
基于SVC和过采样的类别非均衡农业高光谱数据分类
2019-06-26 11:24袁培森翟肇裕任守纲顾兴健徐焕良
农业机械学报 2019年6期
袁培森 翟肇裕 任守纲,3 顾兴健 徐焕良,3
(1.南京农业大学信息科学技术学院, 南京 210095; 2.马德里理工大学技术工程和电信系统高级学院, 马德里 28040;3.国家信息农业工程技术中心, 南京 210095)
0 引言
高光谱遥感技术通过采集不同目标反射或辐射出不同波长的电磁波, 得到以像素为单位的遥感影像。高光谱图像(Hyperspectral image)拥有丰富的光谱信息,能提供准确、详细的土地覆盖材料描述,在农作物长势监测、作物养分监测、水分状况监测、作物生长参数估算、农作物高光谱遥感识别和分类等[1-6]方面具有广泛的应用。
高光谱图像波段多, 光谱波段覆盖范围广, 包含丰富的信息, 并可结合空间信息和光谱信息,有效地反映目标的信息。高光谱图像分类是高光谱遥感对地观测研究的重要内容,其具体任务是对高光谱图像中的每一个像素所代表的目标进行有效的分类[7-8]。而非均衡问题是高光谱数据非常普遍的现象,当数据集中类别的比例严重失调时,传统的分类技术对于不平衡的数据集往往不能产生令人满意的结果[9]。因此非均衡高光谱数据的分类是一个很普遍和重要的问题[10-14]。
处理非均衡数据分类的主要技术包括数据采样[15-16]、基于代价的分类[17]等。其中,基于数据采样技术包括过采样和欠采样[18]。欠采样采用减少多类样本方案,但是由于高光谱图像训练样本一般较少,对采集到的高光谱图像进行标记代价较高。丢失的标类样本对分类模型具有较大的影响,因此对于不均衡农业高光谱数据导致的少数类分类质量问题,本文采用典型的合成少数类的过采样技术(Synthetic minority oversampling technique,SMOTE)[19]。
目前,在非均衡高光谱数据集上的分类研究,尤其是农业高光谱数据分析方面,许多学者进行了研究。ZHANG等[10]提出,模型学习期间使用支持向量进行抽样,使得训练数据分布均衡。GARCA等[20]使用随机采样和PCA技术对高光谱数据随机采样再降维,进而使用决策树来分类,分类精度虽有所提高,但是该方法试验结果仍有很大的提升空间。LI等[14]提出基于正交补的数据子空间投影不平衡的高光谱图像分类技术。CHAO等[13]针对复杂高光谱图像数据分类中少数类别分类精度低的问题,提出了一种基于MK-LSSVM的不平衡分类方法,该方法使用K-means聚类将多数类划分为不同的组,在聚类之后使用抽样技术平衡每个组和少数类,通过构建MK-LSSVM分类器对高光谱图像进行分类。GRAVES等[21]通过成像光谱数据的分类不平衡数据集绘制物种图谱,这将有助于研究在越来越大的空间尺度上理解树种分布。
本文针对非均衡农业高光谱数据,采用过采样(Oversampling)技术处理少数类样本数据,通过对少数类采样个数的分析,研究少数类样本采样倍率对分类结果的影响。通过对非均衡高光谱数据采样,使少数类样本尽可能均衡,进而采用多类分类器——支持向量分类(Support vector classification,SVC)进行分类。采用SMOTE[19]进行过采样少数类样本,研究SMOTE参数对分类精度的影响,研究非均衡高光谱数据分类器与模型的一致性对分类的影响。针对高光谱数据多类分类问题,采用SVC[22]有效解决不平衡高光谱图像分类模型的集合学习过程。
1 非均衡数据及处理
1.1 非均衡数据
数据非均衡是数据挖掘等领域常见的问题,例如信用卡欺诈数据分析[16]、疾病诊断[23]、生物信息分析[24]、高光谱数据分析[21]等。BRANCO等[25]总结了非均衡数据的问题,并对比了相关的方法和理论,同时得出,非均衡数据中,用户更加重视在目标变量域的子集上的预测性能,但是与用户更相关的样本在训练中的代表性较差,进而导致模型对少数类样本的错误估计。

1.2 过采样
处理不均衡数据,有两个基本方法[16-17]:改变数据分布,在数据层面使得类别更均衡;改变分类算法,在传统分类算法的基础上对分类器采用加权方式,使得模型对少数类更加敏感。采样技术简单高效,常用的采样方法有:欠采样、过采样、欠采样和过采样综合采样[18]。过采样采用增加少数类样本,通过设置多数类和少数类的比例系数,在多数类样本不变情况下,生成指定数量的少数类样本,如图1所示,图中η为少数类的采样倍率。
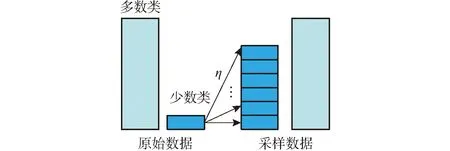
图1 非均衡数据过采样示意图Fig.1 Illustration of unbalanced data oversampling processing
SMOTE[19]是典型的非均衡数据过采样技术,它通过在少数样本附近位置生成新样本达到类别平衡的目的,可以有效避免分类器过拟合。其处理基本过程如下:
(1)对少数类中每一个样本xi,计算它到少数类样本集Dr中所有样本的欧氏距离,得到其中k个近邻。
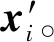
(1)
式中 rand(·)——均匀分布函数
SMOTE通过生成新的数据集来解决少数类分类不平衡的问题。假设初始数据集中少数类样本数为|Dr|,多数类样本数为|Dn|,首先增加(η-1)|Dr|个少数类样本,并把最初的少数类样本和新增的少数类样本都放入新的数据集中。这样,新的数据集中少数类样本有η|Dr|个,数据集共η|Dr|+|Dn|个样本。
根据少数类选择策略的不同,SMOTE包含 Regular、Borderline1、Borderline2和SVM这4种策略[26]。
2 非均衡高光谱数据的多类分类处理
2.1 处理过程
非均衡农业高光谱数据的分类采用两阶段处理:数据预处理及过采样,生成新的采样数据集;采用多类分类器训练分类模型,对少数类分类质量进行评估和参数最优化选择。
采样预处理通过对少数类进行过采样使得各类实例大致平等。通过使用过采样,学习模型能够极大地克服由于多数类导致的模型先验偏差。
高光谱数据采用最小-最大规范化(Min-max normalization)[27]对原始数据进行线性变换,设样本属性A的值为v,则该规范化为
(2)
式中vmax——属性A最大值
vmin——属性A最小值
max——属性A的值域最大值
min——属性A的值域最小值
本文将原始数据变换到[0,1]区间,此时最大值和最小值分别为0和1。
通过SMOTE对数据集D中指定的少数类和采样倍率η进行采样,新生成的数据集记为D′,D′=η|Dr|+|Dn|。
2.2 高光谱多类分类
由于高光谱分类任务数据中通常包括多个类别。主要是通过组合多个二分类器来实现多分类器的构造[28]。一般的高光谱分类问题属于多类分类(Multi-class classification),即将实例分类为2个类以上的分类问题。多类分类的假设是,每个样本有唯一的类标签。多类分类问题通过采用二类分类算法和一定的策略完成多类分类任务,采用的策略有Onevsall和Onevsone[28]。
SVC[29]是基于支持向量机分类的一种技术。对于两类分类问题,SVC问题可以归为以下问题:
给定两类问题的训练向量xi∈Rd,i=1,2,…,n,类标号yi∈{-1,1},SVC问题的求解公式为
(3)
式中ζi——松弛变量b——截距
w——权重向量J——目标函数
C——调和系数φ——核函数
式(3)的求解需要转换为对偶形式,其对偶形式为
(4)
其中Qij=yiyjK(xi,xj)=φ(xi)Tφ(xj)
式中e——单位向量y——类标号
α——拉格朗日乘子
αi——拉格朗日乘子
K(xi,xj)——核函数
Q——n×n的半正定矩阵
Qij——Q的元素
式(4)通过核函数φ使得训练向量映射到高维空间。常见的核函数选择为径向基函数(Radial basis function,RBF)[28]
K(x1,x2)=exp(-γ‖x1-x2‖2)
(5)
式中γ——核的泛化能力参数,γ≥0
若γ越小则决策边界越精简,泛化能力越强。γ越大表示决策边界越复杂,则泛化能力越弱。
对于样本x,其分类的决策函数可以表示为
(6)
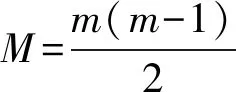
(7)
式中fi——分类器决策函数
3 试验结果与分析
3.1 试验数据集
本文测试的数据集为Indian Pines,该数据集由AVIRIS传感器在印第安纳州西北部的印度松树林采集,由145像素×145像素和224光谱反射波段组成,波长范围为4×10-7~2.5×10-6m。该数据集共包含了16类不同的农业对象,共标注10 249个像素类别,数据集真实类及分布比例具体如表1所示。本文算法采用Python 3.6实现。
本文所使用的数据集Indian Pines中类别分布如图2所示。从图2可以看出,该高光谱数据集少数类数量分布极不均衡。本文把类别中所占比例低于3%的类别作为少数类,其余作为多数类。因此,该数据集中少数类包括6个:Alfalfa、Corn、Grass-pasture-mowed、 Oats、Wheat和Stone-Steel-Towers。
3.2 参数设置
本文参数设置如下:测试集和训练集的比例为3∶7。径向基函数RBF参数γ为0.125,C为1。SMOTE参数k的范围为3~7,默认为6,新样本中生成策略默认为SVM。少数类采样倍率默认为5。
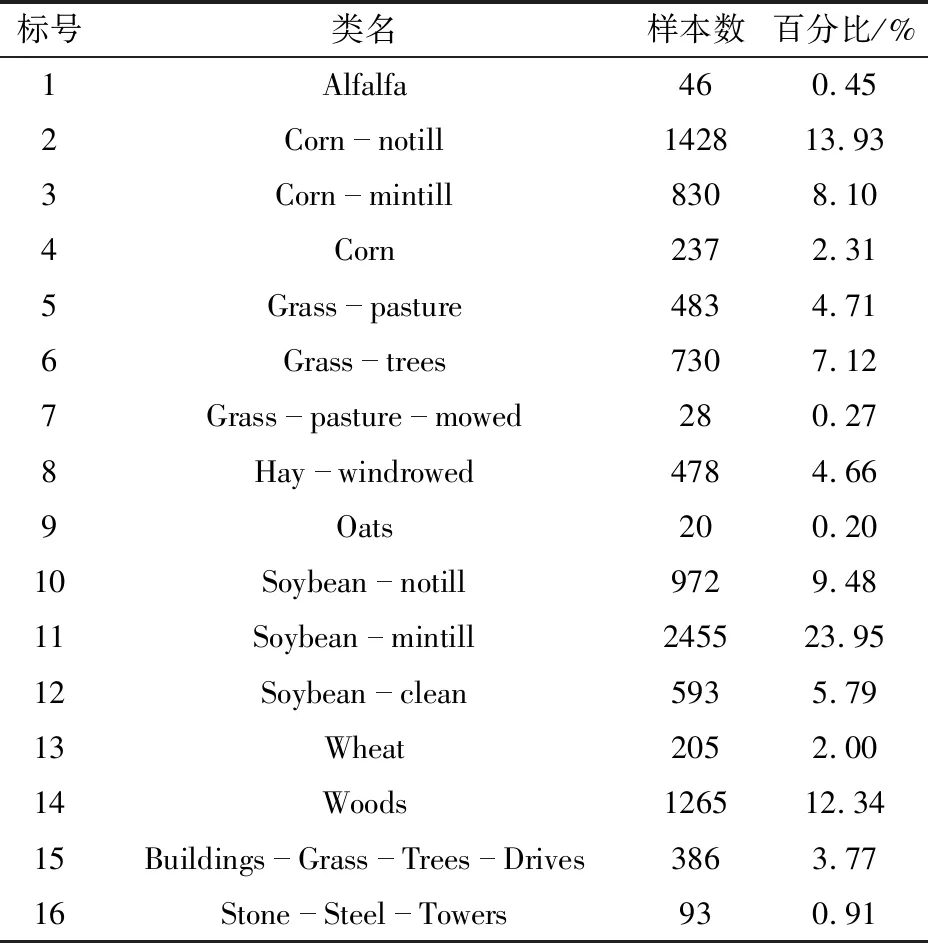
表1 Indian Pines数据集的Groundtruth类及其样本数Tab.1 Groundtruth class of Indian Pines dataset and its sample size

图2 数据集样本类别分布Fig.2 Illustration samples distribution of Indian Pines datasets
3.3 分类精度指标
试验从半监督分类预测结果的质量分类效率进行了系统的研究和分析。 定义TP(True positive) 为正类并且也被预测成正类,FP(False positive) 为负类被预测成正类,TN(True negative) 为负类被预测成负类,FN(False negative) 为正类被预测成负类。
分类结果从7个方面进行度量:加权精度pw(Weight precision)、加权召回率rw(Weight recall)、加权F1度量、分类准确率Ac(Accuracy)、精度的几何平均值GM、平衡准确性指数(Index of balanced accuracy,IBA)和Kappa系数Ka。定义分别为
(8)
(9)
(10)
(11)
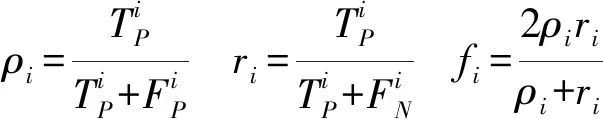
式中si——第i类的支持度
i——高光谱数据类别,即每一类的真实类出现次数



ρi——第i类的精度
ri——第i类的召回率
fi——第i类的F1度量
GM度量用于评估不平衡分类应用的分类性能。两类精度的几何平均值为
(12)
GM在获得两类精度良好平衡的同时使其最大化。
IBA量化了两类准确性平衡指数与选择的无偏估计总体准确性之间的权衡,计算式为
IBAθ=[1+θ(TP-TN)]TPTN
(13)
IBAθ取决于用户定义的参数θ,本文θ设置为1。
Kappa系数[31]Ka准确度指标用于度量不平衡数据集的分类器与模型匹配的精细化程度,公式为
(14)
式中po——评估者之间相对观察到的一致意见的百分比
ph——一致意见的预期次数
使用观察到的数据来计算每个观察者随机查看每个类别的概率Ka∈(0,1),Ka在0.61~0.80之间表示模型具有较好的一致性[31]。
3.4 分类精度
在原始数据集和采样数据集上,对比了SVC和随机森林(Random forest,RF)[32]在Indian Pines数据集的分类准确率。
图3是对Indian Pines原始数据集和采样数据集两个分类方法的分类准确率。采用70%数据集训练模型、30%数据集作为测试集。在Indian Pines原始数据集上SVC在所有类上的分类准确率为0.78,少数类的分类准确率为0.65,RF在所有类上分类准确率为0.82,在少数类上的分类准确率为0.38。结果表明SVC在原始数据集上的分类准确率比RF低4.88%,但是对于少数类的分类准确率,SVC比RF高71.05%。因此,SVC对少数类分类效果优于RF。
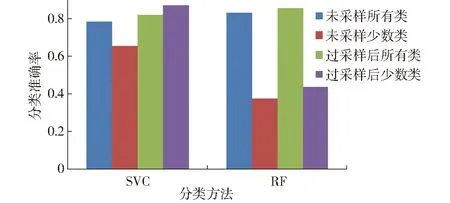
图3 Indian Pines数据集分类精度对比Fig.3 Classification accuracy comparison of Indian Pines dataset
对数据集中的少数类使用SMOTE采样之后,在采样数据集上,SVC和RF的分类准确率有所提高,分别提高32.93%和16.46%。结果表明,SCV在少数类上的分类准确率和提高的比例优于RF。因此,本文采用SVC对高光谱数据进行分类。
图4是在原始数据集上使用SVC分类的混肴矩阵,横轴为在16个类别上预测的类标号,纵轴为16个真实类标号。从图4可以看出,SVC在未采样的高光谱数据集上的分类效果不理想,尤其是对少数类1、4、7、9这4个类分类精度比较低。
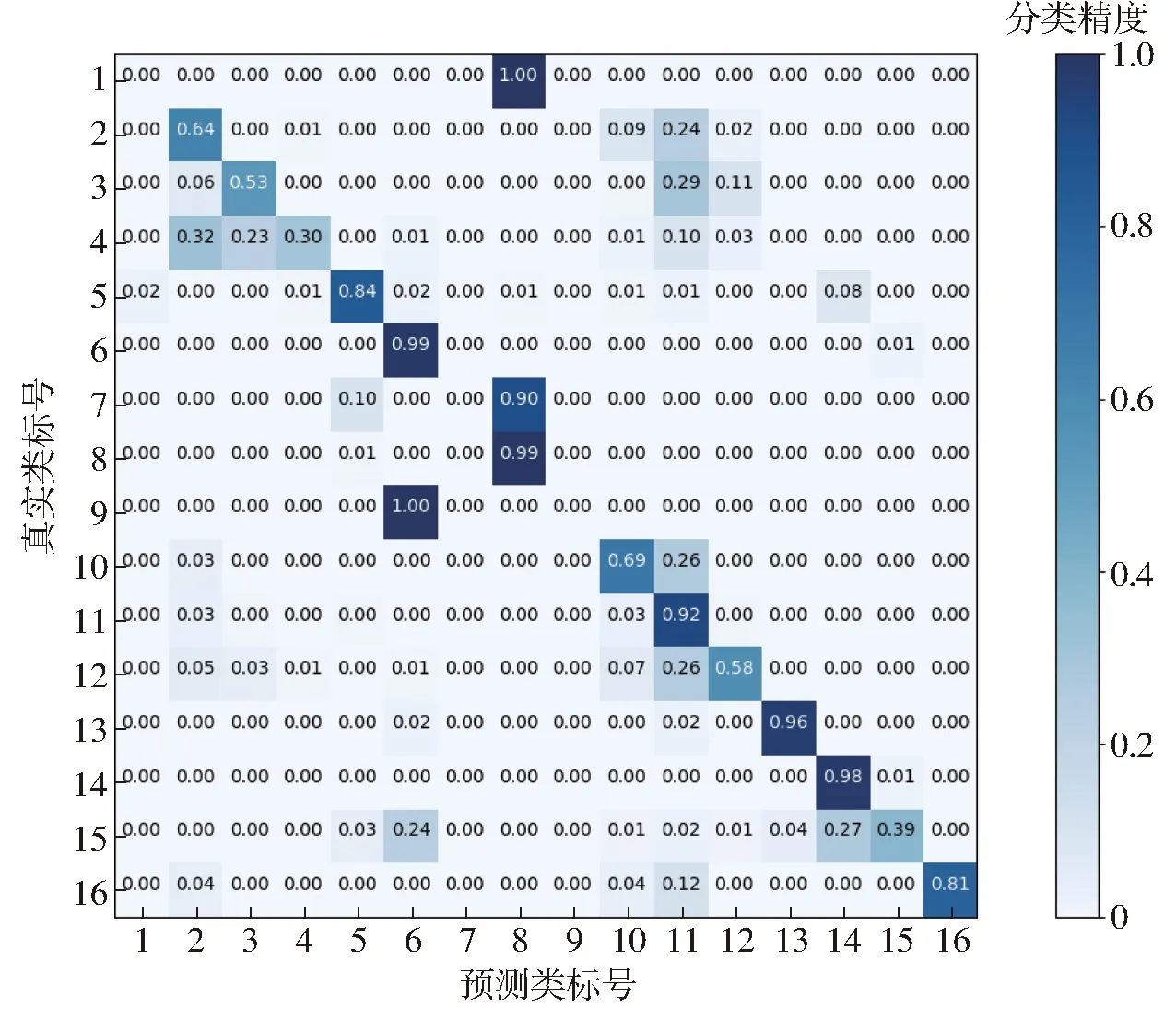
图4 原始数据集使用SVC分类的混肴矩阵Fig.4 Confusion matrix of original imbalanced dataset with SVC
3.5 SMOTE参数对精度的影响
3.5.1新样本生成策略
SMOTE的参数k设置为6时,数据集上少数类识别准确率如表2所示。从表2可以看出,SVM 策略对少数类分类结果的加权召回率rw、F1、GM和IBA结果较其它3个策略好。
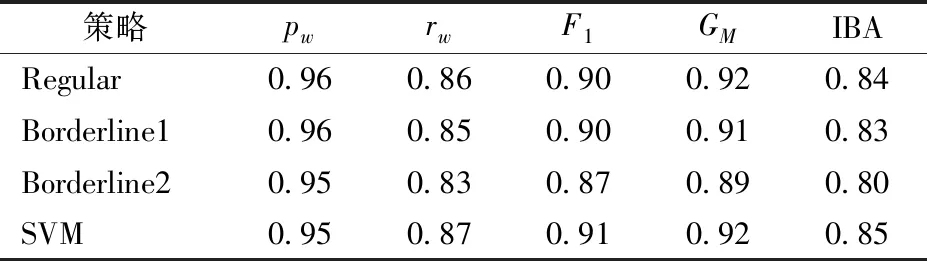
表2 SMOTE的4种新样本生成策略对少数类的影响Tab.2 Influence of new instance generating strategy of SMOTE on minority classes
为了进一步测试少数类上新样本生成策略对分类准确率的影响,在k为6时,测试了少数类分类准确率与4种新样本生成策略的关系,结果如图5所示。从图5可以看出,4个策略中SVM的少数类分类准确率最高,为0.873。

图5 不同生成策略时少数类的分类准确率Fig.5 Classification accuracy of minority classes with new instance generating strategy of SMOTE
3.5.2参数k
SMOTE新样本生成策略为SVM时,少数类结果度量与参数k关系如表3所示。从表3可以看出,k为6时,少数类分类结果在加权召回率rw、F1、GM和IBA指标上较好。

表3 少数类结果度量与参数k的关系Tab.3 Classification performance of minority classes with parameters k of SMOTE
为了进一步测试少数类上参数k对分类准确率的影响,在生成策略为SVM时,测试了少数类的分类准确率与参数k的关系,结果如图6所示。参数k的取值范围为3~7。少数类的分类准确率为0.855~0.873,其中,k为6时,分类准确率最高,为0.873。

图6 少数类的分类准确率与参数k的关系Fig.6 Classification accuracy of minority classes with parameters k of SMOTE
3.5.3少数类采样倍率
高光谱数据中少数类采样倍率η与精度、召回率和F1测试结果如图7所示。从图7可以看出,采用SMOTE对少数类采样的pw、rw和F1影响非常显著;采样倍率η为1~4时,度量值提升幅度最大,pw、rw和F1分别提升了8.67%、30.58%和25.81%;采样倍率为5~15时,pw、rw和F1变化不明显,结果比较稳定,具有较好的鲁棒性。
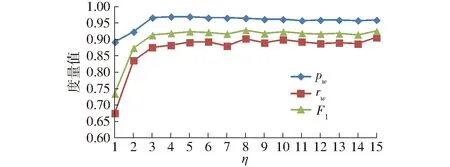
图7 采样倍率η与pw、rw和F1的关系Fig.7 Relationship of precison, recall rate and F1 with sampling ratio η of SMOTE
3.6 Kappa系数
参数k为6时,少数类上分类模型的Kappa系数Ka与SMOTE中新样本生成策略的关系如图8所示。4个生成策略中少数类分类的Ka变化范围为0.768~0.829,其中,SVM策略的Kappa系数最高,为0.829。
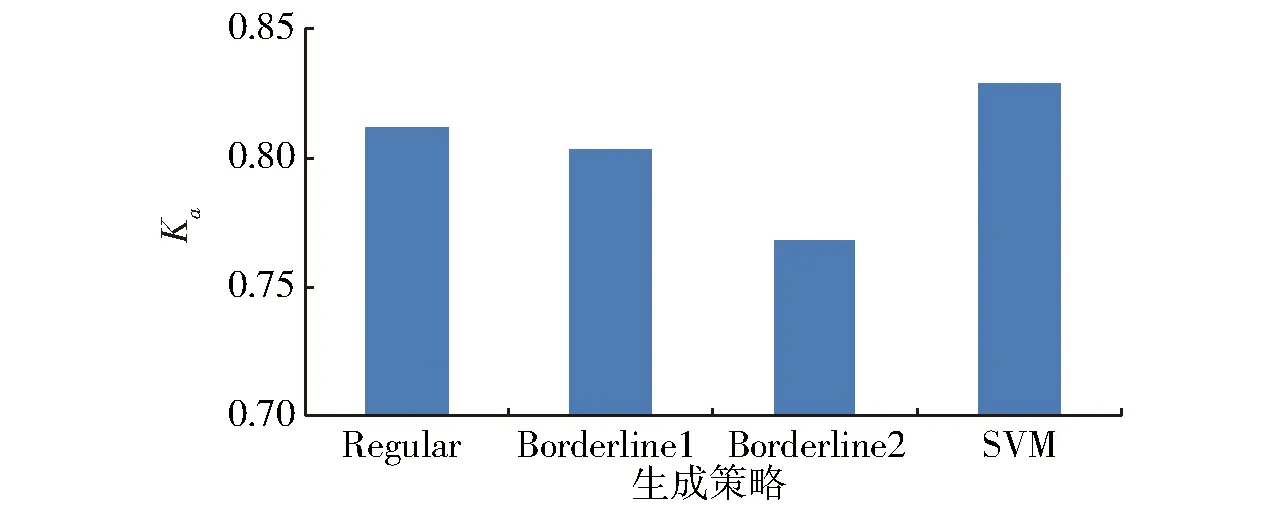
图8 新样本生成策略与Ka的关系Fig.8 Relationship of Ka of model with new instance generating strategy of SMOTE
少数类上的分类模型的Ka与SMOTE中参数k关系如图9所示。参数k的取值范围为3~7。少数类分类的Ka范围为0.803~0.829,其中,k为6时,Kappa系数最高为0.829。
从分类模型一致性度量Ka结果可知,参数k为6时,SVM策略取得最优结果。
3.7 试验对比
表4是SMOTE参数k设置为 6,采用SVM策略时,在非采样数据集和采样数据集上的pw、rw和F1

图9 参数k与Ka的关系Fig.9 Relationship of Ka of model with parameters k of SMOTE

标号采样数据集原始数据集pwrwF1pwrwF110.940.960.9500040.990.820.9010.650.79710.750.8600090.820.450.58000130.920.900.910.910.810.8616111.0010.830.71
结果。SVC分类器采用RBF核函数,各少数类采样的倍率η设置为8。
表4中标号表示的类名与表1相同。表4结果表明,通过数据集SMOTE采样之后,少数类的3个分类指标均有大幅提升。Alfalfa、Grass-pasture-mowed、Oats 3个类由于类数量在原始数据集上过于稀少,非采样集上3个指标都为0。经过过采样之后,pw、rw和F1分别为0.94、0.96、0.95、1.00、0.75、0.86和0.82、0.45、0.58。Corn的pw降低了1%,但是rw和F1分别提升了26.15%和13.92%。Wheat的pw提升了1.1%,rw和F1分别提升了11.11%和5.81%,Stone-Steel-Towers的pw不变,但是rw和F1分别提升了20.48%和40.85%。
上述结果表明,稀少的类在非采样数据集上,其分类的效果较差,往往淹没于多数类中,经过过采样,其分类的效果提升非常显著。Alfalfa、Oats和Grass-pasture-mowed 3个类的rw提升最显著。
表5是本文方法与SVO[10]及SVM[33]方法在平均分类精度Ac和Kappa系数Ka的试验对比结果。本文方法在参数k设置为6、采用SVM策略时,分类的平均精度和Kappa系数相比于SVO分别提升了6.72%和3.50%,相比于SVM[33],分别提升了12.21%和3.62%。

表5 与其他方法的准确率对比Tab.5 Classification accuracy comparison with other methods
图10是默认参数情况下,在采样数据集上使用SVC分类的混肴矩阵,横轴为16个预测类标号,纵轴为16个真实类标号。从图10可以看出,SVC在采样高光谱数据集上的分类精度提升很大,对少数类1、4、7、9、13和16分类精度的分类效果提升显著。

图10 SMOTE采样数据集上分类精度混肴矩阵Fig.10 Confusion matrix of oversampling dataset with SMOTE
4 结论
(1)针对农业高光谱数据的非均衡环境下少数类分类精度低的问题,研究了少数类的分类质量,利用过采样技术对数据进行处理,提升了少数类的分类质量。
(2)在高光谱数据集上进行了试验验证,对系统参数进行了试验和对比分析,试验结果表明,本文方法能够较好地提升高光谱数据集少数类分类精度,pw不小于0.82,rw不小于0.45,rw提升显著,提升幅度在11.11%~ 26.15%之间。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电子产品世界(2022年4期)2022-04-21
黑龙江大学自然科学学报(2022年1期)2022-03-29
四川大学学报(自然科学版)(2021年6期)2021-12-27
空间科学学报(2021年1期)2021-05-22
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
文苑(2015年9期)2015-09-10
