
学术电子书元数据质量检测及控制
2019-07-06 01:21翟中会
图书馆研究与工作 2019年7期
翟中会 周 琴 蔡 勤
(西安交通大学图书馆 陕西西安 710061)
1 引言
过去10年里,电子书数量及质量得到了迅猛发展,仅2016年全球出版了大约45万种英文语种的学术电子书,佛罗里达大学图书馆电子书占所有图书比例已经上升到73%[1]。电子书与物理馆藏相比有其优点,如电子书不会错架和丢失、实时在线访问、不用去图书馆借阅;但也有其缺点,如用户可以通过检索或浏览书架两种方式发现物理馆藏,而电子书只能通过计算机检索的方式发现,如果电子书的元数据不完整或错误,用户很难检索到该书[2]。所以书目元数据和其他描述信息元素是保证用户发现和利用电子书的关键,用户根据电子书第一个页面的元数据决定是否阅读该书。
影响用户使用电子书的因素很多,包括电子书格式、个人书架、添加注释、打印、下载以及移动端访问等,但这些都必须建立在用户可发现的基础上,一旦电子书元数据错误、不全或不一致会对用户发现电子图书造成影响。因此元数据质量是数字馆藏可靠并高效操作的必要条件,元数据能够执行发现、使用、出处、流通、认证和管理这些核心书目功能[3]。本文介绍了出版社和电子书聚合平台元数据的质量问题,进而提出质量控制方法,以促进图书馆建立高质量的元数据,增加电子图书的使用效率。
2 电子书元数据质量及评价
2.1 出版社和图书馆元数据的差异
大部分出版社除了提供电子书外还提供大量的电子期刊,电子期刊发展时间较长,已形成了成熟的标准和生产流程,这些出版社将电子期刊元数据标准直接应用于电子书,但电子书和电子期刊的发现方式完全不同,比如用户通过数据库、索引和A—Z期刊列表发现电子期刊内容,而用户访问电子书的途径主要有OPAC(Online Public Access Catalogue,联机公共查询目录)、资源发现系统、出版社平台、聚合器平台(EBSCO、MyiLibrary等)、Google等方式。这些平台的元数据来源于出版社提供的MARC(Machine Readable Catalogue,机器可读目录)记录,电子图书的发现完全依赖这些MARC记录,所以用户很难发现按照电子期刊方式组织的电子图书。
图书馆和出版商使用的元数据格式不同,出版商使用ONIX(Online Information Exchange,在线信息交换)元数据,图书馆使用MARC元数据。ONIX元数据包括数字版权管理、销售记录和国际分销等内容,这些特点有利用出版商管理电子图书的销售。出版商为了方便图书馆将电子书目加载到本馆的ILS(Integrated Library System,图书馆集成系统),采用第三方软件增强ONIX数据或将ONIX转换为MARC,有时也从一些提供商或OCLC(Online Computer Library Center,联机计算机图书馆中心)订购MARC记录。但在这些转化或增强过程中,由于一些字段对出版社并不重要,所以可能遗漏对于图书馆非常重要的字段信息(如美国国会图书馆标题表LCSH)。另外出版社也很难制定出满足不同ILS系统的元数据。电子书可以按照年度、系列或两者结合方式销售,这些销售信息很容易在ONIX元数据中表示,在MARC元数据中几乎不可能实现。
2.2 MARC记录不适用于电子图书
2011年美国国会图书馆提出重新评估MARC21,认为已有40多年历史的MARC21不能适应大量数字资源描述。尽管MARC标准是一个非常成熟的标准,但不同的编目人员使用时存在差异,在书目聚合平台(发现系统)能够发现许多标题编目级别上的差异。出版商将许可协议年份作为“版权年”,版权年有利于出版社销售给图书馆的电子图书时间范围。虽然MARC中包括了出版年和版权年,但出版商所定义的版权年没有纳入MARC记录,因此MARC记录中仅包括出版年。在新的标准出现之前,我们应该尽最大努力改善MARC21标准,使之尽可能满足电子书元数据要求。
3 电子书元数据质量检测及使用情况
3.1 检测内容及方法
电子书平台包括商业出版社平台、大学出版平台、电子书聚合平台(ebrary、E-Book Library、MyiLibrary和EBSCO等)3种形式。图书馆购买的电子书分布在在这3种类型的平台上。目前,大量出版社不仅在私有的平台上提供电子书访问,也在一些供应商的聚合器平台提供电子书的访问权限。本次测试选择了CABI(Center for Agriculture and Bioscience International,国际农业与生物科学中心)等8个出版社和EBSCO等3个平台测试电子书元数据的准确性。
电子书MARC记录最常见的错误有哪些?不同出版社存在的错误是否相同?MARC记录质量是否一致?为了分析这些问题,我们从资源发现系统中收集电子书MARC记录,包括标题、作者、出版年,样本大小基于99%的置信度和5%的置信区间,采用一个通用ID标识电子书,然后输入Excel工作表,使用Excel中的RANDBETWEEN函数选择随机抽样的电子书标题进行元数据检查。检查内容包括:①对比电子书元数据和PDF格式电子书中的标题、作者、出版年和ISBN是否一致;②检查PDF电子书全文页码、章节是否完整;③电子书全文是否可以下载;④目录表是否能正确链接到PDF全文对应页面(目录通常来源于附加的XML文件或PDF文件中的TOC)。
3.2 检测结果
书的完整性、PDF下载、MARC记录和PDF全文中标题、出版年、作者、内容匹配情况、TOC链接精确度范围为90.3%到99.6%之间,不同出版社MARC记录准确性范围为84.3%到97.8%。结果表明,大多数MARC来源的质量非常好,标题、作者和出版年3个字段中作者出现错误几率最小(如表1所示)。
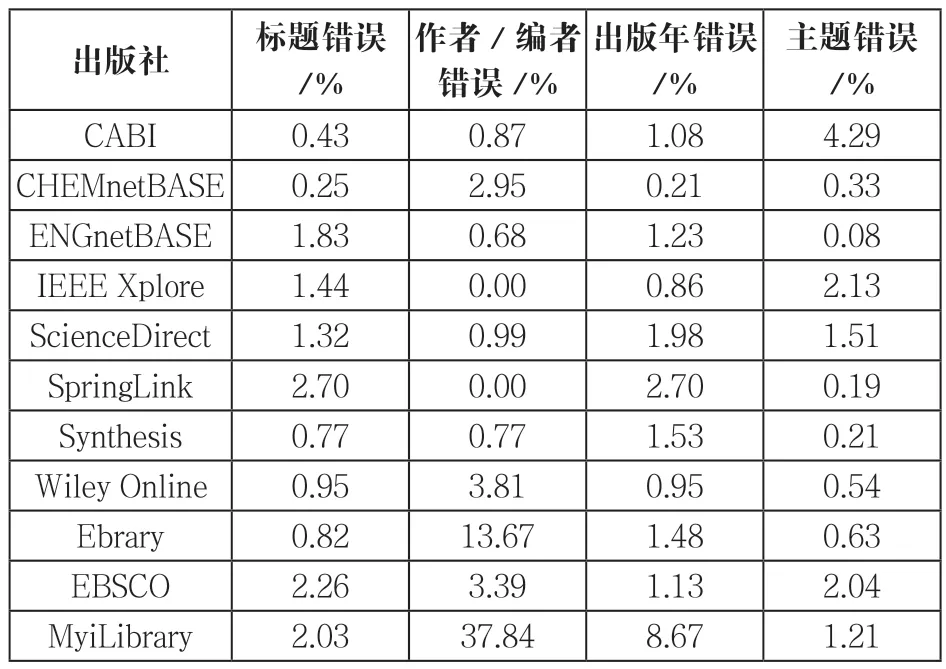
表1 出版社MARC记录错误
3.3 用户使用MARC的检索方式
用户在检索电子书时,有的字段经常被使用而有的则很少被使用,因此经常使用的字段如果发生错误将对电子书的发现产生很大影响,通过了解哪些字段对终端用户最重要(如电子书页码错误对用户几乎没有影响),可以优先考虑对这些字段的纠错。为了确定字段的相对重要性,作者通过电子书平台搜索日志收集用户使用MARC字段检索情况。根据日志分析,用户检索类型主要包括下面几种情况:作者、主题、标题、LCSH、语言、出版社、ISBN、出版年和“关键词在所有字段”。“关键词在所有字段”是使用最多的检索方式,占整个检索类型的88%,标题、作者和主题也是比较重要的字段。另外还有学科、主题、控制号(ISBN和数字对象唯一标识符DOI),标题方式有完整标题检索(如“Envisioning Easiness:Byron's‘Darkness’,Campbell's‘The East Man’,and the Critical Aftermath.”)、短语检索(如“The Troubled Dream of Life”),但该书的完整的标题为“The Troubled Dream of Life: In Search of a Peaceful Death”。主题检索为单个或几个单词主题搜索(如“aestheticism”,或“protests + demonstrations+native+Canadians”)。主题或标题检索,不区分是主题或标题(如“winnipeg+general+strike”)。主题或作者检索,不区分是作者名或是否研究对象为该人名。
4 建立质量控制过程
元数据是电子图书服务的基础,目前还没有完整一致的方法创建元数据。建立有效的质量控制过程可以解决不同提供商元数据不一致和完整性问题,大部分出版社或聚合平台采用冗余方法控制元数据质量。然而这种方法在实践过程中并不是非常有效,另外电子书上线后,读者应该立即就能访问电子图书的内容,所以元数据质量应该在上线前进行检查,而不能依靠读者的反馈纠错。
4.1 质量评价框架
目前,电子书元数据质量评价最完整的一个框架由7个通用维度组成:完整性、精确性、来源、期望一致性、逻辑一致性、时效性和可访问性。精确性和一致性在这7个维度中最重要。也有学者提出采用分析和经验方法组合来估计元数据质量变化,构建对最终用户透明的基线质量模型。OCLC开发了质量保证机制,并测量了它们对数字学习库的影响。他们的案例研究表明,在存储库生命周期中为元数据创建过程插入控制点可以显著提高元数据的完整性。
4.2 质量控制过程中的问题
资源描述的精确性和一致性是保证元数据在本地语境环境下可发现的必要条件,严格检查发布者列表,严格的内容加载后检查以及内容完整性的自动检查有助于元数据质量提高。
在数字环境下,图书馆扮演聚合和发布者角色,很难控制和评估元数据质量,另外元数据也不像MARC记录有成熟的质量控制体系,所以必须开发元数据本身的评价和转化过程支持元数据基本的互操作能力。出版商使用MARC作为ONIX元数据的唯一替代品[4],这迫使图书馆必须以MARC记录质量标准评价元数据。但对于电子书来说应该在元素水平(如标题)评价元数据质量,而不是记录水平(如MARC记录)。电子书元数据必须有书目的发现、使用、来源、流通、认证和管理功能,使用openURL链接解析、搜索引擎可检索。建立聚合平台时索引那些MARC字段,在每个标题的第一页显示那些特殊字段都是需要考虑的问题[5],如版本对于电子书作用不大,不需要在第一页显示版权字段,但MARC记录中含有版本字段。IFLA(International Federation of Library Associations,国际图书馆协会与机构联合会)在国际编目原则中声明,元数据质量控制是为了促进终端用户发现、识别、选择和使用信息资源。然而,近来NISO(National Information Standards Organization,美国国家信息标准组织)强调电子书元数据不仅仅是出版社和图书馆馆员使用,更主要是为读者服务。高质量元数据不但提升了电子书的购买和流通,读者也能通过电子书封面、目录等内容决定是否下载或阅读该书。
目前,虽然有一些标准可以应用于电子书(如期刊文章标签套件),但在电子书行业还在不断发展的状态下使用一个特定的标准也不是非常合适,也不能解决出版商元数据不完整的问题。
4.3 图书馆和出版社在质量控制中的作用
字段重复和错误、MARC记录错误抓取数据并索引,都直接影响了元数据的质量。另外,由于MARC记录由不同主体完成,所以不同的出版社和出版社内部的MARC记录存在不一致的问题。为了处理这些不一致性,图书馆可以通过分析原始MARC记录判断通用映射文件是否正确,在加载数据前,分析每个出版社的样本记录是否包含需要的所有字段,字段是否以与通用XML映射文件匹配的方式进行编码。如果数据不匹配,需要更改映射文件,以便正确地索引所需的字段,不过这种方案的缺点是忽略了映射文件的通用性。通用性映射文件索引较少的字段,因此用户体验性较差,同时如果想转移到丰富元数据格式,会导致个性化映射不一致。
一种处理MARC不一致的方案是从一个元数据标准到另一个标准创建“通路”或将MARC记录映射到完全不同的标准。例如,将不同出版社元数据映射到自然语言(Natural Language Processing,简称NPL)处理标签,即使出版社本身以NPL为元数据标签,也需要进一步对元数据标准化,这可以保证一致的元数据以及索引元数据的所有基本元素。
映射文件不能满足所有出版社提供的原始元数据,出版社提供的原始数据和后期处理过程都可能产生错误,相对于前一种错误后期处理过程中产生的错误较少见,但如果发生这种错误就会同时影响大批记录,例如主题编码字段与映射文件字段不同,处理过程就不能识别主题字段。其他细小的错误如作者名字拼写错误、标题错误需要图书馆员手动修改。
控制号(DOI或ISBN)也是元数据质量非常重要的一个指标[6],近来出现的跨平台和数据库数据共享标准(Knowledge Bases And Related Tools,简称KBART)强调ISBN或eISBN对专著标识的重要性,出版商在电子书元数据中加入了EPUB(Electronic Publication)标识字段。
为了提高电子书元数据索引,图书馆可以采取一种适合于电子书的特殊书目信息标准,比如,为不同版本MARC建立对照表,这种方法有利于从其他资源获取元数据(如ONIX、出版社的DTD文档)。馆员将电子书元数据与从其他学术图书馆的目录中提取的记录进行比较,创建一个与质量控制过程分开的纠错过程。分析哪些字段对终端用户最重要,可以优先考虑对这些字段的纠错。
5 结语
通过对电子书元数据质量分析,发现即使很少的元数据错误对电子书来说也是很大的损失。目前图书馆和出版商协议中还没有考虑到电子书元数据质量,元数据质量也不是协议中的一个条款,但是敦促出版商提高元数据质量,图书馆自身清理元数据或者通过第三方质量控制提升元数据质量对提升电子图书利用非常重要。
猜你喜欢
办公室业务(2019年13期)2019-08-01
作文评点报·小学五、六年级(2019年16期)2019-04-30
中国神经再生研究(英文版)(2017年10期)2017-11-08
出版广角(2017年19期)2017-10-27
中国德育(2016年11期)2016-06-17
语文世界(小学版)(2015年11期)2015-12-18
儿童故事画报·发现号趣味百科(2015年5期)2015-07-22
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
英语学习·阳光英语(2013年3期)2013-07-30
