
基于EmguCV 的智能服务机器人人脸识别系统设计
2019-06-24 02:56范淇元覃羡烘朱培杰
应用科技 2019年3期
范淇元,覃羡烘,朱培杰
1.华南理工大学广州学院机械工程学院,广东广州510800 2.广东理工学院工业自动化系,广东肇庆526100
通过研究分析基于EmguCV的人脸识别技术,将人脸识别技术应用于智能服务机器人,利用Visual Studio2015平台开发出一套智能服务机器人的人脸识别系统,修改程序简化了代码,并添加语音互动系统,提高了人与机器人之间的互动深度和人机交互能力,解决了机器人根据不同人群和对象进行人脸识别,不能对对应的服务项目智能选择的难题,实现服务型机器人的全面智能化转型。
1 系统总体设计
整套智能服务机器人人脸识别系统的设计是在服务型机器人的基本运动系统中增加云端处理、语音交互、视觉模块来实现人脸检测与识别,并对人物做出相对应的服务类型。人脸识别系统组成如图1所示。

图1 系统组成
智能服务机器人在视觉模块可视区域检测到人物存在时,自动进行人脸检测。对于未记录过的人脸信息,可通过语音模块进行图像信息录入,并将信息自动保存到云端服务器。在之后检测到相同人脸信息时,机器人将针对人物的信息与身份自动匹配并进行相关类型服务。
1.1 系统硬件选型
该设计对智能服务机器人的摄像头即图像采集硬件并没有特定需求,本系统可以应用在任意一种具备摄像头并具有WinForm平台的设备中。人脸识别摄像头模块是智能型图像采集模块,该模块具有很强的光线处理能力,能够在强光、逆光、弱光环境中拍摄清晰的图像,并且搭载不同的人脸识别算法[1−2],实现不同光线条件下的精准人脸识别和图像采集,可与第三方软件及应用管理系统紧密结合使用,广泛嵌入VTM、ATM、自动发卡机等自助设备,实现人脸身份认证。本设计并没有采用类似的高级硬件,而是致力于调用普通的摄像头,通过EmguCV直接实现后台的人脸检测与识别。
1.2 人脸识别软件系统设计
人脸识别技术是一种通过对人体脸部的特征信息进行对比识别的技术,即通过摄像设备采集视频流或人脸图像,自动检测和跟踪,进而对检测图像进行后台处理与比对识别的一系列相关技术。人脸识别在实际工作中会受到光照、脸部表情和姿势等因素影响,因此在交互过程中对图像的识别算法进行多条件优化,能大大提高系统的交互性能[3−5]。基于EmguCV的人脸识别系统主要有以下几个部分。
1.2.1 图像采集和处理
图像处理技术包括图像压缩,增强和复原,匹配、叙述和识别3个部分。系统有康耐视系统、图智能系统等,是目前正在逐渐兴起的技术,包括预处理、分割、特征抽取和识别4个模块,针对要完成某一特定的任务,使用特定的图像处理方法达到目标效果。数字图像处理内容如图2所示。

图2 数字图像处理原理
由于检验的光线、角度等因素对人脸检测和人脸识别的影响,需要凸显和细化图像的细节,降低图像的噪点,所以在整个识别过程当中,通常采用图形去噪、灰度变换和均衡化处理等方式来实现。其中,图形去噪采用简易的低通滤波,灰度变换指通过灰度变换将原直方图两端的灰度值分别拉向最小值(0)和最大值(255),使图像占有的灰度等级充满(0~255)的整个区域,从而增加图像层次,达到图像细节增强的目的。均衡化处理是指用于增强局部的对比度而不影响整体的对比度,直方图均衡化通过有效地扩展常用的亮度来实现这种功能。灰度变换代码如下:
Image
gray_image.SmoothBilatral(3,3,3)://采用双边滤波降噪
gray_image._EqualizeHist()://采用直方图均衡化
1.2.2 人脸检测
人脸检测主要采用Adaboost的方法。Adaboost是Boosting分类融合算法的一种,它通过对一些弱的分类器的组合来形成一个强的分类器,从而提高分类算法性能[6−9]。本设计采用Haar分类器,建立Boost筛选式级联分类器,而且是一个监督分类器。先对图像进行直方图均衡化到同样大小,然后标记是否包含被检测物体,人脸通过使用样本的Haar特征对其进行分类器训练得到级联Haar分类器。通过单元测试对XML文件进行识别判断,此方法的实现准确率很高,能够完成识别功能。人脸检测XML文件生成代码如下所示:
String xml_path=Application.StartupPath+“/haarcascade_frontalface_alt.xml”://人 脸 检 测XML文件
CascadeClassifier Face=new CascadeClassifier(faceFileName).
使用EmguCV中的CascadeClassifier类Haar分类器,实现人脸检测功能,检测实现功能准确率约为98%,对于每一张采集的人脸图片素材都进行了训练,识别数据与准确率很高,能够实现识别功能,具体的工作流程如图3所示。
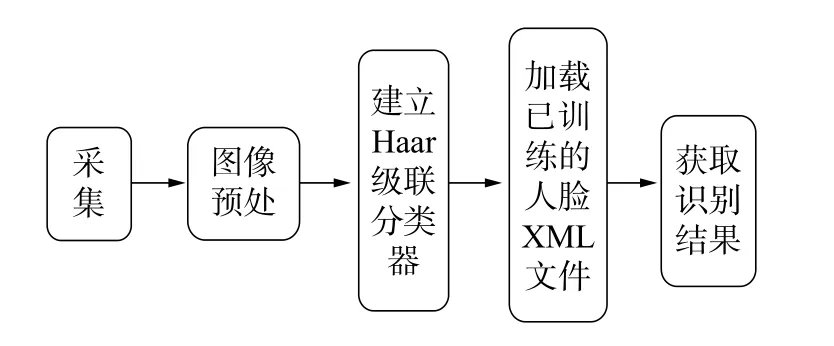
图3 Haar分类器工作流程
1.2.3 人脸识别
人脸识别采用基于线性子空间方法,主要方法有以主成分分析(pricipal component analysis,PCA)和线性判别式分析(linear discriminant analysis,LDA)以及局部二值模式(local binary patterns,LBP)算法。
设计采用LBP算法。LBP是指在像素3×3邻域内的,以邻域中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,如果周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3×3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该邻域中心像素点的LBP值,并用这个值来反映该区域的纹理信息,如图4所示。
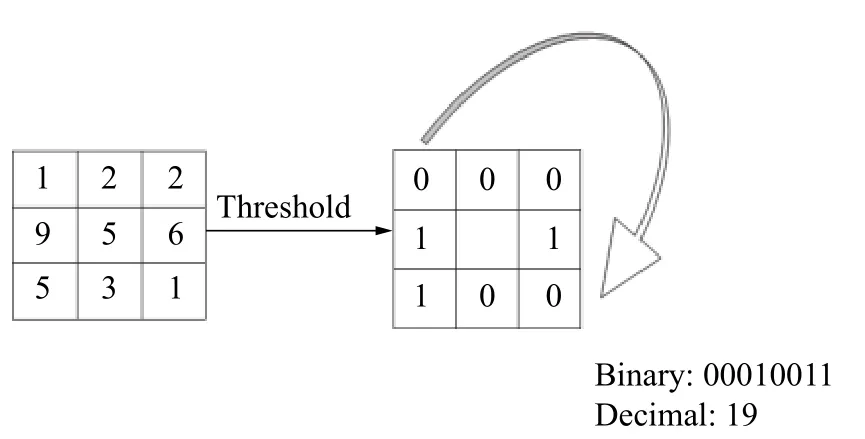
图4 LBP特征提取
用公式来定义:

每个像素都会根据邻域信息得到一个LBP值,以图像形式显示LBP对光照有较强的鲁棒性,如图5所示。

图5 光照下LBP算法的鲁棒性测试
在LBP的应用中,如纹理分析、人脸分析等,LBP图谱一般都不作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
1.2.4 人脸训练及人脸特征提取
通过对每张人脸图像进行编码并且将人脸的相关信息和编号保存起来,模仿机器学习过程。当加载训练模板之后,识别器会主动将人脸信息和人脸图像通过编号逐一关联。检测到的人脸通过识别算法,对训练过的人脸图像中的各个特征点进行评估后,从训练库中选取匹配率最高的人脸图像并输出该图像对应的人脸信息,且此匹配率均达到95%以上。
1)保存人脸图像
在.Net4.0框架下,微软提供了一个System.Drawing.dll的程序集文件,通过使用当中的Image类 的Save(Stream stream,ImageFormat format) 方法,输入保存路径以及保存的图片格式,便可实现图像的保存。其中,format为保存的格式。一般可以选择JPEG、ICON、GIF、PNG、TIFF、WMF以及BMP图标图像。在这里我们选择ImageFormat.JPEG,将BMP图像以JPEG的图像格式保存(见图6)。

图6 保存后的JPEG人脸图像
2)生成XML文件
首先使用System.IO命名空间下的FileStream类的OpenWrite方法,创建IO数据流,然后再对XML文件进行相关的操作。生成XML文件需要用到XmlWriter的WriteStartDocument、WriteStartElement、WriteElementString、WriteEndElement以及WriteEnd-Document这5个方法。至于对XML文件的修改操作则需要使用XmlDocument类中的Save方法以及XmlElement类中的CreateElement方法创建各个根元素和使用AppendChild方法添加根节点。操作完成后必须使用Close方法关闭IO数据流。训练后XML文件内容如下:
-
2 人脸识别系统调试
2.1 调试系统
基于EmguCV的人脸识别系统如图7所示,检测与录入状态如图8、9所示。
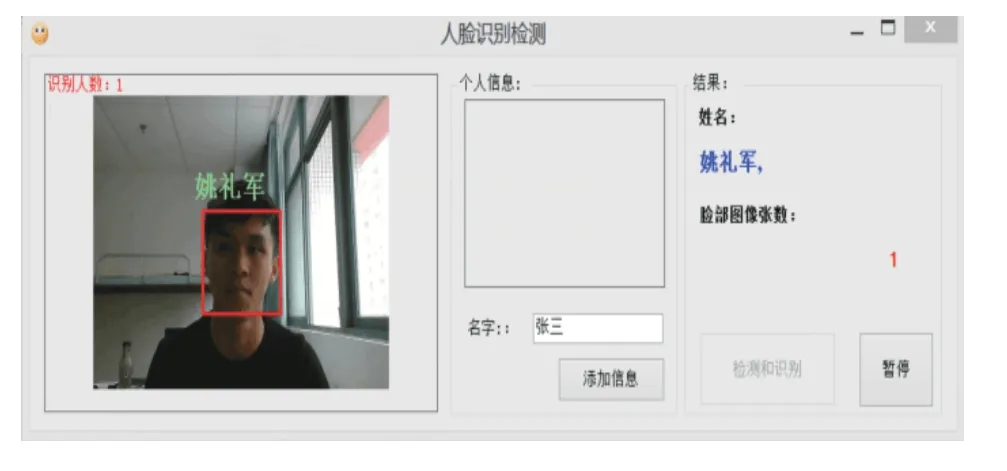
图7 人脸识别检测状态

图8 人脸识别录入状态

图9 系统实测人脸JPEG图像
2.2 系统设计调试训练
EmguCV是.NET平台下对OpenCV(Open Source Computer Vision Library)图像处理库的封装,也就是C#版OpenCV视觉开发包。除此之外,OpenCV还支持在C#、VB、VC++等编译语言下使用开发[10−12]。本设计主要选用C#作为编写程序语言,调用EmguCV里的函数来完成对数字图像的处理以及实现人脸识别。
项目调用EnguCV库函数作为主要检测函数,运行软件,程序自动进入人脸检测环节,对无信息的人脸执行提示功能,仅需添加一次信息,软件会自动多次添加人脸数据,再次检测训练时,检测出人脸信息,调用合成语音函数发出语音欢迎功能,程序支持多人脸同时检测,并有语音读出信息功能。函数训练功能代码如下所示:
if(trainingImages.ToArray().Length!=0)
{
//TermCriteria for face recognition with numbers of trained images like max Iteration MCvTermCriteria termCrit=new MCvTermCriteria(ContTrain,0.001);
//Eigen face recognizer EigenObjectRecognizer recognizer=new EigenObjectRecognizer(
trainingImages.ToArray(),
labels.ToArray(),
5000,
Ref termCrit);
}
Name=recognizer.Recognize(result);
foundPeople[name]=f.rect;
2.3 语音互交功能调试
项目调用SpeechSynthesizer类,提供对已安装的语音合成引擎的功能的访问,实现语音合成播报功能。创建新的SpeechSynthesizer对象时,将使用默认系统语音。配置SpeechSynthesizer时使用其中安装的语音合成(文本到语音),使用Select-Voice或SelectVoiceByHints方法。语音获取安装,使用GetInstalledVoices和VoiceInfo类方法的信息[13−15]。
每次释放对SpeechSynthesizer的最后一个引用前,均应调用Dispose。否则,在垃圾回收器调用SpeechSynthesizer对象的Finalize方法之前,该对象所使用的资源将不会被释放,项目语音代码如下所示:
语音播报
Private void SpeedSound(){
if(string.IsNu110rEmpty(label4.Text))
{
Return;
}
SpeechSynthesizer sp=new SpeechSynthesizer();
if(names==)
{
Thread.Sleep(2500);
if(foundPeople.Count==1)
sp.SpeakAsync(label4.Text+“你好”);
if(foundPeople.Count>1)
sp.SpeakAsync(label4.Text+“你们好”);
}
names==null;
th.Abort();
2.4 设计服务机器人人脸识别系统
本设计基于原有WinFrom平台,对原有的服务机器人(图10)的内置系统进行了改造优化。服务机器人的原有系统是基于C#语言编写,即与EmguCV的使用语言相同,因此将本人脸识别系统直接并入开机程序中,做到机器人开机自动启动识别程序,服务机器人在与不同用户交流时,实时智能识别人物对象身份,自动做出交流互动的主题,并针对不同用户介绍不同的产品,人机对话准确率达到了98%,大大提高了智能化水平。

图10 智能服务机器人
程序自动调用迁入设备的摄像装置,进行图像处理、灰度转换、降噪、均衡化处理等。通过对LBP人脸识别算法的反复实验,发现光照越不均匀,识别器的识别速度越有所下降,但仍具有较高的稳定性和识别率,最终实现多人实时的人脸识别功能,并在智能服务机器人中应用。
对于传统机器人与人脸识别系统的整合设计,需要多方面考虑。人脸识别对用户图像的精准依赖性强,需要机器本身自带较好的摄影摄像头,且关于人脸识别的计算与训练并不会与所有计算流程或传感反馈同步执行,而是以异步形式运行,如图11所示。机器人对于人脸识别训练后,就会对人物开始服务向导,并针对性做出对应的业务场景服务。类似欢迎动作,在检测到人物时会有对应的欢迎动作并播报语音功能,这一系列都是异步处理。且为避免机器人对人的伤害,机器本身都做了传感检测,并将检测级别设为高级,当检测到有人或物品靠近并越过设定的安全距离时,将主动关闭其他正在执行的线程作业。

图11 人脸识别系统
2.5 人脸识别系统训练测试数据(系统识别率)
系统进行训练测试后所得的数据(系统识别率),与常规人脸识别算法所测试的相关数据进行比较,如表1所示。由表中数据可得LBP算法对比其他常规算法而言稳定性较强,且对环境的变化与多人(本实验的测试人数为50人)人脸识别的情况下均能做到很好的支持。
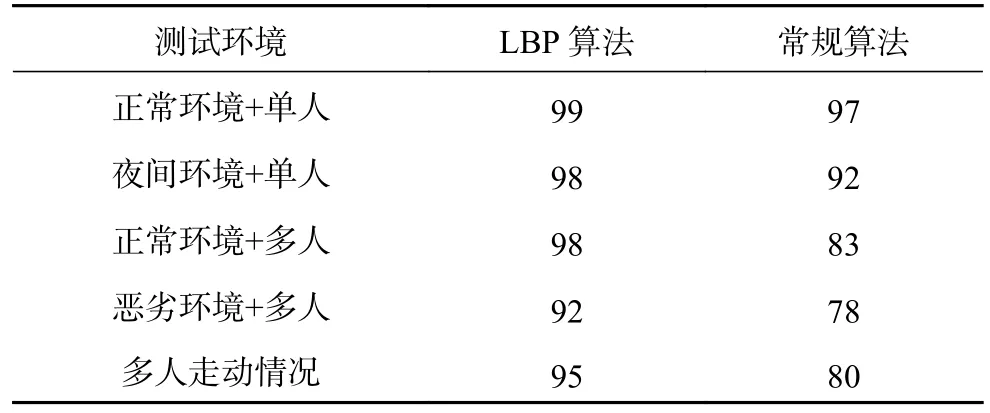
表1 LBP算法与常规算法的系统识别率 %
3 结论
在基于EmguCV的人脸识别方法,包含人脸检测与人脸识别进行了分析研究,通过对LBP人脸识别算法的反复实验,修改编程设计,同时运用Haar特征对图像进行人脸检测处理,设计出基于EmguCV的智能服务机器人人脸识别系统。在本研究中,得出以下结论:
1)对图像进行灰度转换、降噪和图像的均衡化处理,提高了人脸识别能力;
2)简化代码,提高了容错率;添加语音互动系统,提高人机交互能力;
3)对机器设置高级别传感检测,保证了安全距离。
机器人能够直接通过设备调用进行人脸检测,能够在多个环境下应用,对生物特征鉴定技术有一定帮助,对大量同类问题的解决有着相互启发和相互推动的现实意义。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
电子制作(2017年1期)2017-05-17
航天返回与遥感(2014年5期)2014-07-31
