
多视角步态识别综述
2019-06-11 06:42王科俊丁欣楠邢向磊刘美辰
自动化学报 2019年5期
王科俊 丁欣楠 邢向磊 刘美辰
步态识别是指通过人走路的姿态或足迹对身份进行认证或识别,被认为是远距离身份识别中最具潜力的方法之一[1].优势主要包括无需接触、非侵犯、识别过程不需要配合、难于隐藏和伪装等.因此步态识别在安全监控、人机交互、医疗诊断和门禁系统等领域具有广泛的应用前景和经济价值.
步态识别在实际应用中面临许多难点,主要表现在行人在行走过程中会受到外在环境和自身因素的影响[2−3](例如不同行走路面、不同时间、不同视角、不同服饰、不同携带物等因素),导致提取到的步态特征呈现很强的类内变化.其中视角因素是影响系统识别性能最主要的因素之一.当行人行走方向发生变化,或由一个摄像监控区域转入另一个具有不同设置的摄像监控区域时都会发生视角变化.图1为同一个人在不同视角下的步态图像,可以观察到不同视角下的步态图像均具有较大差异.研究[4−6]普遍认为侧面视角的步态轮廓包含了更有价值的信息,特征提取绝大多数也都是基于侧面轮廓的,而传统的单视角步态识别技术在视角变化时,识别性能也随之明显下降[7−8].

图1 不同视角下的步态图像(CASIA-B)Fig.1 Gait images from different views(CASIA-B)
自1994年Niyogi等[9]最早利用步态信息作为特征进行身份认证后,步态识别得到发展快速,并涌现出大量的步态识别算法,其中不乏相关的综述文章[10−12],但多是基于对步态识别的整体概述(相同视角下的步态周期检测与识别),无针对解决视角这一主要难点对现有研究成果进行归纳总结.为了弥补这个不足,有必要对现阶段多视角步态识别研究情况进行总结分析,以期对本领域研究人员有所裨益.
数据库对于学习角度因素对步态识别的影响、评估和性能比较是至关重要的.本文首先总结可用于多视角识别的步态数据库.然后对现有文献的研究方法进行综述.根据特征提取的方式不同,将当前已提出的多视角步态识别方法分为四类,分别是3D模型法、视角不变性特征法、映射投影法和深度神经网络法.最后指出当前研究的局限性和发展方向.
1 现有多视角步态数据库
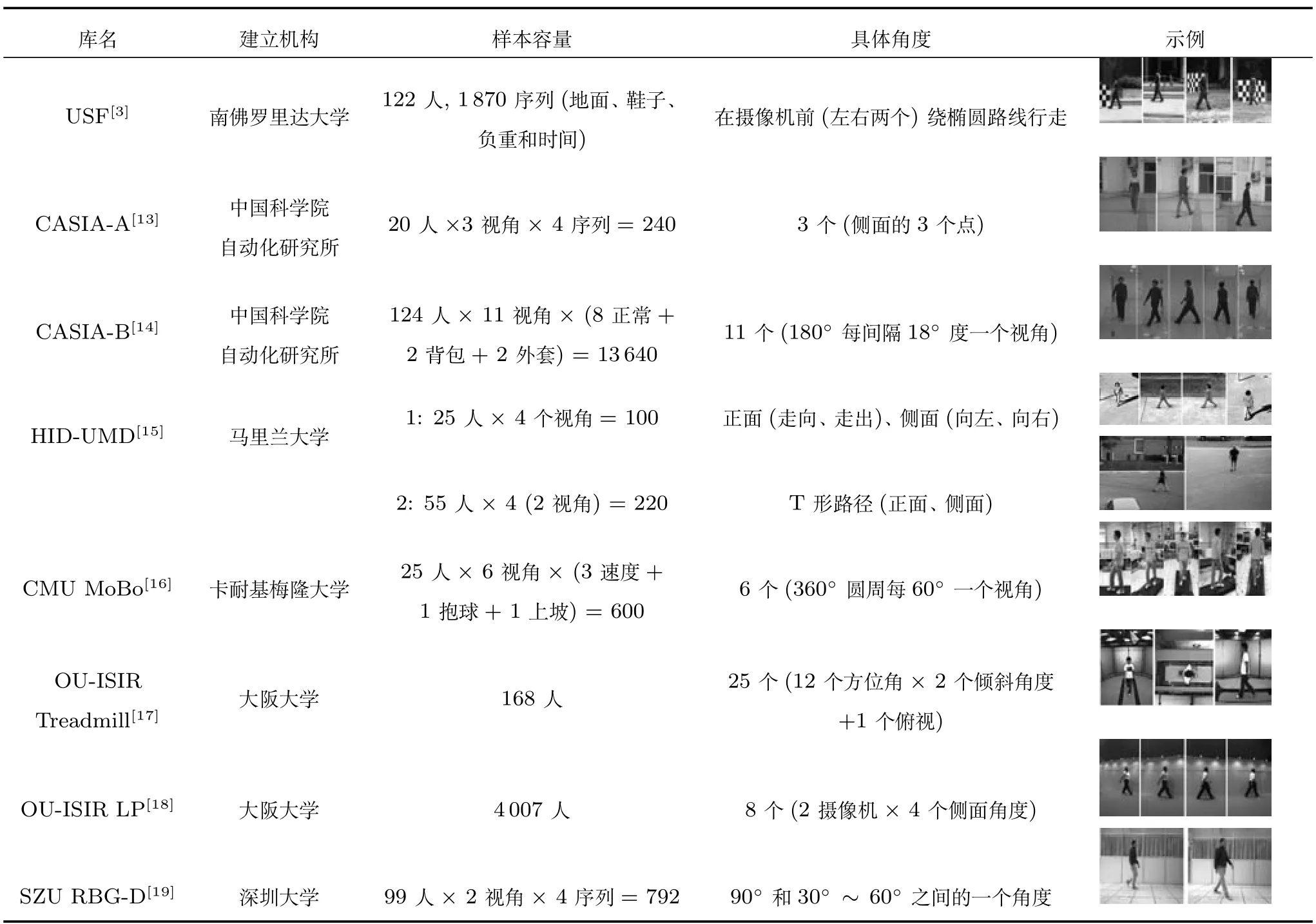
表1 多视角步态库Table 1 Databases for multiview gait
进行身份识别算法研究、系统开发和评估必须要有共同的数据.因此,大型步态数据库是必不可少的.为此,步态数据库应该包含一个大的类别数以及各种协变量条件.要消除角度因素对步态识别的影响,需数据库提供针对各种复杂角度设定的步态序列.为了便于研究,目前国际上已经建立了多个用步态识别研究的数据库,其中具有角度变量,可用于的多视角识别研究的数据库主要有 USF[3]、CASIA-A[13]、CASIA-B[14]、HIDUMD1 和2[15]、CMU MoBo[16]、OU-ISIR Treadmill[17]、OU-ISIR LP[18]和SZU RBG-D[19]等,表1详细地总结了上述多角度步态数据集.
此外, 还有 UMST[20]、 KY4Ddata[21]、AVAMVG[22]和TUM-IITKGP[23]等3D步态数据库,用于3D步态建模.
而现存的多视角步态数据库虽已系统地对各个行人不同视角的下的数据进行注册,但仍存在以下不足:
1)高维的步态特征和小样本问题:除OU-ISIR LP数据库外,步态数据库的注册样本都不足200人.但通常情况下,步态识别技术的特征维数很高,而数据集中的训练样本数目很少,一般的识别算法可能会造成数据过拟合.
2)视角问题:需应用步态识别的视频监控场景的摄像头通常安装是有一定俯角的,然而现存数据库大多是人的行走方向与摄像机镜头主轴方向垂直,视角变量仅限制在行走平面的360度内,无立体视角变量的大型步态库.
3)遮挡、服饰或携带物和夜间识别问题:实际的步态识别中,很可能存在障碍物和行人之间的相互遮挡,现存的步态数据库中,无论室内室外都是在空旷环境中且画面只有一个行人情况下采集的;同时现有的步态数据库服饰和携带物变量较少,通常不超过5种,且所有行人都采用同样的服饰和携带物进行注册;夜间红外摄像头采集的视频信息通常光线较暗,步态轮廓与背景较为接近,视角因素与夜间因素相互影响大大增加了识别难度,而目前仍没有夜间的多视角步态数据库.
2 研究动态
步态分析最早是医学[24]、心理学方面的课题[25],如果考虑步态运动的所有信息,每个人的步态都是唯一的.随着计算机运算能力的增强和生物特征识别技术的兴起,步态分析在计算机视觉领域的发展逐渐引起了关注.美国国防部高级研究项目署在2000年资助了远距离身份识别的重大研究项目[1],研究远距离步态和动态人脸以及其他因素对身份识别的影响,最终开发远距离下具有高可靠性、鲁棒性的大规模身份识别系统,对步态识别的研究产生了深远的影响,在一定程度上促进了步态识别的发展.国内外许多知名的研究机构都开展了步态识别方面的研究,国外比较著名的有麻省理工学院、马里兰大学、南安普顿大学、南佛罗里达大学等.国内的研究机构主要有中国科学院自动化研究所、山东大学、哈尔滨工程大学、复旦大学、深圳大学等.但目前步态识别研究均是理论性的,尚没有成熟的步态识别系统出现.多数的步态识别算法是在理想环境下(背景简单,无遮挡、携带物和服饰变换且画面中只有一行人)对目标侧影图像的分析,与实际应用环境差别较大.因此,虽然现有的方法大多都已取得超过80% 识别率[26],但把步态用于个人身份识别还没有达到在实际复杂环境中应用的要求.
本文将现有的多视角步态识别研究方法分为基于三维建模和基于二维图像或视频序列特征两大类.其中,三维建模主要采用多台校准的不同视角的摄相机构建3D人体步态模型;而基于二维图像或视频序列特征的方法,构造能够有效整合步态视频轮廓与时域信息的步态特征模板直接影响步态识别的精度,故本文先介绍各常用类能量图的构造方法,再根据特征提取方式的不同,又分为提取视角不变性特征法,学习不同视角下映射投影关系法和深度神经网络法三类.
2.1 基于建立3D步态模型的方法
由于步态信息本质是三维的,而二维步态图像序列只提供单一视角信息,限制了任意视角的步态识别.通过多摄像机对人体结构或人体运动进行三维建模,能够更准确地表达人体各个部位的物理空间,充分利用关节的角度约束和人体各个部位的运动特性.且在3D空间中,步态识别的人体检测、人体跟踪等预处理工作变得比较简单,能够降低遮挡等因素的负面影响.
Shakhnarovich等[27]提出基于图像的可视外壳(Image-based visual hull,IBVH)以绘制用于步态识别的视角.IBVH从多个校准摄像机的一系列单视角中计算得出.该方法首先估计规范视觉相机的位置,然后使用从这些视角获得的绘制图像来做视角规范化.Bodor等[28]应用基于图像的绘制技术于3D可视外壳模型,得以在任意所需视角下重构步态特征.该方法可以将不同视角下的多个摄像机所获取的步态信息综合起来,但需要在校准单个摄像机的基础上进行交叉校准使得它们具有相同的参考帧.Zhang等[29]提出基于3D角线性模型和贝叶斯规则的视角对立步态识别方法.该方法在傅立叶表示的样本中使用主成分分析来构建3D线性模型.通过最大后验概率估计将不同视角下的2D步态序列投影到一个3D模型中,由此得出一系列系数用来描述步态特征.Tang等[30]利用先进的3D成像设备进行3D重建和目标跟踪,但很难只用距离数据精确地分割出人体轮廓.为了解决这个问题,Tang等[31]提出建立3D人体模型,通过二维轮廓和姿态建立拉普拉斯形变能量函数将模型产生相应角度和姿势变形,再将局部投影至二维空间构建部分步态能量图再识别的方法.Zhao等[32]从多个摄像机捕获的视频序列中重构3D步态模型.该方法使用从3D模型中提取的下肢的运动轨迹作为动态特征,同时利用线性时间规整化进行匹配和识别.López-Fernández[22]等同样利用多摄像机构成的多视点视频序列重构三维步态序列,提出了一种基于3D角度分析的旋转不变的特征,运用子空间分量与判别分析和支持向量机(Support vector machine,SVM)进行分类识别.Deng等[33−34]提出了一种基于多视点融合和确定性学习的方法,利用不同视角合成轮廓图像.Iwashita等[35]利用4D步态数据库合成虚拟图像估计行走方向,提取仿射不变矩为特征进行识别.
一般3D分析至少需要两台摄像机,通常因为存在遮挡,为了进行充分的3D步态分析,至少需要来自4台摄像机的步态信息.然而,由于复杂的摄像机平衡视角和建模计算,这一系列的方法一般只适用于完全可控的多摄像机协作环境,且难以在实际的实时应用中使用.
2.2 基于二维图像或视频序列特征的方法
2.2.1 步态特征表征模板(类能量图)
与基于三维建模的方法不同,基于二维图像的步态识别通常需构造步态表征模板集中整合步态的静态、动态和时序信息,一般是对视频图像序列按照一定规则的叠加,即构造步态类能量图.学习不同视角下映射投影关系方法的研究绝大多数都是在类能量图基础上进行二次特征提取完成的;也可从能量图中直接提取视角不变特征或将其送入深度神经网络.因此类能量图的构造与选择直接影响了步态识别精度.
类能量图法将一个人周期性的、连续的时空运动序列生成一幅或几幅图像,对步态图像质量要求不高,且无需考虑人体模型结构和计算人体各部分的精确参数,能够节省存储空间和计算代价,对图像噪声有较好的鲁棒性.同时基于序列的步态表征方法更有效地利用了步态序列的时空连续性,包含更多运动特征.Lv等[12]根据类能量图的生成方式将其分成步态信息累计类、步态信息引入类、步态信息融合类能量图三类,并全面地对已提出的各种类能量图的特性进行了理论分析和对比实验研究.其中较为常用的类能量图主要有运动历史图像(Motion history image,MHI)[36]、步态能量图(Gait energy image,GEI)[37]、运动轮廓图(Gait energy image,MSI)[38]、步态历史图(Gait history image,GHI)[39]、主动能量图(Active energy image,AEI)[40]、步态熵图(Gait entropy image,GEnI)[41]、帧差能量图(Frame difference energy image,FDEI)[42]和基于时间保持的步态能量图(Chrono-gait image,CGI)[43]等.其构造方法与性能分析如表2所示.
2.2.2 提取视角不变性特征
直接提取不同视角下视频序列或图像中不随着角度或行走方向而改变的步态特征进行身份识别,从而避免因角度变化而引起的人体轮廓的巨大差异对识别的影响.直接提取视角不变性步态特征的方法各式,通常思路直观,计算较为简单,而提取的特征也较为多样.由于基于局部特征和聚类图像的方法较多,本文大体将其分为局部特征法、聚类图像法和其他三类.
1)局部特征
Jean等[44]提出一种计算视频序列中人体部位轨迹的视角规范化方法.该方法选取轮廓序列中规范化脚和头的2D轨迹将行走轨迹分割成分段线形的部分.然而,该技术仅对有限范围内的视角有效.为了解决Jean等的方法由于遮挡等原因,提取到的人体轮廓中可能丢失头部或脚的问题,Ng等[45]提出从自动检测到的人体关节(臀、膝和脚踝)中计算关节的角轨迹,并应用透视校正来提取视角不变的步态特征.彭彰等[46]提出了一种基于肢体长度参数的方法,利用脚间距计算方法和动态身体分割方法,拟合出场景的转换参数,并以此估计出人运动情况下的5个肢体长度参数用于识别.这种方法受限于图像分割的准确度且只适用于视角与行人水平的情况,立体视角的变化对肢体长度参数影响较大.Goffredo等[47]提出基于模型的步态特征自标定视角不变步态识别.下肢姿态由无标记运动来估计,然后这些姿态在腿关节运动近似平坦的假设下,使用视点矫正在矢状面进行重构.但该方法对于下肢姿态的估计缺乏鲁棒性且无法应用于正面视角,两视角差异较小时性能较差.
2)聚类图像法
Lu等[48]将不同的视角分成几个聚类,提出聚类的平均步态图像(Average gait image,AGI)作为特征表达,利用稀疏重构的度量学习(Sparse reconstruction metric learning,SRML)进行身份分类.Darwish[49]采用聚类的空间域能量偏差图像(Energy deviation image,EDI)[50]作为步态特征,再利用区间二型模糊K近邻(Interval type-2 fuzzy K-nearest neighbor,IT2FKNN)进行步态识别.聚类图像法大多先利用聚类进行视角估计解决角度问题,需要大量的注册样本,且如果在步态序列中没有相似的视角,识别率将下降.
3)其他
Han等[37]从GEI中提取视角不变特征.该方法仅选取部分在视角间相互重叠的步态序列来构建交叉视角的步态匹配表示.Kale等[51]提出一种从任意视角生成侧视图的方法.该方法采用透视投影模型和基于运动方程的光流结构.这种方法要求行人距离相机的距离足够远,当像平面和矢状面之间的夹角变大时,该方法受到自遮挡的影响性能显著下降.
直接提取视角不变特征的方法适用于视角变化范围有限或较小的情形,并且该类方法提取步态特征的过程易受到遮挡因素或服饰变化的破坏.
2.2.3 学习不同视角下的映射或投影关系
在步态相似性度量之前,训练好的映射关系模型可以将不同视角下的步态特征规范化到相同视角的特征空间中,利用多个角度的训练数据学习视角判别子空间,步态特征被投影到子空间(通常在较低的维度)中获得视角不变特征,以解决多角度问题.基于投影映射的方法是一种很好的实时应用解决方案,已有的研究成果多具有较高的识别精度.其中已采用的映射投影方法很多,包括典范相关分析(Canonical correlation analysis,CCA)、视角转换模型(View transformation model,VTM)、线性判别分析(Linear discriminant analysis,LDA)、多线性主成分分析(Multilinear principal component analysis,MPCA)、核主成分分析(Kernel principal component analysis,KPCA)和耦合学习等.由于LDA、MPCA、耦合学习与核思想多交叉融合构造子空间,将其归为一类,故本文将从CCA、VTM和其他三类分别说明.

表2 类能量图构造方法与性能分析Table 2 The construction methods and performances analysis of class energy image
1)典范相关分析(CCA)
典范相关分析(CCA)[52]是一种著名的多元分析方法,其目的是寻找和量化两个多维变量之间的相关性.CCA利用两种相同模式的视图,并将它们投射到一个使其相关性最大的低维空间中.应用CCA解决跨视角步态识别问题,将不同视角的步态特征投影到一个统一的特征空间,并在该公共空间中进行相似性度量.
Bashir等[53]采用高斯过程分类框架进行视角估计,再利CCA进行不同角度建模.Hu[54]将判别典范相关分析(Discriminant canonical correlation analysis,DCCA)进行了高阶张量扩展,应用多重线性分析,利用张量到向量投影直接从张量数据中提取不相关判别特征,增进了DCCA方法在多视角步态识别中的性能.Xing等[55]针对传统CCA方法在处理两个高维数据集合时,存在的广义特征分析的奇异矩阵问题以及解的不稳健和不完备性,提出完备典范相关分析方法(Complete canonical correlation analysis,C3A),并将其应用于多视角步态识别,提升了传统CCA在步态识别中的性能.Wang等[56]对通过改进优化目标函数和类关系矩阵对原有的核判别典型相关分析进行优化,在CCA中引入了类信息并减少对应元素的相关性,在跨视角识别取得了较好的识别效果.Luo等[57]将GEI分割成5个子部分进行CCA,并在不同携带物和行走条件下优化训练每组子GEI,减少携带物和行走条件等变量因素的影响.
然而,基于CCA类的方法仅能利用两个视角间的互补信息,处理N个视角时要重复N次来学习N对特征映射,计算负担沉重.
2)视角转换模型(VTM)
视角转化模型可以将不同视角下的步态特征转化到相同的视角下,解决多角度的步态识别问题.Makihara等[58]提出视角转化模型的概念,由采用奇异值分解的矩阵分解过程创建.训练数据集中的步态矩阵每行包含来自相同视角不同对象的步态信息,每列包含来自相同对象,不同视角的步态信息,应用奇异值分解(Singular value decomposition,SVD)将步态矩阵分解成视角独立的矩阵和对象独立的矩阵,对象独立矩阵用于构建VTM.该方法基于傅立叶变换获得的频域步态特征来创建VTM.为了增进性能,Kusakunniran等[59−60]基于线性判别分析所获取的最优GEI特征来创建VTM,应用截断奇异值分解(Truncated singular value decomposition,TSVD)来缓解训练VTM 时的过拟合现象.进一步将VTM的构建重新表述成回归问题.使用回归概念来揭示不同视角间步态的运动相关性.Zheng等[61]通过首先对步态矩阵进行低秩分解再应用SVD分解构造VTM的方法来实现鲁棒的VTM 模型.Hu等[62]应用高阶奇异值分解将VTM模型扩展为在四阶张量空间的多重线性投影模型,然后提取视角独立、站姿独立的单位矢量,以对多视角、不完整步态周期的步态序列进行识别.Muramatsu等[63−65]在VTM中引入一种质量评价措施.由于一般是通过VTM 视角转换至规定视角的步态图像与目标视角图像进行相似性度量评判是否为同一身份,步态特征组引入了相似度的不均匀偏差.通过引入转化质量(源视角内在特征质量)和不均匀边缘质量(目标视角内在特征质量),利用这两个质量度量来计算真实配对的后验概率和原始特征的相似度量结合作为最终的匹配结果以提高识别精度.
VTM类方法虽然可以将一个视角下的步态特征转化为另一视角下的步态特征,从而解决不同视角之间的相似性度量问题,但无法有效地同时利用多个视角之间的互补信息.且基于VTM的方法都有在进行模型构建和视角转化时容易造成噪声传播,致使识别性能退化的问题.
3)其他(LDA、耦合学习、MPCA与核扩展等)
LDA是一种监督学习的降维技术,投影后类内方差最小,类间方差最大,提取需要的判别信息并减少维度.通常步态特征空间的维数非常高,且有许多在相似度测量中冗余的零值的像素,在经过LDA投影后减小同一行人不同视角下的类内方差,提高识别精度.Choudhury等[66]提出一种首先分割得到腿部步态能量图用于估计视角,再利用随机子空间学习进行身份分类的方法.Liu等[67]在每个视角下的训练数据集中提取步态特征在LDA子空间中的判别信息.在测试阶段,每个步态特征分别投影到每个子空间中,然后最终的步态距离由每个子空间匹配结果的加权和组成.Liu等[68]提出一种联合子空间学习的方法(Joint subspace learning,JSL),构造含有不同视角原型的JSL,不同视角的注册和待测样本分别被表示为这些原型在相应视角中的线性组合,并提取特征表示的系数利用最近邻识别分类.
核方法[69]是对SVM中主要思想核映射的应用的扩展,很多线性子空间算法都可以运用核函数扩展为非线性子空间,如核主成分分析[70]和核判别分析[71]等.Connie等[72]以双核主成分分析进行系数膨胀建立非线性子空间,形成Grassman流形描述多角度的步态特征,非线性子空间的结构能够更恰当地在视角变化中保留步态特征.
耦合度量学习(Coupled metric learning,CML)受启发于局部保留投影,旨在通过寻找保留局部信息的低维嵌入获得一个可以保持数据内部流形结构的子空间.与局部保留投影不同,耦合距离度量学习寻找一对线性变换矩阵将不同的样本映射到共同的子空间,在这个子空间中不同视角的步态数据差异被削减.Xu等[73]提出一种耦合局部保留投影的方法,学习耦合投影矩阵,在保证基本流形结构的同时,将交叉视角特征投影到统一的子空间中.Ben等[74]基于耦合距离度量学习思想,通过广义特征值分解将不同视角下的步态特征联系起来,提高了跨域生物特征的识别率,在跨视角步态识别中也取得了良好的效果.在此基础上,Ben等[75]引入了核的思想,通过核耦合距离度量学习(Kernel coupled distance metric learning,KCDML)使不同类样本线性可分,并保持样本局部结构数据的几何特征.Wang等[76]在传统CML中引入可分离标准,将标签信息加入其中,应用这种新的方法将步态特征从不同视角转换为一个耦合特征空间.但基于耦合度量学习的方法同CCA方法有相同缺点,仅能利用两个视角间的互补信息.
MPCA是一种无监督多线性子空间学习方法,实现了由张量至张量的投影技术,将高阶张量对象投影到下维张量中,即直接在张量维度进行降维.Al-Tayyan等[77]提出了一种基于累计预测图像的方法,同时定义累积流量图像和边缘掩蔽活性能量图像两种新的步态表达方式,采用MPCA与LDA结合通过K近邻进行身份分类,以最大化类间散射矩阵与类内散射矩阵之间的比例,提高分类的准确性.
子空间学习的方法通常计算较为复杂,步态图像转换成向量后维数常常高达上万维,计算量很大.此外,在视角的变化较大时,这一类方法性能下降较大.
2.2.4 基于深度神经网络
深度学习[78]是含多隐层的多层感知器的深度神经网络结构,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示.因其在语音识别、图像目标分类等实际应用中的出色性能近年来备受关注.但将深度学习应用于解决多视角步态识别问题的研究相对较少.
卷积神经网络(Convolutional neural network,CNN)[79]近年发展迅速,并引起广泛重视.其避免了对图像的复杂前期预处理,可以直接输入原始图像,对于大型图像处理有出色表现.且具有非常强的自主学习能力和高度非线性映射的能力,能够学习非线性度量函数以解决跨视角步态识别问题.Yan等[80]提出将步态能量图送入CNN来提取高级步态特征,并引入多任务学习模型,在步态识别的同时预测状态,联合每个任务的损失函数进行反向传播,获得比单独步态识别更好的性能.Wu[81]提出一种对一组图片集进行特征提取的方法,有效抑制过拟合问题.将步态轮廓集送入相同的CNN网络中,积累这些特征以获得集合的全局表示,能够较好地应对步态中的角度变换.Zhang等[82]提出将GEI送入具有两个卷积子网络的对称结构的孪生深度卷积神经网络.Tan等[83]提出将GEI送入使用共享权重的双通道卷积神经网络训练匹配模型,从而匹配步态识别人的身份,对跨较大视角的步态变化有很强的鲁棒性.Wu等[84]提出深度CNN网络用于步态识别,网络分为局部特征匹配的底层网络、中级特征匹配和全局特征匹配的上层网络,在跨视角和多状态识别中都有较好表现.Wolf等[85]提出了一种用于步态识别的3D CNN方法,网络的输入由灰度步态图像和光流组成,能够在多个角度下提取步态的时空特征.Li等[86]提出一种基于深度学习VGG网络[87]的识别方法.步态序列经过周期检测后直接送入VGG网络进行特征提取,最后利用联合贝叶斯进行步态识别.
自动编码器(AutoEncoder)[78]是近年来流行的网络模型,它可以用来提取紧凑的特征.Yu等[88]提出基于GEI进行的层叠式逐步自动编码(Stacked progressive auto-encoders,SPAE)的完成视角转化,每层转化18◦的视角.即利用自动编码器搭建VTM模型,来解决跨视角步态识别问题.
深度学习本质是数据驱动的,需要大量的不同行人的不同角度的步态信息,而现有的数据量相对较少.且现有的方法大多基于步态能量图和卷积神经网络的.然而步态能量图在轮廓序列的周期叠加后会丢失时序信息.卷积神经网络本身无法直接处理时间序列信号,也缺乏对时间序列信号的记忆功能.而基于自动编码的视角转换也有在转化时容易造成噪声传播使识别性能退化的问题.
3 对比与总结
3.1 实验结果对比
为了对现有方法的性能进行直观比较,表3选取了在CASIA-B数据集上验证过的若干方法的实验结果作为对比.由于跨视角情况下的步态识别暂没有统一的性能评价标准,研究中通常进行多组实验,选择每个行人不同的一个或若干个角度为注册样本,验证其他视角下的识别率以全面评估性能(即选取不同的Gallery和Probe set进行验证).表3中仅仅展示以90◦为待检测样本(Probe)的情况下,不同方法分别在54∼126◦为已知参考样本(Gallery)的识别准确率.
实验中都只采用正常行走状态下的行人步态样本(即无携带物和着装变化的视频样本).而在训练与测试集的划分上,不少工作采用在库中124行人中选择部分行人的样本作为训练,剩余行人作为测试集的验证方式,也有部分工作选择了其他的划分方式.3D模型局部能量图投影和KCDML的验证方式分别为选取数据库中所有行人的6个正常步态视频中的3个和2个作为训练,剩余视频作为测试集;其余方法均使用上述主要验证方式,其中GEI+CCA训练和测试集行人样本数量划分为74/50,GEI+SPAE为62/62,剩余方法为24/100.
3.2 现有方法总结
早期的多视角步态识别方法主要是提取视角不变的步态特征[37,44−51].随着三维建模与多摄像机协作技术的发展,建立3D步态模型[22,27−35]也很好地解决了识别中的视角问题;同时基于度量学习的方法也被用于多视角的步态识别中[53−77],通过投影到子空间获取视角不变特征,取得了相对较高的识别精度.而深度学习利用深层神经网络学习出高层抽象的步态特征,在步态识别的视角变化中也取得了良好的识别效果[80−88].表4比较了现有的多视角步态识别算法.
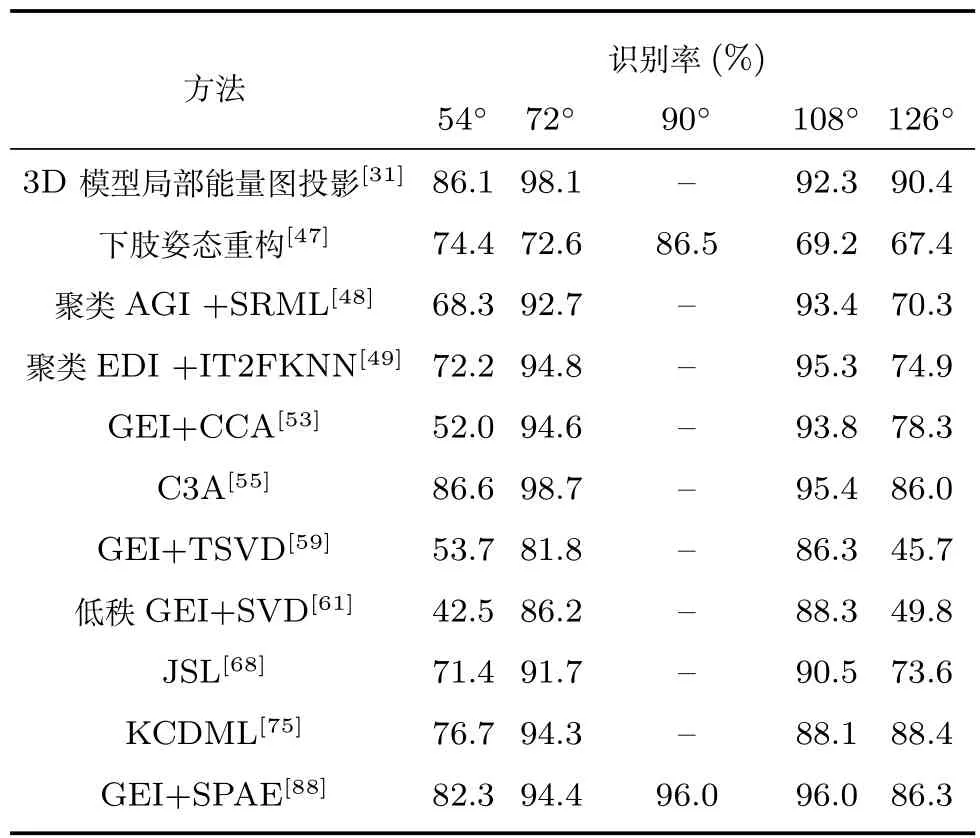
表3 CASIA-B数据集上现有步态识别方法的准确率对比Table 3 Recognition accuracy of existing approaches on CASIA-B datasets

表4 现有多视角步态识别方法Table 4 Existing approaches for multiview gait recognition
4 研究难点与发展趋势
4.1 研究难点
当前的研究难点主要集中以下在三个方面:
1)与指纹、人脸识别等相比,步态数据库的样本量过小,且通常的实际生活中摄像机的安装位置为俯视视角,但当前研究主要集中在行人行走平面的多视角识别,即缺乏模拟真实环境下立体视角的具有大量样本的大型步态数据库.同时现有的数据库都是在行人已知的情况下采集步态信息的,注册行人在面对复杂的采集环境时可能产生不自觉的姿态变化.
2)实际行走过程中会受到行走路面、不同时间、不同视角、不同服饰和不同携带物等的多种因素综合影响,目前的研究多着重于解决视角问题,但在视角与其他影响因素结合的复杂真实环境中的识别率仍然较低.
3)当前的基于图像或视频序列的多视角步态识别多是利用步态序列叠加合成图像构造类能量图模板.而图像的合成过程中可能会丢失信息,且因涉及周期检测等问题,此过程中可能已经引入了误差,影响识别率.
4.2 发展趋势
1)现有的数据库与真实环境中步态识别差距较大且样本数量较少.一致的评估和性能比较需要构造一个大型的、涵盖各种变量、环境因素并适合实际应用的数据库.同时构造隐藏摄像机的步态采集环境,获取在行人未知状态下的步态信息也是未来研究中数据库建设的一个发展方向.
2)深度学习用更多的数据或是更好的算法来提高学习算法的结果.对某些应用而言,深度学习在大数据集上的表现比其他机器学习方法都要好.其中长短期记忆网络(Long short term memory networks,LSTM)[89]对时序信息的处理能力为实现步态视频帧序列直接输入提供了可能性;深度学习的实现需要大数据集作为依托,而实际中很难采集同一行人遍历所有不同变量的大量样本,生成对抗网络(Generative adversarial network,GAN)[90]可以通过生成的方式生成多角度、多状态的大量不同步态样本用于深度学习的训练中.
3)深度学习可以依靠深层的网络结果自动提取特征,但过深的结构不利于参数训练,同时导致信息不断稀释.在深度学习中引入传统的步态特征提取方法,并将两者结合起来或许能取得更好的步态识别效果.
4)人体骨骼关键点检测技术[91]能够实时的抽象出人体的比例结构与姿态信息,而步态识别本质也是通过行人的轮廓和运动姿态信息进行识别.可考虑将提取的人体骨骼步态模板用于步态识别中,此种方法还可以避免服饰、携带物和遮挡带来的影响.
5)研究中步态识别视频数据的形式往往是采用已分割好的个体步态视频流.实现个体步态视频流的自动截取,是未来实现端对端的步态识别系统的实际应用的关键步骤.
6)步态识别仅仅利用步态信息进行身份认证,但每种生物特征识别都有相应的适用场合,以及各自的优缺点.故开发多模态系统,代替现有的使用单一特征的生物特征识别,使其能在各种环境下都能提供有效的身份认证与识别,有至关重要的意义.
5 结语
步态作为生物特征识别领域的一个新的研究方向,多视角识别对其应用具有极大的实际意义,近年来也引起了广大科研工作者的广泛关注.针对步态识别中的视角问题,本文首先介绍了现有的可用于多视角步态识别的数据库,然后分别从3D模型法、视角不变特征法、映射或投影法和深度神经网络法4个方面对现有研究成果进行综述,阐述了各种方法的原理和优缺点;同时结合步态识别实际应用的需求,针对现有工作中存在的不足,提出一些有待深入研究的问题并指明未来的研究方向.这些问题的解决将促使步态识别具有更宽泛的识别条件、更好的实时性与识别率,从而将步态识别真正用于实际的远距离身份判断中.
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
军事文摘(2022年8期)2022-05-25
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
电子制作(2018年18期)2018-11-14
科学之谜(2018年4期)2018-09-17
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
中华骨与关节外科杂志(2016年3期)2016-05-17
