
Nginx负载均衡技术的研究
2019-07-10 09:23梁剑
太原师范学院学报(自然科学版) 2019年2期
梁 剑
(太原工业学院 计算机工程系,山西 太原 030008)
随着互联网应用的发展,由多台服务器分担客户的HTTP请求已经广泛部署到现实中.但是我们很难做出一个完美方案能解决合理分配负载.一般来说,服务器的资源包括CPU、内存、硬盘IO等,如何充分利用这些资源是个难点。首先,很难根据一个URL来判断是消耗了哪种资源,比如说图片、HTML文档这样的静态内容主要消耗硬盘IO资源.如果是动态内容,可能主要消耗CPU或内存.第二,如何对后端资源进行价值度量,各种资源的值简单相加并不合理.第三,合理利用所有资源未必是最优选,比如当访问的是热数据时,结果会从缓存中取出而节约时间,任务分配不合理,可能会出现更多的锁等待时间.
1 Nginx负载均衡机制简介
Nginx是由俄罗斯人Igor Sysoev开发的一款高性能Web服务器,同时还支持反向代理和负载均衡.由于使用了epoll这样的多路复用IO技术,Nginx所消耗的资源比传统的Apache服务器要小,因此能支持更高的并发连接数,根据NETCRAFT调查,在2018年1月占有25.39%的份额,并且还在快速增长中[5].
1.1 Nginx反向代理模块
Nginx的反向代理是在ngx_http_upstream_module模块中实现的[4],配置文件如下所示:
upstream backserver {
server backend.server.com weight=5;
server 127.0.0.1:1234 weight=10;}
upstream模块可以通过proxy_pass被引用,配置如下所示:
server {
listen 8080;
proxy_pass backserver;}
1.2 Nginx的负载均衡算法
1.2.1 轮询算法
轮询(round-robin)是Nginx的默认负载均衡算法,根据请求到来的顺序,依次将任务分配给后端服务器,此算法的优点是实现简单,但是分配任务上没有任何优化,无法充分利用后端服务器资源.
1.2.2 会话保持算法
又称IP_HASH方式,采用轮询或共他负载均衡算法会造成同一用户的请求分配到不同的服务器上,这种情况下必须使用session共享技术,不同的服务器访问来自同一源的session,可使用redis等技术来实现.在Nginx中可以使用ip_hash指令配置此算法.此方法的好处是不需要解决不同服务器间的共享session问题,但其缺点是缺乏对任务分配的优化.
1.2.3 加权轮询负载均衡算法
加权轮询负载均衡(Weighted Load Balancing)是在轮询的基础上根据服务器的负载能力来调整任务分配,前面提到的两种算法中对待后端服务器是一视同仁,而现实中后端服务器的能力是有差别的.在Nginx轮询方式的配置后面加上weight命令来指定服务器的权重.此算法的优点是考虑了后端服务器能力的差异,其缺点是这种任务分配方式是静态的,无法根据实际负载动态调整.
1.2.4 最少连接数负载均衡算法
最少连接数负载均衡(Least connected load balancing)就是根据前端任务分配器与后端服务器的连接数做为分配的依据,连接数少的负荷小,连接数多的负荷大.新到的任务会分配到连接数少的服务器上.其优点是考虑了服务器的动态负荷状况,但其缺点是依赖连接数判断负荷是不够准确的,比如说连接数多并不能表明负荷重,也许是因为等待锁资源,或者是在等待其他服务器(如数据库服务器)完成任务.
2 Nginx负载均衡的研究状况
国内外负载均衡算法的研究都比较多,总体上分为静态和动态两种类型.静态类型就是不考虑后端服务器的工作状况,根据预先设定的方式分配任务,如Nginx中自带的轮询、加权轮询以及会话保护方式.动态类型是根据后端服务器的负载状况分配任务,这其中又有两种方式,一是根据连接数推测服务器的运行状况;二是根据后端服务器将自身的负荷状况反馈给任务分配器,以此信息做为任务分配依据.
在文献中提出了一种动态自适应权重轮询随机负载均衡算法,将后端服务器的CPU、内存、磁盘IO、网络使用经过加权计算得到资源使用率,将其反馈给任务分配服务器.但也应该看到,其相比于加权最少连接数算法只有10%左右的性能提升,付出的代价是大大提高了系统复杂性.在文献中提出了一种具有实时反馈能力的负载均衡算法,选择了与文献中近似的方法,通过计算后端服务器中CPU、内存、IO的负荷情况反馈回前端负载均衡器.在文献中提出了负载均衡算法,并且结合memcache,将CPU、网络等资源使用情况反馈给前端负载均衡器.
综上文献看出现有的研究主要集中在后端服务器向前端反馈资源占用状况,这种方式能一定程度准确反应实际情况.但其问题有三,一是增加了复杂性;二是占用了资源,性能提升并不明显.三是负载反馈具有滞后性,当短连接数较多时,无法反映出实际负载情况.
3 基于热数据的最少连接数负载均衡算法
相比于依赖于后端服务器反馈负载情况,在负载均衡器上也能采集到负载情况的相关信息,如连接数、时延等.热数据是指一段时间内频繁访问的数据,对于Web访问来说,可以简单地认为,相同的URL访问出现热数据的几率要高得多.
设W(Ni)是为第i个后服务器的权重,W(Ni)权重主要考虑三个因素连接数、时延和URL的哈希.URL的哈希权值代表与热数据的接近程度,按URL的哈希分配更能接近热数据.设URL经过哈希运算后结果会落到[0,H)的区间上,则H(Ni)是URL相对于第i个服务器的权值,则有如下公式:
设C(Ni)为第i个的服务器的连接数,D(Ni)为第i个服务器的平均延时值,则连接数与时延的联合加权值W(Li)为:
设Ccnt为预先设定的常量,W(Ni)的值为:
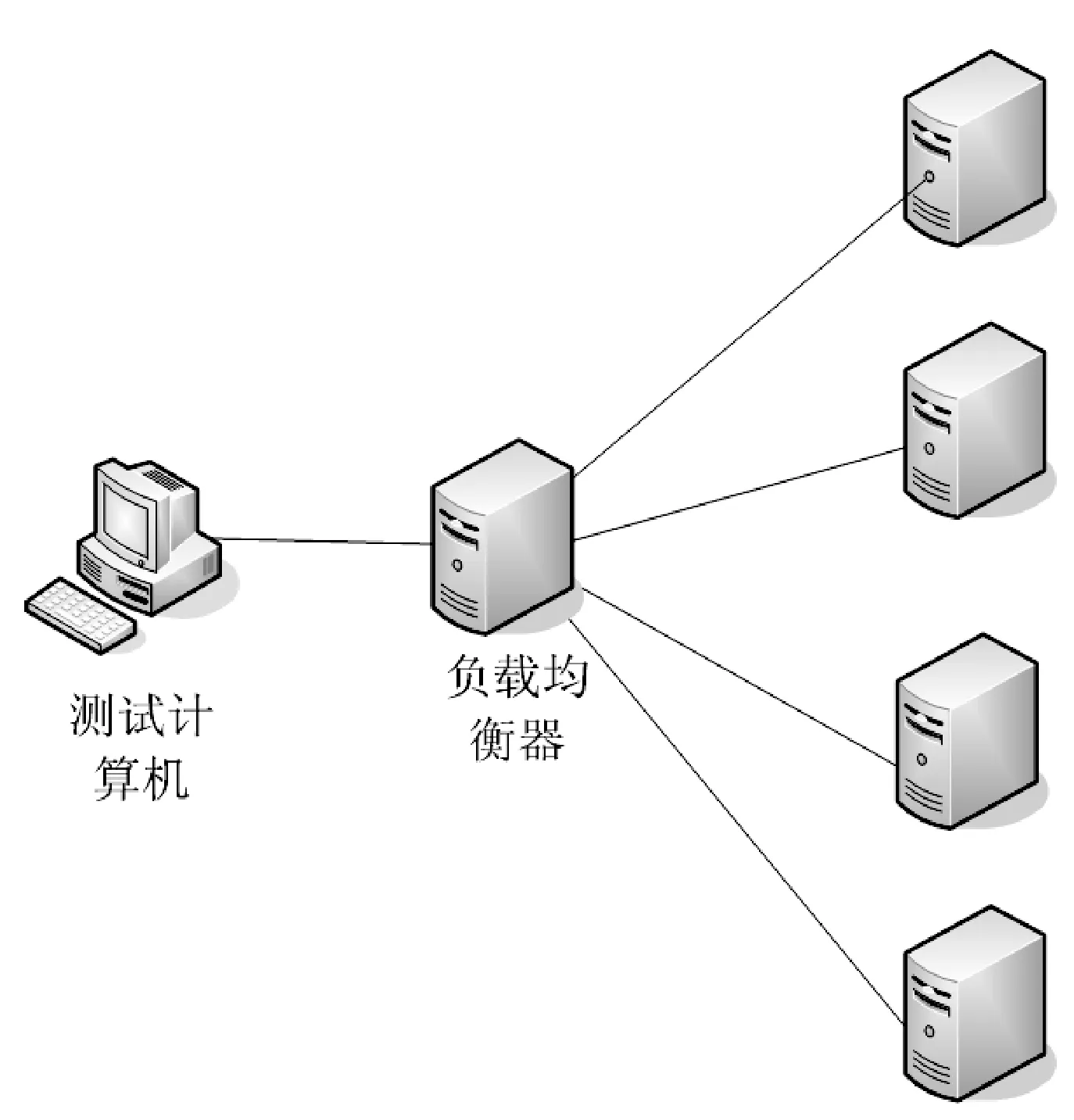
图1 实验示意图
那么第i个服务器分配到负载的概率Pi为:
4 实验验证
实验开发环境是使用五台计算机,操作系统为CentOS6.9,一台安装Nginx作为负载均衡器,四台作为后端服务器,安装php_fpm服务软件.压力测试软件使用Apache AB实验图如图1所示.
实验测试分别测试轮询算法(RR),最少连接数算法(LC),基于热数据的最少连接数算法(HLC),实验做了5次取平均值.在表1中列出了三种算法的平均响应时间,可以看到,使用LC算法要比传统的轮询算法响应时间要少,而使用基于HLC算法,响应时间更好.
表2测试了连接成功数,可以看到相比于传统的RR算法,LC算法的连接成功次数有了一定的提高,而使用HLC算法在连接成功数上与LC算法相当.
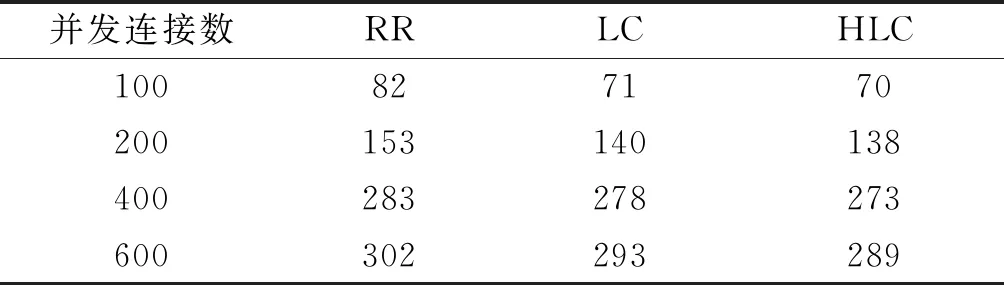
表1 平均响应时延 ms
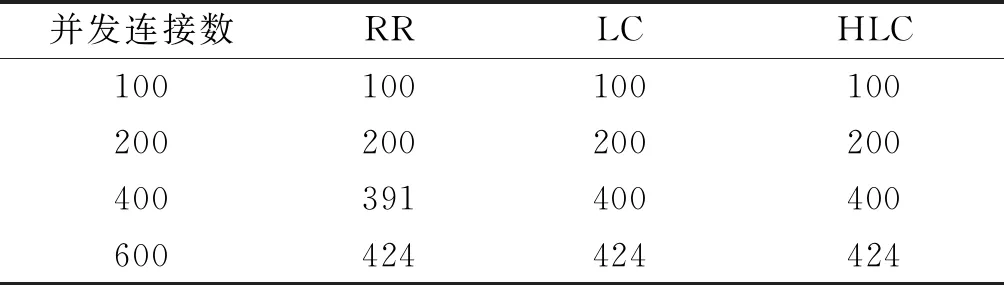
表2 连接成功数
5 总结
相比于传统的轮询算法,最少连接数能够提高负载均衡的性能,使用热数据的最少连接数算法比较依赖于是否能读到热的数据,所以不同的环境下可能性能表现会有差距.
猜你喜欢
睿士(2022年7期)2022-07-15
电子与信息学报(2022年6期)2022-06-25
电光与控制(2022年4期)2022-04-07
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
计算机与数字工程(2019年2期)2019-02-28
火控雷达技术(2016年1期)2016-02-06
电脑爱好者(2015年13期)2015-09-10
移动通信(2014年4期)2014-03-31
