
基于框架语义扩展训练集的有监督事件检测方法
2019-06-03 10:52:52张婧丽周文瑄姚建民周国栋朱巧明
中文信息学报 2019年5期
张婧丽,周文瑄,洪 宇,姚建民,周国栋,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
事件抽取旨在从文本中识别事件信息,在问答、文本分析和知识图谱等研究中都有重要应用价值。自动内容抽取(Automatic Content Extraction,ACE)将事件抽取定义为四个任务: 触发词识别、事件类型识别、事件角色识别和事件元素识别。本文主要研究前两个任务: 触发词识别和事件类型识别。该领域将这两个任务并称为事件检测。具体如例1所示,目标是识别出句子中的触发词“战斗”及其事件类型Attack。
例1我支持那些为自己国家进行战斗的人。
触发词: 战斗
事件类型: Attack(袭击)
目前,事件检测逐步从传统机器学习方法转向神经网络模型,性能得到较大提升[1-5]。但英文语料数目少,事件类型样例分布不平衡,仍是这一任务中重要的研究难点。ACE英文语料仅有3 966条句子级别的事件描述,事件类型Attack(袭击)的样例数为1 537条,而事件类型Nominate(任命)的样例只有12条,样例数目少,且分布严重不平衡。这使得学习模型在样例稀疏的事件类型上训练不充分,难以识别相关事件。上述问题均会直接影响事件检测模型的性能。
为此,本文提出: 利用框架语义结构与事件类型描述之间的相似性,以及FrameNet[6](FN)语料库中丰富的样本与确切的语义架构辅助事件检测。首先,采用框架类型识别方法获得ACE语料中触发词的框架类型,按事件类型与框架类型映射关系的强弱区分正负例框架,进而获得“正例”,用以扩充训练集。通过在相同模型上进行实验,验证该方法是否能缓解语料稀疏和样例分布不平衡问题。实验结果显示该方法对触发词识别和事件类型识别均有较好的效果。
本文的主要研究贡献如下:
(1) 提出利用FrameNet中的大量数据扩充ACE事件检测语料。
(2) 提出构建框架类型与事件类型映射关系的新方法。
(3) 检验并分析了利用FN中的例句扩充ACE语料训练集对事件检测性能的影响。
本文的组织如下: 第1节介绍了相关工作;第2节陈述利用FN辅助事件检测的原因;第3节对本文中所使用的方法进行介绍,包括框架类型的识别方法与事件检测的语料处理方法;第4节介绍了本文采用的事件检测模型;第5节介绍实验架构及结果分析;第6节总结全文并对未来工作进行展望。
1 相关工作
目前,事件检测技术的研究思路主要包括两个方面,其一是以语义编码为基础的表示学习和深度计算;其二是借助外部资源的训练数据获取与扩展。
从模型角度,事件检测技术逐步从传统机器学习方法转向神经网络方法。Li[7]等基于结构化的感知机,将局部特征与全局特征进行结合,利用充分的句子特征信息进行事件抽取;Nguyen[8]等将实体类型信息与词的位置信息作为特征,并利用词向量的形式表示,通过卷积神经网络(Convolutional Neural Network,CNN)自动学习这些特征,取得较好效果;Chen[9]等提出动态多池化卷积神经网络模型(Dynamic Multi-Pooling Convolutional Neural Network,DM-CNN),即通过学习词向量得到词级的特征表示,再利用动态多池化层的卷积神经网络获得句子级的特征表示,从而保存句子的关键信息;Tang[10]等提出双向长短时记忆模型(Bidirectional Long Short Term Memory,Bi-LSTM),通过对句子中每个词的前面和后面的内容建模,能够很好地捕获句子中的长期依赖信息;Feng[11]等提出将双向Bi-LSTM与CNN两个模型进行结合,先通过Bi-LSTM对句子中每个词的前向和后向内容进行语义编码,再经过一个CNN卷积神经网络捕获结构化的信息,这种联合的模型在事件检测任务上取得了很好的效果;Liu[12]等则在人工神经网络(Artificial Neural Network,ANN)的基础上加入注意力机制,从而使模型对句子中对触发词识别与事件类型分类有重要影响的实体信息加深关注,从而有效捕获重要信息。
从语料角度考虑,Ji[13]等将事件检测范围由单文档扩展到主题相近的文档,通过在局部特征基础上加入相近文档特征来改进事件检测性能;Hong[14]等提出跨实体推理的事件抽取方法,即应用命名实体作为额外的判别特征辅助事件抽取;陈亚东[15]等在Li等的Joint系统基础上,将框架语义知识作为特征加入其中,证明了框架语义作为特征的有效性;Liu[16]等考虑到框架语义与事件在结构上的一致性,应用提前训练好的事件检测模型对FrameNet中的例句进行事件类型标注,同时采用框架语义中的相关规则进行约束,得到事件检测的扩充语料,改进事件检测性能;Chen[17]等提出一种自动标注数据集的方法来获取大规模数据用于事件抽取,利用知识图谱(Freebase)自动找到一个事件的触发词,再利用FrameNet对触发词进行过滤和扩展,最后进行自动标注生成标注后的数据集,通过DM-CNN自动进行事件的抽取,实验证明该数据集可以达到与人工标注的数据集同等的效果。
FrameNet是框架语义的典型资源库,包含了具有框架语义规则的英文单词的描述与框架标注。Narayanan[18]等首次将FN应用于问答领域;之后,Shen[19]等也在问答任务中引入FN知识库,获得了较好的性能。基于FN的研究还有Padó[20]等的篇章识别任务,Burchardt[21]等的文本蕴含任务。对于这些任务,FN中的框架知识均起到较好的作用。此外,Liu[16]等首次将FN应用于事件抽取领域,利用FN中的例句扩充ACE语料,使事件抽取性能有了较大提升。
2 基于FrameNet的事件检测
针对引言中提出的问题,本文利用FN辅助事件检测。主要原因有两个,下面分别进行介绍。
2.1 框架与事件的类型可比性分析
ACE 2005[22]定义了33种事件类型,每种事件类型对应多个触发词,每个触发词包含一组样例。而FN是以框架语义学为基础形成的权威知识库,具体结构如图1。FN中定义了多种框架,每种框架包含一组词法单元,每个词法单元又包含多条已标注框架类型的样例。因此,框架类型与事件类型具有极其相似的结构,可形成较为对称的可比关系,一些框架甚至可以直接表达某些事件。表1列举了部分映射关系,如框架类型Fining与事件类型Fine均表示“罚款”含义。此外,FN中的词法单元与事件中的触发词也具有对应关系。如例2中的触发词与词法单元均为“fractured”。
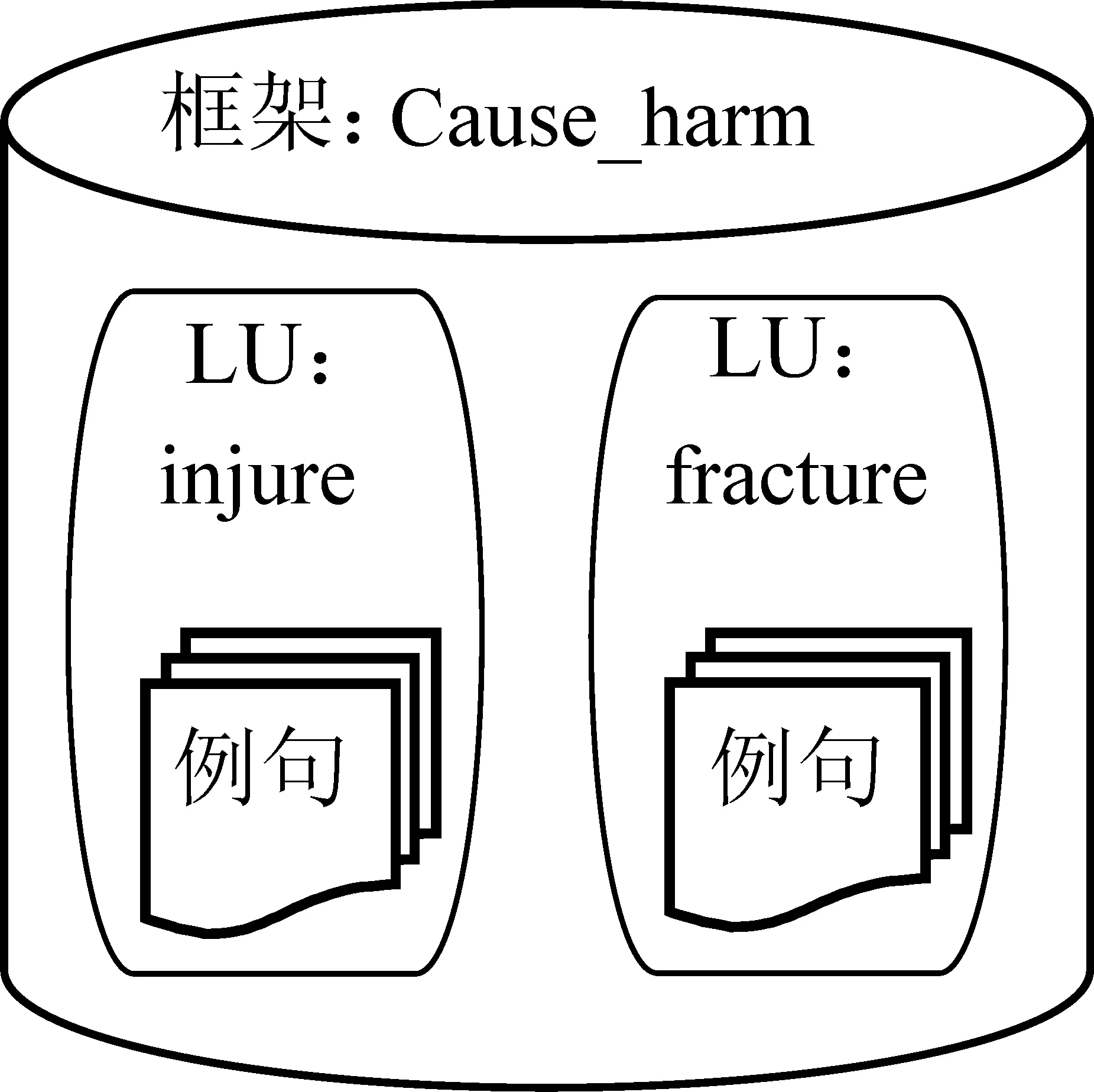
图1 FN中框架、词法单元与例句的关系注: 该图以框架类型Cause_harm(造成伤害)为例,描述框架、词法单元与例句的关系。图1中的符号LU表示词法单元,相当于中文样例中的词。图中框架包含38个词法单元,这里只列举其中两类,分别为injure(受伤)和fracture(骨折),每个LU平均包含15个例句[注]https://framenet2.icsi.berkeley.edu)
例2Shehasfracturedlegsandherrightforearm.
(译文: “她的腿和右前臂骨折了”)
触发词: fractured(骨折)
事件类型: Injure(受伤)
(注: 该例句来自ACE2005英文事件语料)
词法单元: fractured(骨折)
框架类型: Cause_harm(造成伤害)
(注: 该词法单元与框架标记来自FrameNet语料)
2.2 FN含有丰富语料
FN中含有大量词法单元,并为每个词法单元都标注了充足的例句。FrameNet 1.7 有157 631条例句,而ACE语料仅有3 966条。例2中的触发词“fractured”在ACE语料中只有一条例句,若作为测试样例,那么在训练语料中将不存在用词一致的样本,从而导致两种可预见的瓶颈:
• 其一: 若训练语料中不存在同义词,则即使充分的表示学习和语义编码也无法有效获取该词的语义表示,造成知识缺失,影响测试阶段的判别;
• 其二: 目前,语义编码与学习的神经网络模型,在追求词一级语义共享空间的时候,需要对网络层数进行控制,当层数较少时,上述训练阶段语义缺失的样本将无法得到有效模拟,即使同义词存在于训练集,其表示的可共享性也将较低,当层数较高时,一味地追求语义表示的共性,则不仅提高计算成本(时空消耗),也将影响词义表示的独特性,从而影响模型的实用性。
但在FN语料中,该词含有11条例句,若已知框架类型Cause_harm与事件类型Injure具有映射关系,则可用这11条例句扩充训练集,丰富训练语料。表1给出了部分框架与事件类型映射表。
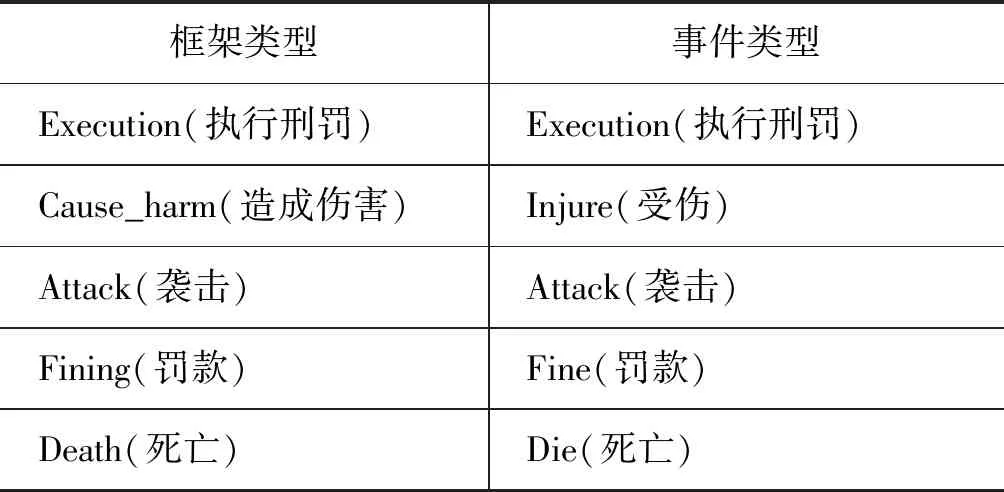
表1 部分框架与事件类型映射表
3 事件检测的语料获取
本文利用框架语义知识从FN中获取例句扩充训练数据,从而优化触发词识别和事件类型识别任务。这一过程包括两方面工作: 其一,获取触发词的框架类型,并区分正、负框架;再通过框架标签得到触发词在FN中对应的例句。其二,将获得的例句加入训练集,用产生的新数据训练事件检测模型。
3.1 框架类型识别
本文采用以下两种方法进行框架类型识别。
方法一: 同陈亚东[15]等、Evangelia[23]等一样,采用框架语义分析开源工具SEMAFOR[注]http://www.ark.cs.cmu.edu/SEMAFOR/实现框架类型识别。该模型由FN中157 631条例句训练得到。本文旨在用该工具识别ACE语料中触发词的框架。SEMAFOR对每个句子中的触发词能识别出唯一的框架类型,如例3中的框架标签Possession(拥有);再通过检索FN得到该触发词的其他框架。本文将SEMAFOR识别的框架指定为正例框架,该框架下的例句为“正例”,其他框架即为负例所在的框架。
例3Thecountryhadbannedawomanfromhavingmorethanonechild.
(译文: “以前,国家禁止生二胎”)
触发词: having(有)
事件类型: Life(生命)
事件子类型: Be-Born(出生)
SEMAFOR识别的框架: Possession(拥有)
触发词的其他框架: Giving_birth(给予生命)、Ingestion(采食)、Have_associated(有关联)、Inclusion(入选)
方法二: 由于框架与事件具有较为对称的可比关系,甚至可直接用框架类型表示事件类型,所以二者的标签具有较高相似度。本文利用这一点进行框架类型识别。首先,检索FN得到触发词对应的所有框架类型标签,再计算这些框架标签与触发词的事件类型标签及事件子类型标签的相似度;计算框架与事件的最终相似度,从而判断得到正、负框架。具体计算方法如下:
(1) 将触发词的框架标签与事件类型标签及事件子类型标签都视作短语(即短句子),采用Sanjeev[24]等计算句子词向量的方法得到每个短语的词向量表示。首先,利用式(1)计算短语中每个词的重要性fi:ni表示第i个词在词表中出现的次数,a为参数,本文设置为10-3。再利用式(2)计算整个短语的词向量v:L为短语长度,即短语中词的个数,νi表示第i个词的词向量。将每个词的词向量乘以其重要性fi后求和,即对短语中的每个词按其频率分配不同重要性。再除以L,即得到整个短语的词向量表示。
(3)
(3) 按上述方法计算得到该触发词的每个框架标签与事件子类型标签的相似度(记为s2)。
(4) 利用式(4),对上面得到的两个相似度结果求算术平均,得到该触发词的每个框架标签与事件标签的最终相似度s。
(4)
(5) 按相似度值的大小进行分类: 相似度最高的框架类型为正例框架,其余为负例框架。
此外,由于某些触发词的所有框架都不能表达事件类型,所得相似度均很低,如果仍将具有最高相似度的框架作为正例框架,用其例句作为“正例”扩充训练语料,会引入噪声,对系统造成不良影响。所以本文在实验过程中需要先设定参数γ,只有当s>γ时,才可将其归为正例框架,否则将其归为负例框架。
为了便于与方法一进行比较,同样采用例3的例句对方法二进行阐述。具体如例4。
例4Thecountryhadbannedawomanfromhavingmorethanonechild.
(译文: “以前,国家禁止生二胎”)
触发词: having(有)
事件类型: Life(生命)
事件子类型: Be-Born(出生)
搜索FN得到的所有框架: Possession(拥有)、Giving_birth(给予生命)、Ingestion(采食)、Have_associated(有关联)、Inclusion(入选)
根据触发词“having”搜索FN语料后可得到其对应的5个框架。根据方法二描述,利用式(1)与式(2)得到事件类型标签、事件子类型标签与所有框架标签的词向量表示后,分别计算5个框架标签与事件类型标签Life的相似度;同样,计算得到5个框架标签与事件子类型标签Be-Born的相似度;利用式(4)对上述两个相似度结果进行计算,得到每个框架与事件的最终相似度值,具体结果如表2所示。
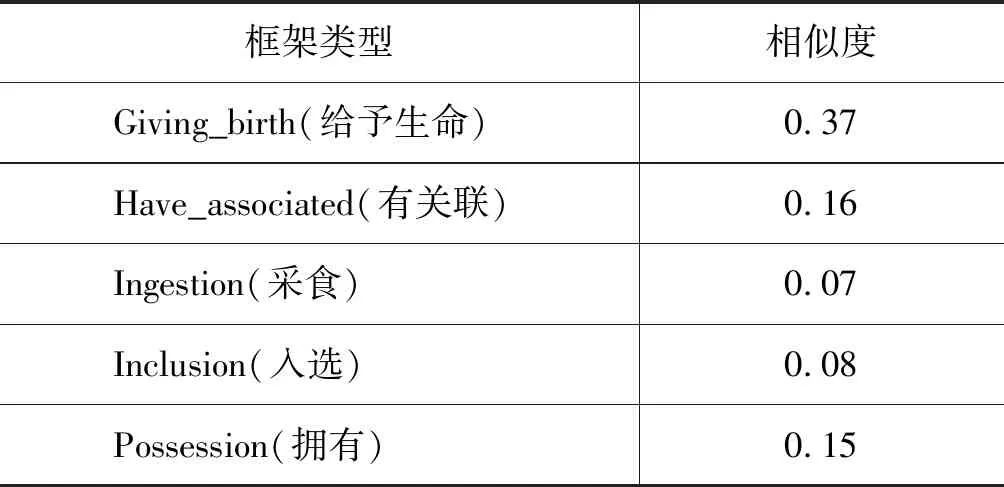
表2 触发词“having”的相似度结果
由表2知,相似度最高的框架为Giving_birth(给予生命),所以将此框架类型作为触发词的正例框架,其余框架均为负例框架。
此外,本文列出了利用该方法获得的ACE所有事件的框架及例句结果,如表3所示。
3.2 事件触发词识别与事件类型识别语料处理
利用上述方法可获得大量“正例”,这些例句根据事件与框架的高映射关系获得。很大程度上,例句中的词法单元可作为触发词,触发对应的事件类型。本文将“正例”作为训练集扩充语料,用新产生的语料进行实验,使模型得到充分训练,从而识别出更多触发词,达到缓解语料稀疏及样例分布不平衡问题的目的。
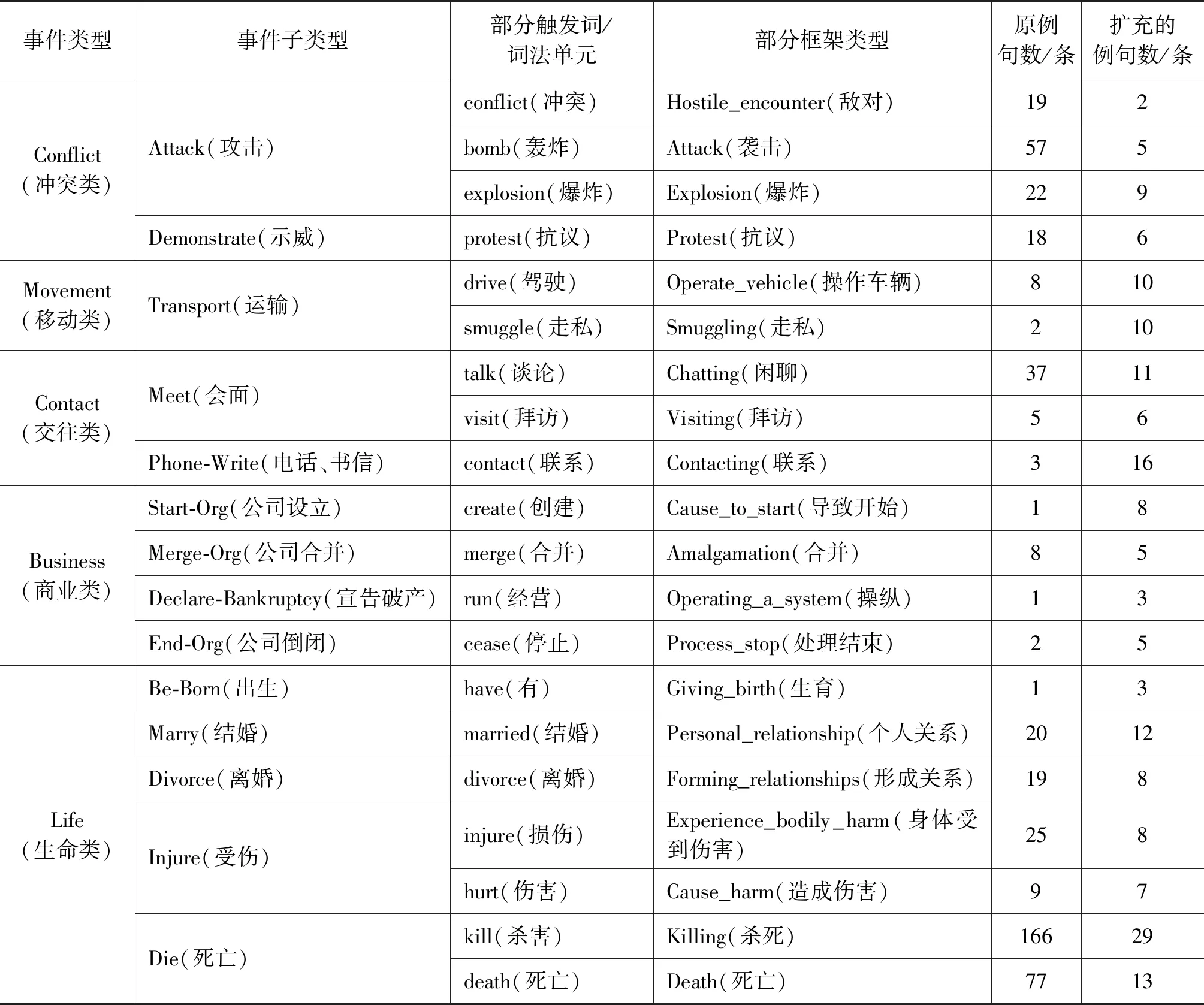
表3 利用SIF方法获得的ACE语料中所有事件类型及其部分可比框架
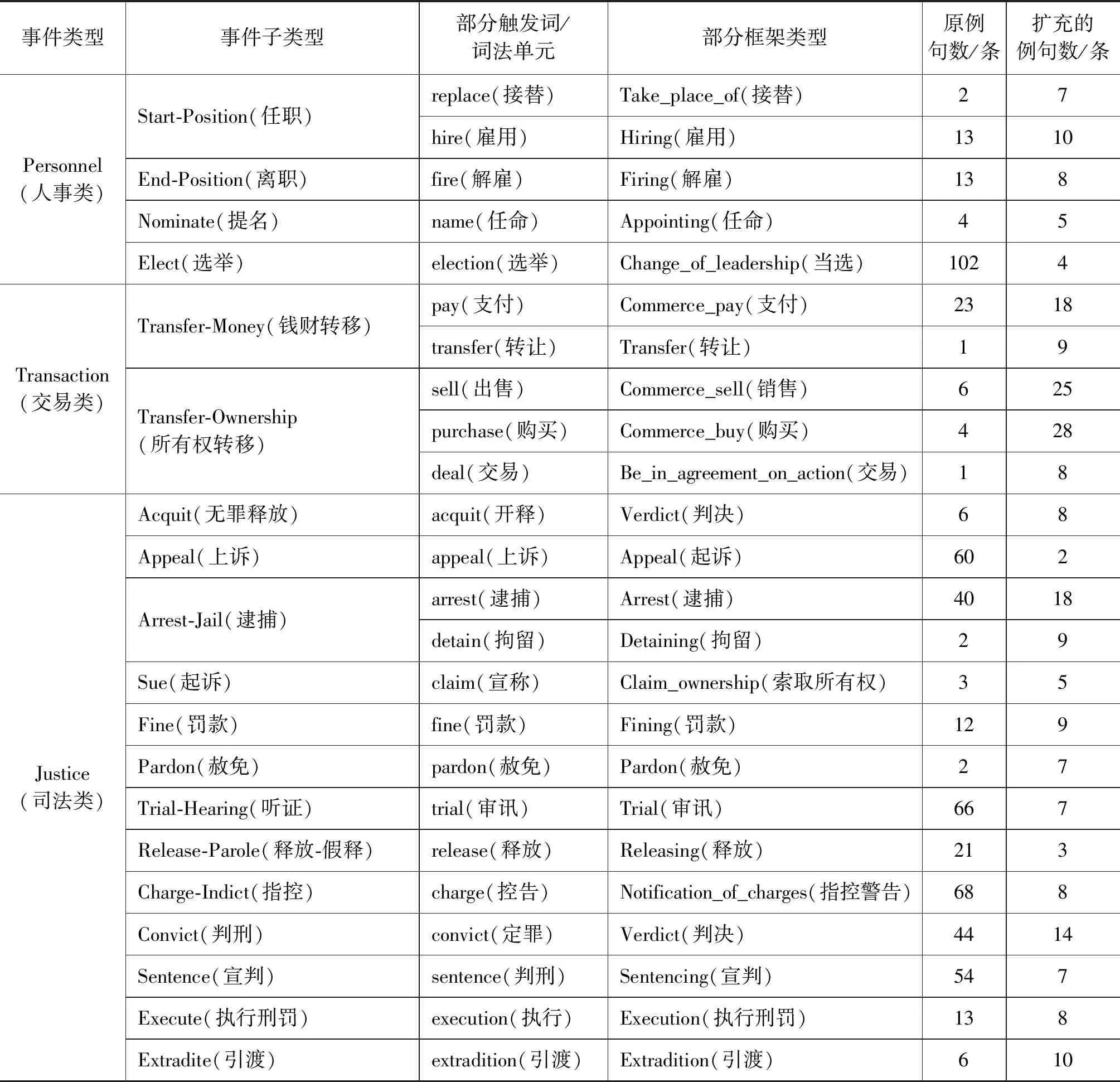
续表
注: ①由于篇幅限制,该表格对每个事件类型只列举了部分触发词及其对应的框架,且没有列举具体的例句。
② 本文所有可比的框架类型、词项和扩充语料所用的例句形成的数据集将对所有学术研究免费开放。
4 事件检测模型
为充分验证扩充语料对事件检测是否有效,本文分别采用基于特征抽取的传统机器学习模型和神经网络模型进行实验。
4.1 传统机器学习模型
基于特征抽取的传统机器学习模型采用Li[7]等的联合事件检测模型。所谓基于特征抽取指该模型主要通过抽取样例的各种特征实现触发词识别与事件类型识别任务。该模型采用的具体特征如表4所示。主要包括词法、句法和实体信息三个层面的特征。此外,该模型采用最大熵分类器[注]http://mallet.cs.umass.edu/,同时实现触发词识别和事件类型识别,即将句子中的每个词当作候选触发词,分类器对每个候选触发词进行判断,赋予该词具体的事件类型标签。若事件类型不为空,则认为该词为触发词,其标签即为触发的事件类型;否则为非触发词,不触发事件类型。所以该模型的事件类型为33种,不包括NA(空)类。
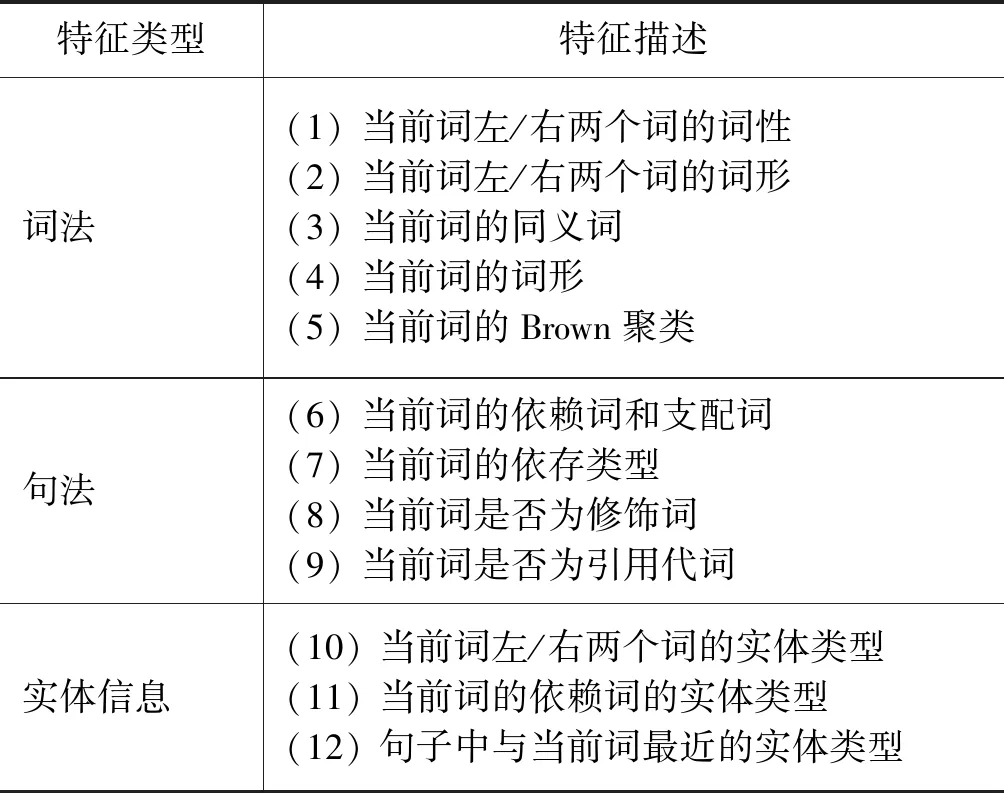
表4 触发词识别与事件类型识别特征表
4.2 神经网络模型
神经网络模型方面,Liu[25]等、Lin[26]等采用双向长短时记忆模型(Bidirectional Long Short Time Memory,Bi-LSTM)在自然语言处理任务中均取得了较好的效果,所以本文也采用该神经网络模型进行事件检测,并严格遵循Feng[11]等的Bi-LSTM架构。Bi-LSTM[27]是一种双向循环神经网络,在隐藏层同时有一个正向LSTM和一个反向LSTM,正向LSTM可以捕获当前词的上文信息,反向LSTM可以捕获当前词的下文信息,这样模型就可以捕获句子中每个词的完整的上下文信息。图2具体显示了该模型的主要架构。本文按照Chen[9]等的方法,将整个句子作为模型的输入。在输入前先将句子转化为词向量的表示形式,词向量是一个固定维度的向量,表示词的语义特征。输入Bi-LSTM模型后,通过前向传播与反向传播过程,会分别得到每个隐藏层的输出,将两个方向的隐藏层输出进行拼接作为最终的模型输出,记为{h1,h2,…,hn},其中,n表示句子长度。再通过全连接层后按照公式(5)对输出做归一化操作,即可得到每个词属于某个事件类型的概率。其中,P(yi│xi,θ)表示第i个词属于事件类型yi的概率,θ为模型的所有参数,t表示事件类型总个数,o表示经过全连接层后句子的表示。
(5)
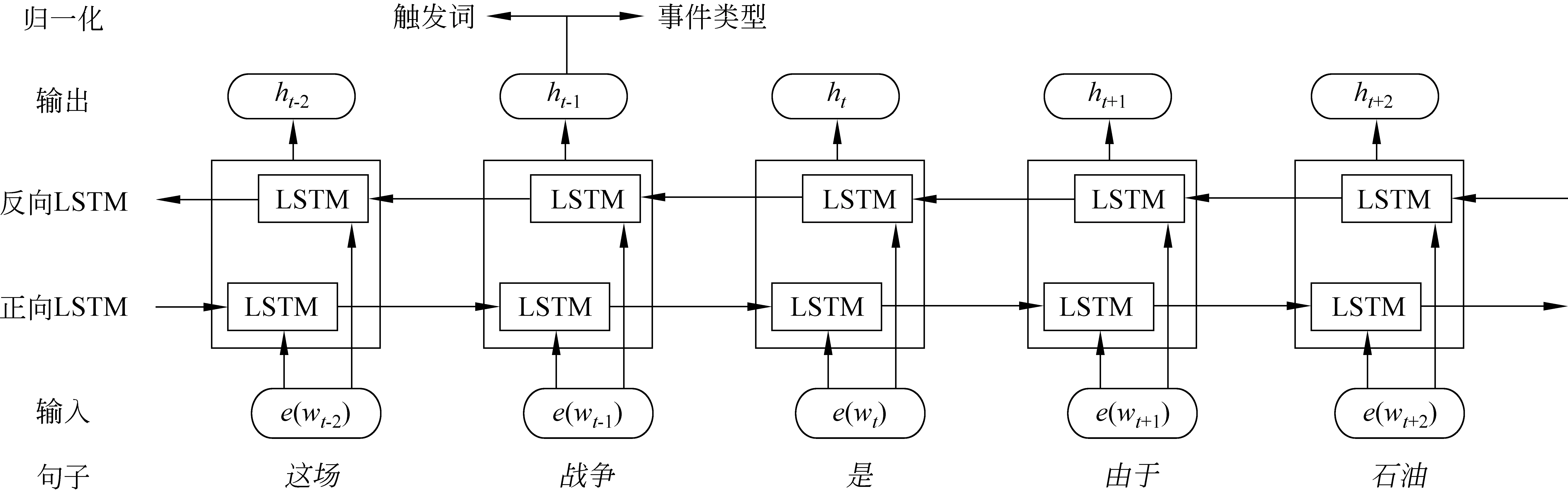
图2 Bi-LSTM模型架构图
该模型同样将句子中的每个词作为候选触发词,最终目标是对这些候选触发词进行分类,将其分为34个事件类别,包括33个ACE事件类型和一个NA(空)类。训练过程中,采用小批量随机梯度下降[28]方法最小化损失函数,并且添加一个dropout层[29](指的是在模型训练过程中随机让网络中某些隐藏层节点的权重不工作),作用是防止出现过拟合问题。此外,该模型采用多类交叉熵作为损失函数,计算公式如下:K为训练数据中所有的词;yi为词xi的真实事件类型;λ为正则化项,θ为所有参数。
(6)
5 实验分析
5.1 数据与评估方法
针对触发词识别和事件类型识别任务,本文选取ACE2005(Automatic Content Extraction 2005)的599篇英文事件文档作为实验的初始语料。为了便于对照,采用同Li[7]等相同的语料,选取其中的529篇文档为基本训练集,另外40篇新闻文档为测试集。扩充语料采用从FrameNet 1.7中获取的例句。
触发词识别任务主要考察句子中的某个词是否触发事件类型,系统性能取决于正确识别出的触发词个数。事件类型识别任务重点考察对识别出的触发词分类是否正确。本文采用准确率P(Precision)、召回率R(Recall)和F1值(F1-Measure)作为评价指标。
5.2 神经网络模型中的参数设置
本实验的参数设置如下: 词向量维度为300,且通过训练得到,词向量的训练过程严格遵循Feng[11]等在NYT[注]http://mallet.cs.umass.edu/语料上利用skip-gram预训练词向量的方法。隐藏层大小设为100,dropout率设置为0.2,最小批量即每次训练的句子数为10,学习率设置为0.3,L2范式取0,调和系数λ设为10-3。上述可调整的参数均在开发集上进行调整,以寻找得到最优参数。
5.3 框架识别5.3.1 实验系统设置
本文首先对3.1节提出的两种框架识别方法进行实验,从而判定采用哪种方法能获得更好的扩充语料。为此,提出以下对比实验:
• SEF: 使用SEMAFOR开源工具直接获取触发词的框架,按3.1节中介绍的第一种方法得到“正例”,并用其扩充ACE初始语料的训练集,测试集不变。采用第4.1节介绍的基于特征的事件检测模型进行触发词识别和事件类型识别。
• SIF: 使用3.1节介绍的第二种方法,即通过相似度计算得到框架类型与事件类型映射关系的强弱,从而区分出正、负例框架,利用得到的“正例”扩充训练集得到新的训练语料,与SEF采用相同的模型对事件检测任务进行实验。
• Frame_forward_combine[15](简写为FRC) (2015): 利用SEMAFOR识别框架类型,并将其作为特征,结合Joint模型中的局部特征与全局特征在最大熵模型上进行实验。
• SEMAFORE test[31](简写为SEFE(2015): 假设框架语义解析与事件抽取在结构上是一致的,故重新训练SEMAFOR框架语义识别开源工具来预测事件触发词。
5.3.2 实验结果与分析
上述实验结果如表5所示。由表可知,用SIF获取的扩充语料进行事件检测实验,能够得到更好的性能。相对于FRC与SEFE,事件类型识别的F1值分别提高1.0%和7.2%,其他指标也都有不同程度的提升。并且相对于SEF,触发词识别和事件类型识别的F1值分别提高0.8%和1.9%。可见,通过计算相似度能够提高框架类型与事件类型映射的精确度,从而使扩充的语料对事件检测更有效。
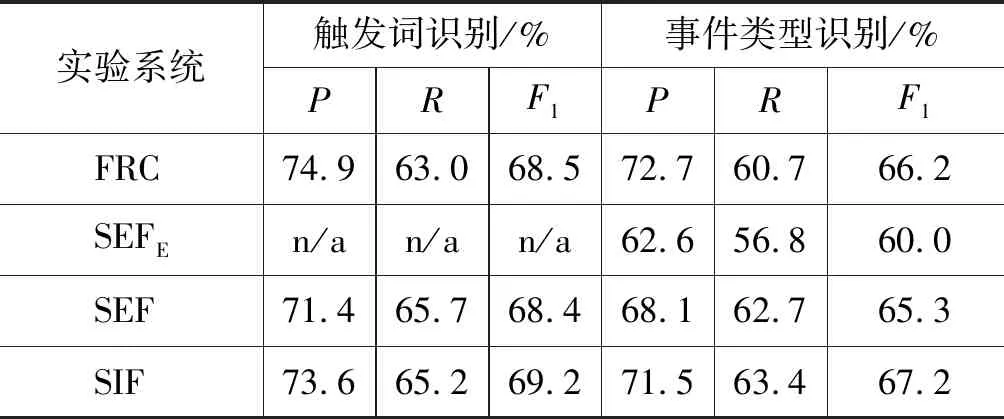
表5 通过识别框架进行事件检测的实验结果
表6列出采用SEF与SIF两种方法进行框架识别的部分结果。通过分析发现出现表5这一结果的主要原因是: SEF方法采用的是SEMAFOR框架识别工具,该工具本身对框架识别的准确率较低,同时也无法识别出所有触发词的框架,如表6中的“protest”。

表6 SEF与SIF两种方法的部分框架识别结果
(注: 单元格中的 — 表示框架为空)
但利用SIF不但可得到所有触发词的框架类型,同时由于一些触发词的框架可以直接表示事件类型,那么这些框架标签与事件类型标签就具有较高相似度。所以,相比于使用SEMAFOR工具,通过相似度计算能够更加精确地确定与触发词的事件类型具有强映射关系的框架类型。如表6中的触发词“hit”,其事件类型为Attack,框架类型也为Attack,如果用SIF方法,通过计算,二者会得到最高的相似度值,故很容易可以确定其框架类型为Attack。但用SEF方法,识别出的框架类型为Impact,映射关系较弱。
5.4 事件检测
上述实验证明采用SIF方法可获得更好的扩充样例,因此,以下实验均在用这些样例扩充训练集产生的新的训练样例上进行。
5.4.1 实验系统设置
为验证本文提出的利用FN中的例句扩充ACE训练集,是否能优化事件检测性能,本文设计以下几个实验系统进行比较。
(1) 基于特征的方法
• Joint(2013)[7]: 基于结构化感知机,并且将局部特征与全局特征进行结合。
• Cross-Entity(2011)[14]: 将命名实体作为额外特征的推理模型。
• PSL(2016)[32]: 捕捉事件与事件间相关性的概率软逻辑模型。
(2) 基于语料扩充的方法
• ANN-FN(2016)[16]: 以人工神经网络为模型,利用FrameNet中标注的语料提高事件检测性能。
• DM-CNN+(2017)[17]: 自动标注大规模数据,利用动态多池化卷积神经网络模型进行事件抽取。
(3) 基于神经网络的方法
• CNN(2015)[8]: 卷积神经网络模型。
• DM-CNN(2015)[9]: Chen等的动态多池化卷积神经网络模型。
• Bi-LSTM(2016)[11]: Feng等利用双向长短时记忆模型进行事件检测。
• Joint+FN: 与Joint采用相同的模型进行实验,训练集采用扩充“正例”后产生的新的训练语料。
• Bi-LSTM+FN: 采用与Bi-LSTM相同的模型进行实验,训练集为扩充“正例”后的训练语料。该系统用来与Bi-LSTM形成对比实验。
5.4.2 实验结果与分析
用“正例”扩充训练集主要是为了缓解事件检测任务遇到的语料稀疏与样例分布不平衡问题。上述几个系统的实验结果如表7所示。扩充“正例”后,相对于Joint模型,Joint+FN的触发词识别和事件类型识别任务的F1值分别提高1.8% 和1.3%。相对于Bi-LSTM模型,Bi-LSTM + FN的事件类型识别提高0.8%;此外,我们的方法相对于其他未进行语料处理的模型,事件类型识别的F1值均有所提高;而相对于其他扩充语料的模型,也有较大优势,相对于当前通过扩充语料进行事件抽取的模型的最高性能(ANN-FN†),我们的方法的F1值提升0.7%,召回率也有很大提高。由此可知: 事件类型与框架类型具有强映射关系,使得某些框架类型确实可以表达事件类型,这些框架下的例句在很大程度上能触发对应的事件类型。故将这些例句作为“正例”扩充训练集后,能有效起到丰富训练语料的作用。原本由于训练例句少而无法识别的某些触发词,在语料扩充后,这些触发词具有更多的训练样例,事件检测模型能得到充分训练,故能较好地对其进行识别。为此,该方法对触发词识别与事件类型识别的召回率有明显提升,极大地缓解了ACE语料数据稀疏的问题。正如例2中的触发词
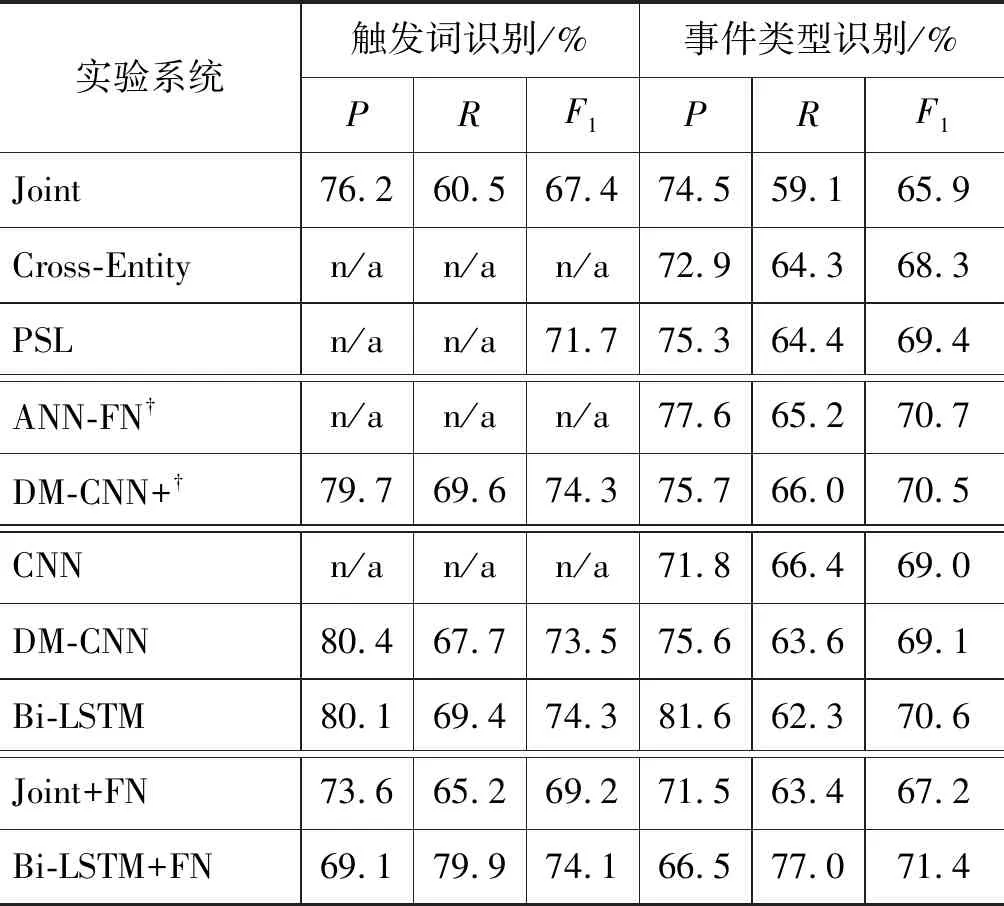
表7 触发词识别和事件类型识别的实验结果
(注: 单元格中的“n/a”表示该模型中未列出此任务的结果;†表示使用了额外的数据
“fractured”(骨折),扩充“正例”后,训练语料中包含11条以该词为触发词的例句,训练样本充足,模型可以很好地将该词判定为触发词。
相对于Bi-LSTM,Bi-LSTM+FN的触发词识别与事件类型识别的召回率分别提升10.5%和14.7%,效果显著。主要原因是神经网络模型对数据量较为敏感,数据量越大,模型训练越充分。扩充语料后,训练样例数目明显增多,神经网络模型可得到充分训练,能识别出更多Bi-LSTM无法识别的触发词,且事件类型分类也更准确,故在召回率上获得较好性能。
相对于传统机器学习模型Joint,Joint+FN的召回率也有较大提升,触发词识别与事件类型识别任务分别提升4.7%和4.3%。主要原因除训练数据集增大,模型训练更加充分外,还由于该模型主要是基于特征抽取,更多地依赖于例句中涉及的各种词法、句法和实体信息。故扩充语料后,具有相同词法、句法或实体信息的样例数目增多,在训练过程中,模型能较全面地捕获这些特征信息,提高对例句中触发词的辨识度,正确识别出更多触发词,有效提升召回率。
但从表7可以看出,Joint+FN与Bi-LSTM+FN相对于baseline,虽然在召回率上均有很大幅度提升,但准确率也都有所降低。相对于Joint,Joint+FN触发词识别与事件类型识别的准确率分别降低2.6%和3.0%;相对于Bi-LSTM,Bi-LSTM+FN的准确率分别降低11.0%与15.1%。我们分析主要原因是语料扩充中会引入部分错误样例,产生噪声。造成这一结果的原因主要有三方面: 其一,虽然我们改进了构建事件类型与框架类型映射关系的方法,但仍会有部分事件类型与框架类型无法正确映射,这会导致错误的传播,使部分错误样例扩充进ACE语料;其二,我们提前假设与事件类型对应的框架类型下的样例能触发该事件类型,其词法单元即触发词。但这一假设并不能保证所有的样例均具有上述性质。所以,扩充的例句不能完全保证词法单元就是触发词,即使词法单元是触发词,也不一定会触发对应的事件类型,且这些样例不一定是事件句。故将据映射关系获得的例句全部作为扩充语料,也会无法避免地引入噪声。其三,在扩充语料过程中,通过触发词获取对应的框架类型,从而将该框架下的例句作为扩充语料。所以,本文默认扩充的样例中,一个例句只有一个触发词。但通过对实验输出数据的认真分析,我们发现扩充的语料并不能保证每个例句只有一个触发词,有些例句会出现多个触发词,而本文在处理时并没有对这些词进行事件类型标记。所以,扩充的语料在类型标记上会出现错误,在模型训练过程中会造成较大影响。
由于上述三个原因造成错误样例的引入,不管对Joint+FN模型还是Bi-LSTM+FN模型,在训练过程中,这些错误样例均会对模型产生错误引导,最终造成模型对触发词识别的准确度降低,从而使系统整体的准确率降低。
6 总结
本文针对现有事件检测方法受限于数据稀疏与语料分布不平衡问题,采用框架语义知识及FrameNet语料对ACE语料训练集进行扩充。从而解决上述两个问题,实验结果显示事件触发词识别与事件类型识别任务的性能有明显提升。此外,本文提出一种通过计算框架类型标签与事件标签的相似度来识别框架的方法,通过与直接利用开源工具SEMAFOR获取框架的方法相比,取得了较好的性能。
但本文默认扩充的“正例”只有一个触发词,而模型在训练过程中把每个词都当作候选触发词,一旦句子中还有其他的触发词,但我们并没有对其进行标记,那么对模型的准确率会有较大影响。此外,扩充的样例并不一定是事件句,所以未来的工作重在对句子中的其他词进行处理,如果为触发词,则为其标记相应的事件类型以及对FrameNet中的样例进行预处理,去掉不是事件句的样例。
猜你喜欢
苏州科技大学学报(社会科学版)(2023年4期)2023-03-03 05:37:43
心理学探新(2022年1期)2022-06-07 09:15:40
广东教学报·教育综合(2020年15期)2020-03-23 05:58:29
少年博览·初中版(2018年12期)2018-01-18 09:17:58
海外华文教育(2016年1期)2017-01-20 08:21:58
小天使·一年级语数英综合(2016年4期)2016-11-19 10:22:17
小天使·一年级语数英综合(2016年6期)2016-05-14 12:21:05
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
小天使·一年级语数英综合(2015年10期)2015-10-14 06:30:06
民族古籍研究(2014年0期)2014-10-27 08:24:34
