
基于多源数据融合方法的期刊评价及实证研究
2019-06-27 03:38孙济庆
中国科技期刊研究 2019年6期
■陈 荣 朱 雯 孙济庆
华东理工大学科技信息研究所,上海市梅陇路130号 200237
期刊评价是信息计量学研究的重要方向之一,Web of Science一直以来被视作计量学的核心工具,成为期刊评价与学术研究的重要数据来源[1],但随着百度学术、谷歌学术等学术搜索引擎的兴起,中国知网、维普等国内数据库及Scopus等国外数据库的广泛使用,可以应用于期刊评价的数据源越来越多,给期刊评价带来了巨大的挑战。目前,期刊评价的计量数据[2-7]主要来源于谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库,但由于不同数据源得到的期刊评价结果差异大,学者们开始研究不同数据源期刊计量结果的差异性。国外研究主要集中于分析谷歌学术、Scopus和Web of Science三者在期刊计量评价方面的差异,如在被引频次方面,Scopus和Web of Science的被引频次比较相近,而谷歌学术与二者的被引频次差异较大[8-9];在期刊h指数方面,Minasny等[10]发现谷歌学术收录期刊的h指数高于Web of Science和Scopus。国内学者在国外研究的基础上,还研究国内本土的数据库、学术搜索引擎与国外数据库、学术搜索引擎的计量差异[11-13],如骆维花[14]比较谷歌学术、中国知网和百度学术中期刊h5指数,发现在医学学科中h5指数差异性最小。
由于提供给期刊评价的数据源越来越丰富,如何通过数据融合方法处理多源数据的计量关系,以期解决单一数据源评价期刊影响力导致的信息缺失等问题,促使计量评价结果更科学、准确,成为科学计量学面临的新问题,也是期刊评价发展的新契机[15]。目前用于多源数据融合的方法主要有加权平均融合法[16]、证据推理法[17]、贝叶斯估计法[18]等,但应用于期刊评价领域的方法主要是计算所有数据源中的计量结果均值或者最大范围地整合多种数据源中的引文数据,苏林伟等[1]比较分析多源数据(Web of Science、Scopus和谷歌学术)的复合引文算术均值、几何均值及调和均值,探索在多源数据融合下不同均值与单一均值的相关性与差异性;Jacso[19]提出不能直接使用系统自动生成的h指数,应通过搜索题名信息以便获取更多的引文数据;Groote等[20]通过汇总Web of Science和Scopus中的引用文献计算综合h指数;Miri等[21]认为使用Web of Science、Scopus和谷歌学术三者的平均影响因子可以更加全面地评价期刊学术影响力。
分析上述研究发现,一方面鲜有研究从期刊计量结果角度比较国内学术数据库、学术搜索引擎和国外的学术数据库、学术搜索引擎之间的差异性,另一方面仅仅从均值的角度综合多种数据源的期刊计量结果不能体现出单一数据源在期刊计量方面的优劣,并且综合引文数据的工作量较大。本研究分析了谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库的期刊收录重叠概况(图1),发现各个数据源在期刊收录方面也各具特色:谷歌学术作为全球免费的在线文献检索系统,虽然期刊来源范围较广,但引文信息不足,引文信息的质量有待考量;百度学术作为中国免费的学术检索系统,引文信息来源及时、广泛,但引文质量有待考量;Web of Science选刊较为严格,数据来源较规范,引文信息质量相对较高,但收录的期刊范围较窄,缺乏多样性[22];Scopus的期刊收录范围较广,但历史文献覆盖相对不足[23];中国知网是国内最大的中外文学术资源整合平台之一,引文信息来源广泛,但英文期刊收录较少;维普数据库是国内最大的数字期刊数据库,但缺少英文期刊。
为了证明所提方法的可行性,本研究仅选取谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库作为数据来源,上述6种数据源可基本反映期刊评价之间的差异;为了证明本研究所提方法的可操作性,以上述6种数据源共同收录的40种国内理工科期刊为例,从发文量、总被引频次和篇均被引频次3方面比较样本期刊2012—2016年在6种数据源中期刊计量结果的差异性,在此基础上综合内容权重和逻辑权重提出面向期刊计量评价的多源数据融合方法,并利用期刊篇均被引频次进行实证研究,以期为综合评价期刊影响力提供参考借鉴。
2 基于单一数据源的期刊计量评价结果差异性分析
当前用于期刊评价的指标主要有影响因子、被引频次、h指数等[24-26]。本研究以谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库中共同收录的40种国内理工科期刊为例,统计这些期刊2012—2016年在上述数据源中的发文量、总被引频次和篇均被引频次。
2.1 发文量比较
学术数据库和学术搜索引擎的发文量是指在这些数据源中的期刊发文量,期刊实际发文量是指期刊官网中显示的发文量。在发文量方面(表1),中国知网和维普数据库的发文量平均占比超过了期刊实际发文量,Web of Science的计量结果准确度最高,百度学术的准确度最低。

表1 每种数据源中期刊发文量与期刊实际发文量平均占比
2.2 总被引频次和篇均被引频次比较
研究发现,在以上6种数据源中,谷歌学术中的期刊总被引频次最高,其次是Scopus和Web of Science,而维普数据库最低。进一步利用篇均被引频次对样本期刊进行排名(表2)(限于篇幅,仅列出10种期刊的排名情况),同一期刊在不同数据源中的排名差异大,如Nano-MicroLetters在Web of Science中排名第1,而在维普数据库中排名第40,排名相差39;TransactionsofNonferrousMetalsSocietyofChina在谷歌学术中排名第8,而在百度学术中排名第39,排名相差31。
由上述分析结果可知,如何从多源数据中获得统一的期刊计量结果成为期刊评价的关键,因此本研究综合内容权重和逻辑权重提出面向期刊评价的多源数据融合方法,为综合利用多种数据源评价期刊影响力提供统一标准。
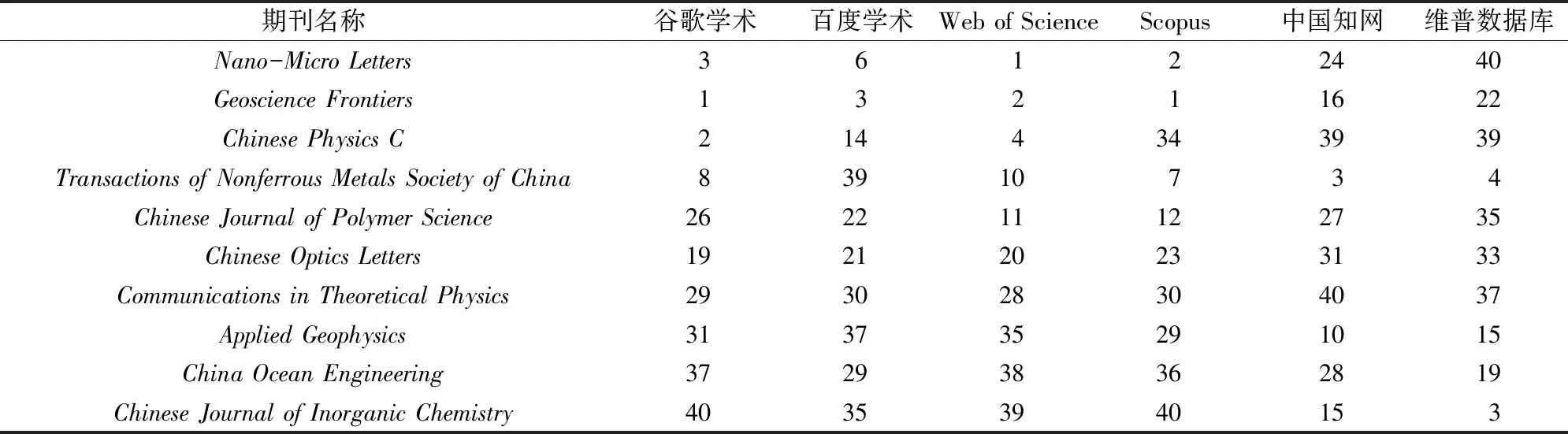
表2 不同数据源中期刊排名情况
3 面向期刊计量评价的多源数据融合方法
本研究借鉴加权平均融合法,利用综合内容权重和逻辑权重后的几何权重值来融合多源数据中的期刊计量结果。内容权重是基于多种数据源之间计量结果的相关关系,为相似度高的数据源赋予较高权重,有利于检验每种数据源中期刊计量结果的质量,而逻辑权重可以计算各种数据源与最优解之间的相似度,最大可能地计算出每种数据源的最优权重,保证了计量评价结果的准确性和科学性。其操作流程是:(1)确定期刊计量评价指标(如期刊总被引频次、篇均被引频次等);(2)依据内容权重、逻辑权重计算每种数据源的几何权重;(3)将每种数据源中的期刊计量评价结果乘以相应的几何权重得到多源数据融合的期刊计量评价结果。
3.1 内容权重
内容权重是计算每种数据源间的相关关系,期刊计量评价结果相似度高的数据源被赋予较高权重。内容权重是用来检验已有期刊指标计量结果的质量,首先利用SPSS 22.0软件聚类分析每种数据源间的相关关系[27],其次利用数理公式探析不同数据间的内容权重,公式为
(1)

3.2 逻辑权重
逻辑权重是依据每种数据源与多源数据源中最优指标计量结果的相似度计算所得,本研究利用欧氏距离计算每种数据源与最优解间的相似度,若相似度越大,表明该系统与最优结果的差距越大,则该种数据源被赋予较大权重。
设X={x1,x2,…,xn}表示某种数据源中n种样本期刊组成的计量结果集,Y={y1,y2,…,yn}表示多种数据源中n种样本期刊组成的最优计量结果集,其相似度计算公式为
(2)
式中:dj表示第j种数据源与最优解间的差异程度;xi为第j种数据源中第i种期刊相应指标的计量结果;yi为第j种数据源中第i种期刊的最优指标计量结果。
对数据进行归一化处理得到相似度:
(3)
逻辑权重公式为
(4)
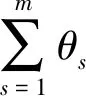
3.3 几何权重和多源数据融合的期刊计量评价结果
几何权重是依据内容权重和逻辑权重计算所得,具体公式如下:
(5)

多源数据融合的期刊计量评价结果是每种数据源中期刊计量评价结果乘以相应的权重值后相加的结果,公式如下:
(6)
式中:m为数据源的总和;σi为多源数据融合后的第i种期刊的计量评价结果;ωs为第s种数据源中原有的期刊计量评价结果。
4 面向期刊计量评价的多源数据融合方法实证研究
为验证多源数据融合方法在期刊评价中的科学性和准确性,本研究以谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库共同收录的40种国内理工科期刊为研究对象,由于每种数据源收录的期刊发文量与实际发文量差异较大,故采用期刊篇均被引频次进行实证研究,比较多源数据融合期刊篇均被引频次和单一数据源期刊篇均被引频次、多源数据融合均值期刊被引频次的关系,进一步探析多源数据融合方法在期刊评价中的应用概况。
4.1 多源数据融合期刊篇均被引频次计算
(1) 对多源数据中期刊篇均被引频次聚类(图2),发现6种数据源可以分为5类:第一类有2种数据源,分别是Web of Science和Scopus;第二类有1种数据源,即百度学术;第三类有1种数据源,即中国知网;第四类有1种数据源,即谷歌学术;第五类有1种数据源,即维普数据库。依据(1)式计算得出Web of Science和Scopus的内容权重为0.25,百度学术、中国知网、谷歌学术和维普数据库的内容权重为0.125。

图2 多源数据中期刊篇均被引频次聚类树状图(组间)
(2) 设定最优篇均被引频次集为每种期刊在6种数据源中的最大篇均被引频次的集合,根据(2)~(4)式计算得出Web of Science的逻辑权重为0.136,Scopus的逻辑权重为0.14,百度学术的逻辑权重为0.117,中国知网的逻辑权重为0.099,谷歌学术的逻辑权重为0.435,维普数据库的逻辑权重为0.073。
(3) 根据(5)式计算得出每种数据源的几何权重,得出Web of Science的权重为0.213,Scopus的权重为0.22,百度学术的权重为0.092,中国知网的权重为0.078,谷歌学术的权重为0.341,维普数据库的权重为0.057。依据(6)式计算每种期刊的多源数据融合期刊篇均被引频次。
4.2 多源数据融合期刊的篇均被引频次与单一数据源期刊的篇均被引频次比较
由图3可知:单一数据源中的中国知网、维普数据库与其他数据源中的期刊篇均被引频次差异大,而多源数据融合期刊篇均被引频次很好地综合了各种数据源中期刊篇均被引频次的优劣,并且未出现极端值,以Nano-MicroLetters(期刊序号为9)为例,谷歌学术中篇均被引频次为18.85,百度学术中篇均被引频次为6.47,Web of Science中篇均被引频次为13.94,Scopus中篇均被引频次为14.15,中国知网和维普数据库中篇均被引频次仅为2.5和0.02,而Nano-MicroLetters的多源数据融合篇均被引频次为13.3,由此可见多源数据融合期刊篇均被引频次可以在一定程度上综合每种数据源的优劣,减小各种数据源的数值差异。
谷歌学术中各种期刊的篇均被引频次均高于多源数据融合期刊的篇均被引频次;除PetroleumExplorationandDevelopment(期刊序号为3)外,维普数据库中各种期刊的篇均被引频次均低于多源数据融合期刊的篇均被引频次。

图3 多源数据融合期刊篇均被引频次与单一数据源期刊篇均被引频次比较
本研究进一步利用SPSS 22.0软件对数据进行正态性检验,发现并非所有的数据满足正态分布,故采用Spearman系数计算多源数据融合期刊篇均被引频次与单一数据源期刊篇均被引频次的相关性(表3)。从表3可以看出,多源数据融合期刊篇均被引频次和谷歌学术、Web of Science中的期刊篇均被引频次的相关性较高,而与维普数据库的期刊篇均被引频次的相关性最低,分析原因:一方面,样本数据中百度学术计量的发文量缺期比较严重,维普数据库和中国知网的总被引频次偏低,故多源数据融合期刊篇均被引频次与百度学术、中国知网和维普数据库的相关性低;另一方面,谷歌学术计量的期刊发文量比较准确并且总被引频次最高,故多源数据融合期刊篇均被引频次与谷歌学术的相关性高;而Web of Science和Scopus的总被引频次相近,但Web of Science计量的期刊发文量准确性高于Scopus,故多源数据融合期刊篇均被引频次与Web of Science的相关性高于与Scopus的相关性。
由上述分析发现:一方面,与单一数据源相比,多源数据融合期刊篇均被引频次缩小了不同数据源间结果的差异;另一方面,多源数据融合期刊篇均被引频次可以很好地综合各种数据源的优缺点,区分出不同数据源的重要性。

表3 多源数据融合期刊篇均被引频次与单一数据源期刊篇均被引频次的相关系数
4.3 多源数据融合期刊篇均被引频次排名与单一数据源期刊篇均被引频次排名比较
多源数据融合期刊篇均被引频次可以平衡各个数据源期刊排名的差异,如ActaOceanologicaSinica(期刊序号为34)在谷歌学术、百度学术、Web of Science、Scopus、中国知网、维普数据库中的篇均被引频次排名分别是36、23、36、37、33、27、34,而多源数据融合期刊篇均被引频次排名是34,由此可以得到相对综合的期刊排名结果。
进一步利用多源数据融合期刊篇均被引频次对期刊进行四等分区,每个分区有10种期刊,计算每个分区中各期刊排名的平均差距(表4),多源数据融合期刊篇均被引频次排名与谷歌学术的排名差距最小,紧接着是Web of Science和Scopus。为了检验此结果,本研究进一步计算了每种数据源中期刊排名差距小于等于10的期刊比例(表5),6种数据源中超过一半期刊的排名差距在10以内,并且与谷歌学术相比,期刊排名差距在10以内的占比最高,由此推断出多源数据融合期刊篇均被引频次可以在一定程度上缩小不同数据源中期刊篇均被引频次排名的差异。
4.4 多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次比较
本研究中的均值期刊被引频次是指多源数据中期刊篇均被引频次的算术平均值,比较分析多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次(图4),旨在发现两者的差异和相关关系。由图4可知,除PetroleumExplorationandDevelopment和ChineseJournalofInorganicChemistry(期刊序号为5)外,多源数据融合期刊篇均被引频次普遍高于多源数据融合均值期刊篇均被引频次。利用SPSS 22.0软件计算多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次的相关性,得出Spearman相关性系数为0.988(P<0.001),多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次高度相关。

表4 多源数据融合期刊篇均被引频次与单一数据源期刊篇均被引频次排名平均差距
注:CG表示多源数据融合期刊篇均被引频次排名与谷歌学术期刊篇均被引频次排名的平均差距;CB表示多源数据融合期刊篇均被引频次排名与百度学术期刊篇均被引频次排名的平均差距;CW表示多源数据融合期刊篇均被引频次排名与Web of Science期刊篇均被引频次排名的平均差距;CS表示多源数据融合期刊篇均被引频次排名与Scopus期刊篇均被引频次排名的平均差距;CC表示多源数据融合期刊篇均被引频次排名与中国知网期刊篇均被引频次排名的平均差距;CV表示多源数据融合期刊篇均被引频次排名与维普数据库期刊篇均被引频次排名的平均差距。

表5 多源数据融合期刊篇均被引频次与单一数据源期刊篇均被引频次排名差异在10以内的占比
由上述分析可知:一方面,多源数据融合期刊篇均被引频次的数值一般高于多源数据融合均值期刊篇均被引频次,但多源数据融合均值期刊篇均被引频次不能区分出不同数据源中期刊计量结果的重要性差别,而多源数据融合期刊篇均被引频次能更好地反映每种数据源中期刊计量结果的重要性差别;另一方面,多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次高度相关,说明多源数据融合期刊篇均被引频次可以在一定程度上替代多源数据融合均值期刊篇均被引频次综合评价期刊影响力。

图4 多源数据融合期刊篇均被引频次与多源数据融合均值期刊篇均被引频次
5 结论
本研究选取40种理工科期刊为样本,比较分析谷歌学术、百度学术、Web of Science、Scopus、中国知网和维普数据库中期刊计量评价结果的差异,发现不同数据源中期刊计量评价结果的差异较大,在此基础上提出面向期刊计量评价的多源数据融合方法,并以期刊篇均被引频次为例进行实证研究,发现多源数据融合方法可以通过内容相关、逻辑相关等原理,解决不同数据源中数据融合问题,在期刊评价中有着重要的应用价值。
(1) 在发文量方面,谷歌学术的发文量准确度最高,百度学术的发文量准确度最低;在总被引频次方面,谷歌学术的总被引频次最高,维普数据库的总被引频次最低;在期刊篇均被引频次排名方面,不同数据源中期刊排名差异较大,如维普数据库和Web of Science的期刊排名差距最大。
(2) 综合内容权重和逻辑权重提出面向期刊计量评价的多源数据融合方法,为期刊评价提供统一量纲。利用期刊篇均被引频次进行实证研究,发现一方面多源数据融合期刊篇均被引频次可以在一定程度上起到综合利用各种数据源期刊计量结果的作用,并且可以综合各种数据源的优缺点,在某种意义上具有统计学意义;另一方面多源数据融合期刊篇均被引频次可以平衡各种数据源中期刊排名的差异。与多源数据融合均值期刊篇均被引频次相比,多源数据融合期刊篇均被引频次能更好地反映每种数据源中数据的重要性差别,并可以在一定程度上代替多源数据融合均值期刊篇均被引频次综合计算期刊评价结果。
需要特别指出的是,一方面,本研究仅选取部分重要期刊,数据仅仅为了证明所提方法的可行性和可操作性,在实际应用中可以根据学科不同,选取不同领域的期刊样本;另一方面,本研究仅借鉴了加权平均融合的多源数据融合方法,未使用贝叶斯估计法等进行期刊评价数据融合,后续将深入探讨贝叶斯估计法、证据推理法等多源数据融合方法是否可以应用于期刊评价,从方法论上为期刊评价的科学性和严谨性提供微薄之力。
猜你喜欢
心理学报(2022年5期)2022-05-16
中国中医基础医学杂志(2022年3期)2022-04-19
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
医学信息(2016年5期)2016-05-14
浙江大学学报(工学版)(2015年2期)2015-05-30
河南图书馆学刊(2014年12期)2015-02-02
——初级保健晚期疾病患者照顾者的识别障碍:3个数据源的三角化测量
中国全科医学(2014年29期)2014-01-28
