力较差。因此,如何利用视觉信息实时检测、跟踪移动目标,并在此基础上对各类目标的未来运动轨迹进行精确预测将是本领域研究工作的另一个主要方向。
同时,目前主流的视觉导航算法、测评数据集和开发工具大多来自于海外院校或科研单位。近些年,我国虽然在该领域取得了较快进展,但在机理研究和平台建设方面,与国外先进水平仍存在着较大差距。因此,我国只有加强引进国外先进科技,进一步深入与国际顶级研究机构的交流与合作,才能逐步缩小与国际先进水平的差距。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
导航定位与授时(2022年4期)2022-08-05
小型微型计算机系统(2021年12期)2021-12-08
军民两用技术与产品(2021年2期)2021-04-13
导航定位与授时(2020年4期)2020-07-29
小哥白尼·趣味科学画报(2019年12期)2019-02-28
岷峨诗稿(2017年4期)2017-04-20
科学大众(中学)(2016年8期)2016-05-14
长江学术(2016年4期)2016-03-11
