
基于联合变化检测的耕地撂荒信息提取与驱动因素分析
2019-06-26 11:24郭旭东岳德鹏汪晓帆韩圣其
农业机械学报 2019年6期
杨 通 郭旭东 岳德鹏 汪晓帆 韩圣其
(1.北京林业大学精准林业北京市重点实验室, 北京 100083;2.中国土地勘测规划院自然资源部土地利用重点实验室, 北京 100035)
0 引言
现阶段撂荒地提取方法主要分为:①基于遥感图像的分类方法,如目视解译[1-2]、监督分类[3-8]、面向对象分类[9-10]等。②基于变化检测的方法,如直接变化检测[5]、分类后变化检测[11-13]、植被指数变化检测[14]、非遥感数据(主要为GIS数据)的变化检测等[15]。
分类方法的前提是基于撂荒地与其他地类存在显著差别,但撂荒地的地表覆被复杂,样本可分离度低,容易与裸地、草地、灌木等地类混分。变化检测方法的前提是基于耕地在监测周期内发生撂荒,但对于监测周期之前已经发生的撂荒地无能为力,且容易受非耕地变化噪声影响。此外,遥感数据本身也存在一定限制,中低分数据空间分辨率低,不足以提取撂荒地;高分数据重访周期长、幅宽小,难以保证大区域的时空覆盖,且易受地形、云层干扰。再加上撂荒地存在多种类型(完全撂荒、半撂荒、过渡撂荒)[1],不同区域的作物特征和种植制度也有差别,因此,用传统方法提取撂荒地困难。
本文提出基于多源数据的联合变化检测方法提取撂荒地。首先利用多源高分遥感数据的观测频度优势,保证研究区的时空覆盖和晴空数据比重;其次利用地理信息调查数据圈定耕地范围和退耕还林范围,以减少非耕地变化噪声干扰;最后,针对不同类型的撂荒地分别提出年内检测法和年际检测法,并耦合为联合变化检测法。利用该方法提取撂荒地的距离特征、高差特征、邻域特征及灌溉特征,并对上述特征进行统计分析及显著性分析,以期得到区域撂荒主导因素,为定向提升撂荒地管理提供依据。
1 数据与方法
1.1 研究区概况

图1 研究区地理位置图Fig.1 Geographical location map of research area
1.2 数据来源
遥感数据源包括高分一号卫星(GF-1)8、16 m多光谱影像;高分二号卫星(GF-2)4 m多光谱影像;资源三号卫星(ZY-3)6 m多光谱影像;哨兵二号卫星(Sentinel-2A)10 m多光谱影像。获取2014—2017年每年春(5月)、夏(7—8月)、秋(9月下旬—10月上旬)多源遥感影像106景,依据“无云数据优先、高分数据优先、高可靠性数据优先”原则筛选可用影像63景,经处理得到覆盖全县的12期高分辨率遥感影像数据,其中,国产卫星数据来源于中国土地勘测规划院,哨兵数据来源于欧空局(ESA)官网,有效载荷技术指标见表1。

表1 卫星有效载荷技术指标Tab.1 Satellite payload technical index
遥感数据源共计4种卫星、5种传感器,各传感器均具备可见光到近红外波段,且各波段中心波长一致,具备数据融合的基础。地理信息数据包括全国土地利用变更调查数据、退耕还林数据。辅助数据集包括GDEMDEM的30 m DEM数据、设施占地数据、统计数据及问卷调查数据。其中,土地变更调查数据来源于中国土地勘测规划院,退耕还林数据来源于和林格尔县林业局,设施占地数据来源于地方网站,DEM数据来源于地理空间数据云。数据源时相分布见表2。
1.3 原理与方法
变化检测方法是利用地物在时间维度的变化情况,回避了易混地类样本可分离度低的问题,且该方法受地形影响较小,相对适宜提取撂荒地。但是该方法不能提取监测周期以前发生的撂荒地,也易受非耕地变化因素干扰。为解决这两个问题,首先需要将ROI定位在耕地范围,然后在ROI内提取正在种植耕地,两者相减可得未种植耕地,即撂荒地。该方法有赖于对农作物的精确提取,需对研究区的主要农作物类型、特征、种植制度予以统计分析,在此基础上确定数据时相和变化阈值。此外,利用多源数据的高时空分辨率和高晴空数据比,可有效提高监测精度。最后,对不同类型的撂荒地需采取不同的提取策略。参考欧盟环境政策研究所关于撂荒地的定义[1],并结合研究区的实际情况,本研究将连续2年及2年以上未种植的耕地归入完全撂荒;将一年未耕种的耕地归入半撂荒;将退耕还林、设施占地造成的短期撂荒归入过渡撂荒。用年内检测法提取完全撂荒,用年际检测法提取半撂荒,用退耕还林、设施占地数据提取过渡撂荒,对上述方法进行耦合分析,联合变化检测撂荒地提取方法技术体系如图2所示。

表2 数据源时相分布Tab.2 Data source phase distribution

图2 技术路线图Fig.2 Technical roadmap
1.3.1多源数据预处理
所选4种高分卫星在所需波段上的中心波长一致,具备数据融合的基础。通过野外踏勘建立联合平差控制点,用七参数法将所有坐标系统转换为WGS84坐标系统。根据传感器的定标方程和定标系数,将其记录的量化DN值转换成对应视场的表观辐射亮度,再经大气校正获得地表反射率。使用ATCOR软件实现GF-1、GF-2、ZY-3等国产数据的大气校正;使用Sen2Cor软件实现Sentinel-2A的大气校正。利用ENVI5.3软件对所有GF-1、GF-2、ZY-3等国产数据进行几何校正。Sentinel-2A的L1C级产品为几何精校级,可作为参考影像校正其他数据。
多源数据融合包括高精度几何相对校正与相对辐射归一化。其中高精度几何相对校正以Sentinel-2A数据为基准自动选择控制点以优化国产数据的RPC参数,并结合DEM实现高精度几何相对校正。相对辐射归一化:在辐射定标和大气校正基础上,将所有数据重采样到10 m空间分辨率,升采样采用二次线性插值模型,降采样采用像素聚合模型。依据重叠区域直方图匹配方法将同组数据进行拼接、匀色和羽化,增强同组数据的辐射一致性。
1.3.2主要农作物生长特征统计
撂荒地提取精度依赖于种植耕地的提取精度。样本县主要农作物为玉米、马铃薯、大豆,还有少量谷子,其余零星播种作物不纳入统计(表3)。主要农作物生长期的NDVI特征统计如图3所示。由图3可知,玉米和谷子的NDVI较高,马铃薯次之,大豆最低。5月所有作物NDVI略有下降,可能是播种期除草所致;6—8月NDVI持续增长,于8—9月间达到峰值;9—10月收割期NDVI陡降;11月天气转冷,杂草枯死,NDVI继续降低。撂荒地的NDVI在8月以前持续上升,于8月达到峰值,8月后逐渐下降。撂荒地与农作物在8月峰值的区别度较大,在5—8月、8—10月的变化梯度差异更为显著。总体而言,研究区的主要农作物与撂荒地的NDVI峰值和变化梯度具有较高的区别度,以此作为阈值分割的基础和联合变化检测的前提。

表3 主要农作物特征Tab.3 Characteristics of main crops

图3 农作物生长期NDVI曲线Fig.3 NDVI curves of crops during growth period
1.3.3阈值分割算法实验

图4 NDVI阈值分割算法对比Fig.4 Comparison of NDVI threshold segmentation algorithms
阈值分割是变化检测的核心,分割精度直接决定方法总体精度[16]。目前较为成熟的自动阈值分割算法包括基于直方图形状的Otsu算法[17]、基于力矩的Tsai算法[18]、基于信息熵的Kapur算法[19]及基于直方图双峰的Kittler算法[20]。本研究采用基于样本统计的阈值分割方法。以年内检测法为例,5种算法进行对比如图4所示。由图4可知,Kapur算法与Kittler算法振幅较大,极不稳定。Otsu算法与Tsai算法振幅较小,且具有较好的一致性。样本统计分割阈值经2017年实地验证精度为97.6%(2.2节),故以2017年的阈值分割及地物信息为基准,控制2014—2016年的阈值分割。总体而言,研究区的阈值分布区间为0.3~0.4,最接近此区间为Tsai算法。
1.3.4联合变化检测
联合变化检测由年内检测法和年际检测法组成,其原理是:农作物由于耕作措施,在成熟期的NDVI最大值通常高于自然植被(杂草、灌木)。且农作物收割后,其NDVI在秋季会发生陡降,而自然植被不收割,故农作物在生长期的NDVI变化梯度显著高于自然植被(图3)。基于此,分别做3次变化检测,按数据时相分为2次年内检测和1次年际检测,对检测结果做交集、并集处理以提取撂荒地。
年内检测法:以土地变更调查数据中的耕地地类为总耕地,通过遥感影像提取正在种植耕地,用总耕地减去正在种植耕地,间接提取未种植耕地,即撂荒地。首先,以耕地矢量图层对遥感图像进行掩膜,去除耕地范围外的变化地物干扰,提取总耕地。然后,利用农作物NDVI的季节变化分别进行春-夏、夏-秋两次变化检测,对两次检测结果取交集,提取“正在种植耕地”。由图3可知,春、夏、秋NDVI变化梯度最大的时相分别是5、8、10月,宜选用相应月份的遥感数据。变化检测采用图像差值法,平滑核为3,最小聚类值为20,阈值分割以农作物统计结果和算法实验为参照。最后,以总耕地减去正在种植耕地得到未种植耕地,即撂荒地。
年际检测法:撂荒地在撂荒前和撂荒后的地表覆被不同,NDVI变化明显。经实地调研,研究区的撂荒地地表覆被主要为草地,新撂荒的地块杂草较为稀疏,长期撂荒的地块杂草较为茂密。基于此,以耕地矢量图层对遥感图像掩膜,将ROI限定在耕地范围内,并对前后两年的夏季遥感影像ROI进行变化检测,将NDVI明显小于前一年的耕地斑块提取出来,即当年新增加的撂荒地。
联合变化检测方法提取全类型撂荒地的计算式为
A=AC+AH+AT
(1)
其中
AC=A1∪A2-AT-AH
(2)
AH=A2-A2∩AT
(3)
AT=T+B
(4)
式中A——总撂荒AC——完全撂荒
AH——半撂荒AT——过渡撂荒
A1——年内检测法提取撂荒斑块集合
A2——年际检测法提取撂荒斑块集合
T——退耕还林B——设施占地
2 结果与分析
2.1 联合变化检测提取结果
利用多源数据、联合变化检测方法对研究区的撂荒地进行全类型提取。以2014年为基准年,全类型撂荒地提取结果见图5(2014年没有退耕还林工程,2017年尚未完成小班验证)。由联合变化检测结果可知,种植耕地主要分布于和林格尔县西北部土默川平原,及县域内两条河流沿岸区域。西北部平原因地形平整、易于灌溉和机械化种植,撂荒较少。同时,河岸附近耕地多为冲洪积地貌,地形相对平整,方便耕种且农作物产量较高,几乎不存在撂荒现象。从河岸向两侧山区辐射,因机械化种植的难度加大,农作物产量降低,导致撂荒地逐渐增多,可见地形是影响和林格尔县山区丘陵耕地撂荒的重要自然因素。

图5 联合变化检测方法提取结果Fig.5 Extraction result maps of joint change detection method
2.2 精度评价
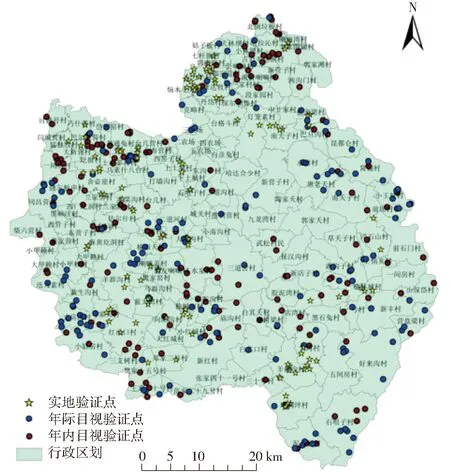
图6 验证点位Fig.6 Verifying point bitmap
结合野外实地验证和目视解译两种方法评价精度。在提取的2017年撂荒地图斑上,用ArcGIS 10.5软件生成均匀分布的450个随机点(图6),其中年际检测法提取230个点,年内检测法提取220个点,最小点距为150 m。对450个验证点中的120个点进行野外实地考察验证,其余330个验证点由Sentinel-2A(分辨率10 m)数据进行目视解译验证。经验证,联合变化检测方法于2017年提取撂荒地总体精度为97.6%,说明撂荒地提取结果真实可信,方法可行。此外,基于图5b分类结果生成200个随机点以评估分类精度。参照数据为同年GF-2数据(1 m全色、4 m多光谱),评估方式为目视验证,评估结果见表4。
基于表4计算2015年的总体分类精度为94.5%,Kappa系数为0.88。保障方法有效性及观测精度需注意:①研究前期进行实地踏勘,建立农作物及撂荒地样本知识库。②多源数据的组合原则:无云数据优先、高时空数据优先、高质量数据优先。③以高质量数据(Sentinel-2A)为基准,尽量削弱多源数据的系统差异,平滑NDVI突变。④阈值分割以各地类样本统计为基础,综合考虑时相跨度和年际降雨量变化。
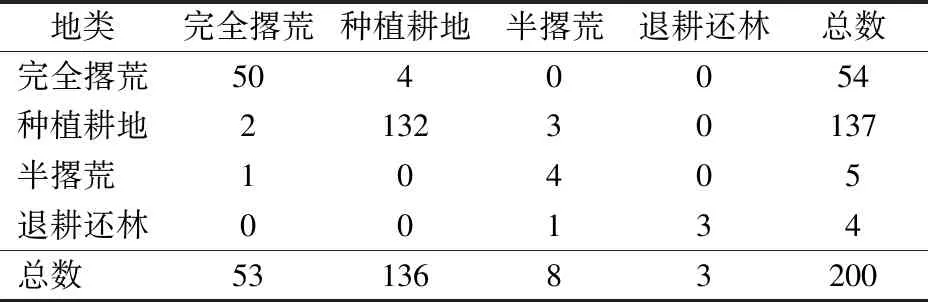
表4 混淆矩阵Tab.4 Confusion matrix
2.3 区域撂荒综合分析
完全撂荒主要分布于西南及东南部的黄土丘陵区以及东北部山区。值得注意的是,完全撂荒在一些区域(西南、东南)已呈集中连片之势,并完全取代了种植耕地,说明此区域人口大量迁出、村庄衰落,农业完全废弃。
半撂荒在全县零星分布,分布于平原区的半撂荒多为休耕地,待地力恢复后继续耕种;分布于山区丘陵的半撂荒则有很大概率在第2年继续撂荒,最终转为完全撂荒。
过渡撂荒在研究区有两种形式:退耕还林和设施占地。研究区每年退耕还林666.7 hm2耕地,各个乡镇平均分配,山区乡镇较多。设施占地方面较大型的占地项目为“盛乐国际机场项目”,计划征收2 266.7 hm2土地,主要涉及西北4个行政村,截至目前尚未征收完毕。对已有退耕还林及设施占地数据进行数字化、坐标转换、配准等处理,并与其他数据耦合分析以提取过渡撂荒。对种植耕地和全类型撂荒地进行统计如图7所示,其中,农作物播种面积数据来源于和林格尔县2014—2017年的国民经济和社会发展统计公报。

图7 种植耕地及全类型撂荒地面积Fig.7 Area of cultivated land and all types of abandoned land
与统计公报中的全年农作物播种面积相比,所述联合变化检测法提取的种植耕地面积与之相仿,4年组间平均偏差为4.9%,表明所述方法的提取结果较为可信。研究区撂荒类型以完全撂荒为主,半撂荒和过渡撂荒较少;撂荒地多分布于山区丘陵,平原分布较少。该县2014年撂荒率为37.8%,2015年为32.4%,2016年为36.7%,2017年为39%,4年平均撂荒率为36.5%,撂荒情况较为严重。总体撂荒规模相对稳定,组内偏差最大的2015年为11.1%,其余3年偏差较小。结合农户问卷和野外踏勘发现,造成研究区高撂荒率的原因是多方面的。内源性因素为:①和林格尔县山区、黄土丘陵区地貌接近80%,耕作难度大、人力成本高。②研究区的耕地质量较差,绝大部分为11~15等耕地,土质贫瘠,产出较低。③研究区为典型的农牧交错区,农牧文化并存,一些农民更愿意弃耕还牧。④和林格尔县距自治区首府呼和浩特仅60 km,根据人口迁移的“引力理论”[21],较高的人口规模及GDP、较短的距离,会对样本县人口产生较强的吸附力。外源性因素为:①随着城市化进程的加快,劳动力老龄化逐年加剧。②较高的种植成本及较低的机械化程度导致山区耕地流转困难。平原区的半撂荒多为主动撂荒,具备复耕潜力;山区的完全撂荒则多为被动撂荒。高撂荒率会进一步加速村庄边际化,直至村庄完全废弃。
2.4 空间特征提取及统计分析
以联合变化检测法提取的撂荒地斑块为基础,结合30 m DEM数据,以及图6的随机验证点和二调数据的旱地、水浇地、建筑用地、村庄边界等信息,可以提取4种空间特征指标,分别是:撂荒地块距村庄中心距离、撂荒地块距村庄中心高差、撂荒地块的灌溉类型(旱地/水浇地)、撂荒地块的邻接关系。考虑到坡度可由距离和高差求得,导致多重共线性,故不予提取。空间特征统计信息见图8。
由图8a可知,大多数撂荒地块分布在所属村庄的2 km以内。究其原因,平原区人口稠密,村庄之间距离很近;而山区的部分村庄完全废弃,全部撂荒。计算距离平均值发现,研究区的撂荒地距所属村庄中心的平均距离为1.17 km,可见距离对撂荒的影响并不显著。
以村庄中心高程为基准高程,基于30 m DEM数据对撂荒地距所属村庄的高差进行统计,得出研究区撂荒地平均高于村庄基准面40.8 m,且近40%的撂荒地块高于村庄基准面60 m以上(图8b),撂荒地受高差因素影响显著。结合实地调研分析,高差对撂荒的驱动作用力限制了农用机械的使用,增加了劳动力成本。
以二调数据为本底,对研究区耕地、撂荒地的旱地/水浇地属性类别进行统计(图8c),得出全县耕地的旱地比例为72.3%,全县撂荒地的旱地比例为89.6%。撂荒地旱地比例远高于耕地旱地比例,说明灌溉条件是决定耕地撂荒与否的重要因素之一。

图8 空间特征统计四维雷达图Fig.8 Four-dimensional radar maps of statistical spatial characteristics
由图8d可得,样本县81.9%的半撂荒地块紧邻完全撂荒地块,83.1%的完全撂荒地块彼此相邻。一方面农户决策易受相邻其他农户决策的影响;另一方面,局部区域的耕地内源性因素相似,撂荒地会向相似条件的地块蔓延。
3 结论
(1)提出了耦合年内检测法和年际检测法的联合变化检测方法,为基于遥感的区域撂荒地识别提供了快速有效的技术方法与体系。该方法对撂荒地的提取精度为97.6%,全类型分类精度为94.5%,Kappa系数为0.88。
(2)研究区撂荒地距村庄中心的平均距离为1.17 km,平均高差为40.8 m,旱地比例为89.6%(耕地为72.3%),邻接比例超过81%,结果表明研究区的撂荒驱动因素以高差因素、邻域因素和灌溉因素最为显著,距离因素不显著。针对多源数据的特征提取及显著性分析,有助于判别区域撂荒主导因素,为撂荒驱动力研究、定向提升撂荒地管理方法提供依据。
(3)研究区2014—2017年撂荒率均超过32%,南部黄土丘陵区部分村庄完全废弃,全部撂荒。
猜你喜欢
中国化肥信息(2022年8期)2022-12-05
今日农业(2022年13期)2022-11-10
北京航空航天大学学报(2022年8期)2022-08-31
建材发展导向(2021年19期)2021-12-06
今日农业(2021年14期)2021-11-25
计算机应用(2021年8期)2021-09-09
河北地质(2021年1期)2021-07-21
内蒙古科技与经济(2021年3期)2021-03-09
当代陕西(2019年10期)2019-06-03
航天电子对抗(2017年6期)2018-01-22
