
基于网络爬虫技术的数字资源检测软件的设计与实现
2019-06-20 06:07王思敏尹伊秋宣静雯马冲
现代电子技术 2019年10期
王思敏 尹伊秋 宣静雯 马冲

摘 要: 数字资源受网络状态的影响故障频发,图书馆作为高校信息文化的传播中心,做好资源的保障工作意义重大。文中设计实现一种基于爬虫技术的数字资源自动监测系统。该系统利用日志文件替代数据库软件,降低软件复杂度;利用爬虫技术及正则解析,获取监测URL的状态值和数据库定制名称,监测结果通过邮件自动发送给所有管理员。实验结果表明,该系统具有较好的扩展性能,在任何网络坏境和IP地址下,均能准确进行检测,对运行环境要求低,稳定性好,无需人工操作。
关键词: 数字资源; 自动监测; 网络爬虫; 日志文件; 正则解析; 检测软件
中图分类号: TN919?34; G250 文献标识码: A 文章编号: 1004?373X(2019)10?0132?04
Design and implementation of digital resource detection software based on
web crawler technology
WANG Simin1,2, YIN Yiqiu1, XUAN Jingwen1, MA Chong1
(1. Xian Polytechnic University, Xian 710048, China; 2. School of Electronics and Information, Xian Jiaotong University, Xian 710049, China)
Abstract: Frequent failures occur for digital resources which can be easily affected by network states, and it is of great significance to do the resource protection work well for the library which is the communication center of information culture in university. Therefore, a digital resource automatic monitoring system based on the crawler technology is designed and implemented in this paper. In the system, the database software is substituted for log files to reduce software complexity. The crawler technology and regular parsing are used to obtain and monitor the state values of URL and custom names of database. The monitoring results are automatically sent to all administrators by email. The experimental results show that the system has a good scalable performance, and can conduct detection accurately in any network environment and IP address, which has a low requirement on running environments and good stability, and needs no manual operations.
Keywords: digital resource; automatic monitoring; web crawler; log file; regular parsing; detection software
電子资源由于获取方便、易于检索,已成为教学、科研工作不可或缺的文献来源。在图书馆界,越来越多的图书馆加大了电子资源的采购力度;然而电子资源的访问受用户操作系统、网络传输、数据库商服务器多方面影响,停电、断网、网速过慢、服务器负载过重、宕机等都会造成资源无法访问[1]。在图书馆不断加强数字馆藏建设的同时,也造成了数据库运维人员工作压力的不断增加。个别数据库发生故障,连续数月无法访问却无人发现,这不仅是对资源极大的浪费,同时也降低了用户满意度。因此及时监测电子资源的可访问性,捕捉访问故障,有的放矢地进行维修和维护,是电子资源管理工作的关键[2?3]。
1 电子资源监测的主要方法
1.1 人工监测
人工监测通过人工逐个访问电子资源,手工检索并下载,判断电子资源是否可用。该方法劳动强度大、受管理人员主观因素影响大。笔者所在西安工程大学图书馆,为了规范数字资源管理,在图书馆内抽调了12名图书馆年轻馆员,组建数据库 “周检月报”小组,每周对数据进行抽检,即时排除数据库使用故障。由于人工检测速度慢、效率低,即使一周检查一次,也难以避免假期或工作繁忙时的漏检,不仅费力且效果不佳,不能实现数据库的连续监测。
1.2 监测软件
目前,商业网络监测软件主要有Simple Server Monitor,McAfee Secure,Uptime Software,PA Server Monitor等。国内较为成熟的有聚生网管、SUM等,主要监测远程服务器是否正常运转。商业软件通常价格昂贵,很多高校图书馆选择自行开发[4]。例如,庄纪林结合图书馆网络服务的特点,分析了“远程登录”和“安装代理”类商业化软件不适合数字图书馆网络服务监测的原因,并自行设计开发了“基于内容”的图书馆网络服务监测方案和管理系统[5]。宋磊等设计并实现基于开源软件Nagios的网络服务监控管理系统[6]。彭晓庆使用SNMP及J2EE技术监控电子资源服务器,当服务器假死造成的终端用户无法访问网络以及电子资源时,可自动重启服务器[7]。温晓明使用Python编制软件,通过模拟人机交互等操作对山东大学图书馆OPAC运行状况进行监控[8]。朱玉强采用操作网页文档等方式,模拟真人操作电子资源,以监测各电子资源可否正常提供服务[9]。
以上软件设计大都基于各种网络传输协议、检测服务器端是否运行正常或检查特定的程序。一般都架构在SQL Server或者Access等数据库软件之上,软件功能较完善,但开发难度和技术成本较高,对操作系统及安装配置人员有一定要求[9?10]。而本文介绍的基于网络爬虫技术的数字资源检测软件,用Python语言设计并实现,真正实现了免安装,对操作系统零要求,能够代替人工,定时检测数据库资源的访问情况并将检测结果发送到管理员邮箱,避免了操作软件的麻烦。由于爬虫技术的使用,可以在不用网络坏境和IP地址下,准确对网页进行解析和监测,提高了系统的自适应性和扩展性,便于在图书馆中推广。
2 自动监测系统的架构及流程
2.1 系统总体架构
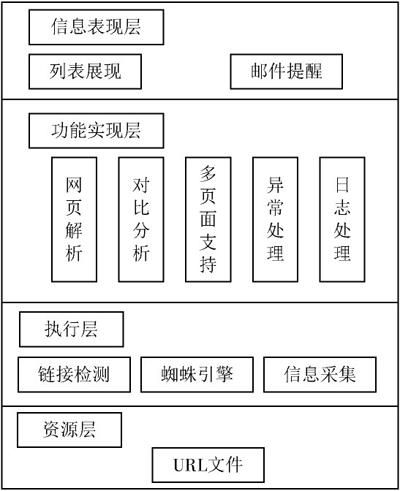
数字资源自动监测系统的总体架构,主要有资源层、执行层、功能实现层和信息表现层。系统架构见图1。
资源层:需要检测的URL地址文件,是资源监测的基础。软件设计利用日志文件系统代替SQL Server,Access等数据库软件存储URL地址信息,使得程序绿色免安装,降低了系统安装和使用的复杂度。
图1 系统架构图
执行层:读取URL地址并逐个发送访问请求,进行链接可用性检测;并利用蜘蛛引擎,自动检索 Web 文档,提取网页的内容。
功能实现层:对爬取的网页内容进行解析,支持多种格式的页面;同时提取有价值的数据,如返回时间、状态、错误代码,对异常情况进行处理,将检测结果生成日志文件并存储。
信息表现层:将检测结果与前一次运行结果日志进行对比分析,对访问异常状态加以提示,并以列表的形式发送至管理员邮箱。
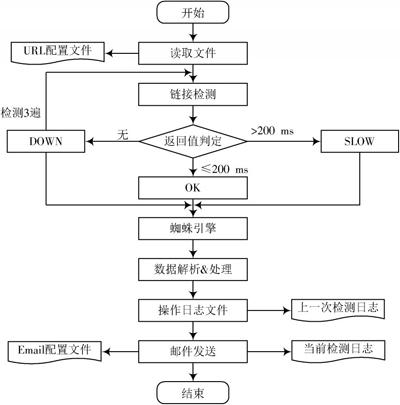
2.2 系统运行流程
可利用Windows自带的定时执行功能每天自动运行程序。运行流程如图2所示。具体运行过程如下:
1) 开始,读取配置文件中的URL地址;
2) 蜘蛛引擎启动,向每个URL地址发送访问请求,检测链接的可用性;
3) 接收HTTP响应信息,根据预先设置的响应时间阈值(200 ms),将访问速度划分为OK(≤200 ms),SLOW(>200 ms),当超过10 s未收到HTTP响应时,重新发送访问请求,3次访问均无响应,视为访问失败,记为DOWN;
4) 网页解析,通过正则表达式,将不同网页格式中的信息,如HTTP返回状态值、返回时间、数据库名称等准确提取出来,对异常情况进行处理;
5) 处理日志文件,更新上一次检测日志和当前检测日志;
6) 数据对比,生成报告,发送至用户邮箱,完成本次检测任务。
3 关键方法与技术
3.1 利用蜘蛛引擎进行链接检测
蜘蛛引擎的基本操作是把URL地址中的网络资源从网络流中提取出来。爬取页面内容时会涉及到HTTP协议返回的响应状态码。当用户向服务器发送请求,如能成功地獲取请求的资源,返回状态码“200”;如请求的资源不存在,通常返回“404”错误。
图2 系统流程图
网络爬虫运行过程中,需要进一步对复杂的HTML页面进行解析,才能提取出有用的信息。HTML编码格式很多,利用正则表达式来解析和限定不同编码格式下抓取的内容。
url=′http://cssci.nju.edu.cn/′ //检测URL地址
try: headers = {′User?Agent′ : ′Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) //使用代理,隐藏爬虫程序的身份,避免
一些网站拒绝被爬虫程序访问
′Accept′: ′text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8′,′Accept?Encoding′ : ′gzip′}
//服务器向支持gzip的浏览器返回gzip编码的HTML页面, 该编码方式可减少0.1~0.2的下载时间
begin_time=str(time.time()) //记录开始时间
r = requests.Session.get(url,headers = headers,timeout=10)
//用蜘蛛引擎抓取网页内容,timeout为响应超时字段,设置为10 s
end_time = str(time.time()) //记录结束时间
if r.status_code == 200: //获取HTTP返回状态,返回值
“200”表示服务器已成功处理了请求
soup = BeautifulSoup(text, parseOnlyThese=strainer, fromEncoding="gb18030") //网页内容解析
title = get_title(soup) //获取URL对应的数据库真实名称
else: return str(404),begin_time,begin_time,"unknow"
//服务器未成功处理了请求
return r.status_code,begin_time,end_time,data[′title′]
//检测完毕,返回HTTP状态码,开始时间,结束时间,URL名称
3.2 日志文件处理
软件运行过程中会生成4个日志文件。sitemonitor.previous.status记录前一次检测结果,sitemonitor.current.status记录本次检测结果,report.txt在对比前两次检测结果的基础上生成检测报告。为了便于用户阅读检测报告,系统另外生成了HTML类型的report文件,将不同检测结果(OK,SLOW,DOWN)分类显示,以邮件形式发送给用户。以下为部分生成report.txt文件的代码。
filepath=′report.txt′ //日志文件名称
filepath=os.path.join(basedir, filepath) //存储路径
with open(filepath, ′w′) as f: //生成检测报告,记录本次
检测操作的开始和结束时间
f.write(′Start date : %s\n′ % start_process_date_str)
f.write(′End date : %s\n′ % end_process_date_str)
for status in [STATUS_DOWN, STATUS_SLOW, STATUS_OK]:
//URL检测结果逐条写入日志
′Previous status : %s : Previous HTTP code : %s\n′
//读取前一次检测结果和响应状态
f.write(line_text % (host[′website′],host[′webtitle′],host[′response_time′],host[′http_code′], host[′previous_status′], host[′previous_http_code′]))
//在日志文件中写入URL地址、URL名称、响应时间、HTTP
返回值、上一次响应状态(OK,SLOW,DOWM)、HTTP返回值
send_report_by_mail(True) //发送邮件
4 测试效果
为了测试软件性能,在不同网络環境下进行了实地测试。将软件拷贝至电脑的任意位置,甚至在U盘中,均可以流畅运行,对电脑配置无要求。运行时间在4 min 30 s左右。
1) 链接检测准确。从软件运行6个月的总体情况来看,整体检测正确率100%。系统设置的检测URL地址为73个,95%数据库检测结果为OK或者SLOW,5%数据库为DOWN。当检测结果为OK和SLOW时,表明电子资源可用,系统记录HTTP的响应时间和状态码;检测结果为DOWN时,电子资源无法访问,或者HTTP返回速度过慢(超过10 s),超出规定的响应时间上限。
2) 扩展性测试。软件在西安工程大学和西安交通大学网络环境中,均准能抓取到URL链接所对应的数据库名称,并能够根据IP地址变化准确解析出相应的定制数据库名称。例如网址http://www.duxiu.com,在两所院校中运行结果分别为:西安工程大学学术搜索和西安交通大学学术搜索。软件在不同网络环境下无需配置,便可准确运行。运行结果见图3、图4。
另外,为便于区分网络故障和数据库自身故障,检测时引入若干大型门户网站,如Baidu和Sina等,当故障发生时,可通过观察门户网站是否能正常访问,来判断数据库故障是本校网络自身故障还是数据库商故障,以便有的放矢地寻求解决办法。当然计算机并非万能,仅仅通过软件进行检测,并不能完全说服。将计算机技术和人工抽检结合起来,可以达到事半功倍的效果。以笔者所在西安工程大学为例,图书馆数据库管理员人工对于出现故障的几个数据库进行截图、留存,并及时向数据库商反馈。通过这种方式,在2017年成功地跟数据库商进行谈判,抵制了某外文数据库的涨价要求。
图3 在西安工程大学运行结果(部分)
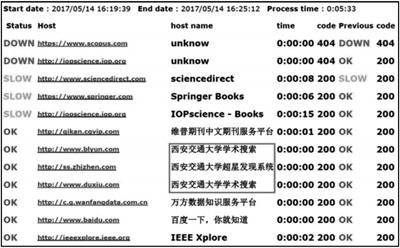
图4 在西安交通大学运行结果(部分)
5 结 语
本文设计基于网络爬虫技术的数字资源链接监测软件,可以每日定时执行,365天记录数据库全年整体运行情况,将数据库管理人员从繁重的工作中解脱出来,还可以提高读者满意度,提升服务水平,必要时也是跟数据库商谈判、维护自身权益的有效工具。
参考文献
[1] 叶兰.电子资源管理系统实施与应用研究[J].图书情报工作,2012,56(13):89?94.
YE Lan. Planning and implementing an electronic resource management system [J]. Library and information service, 2012, 56(13): 89?94.
[2] 史克红.图书馆数字资源访问监控系统的设计与实现[J].图书馆理论与实践,2016(7):93?96.
SHI Kehong. The design and implementation of library digital resource evaluation system [J]. Library theory and practice, 2016(7): 93?96.
[3] 陈涛.网络服务性能监测系统设计与实现[J].现代电子技术,2010,33(10):133?135.
CHEN Tao. Design and implementation of network service performance monitoring system [J]. Modern electronics technique, 2010, 33(10): 133?135.
[4] 龙净林.评价与发挥高校数字图书馆数字资源服务能力研究[J].图书馆理论与实践,2016(12):101?104.
LONG Jinglin. Evaluation and exertion of digital resources service ability of university digital library [J]. Library theory and practice, 2016(12): 101?104.
[5] 庄纪林.数字图书馆网络服务的监测[J].大学图书馆学报,2008,26(3):38?42.
ZHUANG Jilin. The monitoring of network service in digital library [J]. Journal of academic libraries, 2008, 26(3): 38?42.
[6] 宋磊,王静文.OpenBSD下基于Nagios的网络服务监控报警系统的研究[J].电脑编程技巧与维护,2009(14):112?113.
SONG Lei, WANG Jingwen. Research of network services monitor & alarm system based on Nagios under OpenBSD [J]. Computer programming skills & maintenance, 2009(14):112?113.
[7] 彭晓庆.高校图书馆电子资源服务监控系统设计与实现[J].现代图书情报技术,2011,27(4):82?88.
PENG Xiaoqing. Design and realization of the library electronic resources service monitoring system [J]. New technology of library and information service, 2011, 27(4): 82?88.
[8] 温晓明.基于Python的电子资源可用性检测方案[J].中华医学图书情报杂志,2013,22(1):68?71.
WEN Xiaoming. Python?based detection plan for accessible electronic resources [J]. Chinese journal of medical library and information science, 2013, 22(1): 68?71.
[9] 朱玉强.图书馆电子资源可否浏览及下载监测程序设计[J].现代图书情报技术,2013,29(11):86?90.
ZHU Yuqiang. Design of monitoring program to detect the browsable and downloadable status of library′s electronic resources [J]. New technology of library and information service, 2013, 29(11): 86?90.
[10] 张昕,孙江辉.舆情监测系统设计[J].现代电子技术,2015,38(11):98?102.
ZHANG Xin, SUN Jianghui. Design of public opinion monitoring system [J]. Modern electronics technique, 2015, 38(11): 98?102.
猜你喜欢
中国新通信(2016年21期)2017-01-06
数字技术与应用(2016年9期)2016-11-09
知音励志·社科版(2016年9期)2016-11-09
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
出版广角(2016年4期)2016-04-20
江苏农业科学(2016年2期)2016-04-11
科教导刊·电子版(2016年3期)2016-03-14
科技资讯(2015年19期)2015-10-09
