
基于笔画中文字向量模型设计与研究
2019-06-03 10:52:44赵浩新俞敬松
中文信息学报 2019年5期
赵浩新,俞敬松,林 杰
(1. 北京大学 软件与微电子学院,北京 102600;2. 中国人民大学 信息学院,北京 100872)
0 引言
数据表示是机器学习任务的基础问题,在自然语言处理(natural language processing,NLP)领域中,任务转换为问题的第一步便是文本数字化。1954年,Harris提出分布式假说——“上下文相似的词,其语义也相似”。这为以后的词向量研究提供了理论基础。
在NLP中,单词最初采用one-hot编码方式表示。但是这种表示方式,存在语义鸿沟、维度灾难等问题。2006年,Bengio等在神经网络语言模型(neural network language model,NNLM)中使用分布式方式构造并训练了词向量[1]。Andriy Mnih等在此基础上引入层级思想[2]。随后Mikolov提出使用循环神经网络,构建语言模型,有效利用了长距离文本信息[3]。2013年Mikolov等总结C&W、ivLBL等模型特点,对模型进行了简化,提出了Word2Vec模型[4-6]。Yoav Goldberg等从矩阵分解的角度分析了Word2Vec模型[7],Shihao Ji等基于该理论提出了WordRank模型,在使用更少的数据基础上达到了不次于Word2Vec的效果[8]。随后斯坦福大学Jeffrey Pennington等引入单词共现信息,提出了GloVe模型[9]。然而现有的模型都是基于统计学理论,无法为未登录词、低频词等产生高质量的词向量。P Bojanowski等提出使用sub-word信息缓解这一问题[10]。Yoval Pinter等提出从字符粒度构建词向量,有效解决了未登录词等问题[11]。
中文词向量研究大都借鉴英文词向量研究技术。清华大学陈新雄等基于Word2Vec中CBOW模型提出了一种混合汉字后的中文词向量模型[12]。该模型在构造词向量的时候根据汉字出现位置引入字向量,丰富词向量构造信息,成功添加了汉字信息。哈工大孙亚明等提出在使用上下文信息预测当前字的同时预测该字的部首[13]。
蚂蚁金服团队从笔画角度出发,提出Stroke n-gram模型[14]。参考sub-word模型将中文笔画缩减为5种,将汉字词组拆分为对应笔画序列,但是这需要投入巨大成本构建新的汉字笔画映射关系。且部分词组笔画序列完全相同,例如,“大夫”“丈夫”。
现有的中文词向量研究很少从笔画粒度出发,根据笔画序列直接构造汉字字向量。在本文中,我们扩展CBOW模型,提出了一种新的基于笔画的中文字向量技术Stroke2Vec,旨在学习笔画序列生成汉字的规律。
测评工作对比了Stroke2Vec、Word2Vec、GloVe等模型产生字向量在命名实体识别、中文分词任务上的实际效果,以Word2Vec计算得到的字向量作为baseline。结果表明,在命名实体任务中,Stroke2Vec模型效果均优于Word2Vec、GloVe;中文分词任务中,模型效果与Word2Vec、GloVe效果基本相同。通过实验分析,模型可以在一定程度上从笔画序列中提取汉字部件信息,并生成字向量,为低频字、未登录字做补充,且模型在训练过程中需要的语料数据少于其他模型。
1 模型设计
汉字可以分为两种: 单体字、合体字。具有相同部件的合体字,大都在语义上具有一定的相关度。如“语、诉、话”,都具有相同的“言字旁”。
汉字的构造符合“笔画—部件—汉字”的规律。然而汉字是标准的“方块字”。学习笔画构造汉字的规律,面临着以下两种困难:
(1) 汉字由部件组成,部件由笔画组成。但是部件在组成汉字时,其在汉字中位置不同,会导致语义的变化。而笔画序列很难捕捉到部件的“二维”位置信息,如“杳、杲”的部件完全相同,但是位置不同,导致语义完全不同。
(2) 汉字的笔画序列不能唯一地确定一个汉字,即汉字笔画和汉字之间是一对多的关系。而且相同笔画序列的汉字语义完全不同,如“人、八、乂”笔画序列均为“撇、捺”,“日、曰”笔画序列为“竖、横折、横、横”,它们的笔画序列完全一致,但语义毫不相关。
我们仔细研究了汉字的构成规律,以及现有的字向量技术,将Stroke2Vec模型划分为上下文信息抽取组件、字向量生成组件、注意力组件,如图1所示。

图1 Stroke2Vec整体结构
Stroke2Vec扩展了Word2Vec中的CBOW模型。因此,Stroke2Vec模型是基于当前字的上下文信息,计算当前字的概率。
1.1 上下文信息抽取组件
本文中使用单独的网络结构替换Word2Vec模型中上下文信息矩阵,称作上下文信息抽取器。该模块借鉴了Cao等[15]等提出的模型,使用卷积神经网络,捕获更加丰富的上下文信息,在输出层新增全链接层,用于将卷积神经网络提取的上下文信息映射为任意维度的向量,解耦合上下文信息抽取器、字向量生成器输出向量的维度关系。
如图2所示,在输入层中为了计算更加丰富的上下文信息,我们引入了上下文汉字的拼音、部首、拆字等特征,而非简单的汉字id,其中拆字信息,是指一个汉字拆分为其他汉字的形式。如“林”拆分为“木 木”,“树”拆分为“权 寸”等。而汉字是“音形义”相结合的文字。
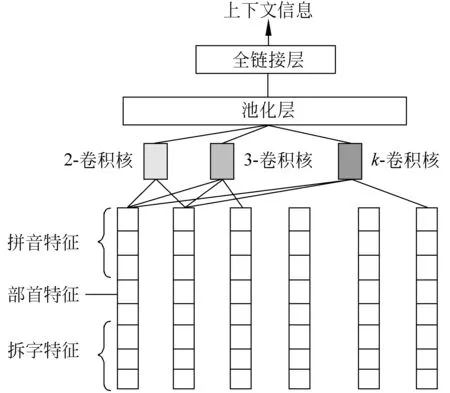
图2 上下文信息抽取器模型结构
通过引入汉字的拼音、部首等信息,可以使得上下文包含的信息更加的丰富,有利于提取具有辨识度的特征。
1.2 字向量生成组件
中文汉字主要分为两类,单体字与合体字。据统计,90%以上的汉字为合体字。单体字是指那些无法进行拆分的汉字,即由部件直接组成的汉字,这些单体字构成了合体字的原子部件。合体字便是由这些原子部件按照其在二维空间中的不同位置组合而成。
假设笔画构字符合某种规律,我们做出以下定义:
S={横、竖、撇、捺、点、…},si∈RN,N表示笔画向量维度大小;
SC={笔画所有排列组合},SCi∈RK×N,K表示汉字具有笔画序列最大长度;
W={一、二、三、…},wi∈RM,中文汉字集合,M表示汉字字向量维度;

具有相同部件的合体字在语义上具有一定的相关度:
“甜”——“舌”+“甘”,用舌头品尝甘甜的东西后的感觉。
“话”——“言”+“舌”,用嘴说出来的文字。
“凝”——“两点水”+“疑”,气体变为液体或液体变为固体,(疑,止也)。
对于大多数合体字,其笔画序列完全不同,但又局部相似,即构成合体字的笔画是局部有序的。因此我们采用卷积神经网络提取笔画序列中的部件信息。而且CNN具有平移不变性[16],不会因为部件在汉字中位置不同而无法捕捉。文献[17]已经证明CNN在翻译任务中有不俗的表现,可以用于处理序列数据。
字向量生成组件将注意力组件计算笔画权重得到的新的笔画序列作为输入,然后经过CNN卷积神经网络计算得到字向量。
本文中提出了三种字向量生成器,如图3所示。
CNN-1表示,我们使用不同宽度的卷积核提取不同笔画长度的部件,通过最大池化过滤最有效汉字部件,接着直接使用这些部件序列对汉字进行表示,然后通过全链接层映射成任意维度的字向量。
CNN-2、CNN-3则是在卷积层提取的部件特征的基础上,使用卷积神经网络学习部件组合形成汉字的规律。区别在于,CNN-2是双卷积层连接池化层。CNN-3是标准的双卷积神经网络。
1.3 注意力组件
正如前文所述,不同汉字可能具有相同的笔画序列。我们通过汉字拼音等外部信息,计算了笔画对于汉字的贡献度,如式(1)所示。
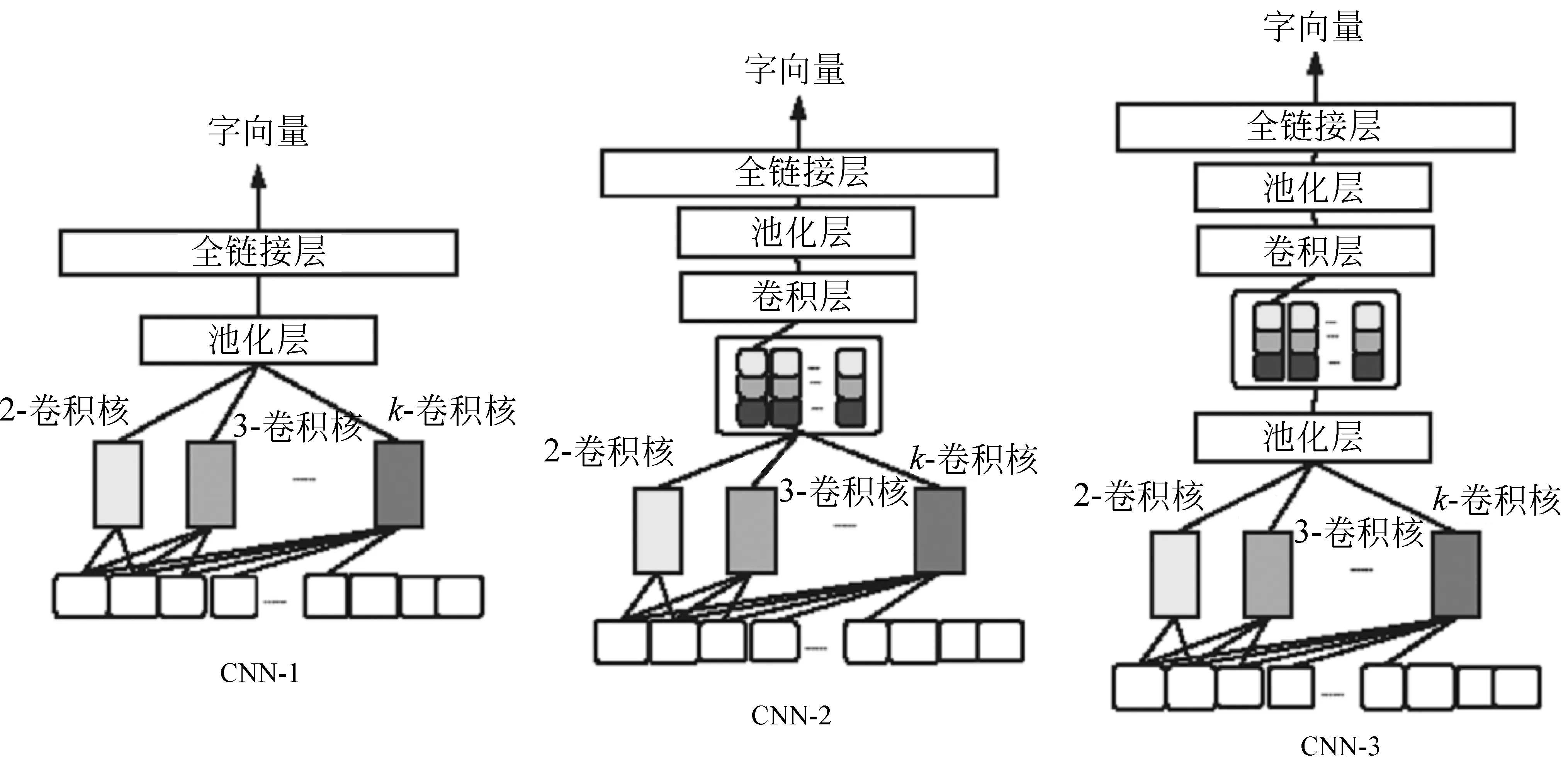
图3 字向量生成器网络结构

本文采用乘法注意力机制作为计算笔画贡献度的方法,如式(2)所示。
乘法注意力组件如图4所示。
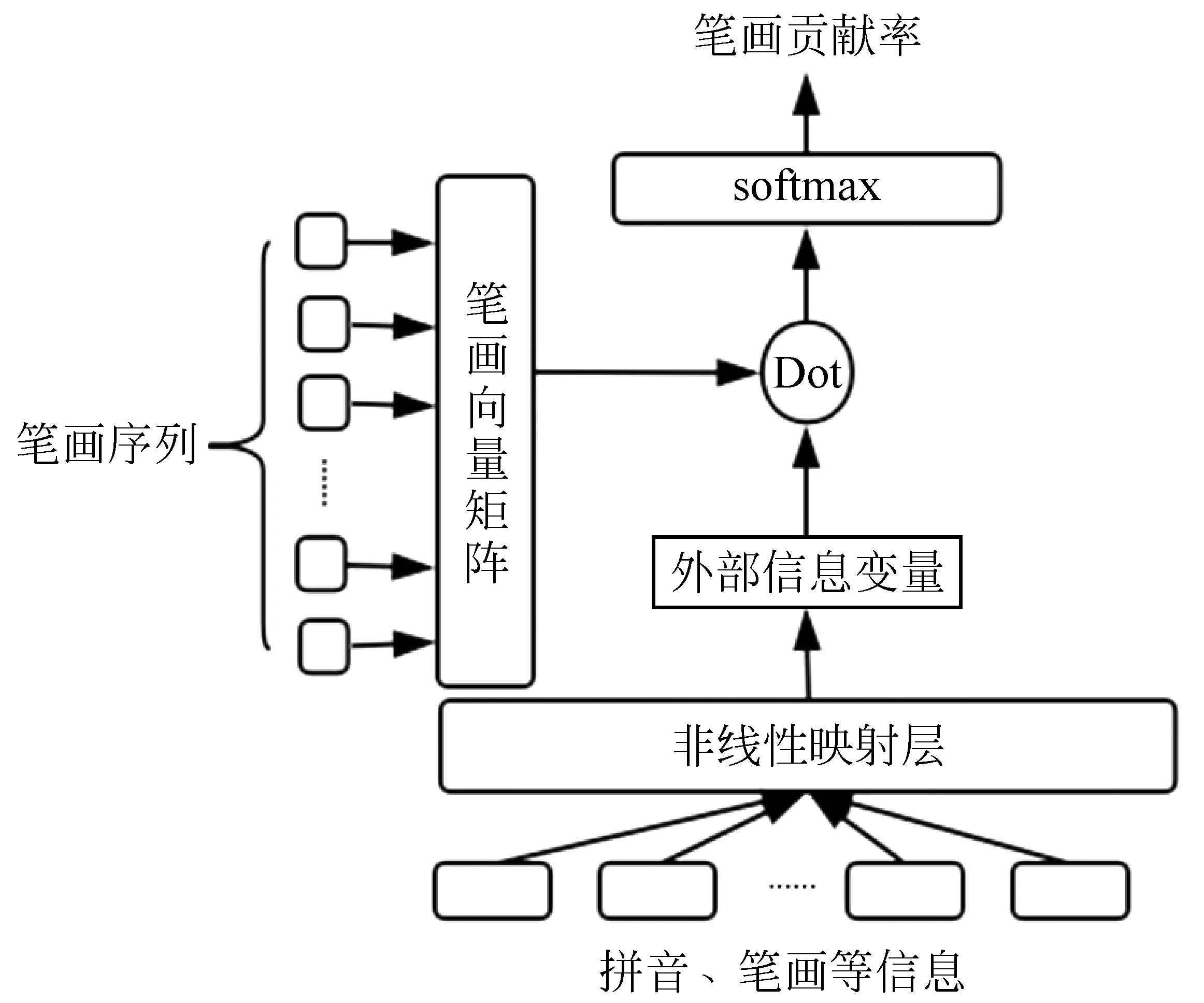
图4 乘法注意力组件
1.4 模型目标函数
Stroke2Vec模型通过上下文信息抽取器计算当前汉字的上下文信息,使用注意力组件和字向量构造器,计算当前汉字的字向量,然后这两个向量进行相似度计算,使用softmax归一化后,表示当前汉字的概率,如式(3)所示。
(3)
采用负采样算法,则目标函数如式(4)所示。
其中,NEG(w)表示当前字w的负采样集合。
2 实验分析
本文中Word2Vec[注]https://github.com/svn2github/word2vec工具、GloVe[注]http://nlp.stanford.edu/projects/glove/词向量开源工具均来自官方开源代码。
为保证一致性,模型窗口大小为3,最低词频为3,负采样个数为5,词向量维度为100。然后我们使用相同的维基百科语料训练了Word2Vec的CBOW模型、GloVe模型。
2.1 实验语料介绍
本文数据主要分为两类,词向量训练语料、测评任务语料。
词向量训练语料主要分为5种: 中文维基百科数据[注]https://dumps.wikimedia.org/zhwiki/、汉字笔画数据[注]https://github.com/DongSky/zhHanSequence、汉字拼音数据[注]https://github.com/cleverdeng/pinyin.py、汉字偏旁部首数据[注]https://github.com/yyd27/Chinese_radicals、汉字拆字数据[注]https://github.com/kfcd/chaizi。其中中文维基百科语料选自维基百科官方2017年12月23日开源数据。其余4种语料来源于Github官方开源数据。
测评任务分为命名实体识别、中文分词。其中命名实体识别语料来源于微软亚洲研究院开源的中文命名实体语料,共43 364行,实体分为人名、地名、机构名三类。其中人名共11 466个、地点名称共17 068个、机构名称12 695个,按照9∶1比例,将数据分为训练集、评测集。
分词任务数据为NLPCC-2016年中文分词语料,训练文本20 135行,测试数据2 052行。
2.2 测评模型
命名实体识别、中文分词任务可以看作序列标注问题。本文采用Huang等提出的Bi-LSTM+CRF模型作为评测模型[18],对比不同字向量的效果。评测模型的代码来自Github中fork最多的开源项目。评测指标严格按照分词边界、命名实体边界计算准确率、召回率、F1值。
2.3 命名实体识别任务
在命名实体任务中共有四大种类的标签: PER、LOC、ORG、O,分别对应数据中的nr、nt、ns、o标签,表示任务、地点、组织机构、非实体。又根据实体词的个数、汉字在实体中的位置进一步细化了四个类别的标签: S、B、I、E,当实体词为单独一个字时,在标签名称后添加后缀“-S”,例如“我 今天 在 京(LOC-S)”,至于“B、I、E”则按照汉字在实体中的具体位置添加后缀。总计有16种标签。
本节横向对比了不同模型产生的字向量在命名实体识别任务中的效果,如表1所示主要对比了Word2Vec中CBOW模型(后面使用Word2Vec特指CBOW模型)、GloVe模型、Stroke2Vec模型,混合Word2Vec词向量与Stroke2Vec字向量结果,以及混合GloVe词向量与Stroke2Vec字向量结果5种实验。
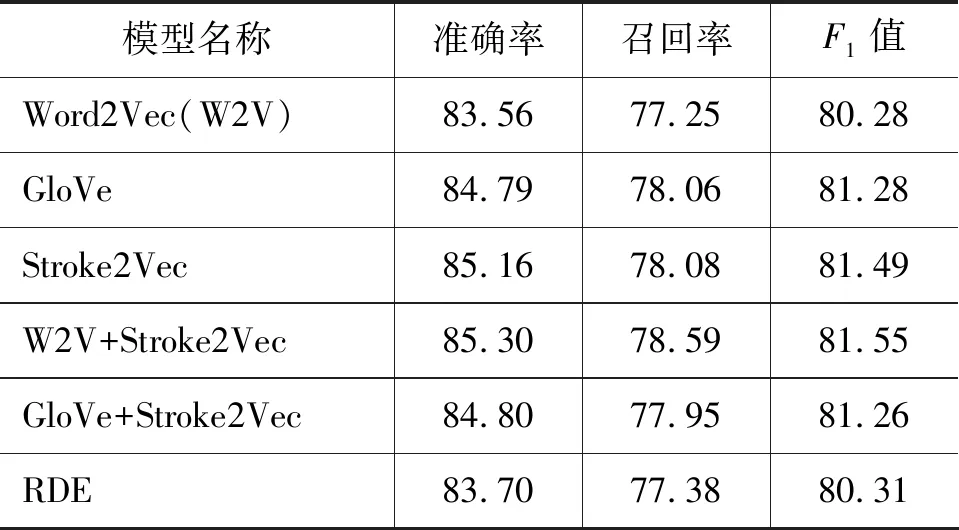
表1 不同模型NER效果展示(%)
然后纵向对比了基于笔画字向量模型中不同结构字向量构成器组件产生的字向量,以及上下文信息抽取组件中不引入拼音数据情况下生成的字向量在NER任务中的效果,如表2所示。
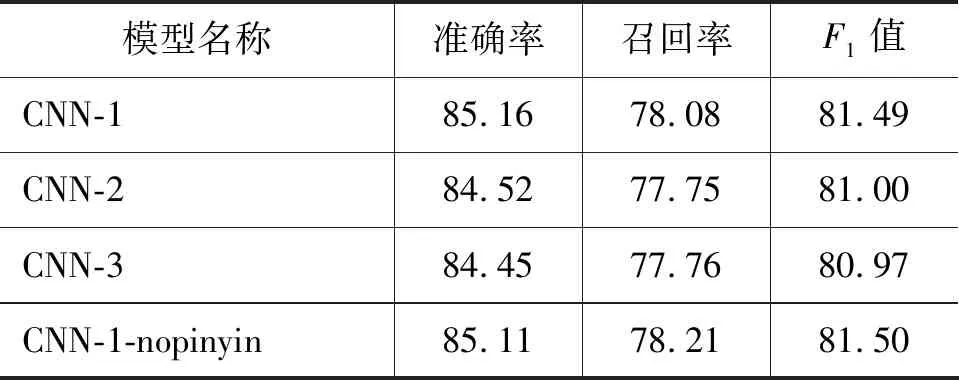
表2 不同字向量生成器NER效果展示(%)
2.4 中文分词任务
在中文分词任务中,共有4种标签{B、E、M、S},表示汉字在词组中的位置。以切词最终结果为标准,本节横向对比了不同模型产生的字向量在切词任务中的效果、纵向对比了不同字向量生成器的切词效果,如表3、表4所示。
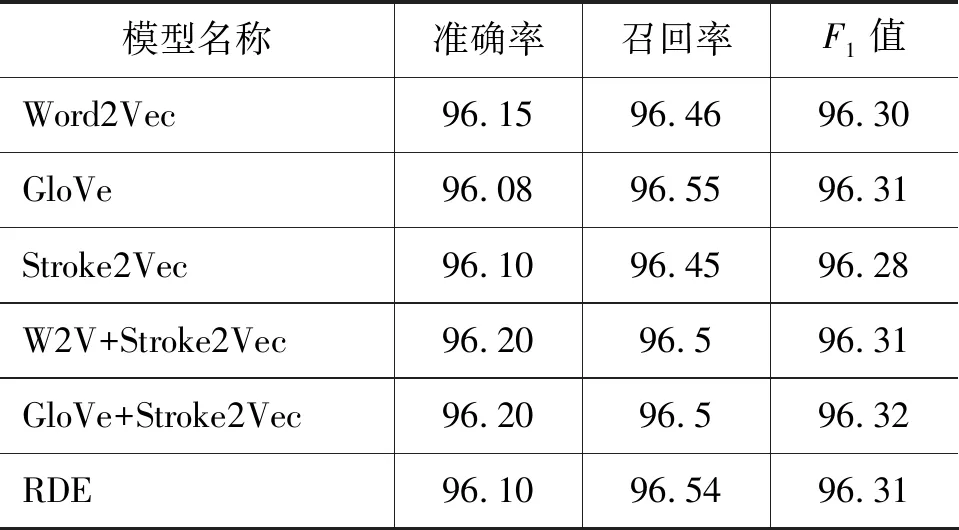
表3 不同模型CWS效果展示(%)

表4 不同字向量生成器分词结果(%)
2.5 实验分析
2.5.1 Stroke2Vec模型分析
汉字是部件在二维空间中的组合构成,部件是笔画在二维空间中的组合构成。本文针对此提出了三种字向量生成器的变种,实验结果(表2、表4)显示,使用单层CNN结构的字向量生成器效果最好。即从笔画序列中提取汉字部件信息,然后将部件信息组合映射为汉字向量,较符合笔画组合形成汉字的规律。
针对此种情况,随机抽取了50个汉字的字向量,采用余弦相似度算法计算最相似的汉字,最终得到50组相似汉字,其中有32个汉字字形较相似,18个汉字无法直观判断,如表5所示。
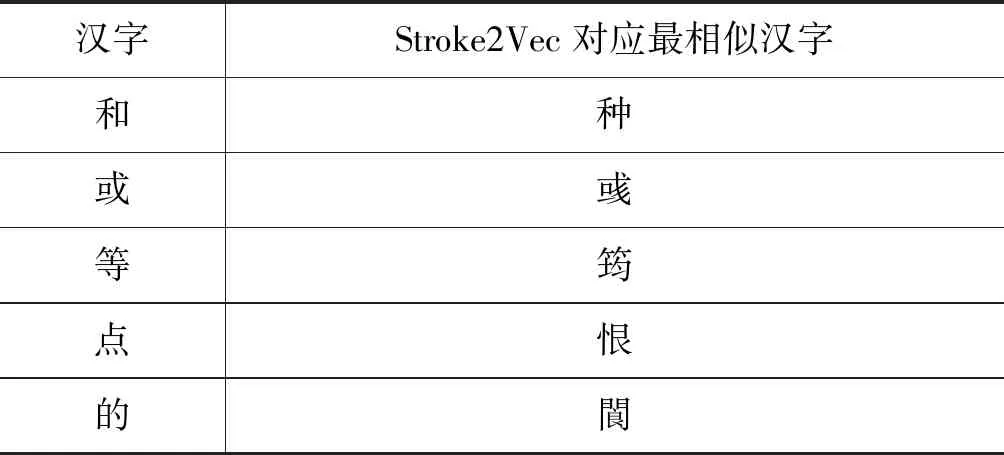
表5 汉字相似度展示
Stroke2Vec可以有效地捕捉到存在于笔画序列中的局部汉字部件信息,如“和”最相似的汉字为“种”。但是由于卷积神经网络具有平移不变性的特征,也会对生成的字向量产生负影响,如“的”“閬”都具有部件“白”。
如图5、图6 所示,为注意力组件计算得到“日”、“曰”笔画贡献度,由此生成的新的笔画序列虽然可以区分这两个字,但是与实际情况有较大差距。每一个真实笔画对于汉字的贡献度都不相同,但它们之间的差异并不是很大,即这些笔画贡献度之间应该相对平滑。

图5 “日”字笔画贡献度

图6 “曰”字笔画贡献度
2.5.2 横向分析
在NER任务中,Stroke2Vec模型的表现优于GloVe和Word2Vec,在CWS任务中,三者基本持平,Stroke2Vec模型表现略次。使用Stroke2Vec生成字向量替换Word2Vec中UNK字后,在NER任务中有较好的表现,与CWS任务持平。使用Stroke2Vec替换GloVe中UNK字后,在NER、CWS任务中效果基本不变。因此本文提出模型Stroke2Vec生成的字向量一定程度上缓解了有未登录字、低频字产生的负面影响。
在NER任务中,命名实体一般以名词居多。一些汉字含有的名词性部件可以增强这种信息,使其免于误判。如“组织”,本义偏动词性,但是在实际文本中,会频繁出现“某某组织”这种机构词语,导致模型误判“组织”为机构实体。随机抽取了Word2Vec、GloVe模型共同出现错误但不在Stroke2Vec中的样例如表6所示。
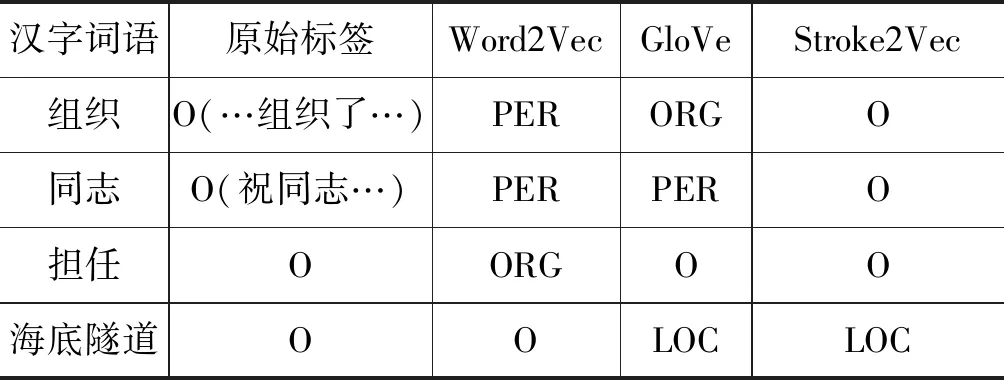
表6 Word2Vec/GloVe/Stroke2Vec在NER中错误示例
3 未来展望
Stroke2Vec模型可以从笔画序列中提取部件信息生成字向量,这对于命名实体识别任务产生了一定的效果。但是,现有的Stroke2Vec模型依然存在以下不足:
(1) 注意力组件生成笔画贡献度与实际相比仍有较大差异。汉字笔画贡献度应该与部件一一对应,是局部平滑的,而现有模型无法做到。
(2) 字向量生成组件可以从笔画序列中提取部件信息,但是并不能判断笔画序列中哪一部分笔画应该组成什么样的部件。
因此在未来的研究中,可以基于这两点出发,尝试更加有效的注意力机制、网络结构,对笔画序列进行自动切分,提升模型的效果。
猜你喜欢
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16 08:28:52
学生天地(2020年14期)2020-08-25 09:21:06
小天使·二年级语数英综合(2018年10期)2018-10-15 09:20:10
制造技术与机床(2018年9期)2018-09-19 06:48:16
海外华文教育(2017年6期)2017-08-07 03:11:00
创新作文(小学版)(2017年5期)2017-05-13 06:16:30
海外华文教育(2016年1期)2017-01-20 08:21:58
水电站机电技术(2016年1期)2016-02-28 14:21:50
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
