
敏感变量和感知机结合的测试预言生成方法∗
2019-06-11 07:40马春燕李尚儒王慧朝
软件学报 2019年5期
马春燕,李尚儒,王慧朝,张 磊,张 涛
(西北工业大学 软件与微电子学院,陕西 西安 710072)
软件测试是保证软件系统质量的主要活动.在软件测试中,测试预言的作用至关重要,它是一种判断程序在给定测试输入下的执行结果是否符合预期的方法.测试预言的质量直接影响测试活动的有效性和软件系统的质量.目前,虽然研究人员已提出了各种自动化测试输入生成技术,成果颇丰,但是测试预言问题仍然被公认为是软件测试中最难解决的问题之一[1].
测试预言问题的综述文献[1]将测试预言生成的研究分为基于软件形式化规格说明或形式化模型(例如状态机或时序逻辑规范等)的测试预言生成方法(317篇相关论文)、基于各种软件制品(例如需求和设计文档、软件执行的属性信息、软件其他版本等)的测试预言生成方法(245篇相关论文)、基于常识或隐含的知识生成测试预言(76篇相关论文)这3类.第1类需要软件开发人员或测试人员给出软件的形式化规格说明,人工参与的工作量较大,形式化规格说明缺乏以及程序行为描述不全面等,是该类方法面临的极大挑战;第2类研究克服了第1类研究面临的挑战,正在成为一个活跃的研究方向,主要研究包括基于规格说明或编程接口挖掘的方法、基于程序文档的挖掘方法、蜕变测试、基于源码的静态和动态分析方法以及基于机器学习的方法等,该类测试预言的生成方法包括全自动的方法或人工辅助的半自动化方法,其中,半自动化方法较多;第3类应用领域较窄,仅针对特种类型或特定的应用范围的软件.
智能化技术在测试预言生成方面的应用研究具有鲜明的学科交叉特点,目前研究成果相对较少,上述第 2类测试预言生成方法的研究中逐步开始出现智能化技术的应用.本文的工作属于无需测试人员干预的测试预言自动生成方法,借助揭示成功和失败概率的敏感变量,采用监督的机器学习算法——线性感知机作为测试预言自动生成的模型,收集部分测试用例的语句覆盖、不同断点处的内存变量及其取值的集合等数据信息作为训练集,观察新测试用例执行的相应语句覆盖和内存变量集等信息,对该新测试用例在不同断点处的执行结果是成功还是失败进行预测,自动生成测试预言.本文成果可以形成测试用例集合构造的“滚雪球效应”,不断迭代自动生成新测试用例或回归测试用例的测试预言.
本文第 1节首先给出相关定义和假设,在此基础上,给出求解断点处敏感变量集的算法,并应用线性感知机算法求解断点处成功或故障概率的门限值,提出本文的测试预言生成算法.第2节对算法进行讨论.第3节给出实验对象和实验方法.第4节通过案例对算法进行阐释和验证.第5节将已有研究工作进行总结,并与本文工作进行对比分析.
1 测试预言自动生成方法
1.1 相关定义
本文测试预言生成方法用到的定义如下.
定义 1(测试用例ta和tb的相似度Sim(ta,tb)).设测试用例ta和tb执行的语句集合分别为A(其元素个数记作|A|)和B(其元素个数记作|B|),|A∩B|表示A与B交集的元素个数,则ta和tb的相似度定义为Sim(ta,tb)=2×|A∩B|/(|A|+|B|)∈[0,1].Sim(ta,tb)的值越大,ta和tb的相似度越高:如果A=B,则Sim(ta,tb)=1,ta和tb的相似度最高;如果A∩B=∅,则Sim(ta,tb)=0,ta和tb的相似度最低.
定义2(内存变量).内存变量是一个二元式[var,val],其中,var表示变量名,val表示该变量的值.
定义3(两个内存变量相等).两个内存变量[vara,vala]和[varb,valb]相等当且仅当vara=varb和vala=valb.
定义4(两个内存变量集合M和N的交集).两个内存变量集合M和N的交集记作M∩N,定义为M与N中相等的内存变量的集合.
定义5(两个内存变量集合M和N的差集).两个内存变量集合M和N的差集记作M-N,定义为与N中变量名相同而变量值不同的M中内存变量的集合.
定义6(敏感变量的定义).一个敏感变量t是一个内存变量二元式t=[sv,v],其中,sv表示敏感变量的名字,v表示敏感变量的值.
1.2 相关假设:
根据程序测试和调试经验,本文的算法思想基于下述基本假设.
· 假设1:变量集对成功和失败具有一定的揭示能力.
对于高相似度的测试用例(见定义1)形成的一个集合St而言,在每个断点处,St中测试用例执行的变量集合的交集或差集对程序执行的成功概率或失败概率具有一定的揭示能力.
· 假设2:不同断点处变量集合对成功或故障的揭示能力不同.
因为故障发生程序的某个位置且故障有传播能力,断点位置越靠后,其相应变量集合对成功或故障的揭示能力逐步增强.
1.3 测试预言生成算法
已知一个程序、一个测试用例集合及各测试用例执行成功或失败的信息,本文通过在程序中设置批量断点的方法收集所有测试用例在各断点处的内存数据以及代码覆盖信息作为训练集;然后根据新测试用例的执行,计算各断点处的敏感变量集合,并应用线性感知机算法计算该断点处执行失败或成功概率的门限值;在此基础上,本节给出了一种基于内存分析的测试预言自动生成方法,即对新产生的测试用例执行同一程序的运行结果是成功还是失败进行预测,自动生成测试预言(见下文算法1).为了阐述本文提出的测试预言生成算法,表1给出了算法中涉及的符号名称及其含义描述.
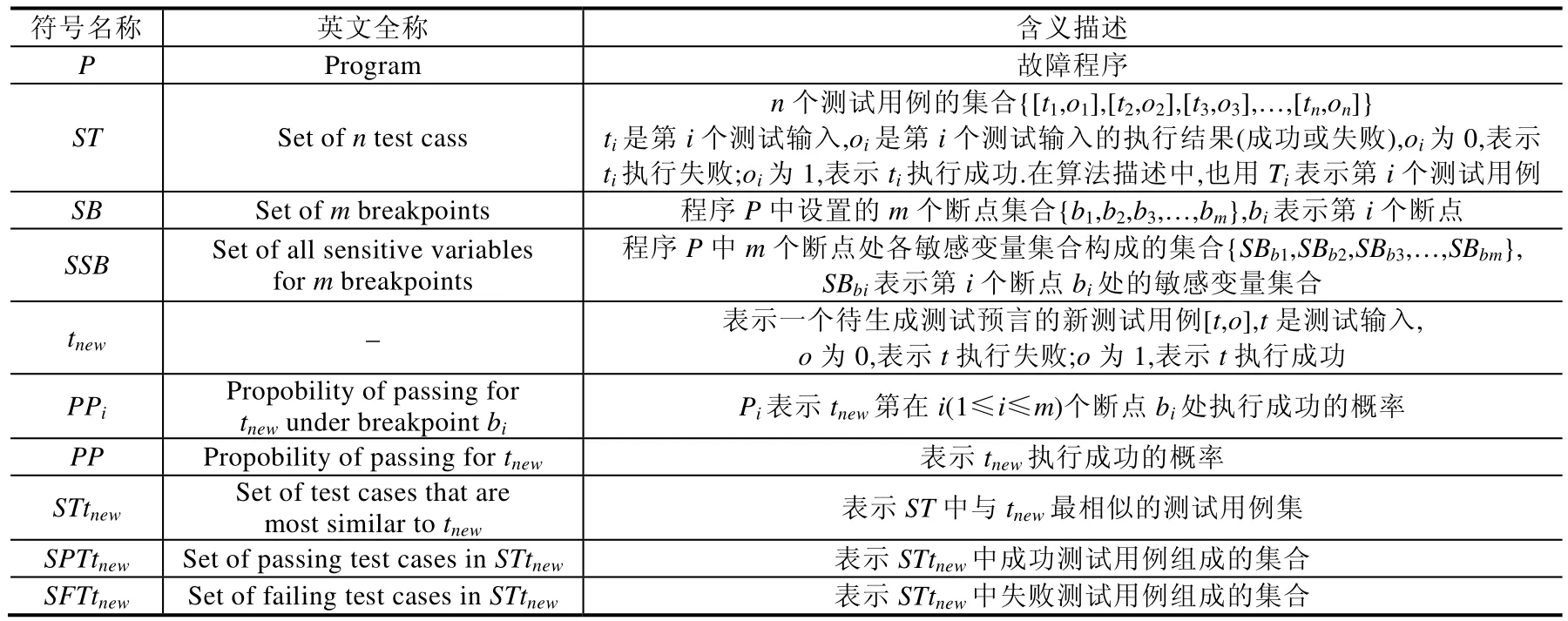
Table 1 Notations and their meanings in this section's algorithm表1 本节算法中涉及的符号名称及其含义描述
1.3.1 算法1:测试预言生成算法
给定P,ST,SB和tnew的测试输入t,首先计算ST中与tnew最相似的测试用例集合STtnew(见下述算法1伪代码中的第1行~第20行).将获得的STtnew分为最相似成功测试用例集SPTtnew和失败测试用例集SFTtnew,调用后文算法2计算SB中每个断点处的敏感变量集.
· 如果SPTtnew≠∅,SFTtnew≠∅,求得的敏感变量的含义为:从所有与tnew相似正确测试用例和失败测试用例的执行来看,可能错误的内存变量有哪些,在这种情况下,敏感变量称为“故障敏感变量”;
· 如果SPTtnew≠∅,SFTtnew=∅,求得的敏感变量的含义为:从所有与tnew相似的正确测试用例的执行来看,可能正确的内存变量有哪些,在这种情况下,敏感变量称为“成功敏感变量”;
· 如果SPTtnew=∅,SFTtnew≠∅,求得的敏感变量的含义为:从所有与tnew相似的失败测试用例的执行来看,可能错误的内存变量有哪些,在这种情况下,敏感变量称为“故障敏感变量”.
然后调用后文算法3,计算bi处的门限值Thresholdbi,根据算法1的第21行~第79行陆续计算各断点处程序执行成功的概率PP1,PP2,PP3,…,PPm.
最后,对于序列PP1,PP2,PP3,…,PPm,用等差序列作为对预测结果影响所占的权重,分别记为a1,a2,a3,…,am,则等差数列的公差为d=(am-a1)/(m-1),可以求得该等差数列首项a1=1/m-(am-a1)/2=3/4m,其余各项为ai=a1+(i-1)d,测试用例执行程序P成功的概率为PP=PP1*a1+PP2*a2+…+PPm*am.
算法1的伪代码如下所示(第1行~第86行).
算法1.GeneratingTestOracles.



1.3.2 算法2:敏感变量集求解算法
给定输入P,SPTtnew,SFTtnew以及SB中第i个断点bi,设两个临时变量ST1和ST2.
· 如果SPTtnew≠∅,SFTtnew≠∅,则令ST1=SPTtnew,ST2=SFTtnew;
· 如果SPTtnew≠∅,SFTtnew=∅,则令ST1=SPTtnew,ST2=SPTtnew;
· 如果SPTtnew=∅,SFTtnew≠∅,则令ST1=SFTtnew,ST2=SFTtnew.
令x=|ST1|,y=|ST2|,首先计算得到个内存变量集合{dj1,dj2,dj3,…,djy},将其存入哈希表Dpj,其中,djk(1≤k≤y)作为哈希表的key(记作djk.key),该内存变量出现的次数作为哈希表的value(记作djk.value)
然后,可计算得到的x个哈希表Dp1,Dp2,Dp3,…,Dpx,计算哈希表Hbi=Dp1∪Dp2∪…∪DpX,其中,∪表示的含义为:各个Dpj(1≤j≤|SFTtnew|)中,key不同则合并;key相同,则value相加.
最后对Hbi中各value值从大到小排序,key值为前20%的变量(取key值较大的变量作为敏感变量)加入SBbi,算法结束,返回SBbi.
算法2的伪代码如下所示(第1行~第29行).
算法2.CalculateSensitiveVariabls.


1.3.3 算法3:应用线性感知机算法求解每个断点处门限值
给定输入P,SPTtnew,SFTtnew,bi以及SBbi,首先初始化候选门限值二维数组temp[][]为 0,两维数组长度都为SPTtnew∪SFTtnew中测试用例个数.对于SPTtnew∪SFTtnew中每个测试用例tk(1≤k≤|SPTtnew∪SFTtnew|),将其作为一个新测试用例,分别计算temp的第k行元素,根据“测试预言生成算法”,对于SPTtnew∪SFTtnew中每个测试用例tk(1≤k≤|SPTtnew∪SFTtnew|),将其作为一个新测试用例tnew;计算每个候选门限值的预测成功率,将temp中预测准确率最大的候选门限值存入Thresholdbi,算法结束,返回Thresholdbi.
算法3的伪代码如下所示(第1行~第34行).
算法3.Threshold.


2 实验对象及实验方法
本文采用SIR(software-artifact infrastructure repository)知识库[2]提供的5个C程序实验对象和从开源网站travis-ci上下载的两个C程序实验对象expresstionParser和sort(网址:https://travis-ci.org/swenson/),通过实际案例程序阐释本文给出的测试预言自动生成方法的有效性.表2给出了实例验证过程中所使用的每个案例名、功能、故障版本数、测试用例数以及正确版本的源码行数等信息.
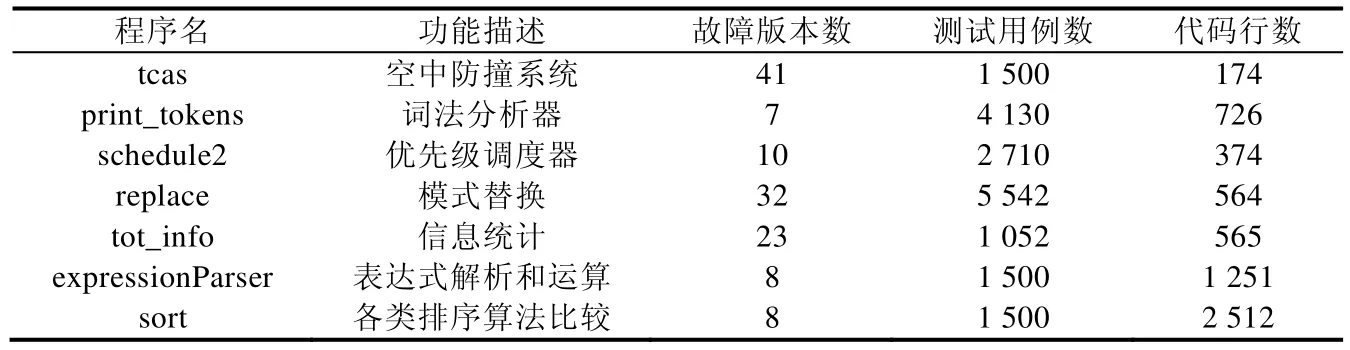
Table 2 Experimental objects表2 实验对象
为了将提出的测试预言生成算法进行实践,本文开发了图1所示的实验辅助工具,工具的开发环境是Ubuntu Linux 10.04.为了方便与SQLite数据库以及GDB调试集成,本文应用Python语言和shell script实现工具的开发,辅助工具源码TestOracleGen.rar在https://github.com/machunyan/LCEC网站上可以公开下载.工具的主要模块功能阐述如下.
1)程序代码分析模块.该模块负责分析源文件,根据断点的设置原则进行断点标注(本文实验过程中设置的断点设置原则为:以return和exit作为结束的行,本实验辅助工具允许用户批量自定义断点位置),为程序执行以及执行过程中调用GDB命令获取内存数据做准备.
2)程序执行分析模块.该模块运行每一个测试用例,在程序运行过程中获取断点处程序执行的内存变量集,并通过gcov软件获取每个测试用例运行时的程序覆盖信息.
3)数据存储模块.该模块将程序代码分析模块和程序执行分析模块得到的断点信息和测试用例的执行覆盖信息存入数据库.在分析所有测试用例执行覆盖的基础上,对不同覆盖进行分类,计算测试用例之间执行覆盖的联系.
4)预言模块.该模块根据上述 3个模块收集的故障程序的断点信息、测试用例运行故障程序时所有断点的内存变量信息以及执行语句覆盖信息,执行第 1.3节中的测试预言生成算法,对测试用例运行同一故障程序的运行结果是成功还是失败进行预测.
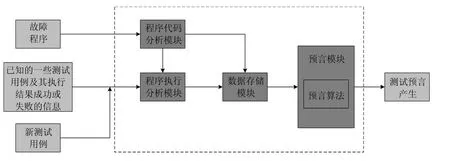
Fig.1 Assistant tool framework for experiments图1 实验工具总体架构
采用该实验辅助工具的具体实验步骤如下.
1)将工具复制到需要进行测试预言生成的测试程序所在的文件夹中.
2)在测试程序的文件夹中建立output文件夹,用于存放程序的执行覆盖文件cov_result和mod_classify_result.
3)将已知执行结果的所有测试用例存放在文件trainset中.
4)运行数据收集程序 train.sh,输入参数为已知结果的测试用例存放的文件名、测试程序对象名、测试故障程序版本号.数据收集程序执行完成后,将收集的所有数据信息存放于数据库中.
5)运行预测程序predict.sh,计算新测试用例的测试预言.
3 实验结果及分析
3.1 实验对象的实验结果及分析
Tcas、print_tokens、schedule2、replace、tot_info、expressionParser和 sort共129个故障版本.为每一个故障版本设计100个新的测试用例(其中,成功和失败的比率与训练集一致),计算这100个测试用例预言正确的个数.图2~图8分别展示了每类程序所有故障版本的预言正确数目的折线图.图中横轴表示每类程序的版本号,竖轴表示100个新测试用例使用本文的测试预言自动生成方法预测正确的个数.

Fig.2 Test oracle prediction results of 41 tcas versions图2 Tcas的41个版本的测试预言预测结果

Fig.3 Test oracle prediction results of 7 print_tokens versions图3 Print_tokens的7个版本的测试预言预测结果
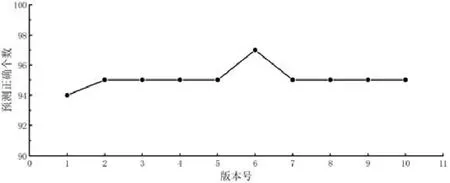
Fig.4 Test oracle prediction results of 10 schedule2 version图4 Schedule2的10个版本的测试预言预测结果
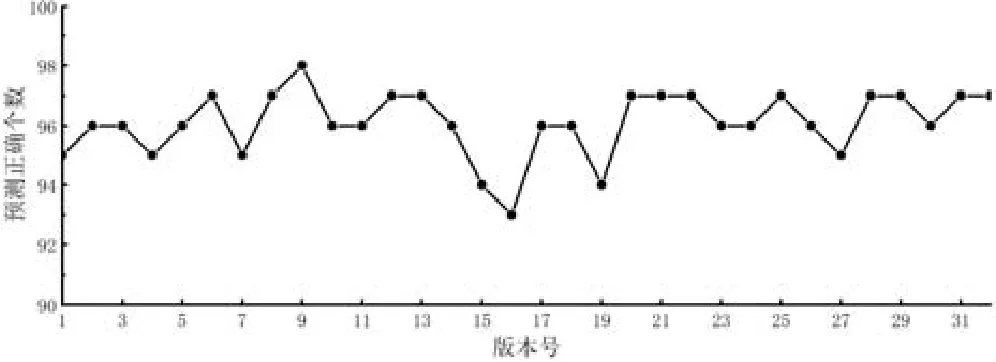
Fig.5 Test oracle prediction results of 32 replace versions图5 Replace的32个版本的测试预言预测结果

Fig.6 Test oracle prediction results of 23 tot_info versions图6 Tot_info的23个版本的测试预言预测结果

Fig.7 Test oracle prediction results of 8 expressionParser versions图7 ExpressionParser 8个版本的测试预言预测结果
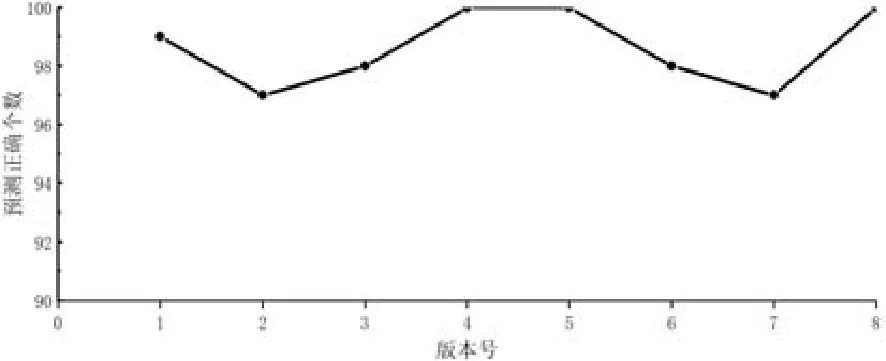
Fig.8 Test oracle prediction results of 8 sort versions图8 Sort 8个版本的测试预言预测结果
程序tcas共有41个故障版本,每个版本运行100个新的测试用例,预测情况如图2所示.预测效果最差的是V39,91个测试用例预测正确.V3、V7等8个故障版本的100个测试用例全部预测正确.41个tcas版本预言生成的正确率平均为96.3%.
程序print_tokens共有7个故障版本,每个版本运行100个新的测试用例,预测情况如图3所示.预测效果最差的是版本V4,92个测试用例预测正确.预测正确个数最多的是版本V2,预测正确95个.7个版本平均预言正确率为93.7%.
程序 schedule2共有 10个故障版本,每个版本运行 100个新的测试用例,预测情况如图4所示.故障程序schedule2的预测效果比较平均,有8个版本预测正确95个.10个版本平均预言正确率为95.1%.
程序replace共有32个故障版本,每个版本运行100个新的测试用例,预测情况如图5所示.预测效果最差的是版本V16,93个测试用例预测正确.预测正确个数最多的是版本V9,预测正确98个.32个版本平均预言正确率为96.1%.
程序tot_info共有23个故障版本,每个版本运行100个新的测试用例,预测情况如图6所示.预测效果最差的是版本V21,91个测试用例预测正确.预测正确个数最多的有版本V8,V11和V15,预测正确98个.23个版本平均预言正确率为96.2%.
程序expressionParser,sort各有8个故障版本,每个版本运行100个新的测试用例,预测情况如图7、图8所示.8个版本平均预言正确率分别为97.5%和98.6%.
综上,对129个故障版本,每个版本预言100个测试用例,平均预言正确率为96.2%,说明了本文给出的测试预言自动生成方法预测的有效性.
3.2 实验结果与其他相似方法的比较
从采用机器学习、现有测试用例的输入及执行结果协助自动生成新测试预言和完全自动化的角度来看,与本文相似的工作有文献[3-5]等.与他们相比,本文工作的优势如下.
1)本文训练集数据量要求宽松,文献[5]要求失败的输入和成功的输入各占一半,而且数据量偏大,在实际应用中不可行.
2)本文测试预言的生成应用范围更广.针对某个新的测试输入,上述 3个文献生成的测试预言准确率完全依赖于训练集中的测试输入特征,在具体应用中具有一定的局限性和针对性;而本文的方法则是收集训练集中测试输入执行的语句覆盖、不同断点处的内存变量及其取值的集合等大量数据信息,更能真实反映被测试程序的行为,对于哪些输入数据个数少、输入取值有限或程序执行是否成功与输入的对应关系不明显等的应用程序而言,本文的方法皆可应用.
3)本文的实证研究更深入和合理.上述文献的实证研究均通过个别案例程序并注入若干故障来检测方法的有效性.从故障版本的数量(共 129版本)、故障类型的数量(比较和逻辑等各类运算符错误、常量赋值错误、变量定义错误、语句丢失、多余语句、变量赋值错误)和产生的测试预言数量角度,本文的实验更加深入和合理.
4)测试预言的准确率方面本文有一定优势.从文献[5]的实验结果来看,对于案例Tcas而言,Sir知识库中有效测试用例共 1 500个,其中成功测试用例约占 85%;该文献在现有测试用例的基础上又构造了1 500个测试用例作为训练集,其预测准确率为98.72%;但在1 500个测试数据集(还要求成功输入与失败输入数量相当)的情况下,其预测准确率约为82%(文中未指明是否针对Sir知识库中41个版本都进行了实验,也未指明测试预言产生的数量).而本文针对Tcas的41个版本,每个版本均生成了100个测试输入的测试预言,平均预测准确率为96.3%,其中,Tcas的第3、7、15、17~20和28这8个版本的预测准确率为 100%.文献[5]中的其他实验对象,预测准确率最低为 84.66%.本文在其他实验对象中,在最少训练集合1 052个的情况下,预测准确率最低平均为95.1%.
4 方法讨论
4.1 方法的实用性
本文提出的测试预言自动生成方法独立于源代码,不需要向源代码中插入任何断言;独立于编程语言,对任何一种编程语言都适用,没有构造形式模型的限制,具有很强的灵活性,适用范围广.本文的测试预言预测方法也适用于其他编程语言,例如Java和C++语言的程序,但是本文搭建的实验环境仅支持C语言程序.
在软件调试过程中,程序员需要通过在程序关键语句处加断点,通过分析和比较部分断点处的变量取值以及语句执行序列等上下文来诊断故障,这是故障诊断的核心行为.所以本文假设符合实际情况,这一点在文献[6]的研究成果中也得到印证.
算法1生成的tnew测试预言的有效性与集合T和St密切相关,如果集合T或St的元素个数非常少,则算法输出结果的准确率就会降低.该算法建立在已经存在的测试用例集合T之上,要求集合T存在一定数量.根据目前程序(C、C++、Java等语言程序)的特点,仅有分支或while循环的判断条件可能导致测试用例执行的路径不同,所以在实际求解中,T中与tnew最相似的测试用例集St也会满足算法求解的要求.
算法1的有效性并不依赖于T中测试用例的类型,并不要求T必须包含成功测试用例或必须包含失败测试用例.T可以仅包含成功测试用例,也可以仅包含失败测试用例,也可以既包含成功测试用例又包含失败测试用例.所以本文训练集数据量要求宽松,并不要求失败的输入和成功的输入各占一半保持均衡.
本文测试预言生成算法在实际项目应用中可以迭代“滚雪球”式生成新的高质量测试用例.例如在项目真实的测试实践中,如果已经运行了 100个测试用例都执行成功,那么对若干新的测试输入,可以用测试预言生成算法预测他们的输出成功还是失败,提示用户重点关注预测失败的新测试输入的执行.
4.2 测试预言生成的准确率问题
本文生成的某个新测试用例tnew的测试预言准确率与下述几个方面的要素密切相关.
1)给定tnew,与tnew相似测试用例集合St相关,St元素个数越多,训练集质量越高,预测结果趋于越精确.
2)与各断点处敏感变量集的成功或失败的揭示能力相关,例如枚举变量、布尔变量及取值为离散值的变量,测试执行时,它们的取值较为集中而且重复率较高,所以这些变量一定被作为敏感变量求解出来,他们揭示程序成功或失败的能力更强.
本文通过分析不同版本的故障发现,如果被测试程序的故障语句是每个测试用例一定执行的语句,与tnew相似测试用例个数较多,我们的方法生成测试预言的准确率为100%,例如Tcas的V3、V7等V8版本.如果被测试程序的故障语句是if或 while中的语句,其对于测试输入集合而言,故障语句未必遇到每个测试用例都执行,故障语句执行次数越少,预测准确率就越低.主要原因是故障语句执行次数少,导致与预测测试用例高度相似的测试用例过少,并且故障敏感变量的影响指标(揭示成功或失败的能力)明显下降,例如 print_tokens的故障版本v4、tcas的故障版本v33和replace的故障版本v16等,它们的故障语句都在多层嵌套的if判断条件中,通过其他条件不变,增加相似测试用例的控制实验,我们发现,如果增加相似测试用例集合中的个数,它们的预测结果会进一步提高.这也印证了与测试预言准确率相关的上述要素1)和要素2).
4.3 方法成本的评估
目前,本文方法未考虑多线程程序以及通过界面与用户交互的图形界面程序.测试套件下被测试程序各断点处变量值集合相关信息收集的工作量较大,它是测试预言生成算法的主要开销,也是本文的主要缺点和代价.
测试预言预测速度受断点个数P、全部测试用例用例的个数T以及与待预测测试用例相似的测试用例个数N的影响.算法1计算相似测试用例集合的复杂度为O(T2),每增加一个断,算法1就要在该断点处执行获取内存数据、计算敏感变量集和门限值等操作,因此算法1的效率与P呈线性关系.算法2比较相似测试用例集合中成功输入(令程序执行成功的输入)与失败输入(令程序执行失败的输入)的内存变量与其取值,计算敏感变量集合,该计算过程的复杂度为O(N2).最后,算法 3在每个断点处计算门限值,所以每次计算的复杂度是O(N2).由于算法1调用了算法2和算法3,综上所述,算法1的算法复杂度较大,为O(T2+P×N2).
5 相关工作及结论
一些研究成果需要测试人员手动输入规格说明或模型,或训练神经网络的方法,辅助部分测试预言的自动生成.例如:(1) 在回归测试中,一些研究基于规格说明和组件应用编程接口规范,应用人工神经网络自动生成测试预言[7-10],这些方法需要手工构造规格说明;(2) 由测试者首先定义包含蜕变关系和数据挖掘算法的 JML规格说明,然后采用蜕变测试技术来产生测试预言[11],中文参考文献[1],通过实验研究蜕变测试技术产生测试预言的有效性;(3) ASTOOT通过检查两个不同的执行场景来产生测试预言,但是需要测试人员提供被测试系统的代数规格说明[12];(4) Li等人提出了基于模型的测试预言生成策略,包括采用状态不变量作为基于状态图测试预言生成的依据[13];(5) Guo等人首次提出一个通用的声明框架,该框架基于测试人员撰写的语义和控制流图生成测试预言[14];(6) Wang等人[15]利用支持向量机 SVM作为监督的机器学习算法,测试人员采用智能测试预言库对被测试程序代码进行注释,根据函数调用收集测试跟踪信息,对训练集中每个测试轨迹提取特征作为SVM 算法的输入,然后使用构建的 SVM 模型作为测试预言,通过两个案例程序的实验结果阐释了方法的有效性.
无需测试人员干预的测试预言自动生成方法.Arantes等人采用逆向工程,通过静态和动态源代码分析的方式构造程序的一个结构化模型,然后基于该模型自动生成测试预言[3],提出的方法检测 4了个案例中的部分故障.Goffi等人借助现代软件系统,可以通过不同的执行顺序提供相同的功能的特征,通过检查给定执行序列与所有可用的冗余和假设等效的执行序列之间的等价性,设计和开发了一种完全自动化产生测试预言的技术,方法生成的测试预言发现了多达53%的错误,并对开发人员撰写的16个案例中4个案例的测试预言,应用该方法提升了其有效性[4].Shahamiri等人以被测试程序输入空间的行为作为训练集合,应用神经网络生成新测试集输入的测试预言;然后,该测试预言的预期结果与被测试程序真实的输出进行比对[16,17];最后,他们通过两个案例阐释其研究成果的有效性.由于被测试单元没有输出或输出形式的多样性,该方法以被测试单元的输出域作为准则产生测试预言有很大的局限性.Gholami等人[5]以测试输入及其对应的成功或失败标记作为训练集,应用神经网络算法建立一个模型,为测试输入产生测试预言.他们通过两个案例研究阐释了其方法的有效性,但是该方法需要的训练集数量较大,而且要求失败的输入和成功的输入各占一半,而现实中积累大量执行失败的输入是不可能的.
本文工作属于无需测试人员干预的测试预言自动生成方法.本文采用监督的机器学习算法线性感知机作为测试预言自动生成的模型.首先,本文收集部分已知测试用例执行的语句覆盖和内存值集合,给出了程序在给定断点处的内存中敏感变量集求解算法;然后,将已知测试用例集合作为训练集,应用线性感知机求解每个断点处的门限值;最后,提出新测试用例的测试预言自动生成方法.
未来的工作将采用大型真实案例对本文提出的测试预言自动生成方法进行进一步分析与验证;同时,进一步探索测试预测的准确率与故障类型的关系.
猜你喜欢
辽河(2022年4期)2022-06-09
计算机系统应用(2022年2期)2022-05-10
电子技术与软件工程(2021年18期)2021-11-21
电脑报(2019年31期)2019-09-10
电脑报(2019年20期)2019-09-10
电子技术与软件工程(2019年12期)2019-08-22
当代陕西(2019年13期)2019-08-20
初中生世界·九年级(2019年6期)2019-08-15
电脑爱好者(2015年21期)2015-09-10
计算机工程与设计(2014年4期)2014-02-09
