
不同维度下维吾尔语N?gram语言模型性能分析
2019-06-20 06:07毛丽旦尼加提古丽尼尕尔买合木提艾斯卡尔艾木都拉
现代电子技术 2019年10期
毛丽旦?尼加提 古丽尼尕尔?买合木提 艾斯卡尔?艾木都拉

摘 要: 针对当前维吾尔语语言模型存在的语料库数据稀疏问题以及困惑度较高等问题,在SRILM和MITLM两种工具生成的2?gram,3?gram,…,9?gram语言模型做了对比实验,试图找出在一定规模的维吾尔语语料条件下使困惑度最低的N?gram语言模型。通过对比分析最终得出结论,对于基于维吾尔语句子的N?gram模型,维度N取在介于3~5之间较宜,困惑度和计算复杂度等因素考虑N=3为较优。这一结论将有助于维吾尔语自然语言处理的发展。
关键词: N?gram语言模型; 性能分析; SRILM; MITLM; 困惑度; 平滑算法; 机器翻译
中图分类号: TN912.34?34; TP391.1 文献标识码: A 文章编号: 1004?373X(2019)10?0027?04
Performance analysis of Uyghur N?gram language models in different dimensions
Mewlude Nijat1, Gulnigar Mahmut2, Askar Hamdulla2
(1. School of Software Engineering, Xinjiang University, Urumqi 830046, China;
2. School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China)
Abstract: In allusion to the problems of sparse corpus data and high perplexity degree of the current Uyghur language models, a contrast experiment was carried out for the 2?gram, 3?gram, 4?gram,…, and 9?gram language models generated by the SRILM and MITLM tools, so as to find out the N?gram language model with the lowest perplexity degree under a certain scale of Uyghur corpus. It is concluded from the contrastive analysis that it is better to determine the value of the dimension N between 3 and 5 for the N?gram model based on Uyghur sentences, and N=3 is more appropriate considering the factors of confusion degree and computation complexity. The conclusion can contribute to the development of Uyghur natural language processing.
Keywords: N?gram language model; performance analysis; SRILM; MITLM; perplexity; smoothing algorithm; machine translation
语言模型(LM)在自然语言处理中占据重要的位置,用于自然语言处理,主要描述自然语言中的统计和结构方面的内在规律,是根据特定语言的客观事实而进行的语言抽象数学模型。近年来,语言模型在基于统计模型的语音识别、机器翻译、拼写纠错、词性标注、印刷体或手写体识别、句法分析和拼写错误等相关的自然语言处理研究工作中广泛应用。维吾尔语语言模型是维吾尔语自然语言处理技术的重要基石,因此对维吾尔语自然语言处理系统来说,构建一个可靠的语言模型具有重要意义。目前流行的语言模型是N元语法模型(N?gram Model)[1],此模型作为统计语言处理的主流技术已被广泛应用于自然语言处理应用中。本文针对当前维吾尔语自然语言处理过程中存在的语料库资源匮乏、数据稀疏等问题,试图找出使困惑度较低的语言模型,分别用SRILM和MITLM两个语言模型工具生成模型,从对困惑度的度量出发,对2?gram,3?gram,…,9?gram模型的结果进行综合比较和分析,进而确定基于维吾尔语句子的N?gram模型中较佳的N值。
1 N?gram语言模型与度量标准
1.1 N?gram语言模型
N?gram语言模型元语言模型是生成模型的典型代表。为了估计一个句子的概率,将句子的生成过程假设为一个马尔可夫过程。马尔可夫假设某一词的出现概率由该词前面的一个单词所决定,前一个词对这一词的转移概率可以采用极大似然估计来获得,基于这些转移概率,利用链式法则就可以直接估计一个句子的概率[2]。
1.2 度量标准
根据模型计算的测试数据的概率是评价一个语言模型最常用的度量,用于评价N?gram模型的最常用的指标是交叉熵(Cross?entropy)和困惑度(Perplexity) [3]。
1.2.1 交叉熵
交叉熵是用于衡量估计模型和概率分布之间的差异的概念。如果一个随机变量q(x)用于近似p(x)的概率分布,那么随机变量x和模型q之间的交叉熵定义为:
[HX,q=HX+Dpq=-xp(x)log2 q(x) =Eplog21q(x)]
由此,可以定义语言[L=Xi~px]与其模型q的交叉熵为:
[H(L,q)=-limn→∞1nxn1p(xn1)log2 q(xn1)]
式中:[H(L,q)]表示L的语句;q(x)表示估计模型。因为无法从有限的数据中获取真实模型的概率,所以需要做出一个假设:假定L是遍历的随机过程,即当n无穷大时,所有句子的概率和为1。
[H(L,q)=-limn→∞1n log2 qxn1≈-1nlog2 qxn1]
交叉熵与模型测试语料中分配给每个单词的平均概率所表达的含义正好相反,模型的交叉熵越小,模型的表现越好[1]。
1.2.2 困惑度
通常用困惑度来代替交叉熵衡量语言模型的好坏。给定语言L的样本,L的困惑度[ppq]定义为:
[ppq=2HL,q≈2-1nlog2qln1=qln1-1n]
式中,困惑度的概率函数正比于由语言模型产生测试数据的log似然的负值。在交叉熵上的一个递减函数即是困惑度。语言模型在测试语料的似然度越大,困惑度越小,语言模型对这种语言的拟合也就越成功,模型对测试语料的拟合能力越强[1]。语言模型设计的任務就是寻找困惑度最小的模型。
在实际应用中使用最多的是三元语言模型,更高阶的语言模型使用很少。N取小有两个方面的原因:一是,模型大小(或者是空间复杂度)几乎是以语料库大小为底,N为指数的指数函数;二是,使用N元模型的速度(或者时间复杂度)也是一个指数函数。因此N不能很大,当N在1~3时,模型的效果上升明显,N值从4开始效果提升不是很明显,但资源的耗费却增加得非常快[4]。
2 维吾尔语形态特性与平滑算法
维吾尔语是黏着性语言,共有32个字母,包括8个元音字母和24个辅音字母。每个字母按照出现在单词中的词首、词中、词尾的位置不同会有不同的写法。32个字母一共有126种书写形式。词法形态变化丰富是维吾尔语的特点。维吾尔语的构词、构形都是通过在词干后面连接不同的词尾来实现的且可以不断的缀接 [5],理论上可以构成无限大的词表,由此也就会产生数据稀疏问题。就维吾尔语这一类黏着性语言而言,存在很大的数据稀疏问题,导致最大似然估计(MLE)对该语言而言不再是一种很好的参数估计方法。对于N?gram语言模型,训练数据稀疏会导致两种错误的概率评估:小概率的事件和零概率事件。采取平滑技术是解决数据稀疏问题的主要方法。数据平滑技术(Smoothing)主要采用最大似然规则的概率估计进行调整,保证语言模型任何概率都不是零,并且使得模型参数概率分布的趋向更加均匀合理。该技术较低的概率被调高,较高的概率被调低。
数据平滑的基本思想是:训练样本中出现过的事件的概率适当减小,将减小得到的概率密度分配给训练语料中没有出现过的事件。这个过程称为数据平滑(datasmooting),也称为折扣(discounting)。本文采用的语言模型生成工具中用到的平滑算法有:Witten?Bell 平滑和修正的Kneser?Ney(ModKN)[3]。ModKN算法具有以下的特点:ModKN使用的方法是插值方法,而不是后备方法,对于出现次数较低的N元语法采用不同的减值,实现了基于留存(held?out)数据进行减值估计,而不是基于训练数据的对比试验。在该对比试验中发现,修正的ModKN平滑算法比其他的平滑算法效果要好得多[6]。
3 实 验
3.1 数据准备
自然语言处理的前提工作是构建一个高质量的语料库,它是建立语言模型非常重要的一个步骤,语料库质量的优劣直接影响到语言模型的性能。本文收集的维吾尔语料主要来自维吾尔语版本的《新疆日报》,《人与自然》,《世界》和《世界周刊》节目台词等官方提供的较高质量的维吾尔语语料。语料的预处理主要包括原始数据分段、段落分句、内容筛选、统一文件格式保存、特殊处理特殊符号、数字替换、编码转写(阿拉伯文格式转换为拉丁文格式)等。最终建立的语料为26万个维吾尔语句子,将整个语料库分成了两个部分,分别为训练集(Training Data)、验证集(Validation Data)和测试集(Test Data)。其中训练语料用于N?gram语言模型的训练;2 500句作为验证集,用于在MITLM模型中powell方法来进行参数优化;2 500句作为测试语料,对模型进行测试。训练集规模255 048 sentences,5 306 368 words,测试集规模2 500 sentences,52 630 words,验证集规模2 500 sentences,51 384 words。
3.2 实验工具
1) SRILM
SRILM是著名的约翰霍普金斯夏季研讨会的产物,由SRI实验室负责开发维护。它是一个生成和使用统计语言模型的工具包,广泛应用于语音识别、机器翻译等自然语言处理领域。将经过分词及预处理过的单语料文本作为它的输入数据,输出数据为输入数据中的N?gram文法概率[7]。SRILM的主要目标是支持语言模型的估计和评测。训练数据中得到一个模型称之为模型估计,评测则是计算测试集的困惑度。支持的平滑算法包括Good?Turing平滑、Absolute平滑、Witten?Bell 平滑和Modified Knerser?Ney 平滑等常用的平滑算法。
2) MITLM
麻省理工学院语言建模工具包MITLM是用于有效估计涉及迭代参数估计的统计N?gram语言模型的工具。除标准语言建模估计外,还可以使用smoothing参数指定不同的平滑算法支持调整平滑、插值和N?gram加权参数。支持的平滑算法包括Good?Turing平滑,Absolute 平滑、Witten?Bell 平滑和Modified Knerser?Ney 平滑等常用的平滑算法。默认情况下,MITLM使用修改的Modified Knerser?Ney平滑(ModKN)。除了支持常规的ModKN平滑外,Powell优化算法还采用validation集合对生成的模型参数进行再次调整,数值优化,最终得出更优的结果。
3.3 实验结果与分析
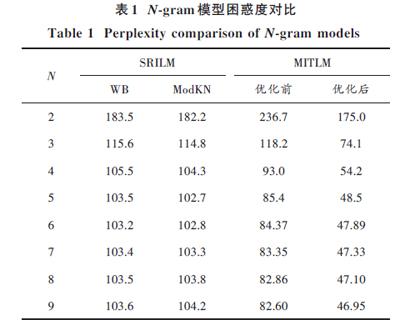
实验一:用SRILM和MITLM两个工具,分别生成2?gram,3?gram,4?gram,…,9?gram语言模型,并对困惑都进行对比。实验二:将本实验得到的语言模型在文献[8]中的汉维统计机器翻译系统中进行测试。测试实验中在原来目标语言语料中作为额外语料加入本文中的26万句维吾尔语语料,用SRILM工具ModKN平滑算法分别生成3?gram,4?gram和5?gram语言模型,进行翻译BLEU值对比。结果如表1、表2所示。
实验一结果分析:在SRILM中,默认的Witten?Bell 平滑算法得出的语言模型困惑度比ModKN平滑算法得出的模型的困惑度要高;同样采用ModKN平滑算法的情况下,MITLM优化前的困惑度比SRILM的困惑度要低;MITLM用Powell优化之后困惑度又明显下降。无论用SRILM还是MITLM得到的语言模型,从1~3元模型困惑度有大幅度降低,但從3~5元模型困惑度虽然有逐步降低,但降低幅度较小;从5~9元模型困惑度基本平稳。
表1 N?gram模型困惑度对比
表2 5?gram模型在统计机器翻译中BLEU值对比
实验二结果分析:在3~5元语言模型中,采用5元语言模型的统计机器翻译BLEU值较高,但相差不大,这也跟语言模型困惑度从3元模型开始困惑度变化幅度小有关。
4 结 语
本文从对困惑度的度量出发,综合比较和分析了基于维吾尔语句子的N?gram模型中N值的选择。实验结果表明,随着N值的增加,语言模型性能的增加不是正比的关系,而是随着N的增大逐渐出现平稳趋势。将对2?gram,3?gram,4?gram,…,9?gram模型的结果进行对比,并得出结论:对于基于维吾尔语句子的N?gram模型,从模型困惑度和计算时间复杂度等多方面考虑,N的取值范围应介于3~5之间,N=3为较优。所以最后得出结论:在N?gram维吾尔语语言模型及其几种平滑算法的试验中,虽然Powell方法优化之后的ModKN平滑算法得到的5?gram以及较高阶的语言模型的效果在维吾尔语N?gram模型中表现比较良好,但考虑到资源消耗和效果增加不明显的原因,选择使用3?gram语言模型。
参考文献
[1] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013.
ZONG Chengqing. Statistical natural language processing [M]. Beijing: Tsinghua University Press, 2013.
[2] 李春生.一种体现长距离依赖关系的语言模型[J].科技视界,2014(5):55?56.
LI Chunsheng. A language model reflecting long?distance dependence relation [J]. Science & technology vision, 2014(5): 55?56.
[3] 文娟.统计语言模型的研究与应用[D].北京:北京邮电大学,2010.
WEN Juan. Research and application of statistical language model [D]. Beijing: Beijing University of Posts and Telecommunications, 2010.
[4] 吴军.数学之美[M].北京:人民邮电出版社,2012.
WU Jun. Beauty of mathematics [M]. Beijing: Posts & Telecom Press, 2012.
[5] 王贺福.统计语言模型应用与研究[D].上海:复旦大学,2012.
WANG Hefu. Application and research of statistical language model [D]. Shanghai: Fudan University, 2012.
[6] 张亚军.维吾尔语的N?gram语言模型及其平滑算法研究[D].乌鲁木齐:新疆大学,2010.
ZHANG Yajun. Research of Uyghur N?gram model and smoothing algorithm [D]. Urumqi: Xinjiang University, 2010.
[7] 唐亮.维吾尔语统计语言模型中建模基元的研究[D].成都:电子科技大学,2013.
TANG Liang. Research on modeling primitives in Uyghur language statistical language model [D]. Chengdu: University of Electronic Science and Technology of China, 2013.
[8] MAHMUT G, NIJAT M, MEMET R, et al. Exploration of Chinese?Uyghur neural machine translation [C]// Proceedings of International Conference on Asian Language Processing. [S.l.: s.n.], 2017: 176?179.
[9] 张亚军.维吾尔语的N?gram语言模型研究[J].电脑知识与技术,2011,7(17):4177?4179.
ZHANG Yajun. Research of Uyghur N?gram model [J]. Computer knowledge and technology, 2011, 7(17): 4177?4179.
[10] 古丽尼尕尔·买合木提,热木土拉·买买提,毛丽旦·尼加提,等.基于双语对话文本的汉、维口语翻译技术研究[C]//第十四届全国人机语音通讯学术会议论文集.连云港:中国中文信息学会语音信息专业委员会,2017:490?494.
Gulnigar Mahmut, Multura Maimaiti, Mewlude Nijat, et al. Research on Chinese?Uyghur oral translation technology based on bilingual dialogue texts [C]// Proceedings of the 14th National Conference on Man?machine Speech Communication. Lianyungang: Speech Information Specialty Committee of Chinese Information Processing Society of China, 2017: 490?494.
[11] 努尔艾力·喀迪尔,彭良瑞.基于SRILM的阿拉伯和维吾尔文语言模型建立方法[C]//第三届全国少数民族青年自然语言信息处理、第二届全国多语言知识库建设联合学术研讨会论文集.乌鲁木齐:中国中文信息学会,2010:94?97.
Nurali Kadir, PENG Liangrui. A method to build Arabic and Uyghur language model based on SRILM [C]// Proceedings of the Third National Minority Youth Natural Language Information Processing and the Second National Multilingual Knowledge Base Construction Joint Academic Seminar. Urumqi: Chinese Information Processing Society of China, 2010: 94?97.
[12] ZHANG Wenyang. Comparing the effect of smoothing and N?gram order: finding the best way to combine the smoothing and order of N?gram [D]. Melbourne: Florida Institute of Technology, 2015.
[13] SADIQUI A, ZINEDINE A. A new method to construct a statistical model for Arabic language [C]// Proceedings of the Third IEEE International Colloquium in Information Science and Technology. Tetouan: IEEE, 2015: 296?299.
[14] ALUM?E T, KURIMO M. Efficient estimation of maximum entropy language models with N?gram features: an SRILM extension [C]// Proceedings of the 11th Annual Conference of the International Speech Communication Association. Chiba: [s.n.], 2010: 1820?1823.
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25
自动化学报(2017年4期)2017-06-15
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年4期)2015-07-18
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
语言与翻译(2014年3期)2014-07-12
外语教学理论与实践(2014年2期)2014-06-21
