
基于多隐层Gibbs采样的深度信念网络训练方法
2019-06-11 06:42:50史科陆阳刘广亮毕翔王辉
自动化学报 2019年5期
史科 陆阳 刘广亮 毕翔 王辉
在机器学习领域里,最重要也是最困难的莫过于特征的提取,抓住事物区分度强的特征也就抓住了事物的本质.在此基础上,分类器的性能会得到极大的提高.但长期以来如何进行特征提取一直是个棘手的问题,不同领域的数据涉及到不同的提取方法,需要大量的领域知识作为支撑.另一方面,一直以来各种深度神经网络模型都困扰在如何找到有效的训练方法.传统的反向传播算法在多隐层神经网络上存在着梯度消失的问题,使得深度网络的性能甚至还不如浅层网络[1].这两个关键问题在2006年Hinton提出的文献[2]中得到了很大程度上的解决.在文献[2]中提出的多层限制玻尔兹曼机(Restrict Boltzmann machine,RBM)堆叠降维的方法,在无监督的情况下实现了自动化的特征学习,实验表明效果比传统的PCA方法要好得多.在此基础上增加分类器就构成了深度信念网络模型(Deep belief network,DBN).作为一种生成模型,DBN有着重要的研究价值.相对于判别式模型,生成模型可以反向生成研究对象的实例,可以直观地观察出生成对象的各种特征,为进一步的研究提供可能.在随后的大量研究中,DBN被广泛应用到了图像识别[3−4]、语音识别[5]、自然语言处理[6]、控制[7]等多个领域,并取得了很好的效果.
针对DBN训练方法的研究一直是一个热点[8−9].Goh等[10]提出了一种有监督的预训练方法,提高了DBN的精度.李飞等[11]从Gibbs采样的次数入手,提出了动态的采样方法,乔俊飞等[12]将自适应学习率引入到对比散度(Contrastive divergence,CD)算法中,提高了算法收敛速度.典型的DBN的训练分为2个阶段[13],分别是逐层预训练和整体精调.在逐层预训练阶段,从网络最底层的RBM开始,自底向上逐层使用无监督的贪婪方法来使得每层RBM的损失误差最小.然后在整体精调阶段使用有监督的学习方法,针对有标签的数据使用梯度下降进行整体权值修正.实验表明此种方法是有效的,很好地解决了一直以来深度网络无法有效训练的难题.逐层预训练将网络的权重调整到一个“合适”的初始位置,如果不进行逐层预训练而直接进行整体精调,则网络很难收敛,在逐层预训练的基础上进行整体精调可以确保网络能够收敛到很好的位置上.在此基础上,网络权重的初始位置有没有进一步改进的可能,从而获得更好的网络性能呢?DBN的逐层预训练是在堆叠着的每个RBM内进行多步Gibbs采样来逼近数据的真实分布的,采样在RBM的可视层和隐藏层之间迭代进行.本文在此基础上,提出了一种两阶段的无监督预训练方法,在已有预训练的基础上引入多隐层Gibbs采样预训练方法,将多个RBM 组合成一个整体概率模型进行预训练,使得Gibbs采样在多个RBM中进行,从而获得更“合适”的网络权值初始位置.在MNIST、ShapeSet和Cifar10数据集上的实验表明,此种方法比传统的深度信念网络训练方法可以获得更好的分类效果,在包含(1300,1300,1300,1300)四层隐层的DBN上使用固定学习率的实验,相对于传统方法的可以将MNIST的错误率从1.25%降低到1.09%.
本文先介绍了受限玻尔兹曼机和深度信念网络模型,然后提出了改进后的算法,最后在MNIST、ShapeSet和Cifar10数据集上验证并讨论了实验结果.
1 受限玻尔兹曼机模型
DBN的预训练是通过受限玻尔兹曼机的训练进行的,所以我们先描述RBM模型.RBM是一个无向图模型,它可以被看做是一个二部图(Bipartite graph),两个部分分别是可视层v和隐层h,层间结点全连接,层内结点不连接,如图1所示.可视层接收数据输入,两层间的连接权值用W表示,W∈Rn×m.可视层的偏置用a表示,a∈Rn,隐层的偏置用bb表示,b∈Rm.RBM的隐层可以理解为模型中尚未被观测到的部分,可视层可以理解为可以观测到的部分,它们的节点状态一般是二进制的,取值1或0.
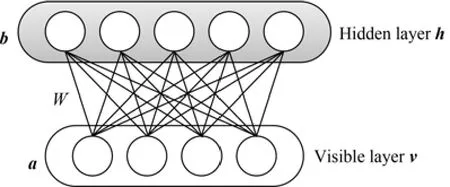
图1 RBM模型Fig.1 Restricted Boltzmann machine
RBM是能量模型系统,它通过能量来表示系统当前的状态,能量定义为[2]:
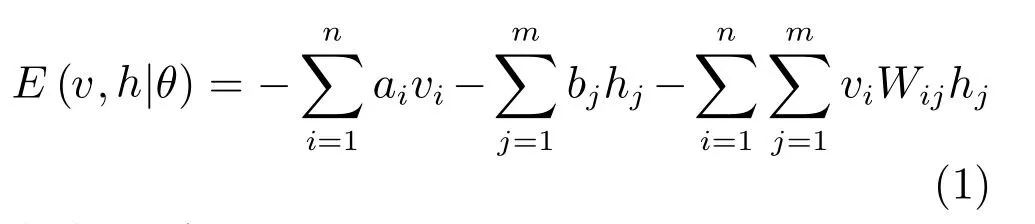
其中,n表示可视层的节点数目,m表示隐藏层节点数目,就表示可视层i节点到隐层j节点的权值大小.使用θ={W,a,b}表示系统所有参数的集合.
给定了能量定义,就可以在此基础上定义系统整体的概率分布[2]:
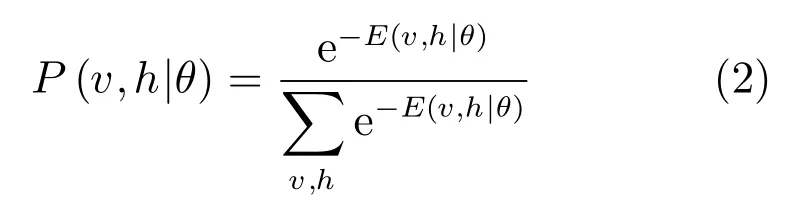
其中,分母部分称之为归一化因子或配分函数(Partition function),使得系统概率取值在[0,1]范围内,一般用表示.
RBM的结构决定了隐层和可见层是相互条件独立的,于是可以得到条件概率分布[14]:
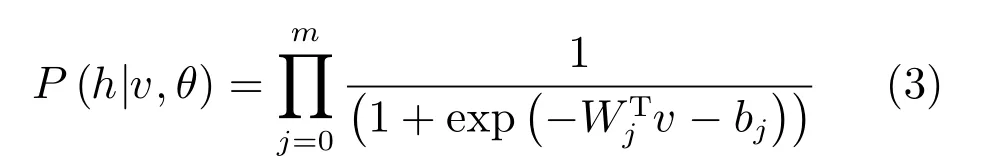
以及
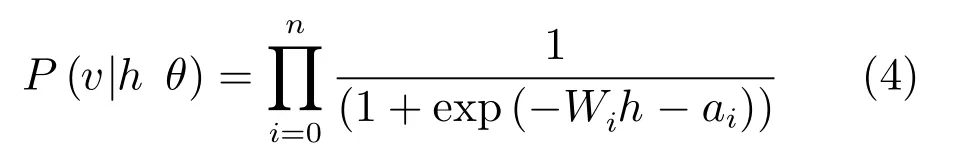
RBM的训练就是依据训练样本来估计模型的参数,使得此模型的推断数据尽可能地接近真实数据.由式(2)可得边缘概率分布,通过使用最大似然的方法来估计,对其对数求导数有[1]:
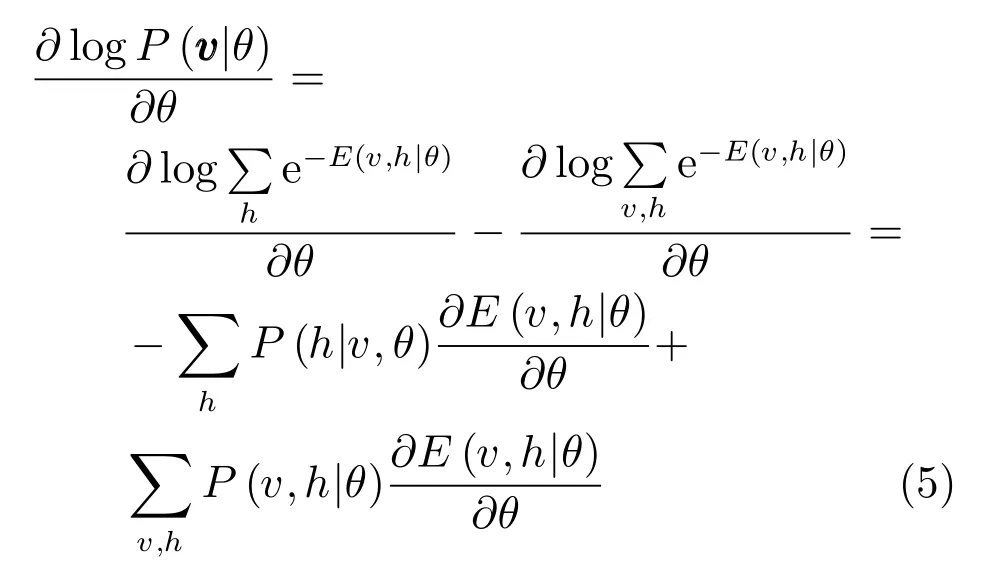
对于训练样本,使用 “data”表示分布P(h|v,θ), 使用 “model”表示分布P(v,h|θ). 其中,使用表示关于分布p的数学期望.因为,联合式(1)的导数,式(5)可表示为[1]:
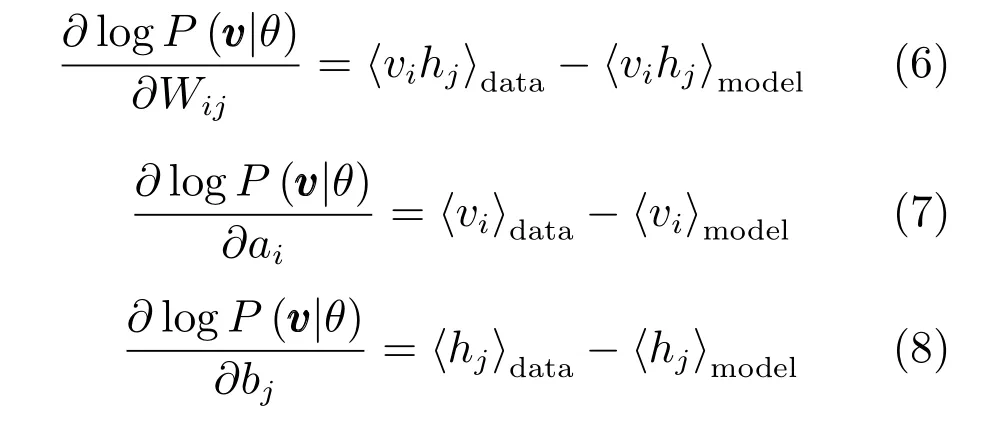
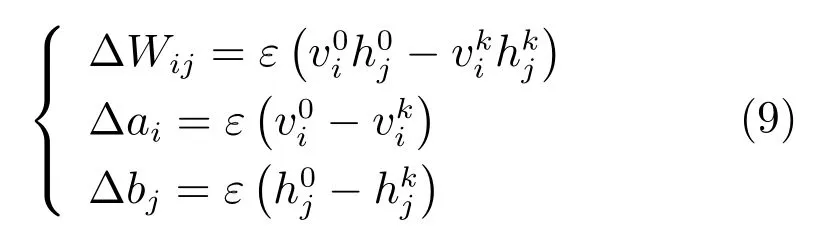
其中,ε为学习率.
2 深度信念网络
多个玻尔兹曼机堆叠后,就形成了深度信念网络[13].通常可以在最上层再增加一层逻辑回归(Logistic regression)层来作为有监督学习分类器.DBN模型示意图见图2.
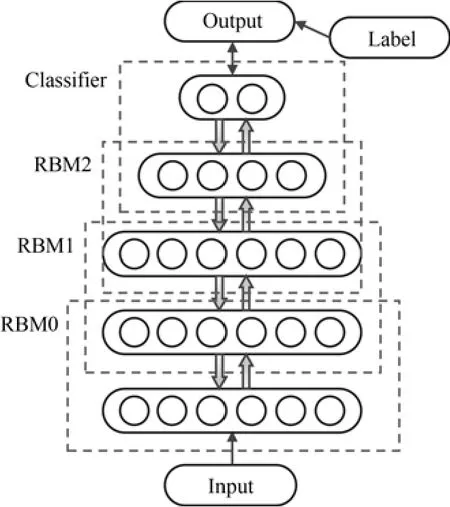
图2 DBN模型Fig.2 Deep belief networks
Hinton在文献[13]中提出了深度信念网络的训练方法,分为逐层预训练和整体精调两个阶段.在逐层预训练阶段,从网络最底层的RBM开始,自底向上逐层使用无监督的贪婪方法来使得每层RBM的损失误差最小.在此过程中相邻的RBM两两连接,下层RBM的输出传递到上一层RBM作为输入,最底层的输入为训练数据,最顶层的输出传递给分类器.在整体精调阶段使用有监督的学习方法,将所有隐层的权值看做一个整体,使用梯度下降的方法针对有标签的数据进行权值修正.第一阶段的学习过程提高了在构造模型下训练数据的似然概率的变分下限,是无监督的,不需要标签信息.如果不进行第一阶段的逐层预训练,直接使用随机初始化的参数直接进行梯度下降法则很容易导致训练失败,模型容易陷入局部极值点[1].通过RBM的逐层训练,深度网络每层的参数都已处于一个比较好的位置上,在此前提下进行全局性的梯度下降可以精调整个模型的精度,获得更好的结果.
3 多隐层Gibbs采样预训练
作为生成模型的DBN,在向下的生成方向上,不仅是最底层的可视层,整个网络的每一层都是为了使得重构数据的分布和真实数据的分布尽可能地接近.如图3所示,表示DBN的隐层.传统的逐层训练算法,针对组合的RBM,是其可视层,是其隐层,Gibbs采样是在这两层之间迭代的,使得此RBM 参数Wm+1收敛,以更好地接近层输入的分布.采样先从层的输入开始向上构建层,概率为再在此基础上反向重构出层的数据,概率为Salakhutdinov等在文献[16]中指出,在DBN中如果每层RBM都被正确地初始化(可以通过逐层预训练保证),则反向的P(hm+1|hm+2,Wm+2)是比P(hm+1| hm,Wm+1)更好的hm+1上的后验分布.反向的概率P(hm+1| hm+2,Wm+2)是由高层多个隐层计算得到,包含了比低层更抽象更丰富的信息.在此基础上我们使用P(hm+1|hm+2,Wm+2)来代替P(hm+1| hm,Wm+1)以获得更好的近似.
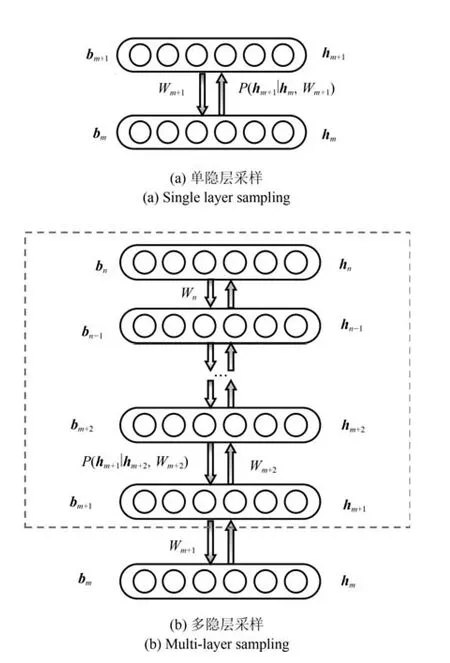
图3 针对hm+1的采样Fig.3 Sampling for hm+1
于是针对hm+1, hm组合的RBM,hm层的对数似然梯度为考虑到
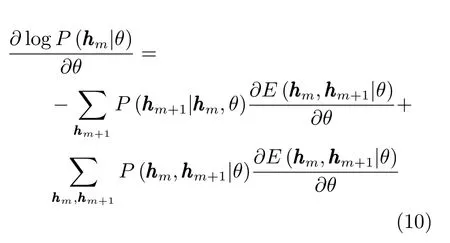
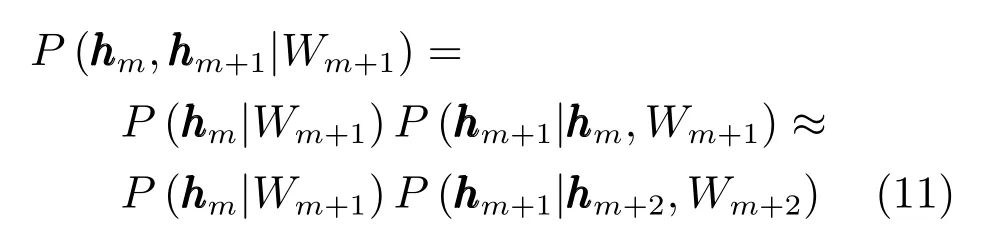
以及能量对于Wm+1的梯度,所以式(10)的第二部分为
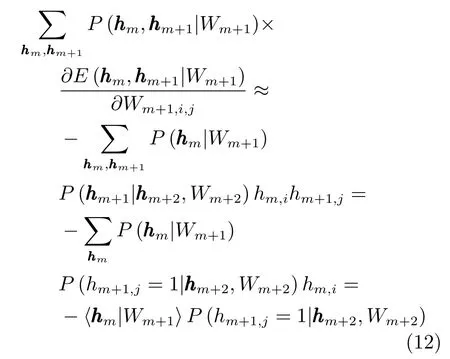
同理,式(10)的第一部分为
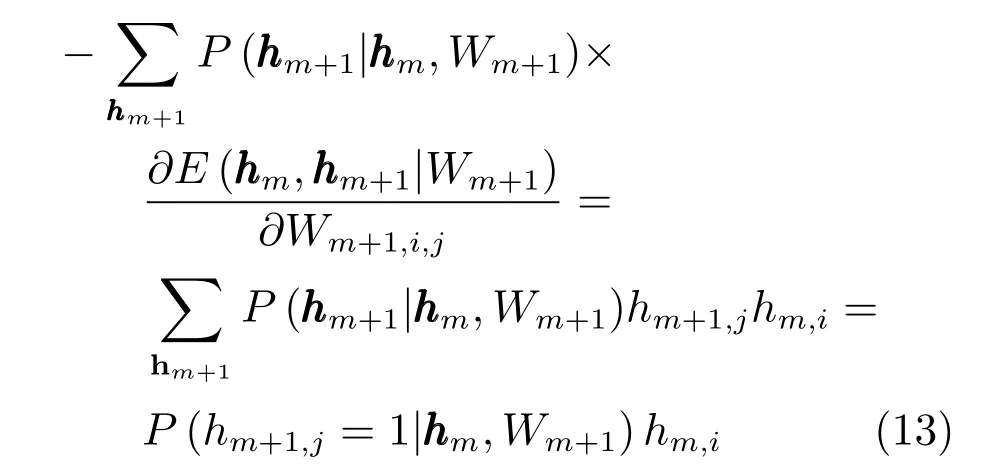
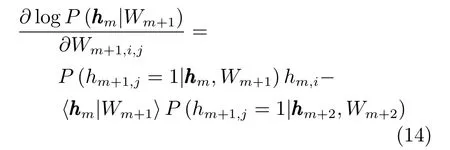
条件概率为
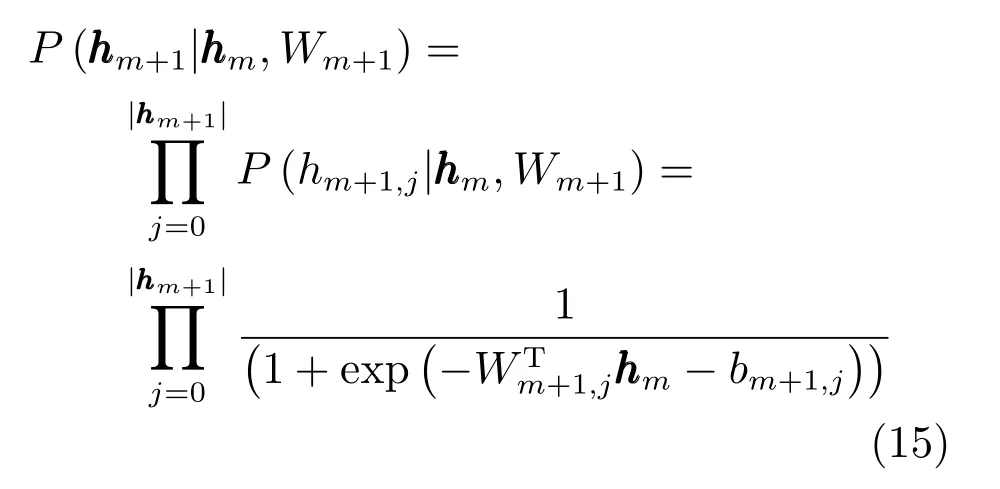
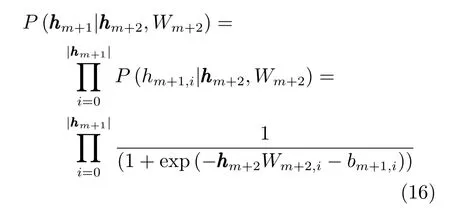
对于bm和bm+1的梯度可以通过类似的方法推导,使用之前的记号,可以得到类似式(6)∼(8)的结论.
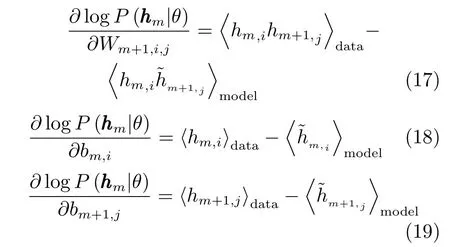
Gibbs采样是一种马尔科夫蒙特卡罗(Markov chain Monte Carlo,MCMC)方法,可以利用已有数据来推断丢失的数据.对于从到的多隐层Gibbs采样是在这n−m+1个隐层上进行的.信号先从层开始向上使用式(15)传播,到达最上层层后开始使用(16)反向传播,等到信号回退到层后使用采样值来估计,随后向下采样估计,再使用式(17)∼(19)来更新网络参数.注意到我们仅更新,层相关权重,而将高层权重固定,以保持模型的稳定,所以本质上还是一种逐层训练方法.在迭代时要注意从底向上逐层进行.如前两节所述,现有的DBN预训练是针对每层的RBM使用Gibbs采样来逼近模型的真实分布,使得每层RBM和其真实分布的差异减小,但DBN的推断过程是将所有的RBM 层看做一个整体进行的,通过引入多隐层Gibbs采样可以在逐层逼近的基础上进一步在局部模型上逼近真实分布.
多隐层的选择和组合方式有多种可能,本文通过实验讨论了以下4种类型的组合方式:两两不嵌套组合(Non-nested)、两两嵌套组合(Nested)、增量不嵌套组合(Incremental non-nested)和增量嵌套组合(Incremental nested).以4隐层的DBN举例,假设4个隐层分别为,那么两两不嵌套组合的RBM序列为;两两嵌套组合的RBM为;不嵌套增量组合的序列为嵌套增量组合的序列为
综上所述,基于多隐层Gibbs采样的DBN模型算法整体描述如下:
步骤1.无监督的逐层预训练.对于DBN中的RBM层进行逐层贪婪预训练.令XXX为最底层RBM的输入.自底向上,对于第i层RBM,计算隐层节点概率并交替采样,具体如下.
步骤1.1.进行K次Gibbs采样.使用式(3)计算概率分布,然后从分布中抽取再使用式(4)计算并从中抽取
步骤1.2.以下式和(9)来更新参数
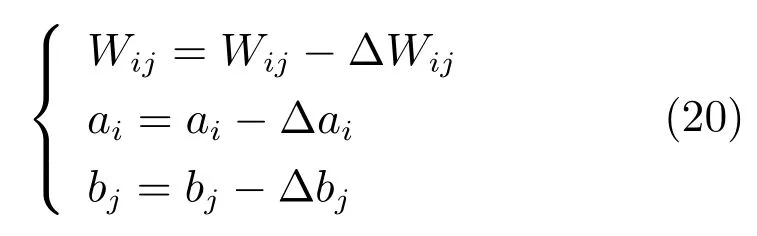
步骤2.无监督的多隐层预训练.自底向上组合多隐层,对于每个RBM组合,执行以下步骤进行多隐层预训练.
步骤2.1.依据式(15)向上计算每层概率分布并抽取出hi,j∈{0,1},直到顶层.
步骤2.2. 依据式(16)计算反向概率,每计算一层同时抽取,直到底层.
步骤 2.3.使用式(17)∼(19)计算梯度,并更新权重.
步骤3.有监督的全局精调.步骤如下.
步骤3.1.对于所有的RBM层,自底向上传递信号.第i层的输出作为第i+1层的输入.
步骤3.2. 将最上层RBM的输出和样本标签Y传递给分类器,使用梯度递减更新所有的参数.
4 实验与分析
实验部分使用MNIST手写数字数据集、合成的数据集ShapeSet以及真实物体图像数据集Cifar10来测试本文的模型.MNIST数据集包含70000张人类手写数字的图片,每张图片包含一个0∼9的手写数字,被分割成28×28的黑白两色点阵.数据集分为两部分,一部分是包含60000张图片的测试用数据,一部分是剩下的10000张用于测试.每张图片都有对应的标签数据,表明正确的数字是什么.MNIST数据集是一个广泛使用的评估机器学习算法的数据库,其中包含的手写数字信息来自于不同的书写方式,且数据集没有经过任何拉伸转换等几何上的处理.在本文实验中,也没有进行任何额外的预处理,相当于没有任何领域知识的介入.ShapeSet是一个人工生成的数据集,每个样本可以包含任意多个平行四边形、三角形或圆形的图像,图像之间可以互相叠加遮挡,且有任意的前景和背景色.在本文的实验中,设置每个样本的大小为32×32,限制样本中出现的图形数为1或2,两个图形之间的遮挡率为不超过50%.Cifar10数据集包含60000张32×32大小,有RGB三原色信息的彩色图片,共有10类物体,每个类别6000张.
在DBN的最上层,增加了一层逻辑回归层来预测类别,使用Softmax激活函数,用预测值和真实类别值之间的负对数似然函数来计算损失.通常情况下动态的学习率会取得更好的结果,学习率一般随着训练次数的增加而逐渐减小,以防止模型错过最小值.在本文的实验中,目的是验证新的算法相对传统算法的有效性,没有去讨论模型在实验数据集上所能达到的最优结果,所以使用了常数的学习率.无论是DBN还是改进后的算法,在训练的第一阶段,也就是逐层训练时使用的学习率都是0.01,在最后一个阶段整体精调时使用的学习率是0.1,改进后的算法的第二阶段使用0.01的学习率.在所有实验的整体精调阶段和本文提出的算法的第二阶段,都使用了“早停”(Early stop)的技术,来防止模型过拟合.为了加速算法,本文使用了小批量(Mini-batch)的方法来把数据批量提交给GPU计算.文献[17]中,Vincent等给出了Mini-batch的数量设置建议,通常情况下每个小Batch包含的样例数目应等于类别的数量,在本文的实验中设置为10.逐层训练阶段循环Epoch数设置为100,整体精调阶段设置为1000,改进的算法的第二阶段设置为100.
本文使用Python ver.3.5.2语言在Theano ver.0.8库的基础上实现了基本的DBN算法以及提出的改进算法.在一台Xeno E3-1230V3,8GB内存,Ubuntu16.10 64位的系统上,通过GeForce GTX1070 GPU加速来运行实验程序.
4.1 4隐层,不同RBM嵌套组合方式
在本组实验中,使用了784×N×N×N×N×10的网络结构.包含了4层相同节点数的隐层.N的取值从100递增到3000.针对不同的方法,在MNIST数据集上做了5组实验,实验结果如图4.
可以看到对于4隐层的深度信念网络,使用两两嵌套组合,方式训练的错误率最低,无论是全局最低值还是整体平均值.在1300×1300×1300×1300隐层的结构下,达到最好的错误率1.09%,比传统的DBN在同样结构时的1.25%要降低0.16%.在整组实验中使用两两嵌套组合方式的错误率普遍要好于其他方式.当隐层节点数逐渐增加到大于200以后时,两两嵌套组合的方法要普遍好于传统方法的DBN.两两嵌套组合方式最小错误率1.09%比传统方法的最好结果1.15%(1500隐层结点时)要低0.06%,且在更少的隐层节点下取得,这表明两两嵌套组合方式能够比传统方法更早更好地找到数据的特征.同时因为是深层层间全连接网络,1300隐层节点的网络要比1500节点的网络少大约1/4的层间参数,相应的计算量要少得多,分类的速度会更快.
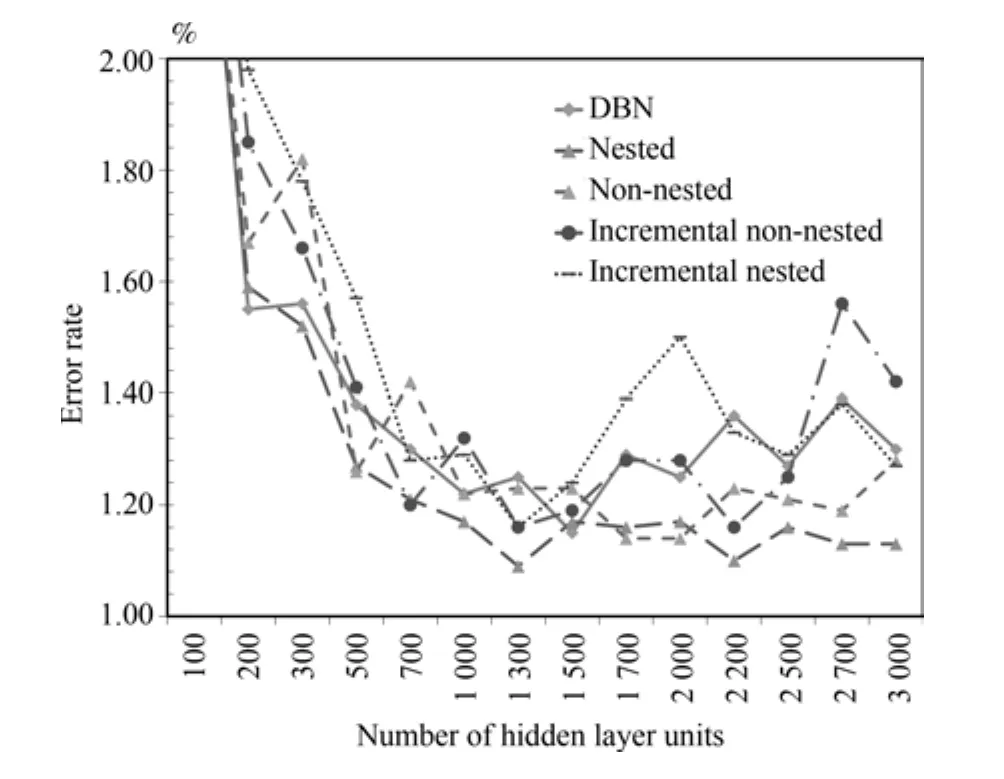
图4 MNIST数据集上4隐层模型错误率对比Fig.4 The error rate of 4 hidden layers model on MNIST
不嵌套组合的方法在隐层节点低于1500时和传统的DBN接近,大于1500时比DBN要好,但普遍比两两嵌套组合方式要差.
增量不嵌套和增量嵌套的组合方式表现出了较大的波动性,错误率围绕传统DBN上下摆动.相对于不递增的组合方式,它们对数据进行了更多轮的学习,也消耗了更多的运算时间,出现这样现象的原因可能是因为组合了超过3层的隐层,从而导致出现了梯度消失或激增的情况,导致了网络性能的不稳定[18].
4.2 3隐层,2RBM组合交叉实验
为了进一步验证模型有效性,在本组实验中,改变了网络的深度,使用了784×N×N×N×10的网络结构,隐层为三层.同样的,为了方便考察算法性能,设置了同样的节点数,都为N.N的取值设定为从100到4000.如果对于3隐层从底向上编号为,增量嵌套的训练序列是嵌套组合的训练序列是最终的MNIST数据集上实验结果如图5.
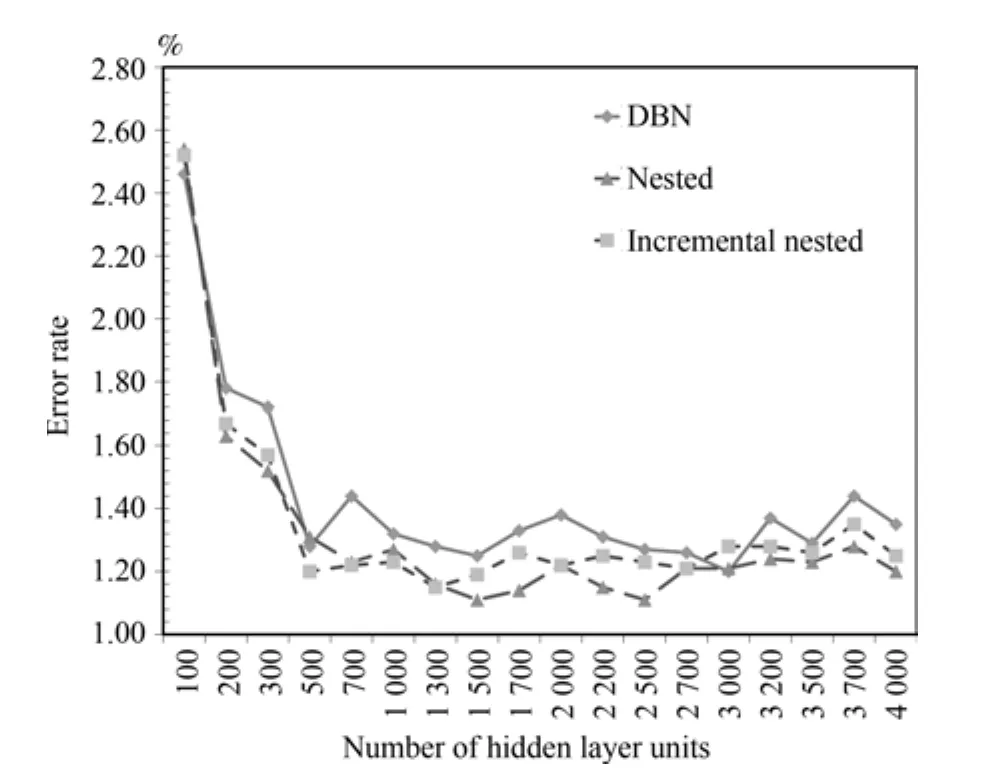
图5 MNIST数据集上3隐层模型错误率对比Fig.5 The error rate of 3 hidden layers model on MNIST
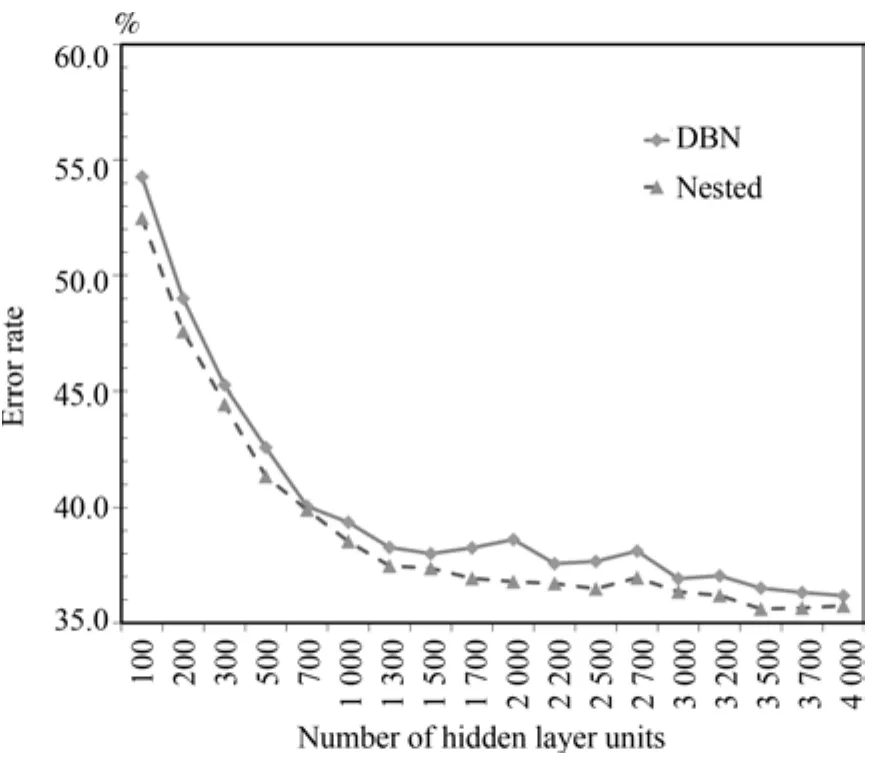
图6 ShapeSet数据集上3隐层模型错误率对比Fig.6 The error rate of 3 hidden layers model on ShapeSet

图7 Cifar10数据集上3隐层模型错误率对比Fig.7 The error rate of 3 hidden layers model on Cifar10
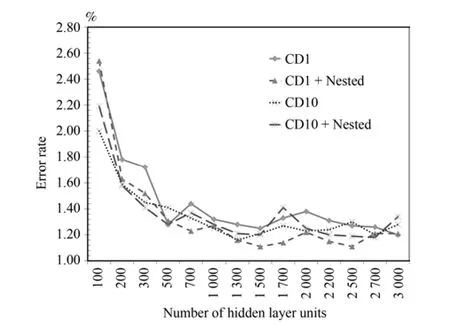
图8 3隐层模型CD1、CD10错误率对比Fig.8 The error rate comparison with CD1 and CD10 on 3 hidden layers model
最好的错误率同时出现在两两嵌套组合算法隐层为1500节点和2500节点时,都为1.11%,对应的传统的DBN算法错误率为1.25%和1.27%,分别降低了0.14%和0.16%.在其他节点数的情况下,从200开始改进后的算法错误率都要普遍优于传统算法.相对于4隐层的结果,3隐层下增量嵌套组合的稳定性要更好,虽然不如嵌套组合的效果,但也普遍优于传统算法.
4.3 ShapeSet数据集和Cifar10数据集
为了进一步验证算法的有效性,在ShapeSet和Cifar10数据集上针对两两嵌套组合算法和传统的DBN算法再次做了比较.实验结果如图6和图7.ShapeSet数据集上错误率普遍比传统方法低2个百分点.Cifar10数据集上从1000结点规模后普遍比传统方法要低3个百分点.类似的结论再次验证本文提出的算法相对于传统DBN算法的有效性,两两嵌套组合算法在各种隐层节点数量的模型上普遍获得了更低的错误率.
4.4 其他方法的比较
上述实验是在传统的DBN方法的基础上增加一轮无监督的组合训练得到的.传统的DBN在逐层预训练阶段使用的是基于对比散度(CD)的采样方法,实验表明CD-1,也就是Gibbs链迭代1次后的采样效果就已经很好了.Tieleman等[19−20]在传统的 DBN 上提出了一种改进的对比散度方法,称之为Persistent contrastive divergence(PCD)算法.实验表明PCD要优于传统的基于CD-1采样的DBN算法,和10次交替采样的CD-10接近.在本文之前实验中的对比算法就是使用CD-1的DBN算法为基准.在CD-1的基础上增加组合训练可以改进模型的精度,那么在使用PCD或CD-10来逐层预训练的基础上能否进一步的改进模型精度呢?在MNIST数据集3隐层的模型上CD-1和CD-10的对比实验结果见图8,4隐层上的CD-1和CD-10以及PCD的对比结果见图9和图10.
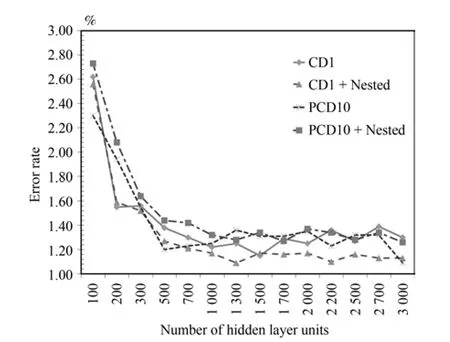
图10 4隐层模型CD1、PCD错误率对比Fig.10 The error rate comparison with CD1 and PCD on 4 hidden layers model
可以看到,在3隐层的网络上,CD-10的基础上再次进行RBM嵌套组合预训练并不能显著提高模型精度.最好的结果仍然是在CD-1+嵌套组合预训练的情况下.
在4隐层的网络上的结论类似,最好的结果还是在CD-1的基础上进行嵌套组合预训练.CD-10和PCD-10的情况下,模型错误率围绕CD-1波动,在CD-10或PCD的基础上增加一轮组合预训练并不能显著地提高系统的精度.
4.5 时间消耗和算法效率
本文在新增的多隐层Gibbs采样预训练中使用了“早停”机制,在训练中一旦检测到模型的代价值增加就会提前终止训练.实际中在大部分的情况下只需额外训练很少的轮数就会满足终止条件,实际消耗的时间非常少.几种算法的实际训练时间对比见图11.可以看到本文的算法相对于CD-1时间略微增加,远少于CD-10和PCD算法.
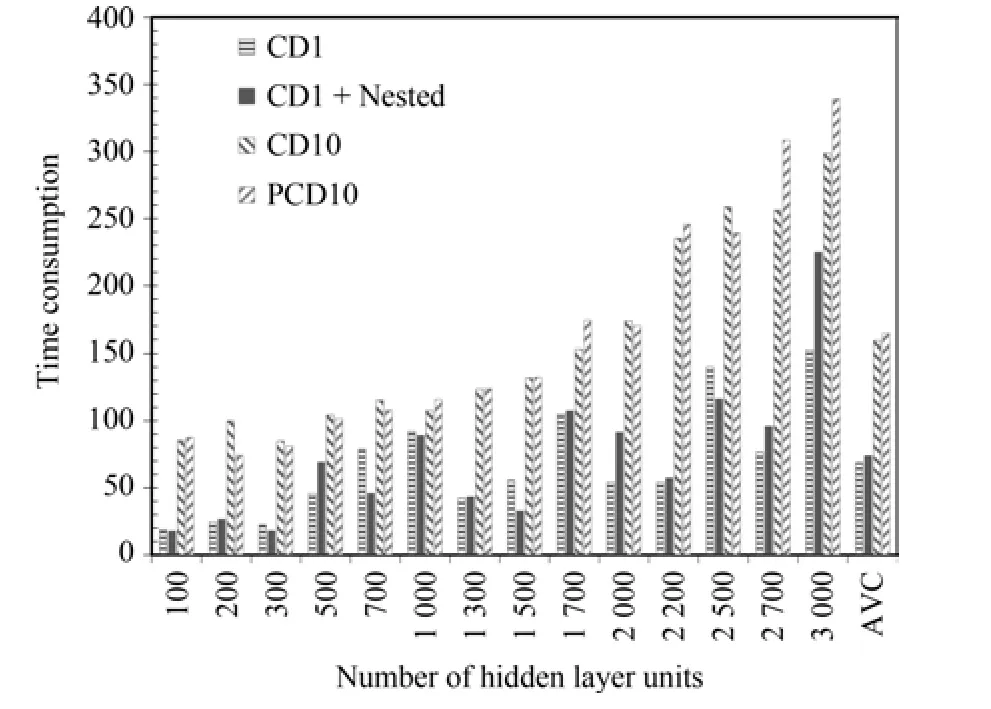
图11 4隐层模型上各种算法训练耗时对比Fig.11 The training time consumption comparison on 4 hidden layers model
上述实验表明,本文方法能够在更小模型规模上实现比传统DBN更好的分类效果.为了量化比较,使用算法效率(Algorithm efficiency,AE)来度量识别速度、错误率和模型规模之间的关系.AE定义为负的算法识别时间和错误率的乘积:

在4隐层上的算法效率对比见图12.可以看出本文方法相比传统的方法有着更高的算法效率.
5 总结和展望
理论分析和实验表明在传统的DBN训练方法的基础上,增加一轮基于多隐层的Gibbs采样无监督预训练,对于提高深度信念网络的精度是有效的,可以为进一步的有监督全局精调提供更好的初始化.对比多种隐层的组合方式,本文发现两两嵌套组合相邻的RBM进行训练的效果最好.此种训练方法在原有无监督逐层训练的基础上进一步地提高了模型训练数据似然概率的变分下限,相对于传统的使用CD或PCD的两阶段训练方法可以将错误率进一步降低,同时也有着更高的算法效率.

图12 4隐层模型上各种算法效率对比Fig.12 AE comparison on 4 hidden layers model
无监督的预训练不需要样本标签,堆叠基本组件逐层预训练也是众多深度学习模型[17,21−22]的一种通用的学习框架.现有的深度网络还有以其他组件为基本元素组合而成的,如深度降噪自编码网络[23],其使用自动编码器来代替限制玻尔兹曼机,组合基本组件混合训练的思想在理论上也可以推广到这些结构上,是否有效也还有待进一步的实验证明.
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
系统工程学报(2021年4期)2021-12-21 06:21:24
人民珠江(2019年4期)2019-04-20 02:32:00
教师·中(2017年3期)2017-04-20 21:49:49
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
计算机工程(2014年9期)2014-06-06 10:46:47
教学研究与管理(2014年4期)2014-05-16 22:44:12
机械工程与自动化(2014年3期)2014-05-07 12:49:22
计算机工程(2014年6期)2014-02-28 01:25:29
河南科技(2014年23期)2014-02-27 14:19:17
