
基于大数据分析的旅游微博用户偏爱研究
2019-05-22 06:52:52蒋文明
滁州学院学报 2019年1期
曹 炜,蒋文明
旅游微博用户偏爱链路算法旨在通过后台用户浏览日志挖掘其浏览网站的习惯规律,并基于研究结果优化网络链路设计或更加精准地为用户提供个性化推送等商业服务[1]。随着微博这一新兴媒介的快速发展,微博平台正向着功能多样化演进,旅游微博是其中一种典型的面向休闲旅游的集社交、美图分享、景点推送和旅游策略制定于一体的网络平台[2]。当前,旅游微博用户偏爱链路研究主要集中在网络拓扑架构既有链路的点击量计算上[3]。
这些算法基本能够实现对偏爱链路的计算,但也存在明显的不足之处:(1)这几种算法建立在“点击量高等同于客户偏爱度高”这一假设上,从而忽略了网站链路设置以及杂散钓鱼链接等对用户访问习惯的影响;(2)旅游微博的生成数据呈指数形式增长,传统算法对海量信息处理能力不足的现象日益凸显[4,5]。
考虑到大数据分析技术在巨量信息处理上的突出优势,将探索建立更加合理的偏爱指数评价方法,并基于大数据分析和Map-Reduce对现有网络拓扑算法进行改进,以实现对旅游微博平台产生的巨量数据进行模块化并行计算。为探究新算法的可行性,将利用某旅游微博平台的真实数据设计验证实验。
一、 真实偏爱指数研究
一个网站某链路的点击量高低并不能客观评价用户的喜好程度,这一观点得到了越来越多的认同[6]。邢东山等人基于“相对点击量”提出了网站偏爱度计算方法,初步建立了互联网条件下网站点击量强度与用户真实需求强度的数学模型。然而这种方法并未将互联网的拓扑架构纳入考虑,若其计算出的一个偏爱链路与互联网拓扑架构中的一个链路重合,这个链路上的高点击量显然来自于用户的顺序浏览,并不能说明用户真实需求强度大[7]。为解决这个问题,在考虑了互联网拓扑架构特点的基础上,提出了“真实偏爱指数”这一概念。
(一) 互联网拓扑架构
旅游微博用户可以通过超链接点击进入不同页面,通过所访问页面提供的超链接,用户可以进一步访问更多巨量网络资源[8]。互联网的这种拓扑架构见图1。

图1 典型互联网拓扑架构
图1是旅游微博常用的典型性三层次网络架构,图1中的圆圈代表网络节点,对应真实网络中的网页,内置字母A-G用于标识不同的网络节点;图1中带箭头的有向指针代表网页间的链接关系。网络拓扑架构最初通常是由网站创建人设置的,网站创建人依据某个指标,对不同网页的关联性进行评判,关联度较大的网页在拓扑架构中距离较近,反之则距离较远。从微博用户的角度来看,网站创建者按设想搭建的网络拓扑架构在真实线上运行中往往不能完全契合用户兴趣,而在网络拓扑架构中拥有高点击量的访问链路,显然更能反映用户偏爱。因此,网站创建人可以依据真实的用户偏爱链路,通过添加或者删减超链接的方式,对原有网络拓扑架构进行重设。如在图1中,若通过计算发现F→C→A→B→E是用户点击量较高的偏爱链路,网站创建人可以设置F→E的访问链路,从而提高微博用户搜索效率并提升平台好评度。
(二) 网页链路矩阵
旅游微博用户的网上浏览历史,会被网页日志所记载,网页日志能够详细记载用户浏览时间、浏览网页地址以及使用网页的超链接情况。研究旅游微博用户的网页偏爱链路,需要基于巨量日志数据进行计算。为了化简计算过程,通常忽略巨量浏览日志数据中的非主要单元,而主要关注用户的浏览链路。表1为浏览日志数据中被重点关注的数据单元。

表1 浏览日志数据中的主要数据单元
在表1中,“时刻”显示了用户访问页面的时间,调取“时刻”数据,可以研究用户在旅游微博上的活跃时间段规律,为个性化推送服务提供依据;“当前页面地址”显示了用户所逗留网址,用户在某个页面上逗留时间的长短,可以间接衡量用户对网页内容的偏爱指数。“链接页面地址”表示用户从当前逗留网页通过超链接点击进入的网页,用户上网过程中产生的“当前页面→链接页面”链路,是研究用户偏爱链路的重要依据。
目前微博用户群数量庞大,一个热门旅游微博平台,用户在24小时内浏览页面所产生的日志数据总量可达到1000GB甚至更高。因而将基于大数据分析理论对日志数据进行Map-Reduce编程运算,以实现从巨量数据中挖掘旅游微博用户偏爱链路。
首先从用户巨量日志数据中提取T、N、L三种主要数据单元。设Q=[N,L]为当前页面地址和链接页面地址组成的一个数据元素,则Q的集合包含了用户浏览页面所产生的所有链路。通过大数据分析中的矩阵简化算法对Q的集合进行计算,可明显减少后期数据计算量,设表2为化简后Q的集合。
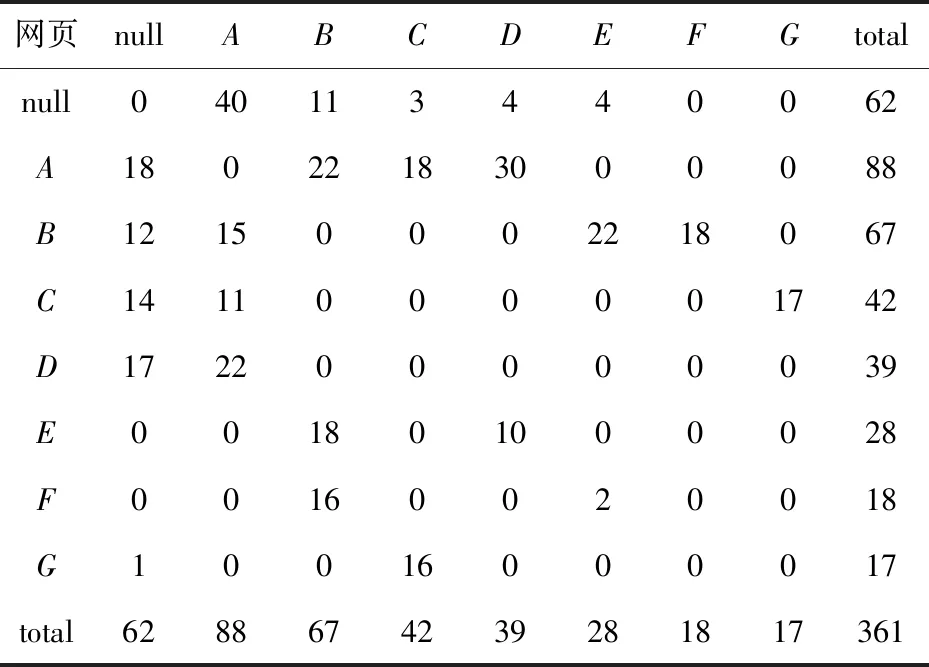
表2 化简后Q的集合

表3 部分数据的三元素矩阵形式
在表2中,null表示退出网页中断浏览,表中数据为相应的N和L之间的链路点击量。为进一步减少巨量数据的计算量,将简化后Q的集合进一步简化为三元素矩阵,表3为表2中部分数据的三元素矩阵形式。
(三)真实偏爱指数计算
真实偏爱度指数计算包括两个过程:网页间超链接真实重要度计算和链路真实偏爱指数计算。
1.网页间超链接真实重要度计算。网络拓扑架构下,超链接的点击量并不能客观反映其重要度,在图1中,假设客户对网页E的内容十分感兴趣,则在网络拓扑架构下,必须经由超链接A→B→E实现对网页的E访问,这将导致超链接A→B的点击量激增,但用户却并非对网页B感兴趣。为此,在已有网络拓扑架构基础上提出了链路加权法,以衡量页面间超链接的真实重要度。设i和j分别表示当前页面序号和链接页面序号,链路加权法的操作方法是赋予网页的每个超链接一个加权系数Kij,Kij∈(0,1)。在网络拓扑架构中,距离主链路越远的超链接,其加权系数越大,距离主链路越近的超链接,其加权系数越小。
2.链路真实偏爱指数计算。设页面i和j间的超链接点击量为Sij,则
(1)
式1中,定义E为某条链路的真实偏爱指数值。
二、基于大数据分析的用户偏爱链路算法分析
热门旅游微博平台的网络日志数据规模庞大,经过化简后的三元素矩阵对常规算法依旧是一个挑战,因此提出基于大数据分析的Map-Reduce程序处理法,对三元素矩阵的巨量数据进行计算。
(一) Map-Reduce巨量数据并行运算模型
Map-Reduce是旨在处理巨量数据(数据量在1TB以上时优势凸显)提出的运算模型,Map-Reduce运算模型的核心理念是将需处理的巨量数据划分成大量的子数据,并将子数据在分布的计算单元之间合理调配,以实现数据的快速处理。Map-Reduce运算模型将处理数据的过程分成了以下几个环节:巨量数据导入、巨量数据合理划分、子数据在分布式计算单元上调配计算、生成计算结果。
Map-Reduce巨量数据并行运算模型已相当完善,将该模型应用于旅游微博网络日志巨量数据处理,是实现用户真实偏爱指数计算的关键一步,具体步骤为:旅游微博用户网络日志原始数据→冗余数据删减→T、N、L数据提取→三元素矩阵→三元素矩阵数据拆分→Map-Reduce巨量数据分布计算→生成最终结果。
(二)基于大数据分析的用户偏爱链路算法
基于大数据分析的用户偏爱链路算法的部分程序代码如下:
1. in:向MR导入旅游微博网络日志的三元素矩阵数据包W,设定链路真实重要度门限E0
2.out:用户真实偏爱链路
3.for each w1 in W…w1是三元素矩阵的一个子数据
4.i=w1_N…N表示当前网页标号
5.j=w1_L…L表示链接页面标号
6. if Kij*Sij>=E0…链路真实重要度超过门限
7.Keep (i,j)…记录链路子集
8.遴选(i,j)集合中连续链路集合为最终生成结果
三、两种算法的对比实验及结果
为探索基于大数据分析的用户偏爱链路算法的可行性,设计实验对该算法和传统算法做了对比分析,从巨量数据处理速度和用户偏爱链路计算结果准确度两个方面对该算法进行了评价。
(一)巨量数据下旅游微博用户偏爱链路计算速度比较
对比实验中,预处理数据(网络浏览日志)来自某旅游微博平台,数据大小为25G左右,基于大数据分析的用户偏爱链路算法使用5台安装Map-Reduce编程系统的计算机,传统算法使用1台安装MPI数据处理系统的计算器,5台计算机均为联想Y46型,主要硬件配置相同。
图2为两种计算方法的数据处理速度对比曲线。由图1可知:
1.当需要处理的数据较少时,两种算法的数据处理速度相差不大,由于传统算法只需要一台计算机,因而优势更为明显。
2.当需要处理的数据逐渐增多时,基于大数据分析的偏爱链路计算方法优势将越发突出,且随着需要处理的数据逐渐增多,相同时间内新算法的数据处理量与传统算法的数据量比值越来越大,这表明当需要处理的数据超过一定规模,5台计算机的分布式大数据处理计算,其效率超过了5台按传统算法运算的计算机的数据处理效率总和。且分布式计算机数量越多,优势越明显。
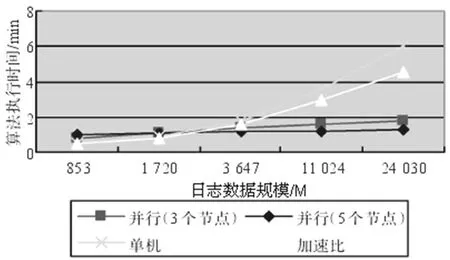
图2 两种算法的数据处理速度比较
因此,在网络日志巨量数据需及时处理的背景下,基于大数据分析的旅游微博用户偏爱链路计算方法更具优势。
(二) 两种算法下用户偏爱链路准确度比较
为比较两种计算方法所计算出的用户偏爱链路的准确度高低,设计了对比实验,在实验中,分别为两种算法导入了相同的原始网络日志数据,并通过两种算法得到了其各自运算下的偏爱指数靠前的X条链路。将两种算法各自计算所得的X条链路分别和网站根据运营经验提供的访问量靠前的X条链路进行比较,实验结果见图3。
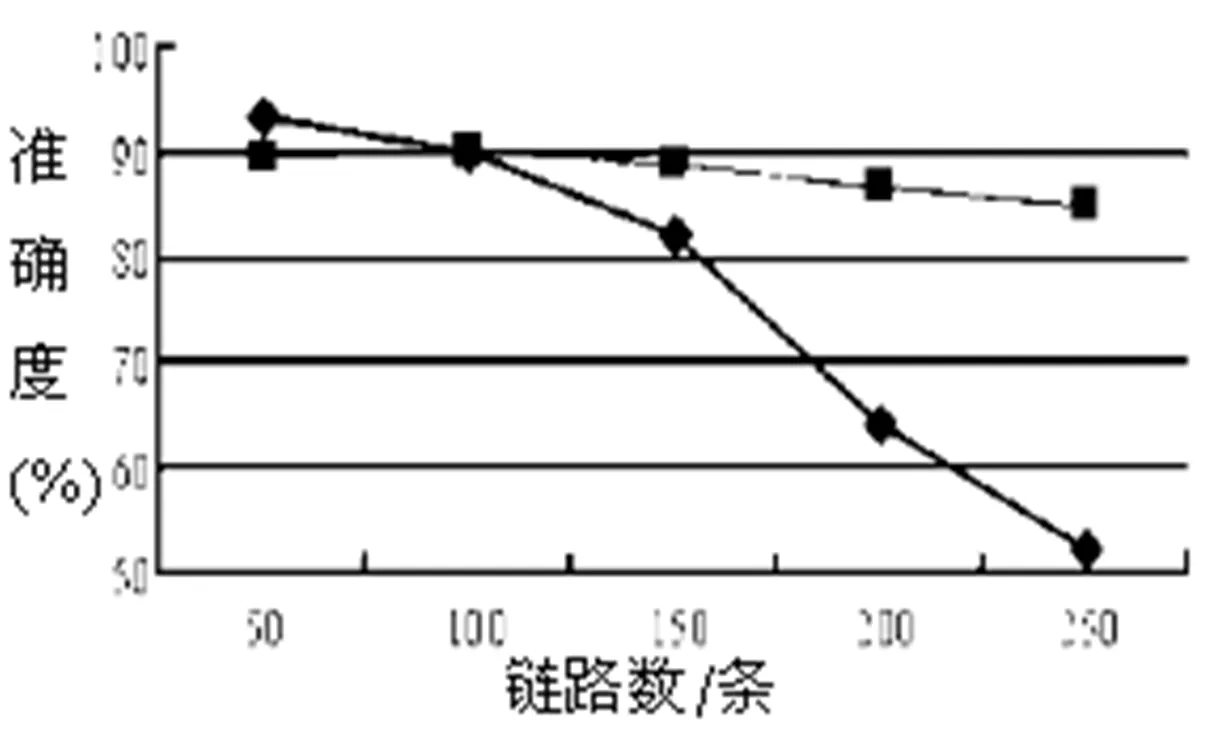
图3 两种算法的链路准确度比较
对比实验的结果显示:当X较小时,传统算法得到的偏爱链路与实际情况更为贴合,这可能是因为新算法加权系数的引入在数据规模较小时,会对数据计算产生较为明显的影响;当X增大时,传统算法的计算结果准确度将开始降低,而新算法的运算准确度将趋于稳定且由于传统算法。这可能是因为新算法中重要度限值的引入,一定程度上排除了主链路高点击量带来的干扰。
四、结论
在巨量数据背景下,基于大数据分析的旅游微博用户偏爱链路算法能够以更快的运算速率和更高的计算准确率对数据进行挖掘。如何将挖掘得到的用户偏爱链路结果应用于微博平台改造或用于个性化旅游策略推送,是需要进一步研究的问题。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23 13:25:46
综艺报(2021年5期)2021-05-08 03:50:05
电子制作(2018年23期)2018-12-26 01:01:16
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
汽车维修技师(2017年10期)2017-03-17 02:25:01
电测与仪表(2016年5期)2016-04-22 01:13:46
电子测试(2015年18期)2016-01-14 01:22:58
科学24小时(2014年2期)2014-09-10 07:22:44
计算机与网络(2014年7期)2014-03-25 10:57:07
