
基于FM与DeepFM模型对GTD特征的研究*
2019-06-25 06:03邵玉斌杜庆治
通信技术 2019年6期
王 美,龙 华,邵玉斌,杜庆治
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
恐怖袭击事件分类在对恐怖事件预测分析中一直有非常重要的向导性作用。到目前为止,挖掘恐怖袭击事件数据间的相关性,以及对恐怖事件进行量化分类仍是一个巨大的挑战。诸多文献[1-3]采用定性方法理论如博弈论聚类分析该问题,但文中方法都比较抽象或是割裂开了影响因素间的关系。随着科学技术的发展,用于从数据中挖掘有价值信息的机器学习(Machine Learning,ML)[4-5]方法越来越多的应用于发掘恐怖袭击事件背后隐藏的关系。
2010年Pagán[6]开始使用K最近邻(k-Nearest Neighbor,KNN)和分类决策树RPART分类器等ML方法对GTD中伊拉克组织的恐怖袭击事件进行分类分析,但由于特征选取与分类方法的不完善,最终分类效果不太理想,交叉验证错误率均在40%左右。为了合理的提取特征,Iqbal和Murad[7]对数据进行了降维,并对缺失值过多特征首次采用删除处理方式,不足的是文中使用了手动选择特征方式降维,使得分类结果有很强的主观色彩,不构成严谨的分析结果。针对以上问题,Haowen Mo在文献[8]中采用了最大相关性(Max-Relevance)以及最大相关性最小冗余(Minimal- redundancy Maximal-relevancy,MRMR)特征选择方法替代手动选择特征获取有效特征集,并结合支持向量机(Support Vector Machine,SVM),朴素贝叶斯(Naive Bayes,NB)和Logistic回归(Logistic Regression,LR)分类器对恐怖袭击事件进行分类研究,文中显示分类准确率均在70%以上,是采用ML方法对(Global Terrorism Database,GTD)进行分类以来效果最佳的模型,其中以LR方法分类效果最好,正是如此,研究者提出GTD中大多数特征参数和分类变量呈线性关系。
是否GTD中大多数特征参数和分类变量呈线性关系,这是一个需要认真分析的问题,也是本文讨论的主题,因为第一点GTD是高维度数据集,则特征分量之间的相互关系不能忽略,所以原理上SVM应比LR分类效果好,但事实相反,第二点GTD有大量缺失数据,即数据集较稀疏,文献[9]学者提出对于此类数据SVM不能很好工作,但因子分解机(Factorization Machine,FM)模型效果较好,基于前面两点分析,文中采用FM与LR模型对GTD进行分类效果对比,以MCC为比较指标,其越大越好。若FM对GTD分类效果较好,由于FM属于(d=2)低阶模型,进而考虑是否高阶模型(d>2)分类效果更好,故文中采用了Huifeng Guo[10]提出的深度分解机(Factorization Machines Based Neural Network DeepFM)应用于GTD,基于FM与DeepFM可判断是否必要对GTD数据的高阶特征进行提取分析,此处基于基尼系数对比模型效果。
本文提出一种基于FM与DeepFM模型对GTD特征的研究,第二节对FM、DeepFM预测模型以及分类阈值算法进行介绍,第三节使用FM、LR与DeepFM预测模型对GTD数据集进行分类实验。第四节文章总结。
1 方法与模型介绍
1.1 TFM分类算法
FM是一个通用的机器学习模型[9,11],利用参数的因子分解对多维不同类别的变量间交互进行建模,FM模型是将SVM模型中两个特征间的关系参数wij,用辅助向量V来代替求解,可将2阶因子分解机特征向量相互作用模型方程定义如下:
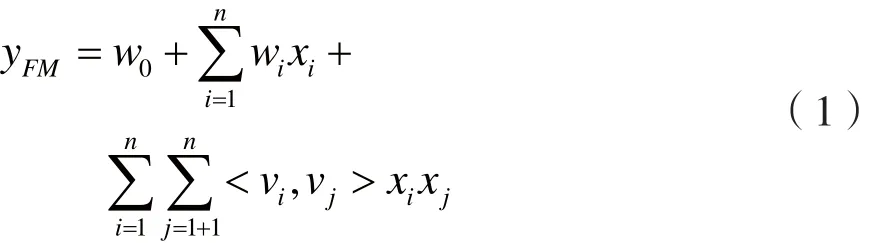
模型中:<.,.>为维度为k的两个特征间的内积,可谓交互权重值。
(1)w0表示全局偏值,w0∈R;
(2)wi表示第i个特征变量的影响程度,W∈Rn;
(3) = < vi, vj>表示模型中第i个变量与第j个变量的交互参数。相对于支持向量机模型中求取每个交互特征参数wij∈R,FM模型中则用分解因子的办法求取其参数值。而这也正是FM对于高阶稀疏数据集能进行很好的参数评估的原因。
总的来说FM建模思想从简单线性模型演变而来,简单的线性函数通过给特征加一阶权重W计算,然而无法学习到特征之间的交互;为了学习特征间的相互性,对xi与xj之间加入二阶项权重值wij,如SVM[12]多项式核函数,但在该多项式模型中,若训练集中未找到xi=1,xj=1,那么wij梯度恒为0,不利于测试集的预测;所以对wij引入了辅助函数V,V∈Rn×k,进行因子分解求解wij,因为没有模型能直接评估出两个特征交互的参数值,所以此处对成对的交互特征参数值计算方法进行重新定义:
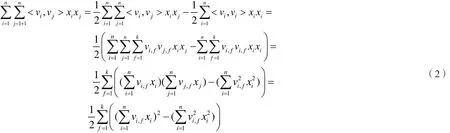
从上式看计算方法时间从O(kn2)变成了仅呈线性复杂度的O(kn),可见FM具有可以在线性时间内计算的闭合方程,所以FM的参数(w0,W,V)可通过随机梯度下降法ALS学习到。算法通过随机梯度方式求解,具体计算细节见ALGORITHM 1,如下:
ALGORITHM 1:Alternating Least-Squares(ALS)
Input: Training data D,regularization parameters λ,Normal distribution variance parameter δ
Output: Model parameters Θ=(w0,W,V)
Initialization: w0:=0; w:=0; v~N(0,δ)
Repeat
FOR i∈ {1,2,…,N} DO


分类阈值算法,加入该算法以实现二分类,假设训练集中属于A分类的有a件,不属于A分类的有b件,则取阈值函数:

当事件xi预测值p>p´时,预测结果属于A分类,反之不属于。TFM(T-Factorization Machine)模型即将FM计算得到的预测结果,与分类阈值结果比较然后归类即可。
1.2 DeepFM模型
DeepFM是2017年Huifeng Guo提出的一种基于神经网络的因子机算法,该方法包含两个部分因子机FM和深度学习Deep,预测结果是两者之和如式(4),FM和Deep共用输入层和嵌入层。FM处理低阶数据,Deep处理高阶数据。

FM的预测表达式yFM,至于深度神经网络yDNN:假设δ表示激活函数,αL、WL、bL分别表示第L层神经网络的输出值、权重和模型偏差,则有α(L+1)=δ(WLαL+bL),以此类推得到深度学习得到的预测值为:

2 实验及结果
实验中我们采用了GTD:全球恐怖主义研究数据库(Global Terrorism Database)数据集S。GTD记录了从1970年至今世界各地的恐怖事件信息,并且不断的更新各种恐怖事件,至今已超过14万恐怖袭击事件,且每一个事件超过45个特征记录值,这使其成为目前是介绍基于恐怖事件的最全面的非机密数据[13]。文章中分别选取了南亚地区A组织、B组织以及C组织所为事件分别打标签得到三个训练集,如表1。并提取2001年至2017年近17年南亚地区未打标签事件为测试集。

表1 恐怖事件组织和标签
2.1 TFM与LR模型对比
LR(Logistic Regression)逻辑回归模型是一个统计过程,用于测量一个或多个预测变量与响应变量之间的多变量线性关系[14],LR主要考虑参数的权重W,常用于线性模型中,W通过最大似然函数求得,且分类阈值为0.5。TFM相对于LR模型来说考虑了特征间的相关性,以及GTD数据稀疏的特点,使得预测模型更准确,结果如表2所示,表2中马修斯系数(Matthews Correlation Coefficient,MCC)同时考虑了被模型预测为负的负样本(True Negative,TN),被模型预测为负的正样本(False Negative,FN),被模型预测为正的正样本(True Positive,TP),被模型预测为正的负样本(False Positive,FP)的四个指标,表达式见式(6),MCC越大分类效果越好;准确率表示预测正确的数占样本数的比例。表中可看出相对于LR模型,TFM准确率和马修斯系数分别提高了0.1%和2%,说明GTD中大多数特征参数和分类变量并非都呈线性关系,低阶(d=2)FM分类模型比线性LR(d=1)效果更佳。


表2 TFM与LR模型比较
2.2 TFM与DeepFM比较
实验得出针对GTD分类,FM略好于LR模型,但介于FM属于(d=2)低阶模型,是否高阶模型(d>2)分类效果更好,此处实验中通过FM与DeepFM实验得到的基尼系数进行比较分析。由图1和图2显示,FM模型相对于DeepFM提前33%的时间基尼系数达到0.8良好情况且最后收敛结果大体一致,可说明没有必要再进行深度学习,只用考虑低维度数据,即只用考虑低阶(d=2)部分即可,所以可分析得到针对GTD的分类低阶(d=2)FM分类模型比高阶(d>2)DeepFM效果更佳。

图1 FM模型基尼系数

图2 DeepFM模型基尼系数
3 结 语
我们强调ML可用于分析恐怖主义数据的特征关系,具有高准确性和快速性。故本文基于GTD数据集,使用Python3.6统计数据,就FM模型与DeepFM模型展开研究。实验结果显示针对GTD数据集的分类问题低阶(d=2)FM分类模型比线性LR(d=1)和高阶DeepFM(d>2)模型效果更佳,所以GTD数据中并非大多数特征参数和分类变量呈线性关系,尽管数据稀疏,也应考虑二阶数据,在实验最后,我们将3组训练集和一个测试集用于TFM模型,其预测结果理想,TFM模型确实有助于我们进行分类操作。GTD分类后的数据可用于更多实验研究,如采用时空扫描方法对一个区域的恐怖袭击事件进行评估预警等,再预警过程中精确地分类数据能使评估预警数据更为准确、可靠等。该模型更广泛的拓展应用待下一步研究。
猜你喜欢
矿产综合利用(2022年2期)2023-01-08
煤田地质与勘探(2021年6期)2022-01-04
矿产勘查(2020年11期)2020-12-25
哈尔滨轴承(2020年1期)2020-11-03
北京航空航天大学学报(2019年9期)2019-10-26
福建基础教育研究(2019年7期)2019-05-28
今传媒(2016年11期)2016-12-19
北京航空航天大学学报(2016年7期)2016-11-16
空间控制技术与应用(2015年3期)2015-06-05
文学教育下半月(2014年5期)2014-07-24
