
基于深度神经网络的车辆检测系统
2019-05-20 09:56:30宋佳兴刘庆伟
传动技术 2019年4期
宋佳兴 刘庆伟 罗 哲 喻 凡
(上海交通大学,机械系统与振动国家重点实验室,上海 200240)
0 前言
车载视觉中的识别目标包括车辆、行人、交通标志、信号灯、障碍物等,其中对车辆的检测是智能辅助驾驶系统环境感知的重要组成部分,检测水平的高低直接影响到整个智能驾驶辅助系统的运行质量。对于车载车辆检测算法的研究源远流长,但近年来基于深度学习的视觉算法发展迅速,目标检测算法检测精度和理解能力都有了长足的进步,这给车辆检测算法带来了新的研究方向。但是基于深度学习的目标检测算法庞大的存储需求和计算量也给其在车载系统上的应用带来了巨大的挑战,需要算法架构层面进行精细的优化设计。本文将对基于深度学习算法的车载车辆检测系统进行研究。
1 目检测研究现状
深度学习是机器学习领域新的发展方向,是近十年来人工智能领域的重要研究方向,在语音识别、自然语言处理、计算机视觉、图像与视频分析、多媒体等诸多领域的应用取得了突破性进展。深度学习的概念来源于人工神经网络的发展,当能够成功训练隐层数量足够多的多层感知器模型(Multilayer Perceptron, MLP)时,可以获得强大的表征能力,这就是典型的深度学习结构[1]。人工神经网络的起源可追溯到20世纪40年代,该算法以大脑认知的机理为指导来解决各种机器学习问题。但是由于理论分析难度较大,训练数据量制约,训练过程复杂,以及计算量庞大和优化求解难等问题,人工神经网络算法并未取得很好的效果,逐渐被人工智能研究学者冷落。2006年,多伦多大学的G.E.Hinton提出深度学习概念、多层级的深度网络架构和基于样本数据的非监督贪心逐层训练算法,为解决深层网络优化求解问题带来希望[2]。2012年,Hinton和他的学生Alex Krizhevsky设计的深度网络AlexNet获得ImageNet图像分类比赛冠军,准确率超过传统图像分类算法10%以上,证明了深度学习模型在计算机视觉领域的巨大应用潜力,引发了深度学习研究的热潮[3]。
继AlexNet在图片分类任务中取得历史性突破之后,卷积神经网络在目标检测领域也备受关注,如今已超越传统机器视觉方法而成为目标检测领域的主流算法。基于卷积神经网络的目标检测算法,通常利用优秀的图像分类模型强大的特征提取能力处理输入数据,然后根据提取出的高层次抽象特征进行目标检测。目前比较通用的检测框架包括以Faster RCNN为代表的two-stage框架和以SSD为代表的one-stage框架。
Girshick等人[4]在2014年提出R-CNN目标检测模型。该模型主要分三个部分:首先使用选择性搜索(selective search)算法处理输入图像,提取车辆检测的候选区域;然后对候选区域进行使用卷积运算,完成特征提取工作;最后将提取出的特征送入SVM分类器完成目标检测任务。该算法发挥了卷积神经网络强大的特征提取能力,使目标检测效果得到大幅提升,但是算法各部分分开进行,训练繁琐,且存在大量重复计算,检测时间较长。2015年,Girshick[5]提出Fast R-CNN,因为卷积计算可保持空间信息,故引入候选区域共享卷积思想,将提取候选区域操作放在特征提取之后,极大地减少了重复计算,提高了检测速度;使用全连接层代替SVM分类器完成目标检测任务,使特征提取部分和检测部分可以结合起来一起训练。Ren等人[6]提出的Faster R-CNN使用卷积神经网络提取候选区域,在特征提取之后首先用RPN网络对图片各位置进行初步检测,然后再进行进一步的目标识别和边界框微调。Faster R-CNN将特征提取、候选区域生成、分类和边界框微调等目标检测各部分统一到一个深度学习模型中,取得了非常好的效果,是two-stage目标检测框架的代表作。
不同于two-stage目标检测框架,one-stage框架中候选区域生成、分类和边界框微调同时进行,大大提高了检测效率,但会损失一些准确度。经典的one-stage算法包括YOLO系列、SSD等。YOLO(you only look once)[7]将输入图像划分成7×7的区域,每个区域负责中心落在该格子的目标的检测任务,使用卷积层和全连接层一次性输出各区域包含目标的概率、目标的类别以及边界框微调,检测速度达到实时,但准确度低于Faster R-CNN等two-stage检测算法。Liu等人[8]提出的SSD(Single Shot MultiBox Detector)检测算法将锚点(anchor)机制引入one-stage算法,并对多层次的特征图进行预测,使SSD算法在达到实时的检测速度情况下,也达到了two-stage检测算法的检测和定位精度。
深度卷积神经网络凭借强大的特征提取能力和端到端的算法框架,在目标检测领域已经取代了传统算法成为主流研究趋势,这也给车辆检测算法指明了发展方向。但车辆检测实际问题中硬件平台多为嵌入式平台,难以承受深度卷积神经网络庞大的存储空间和计算量需求,因此其在车载芯片等工况下的应用受到限制。本文以深度卷积神经网络在车辆检测领域的实际应用问题为出发点,进行算法架构、算法加速和硬件优化的协同设计,旨在完成深度卷积神经网络模型在车载工况下的落地应用。
2 车辆检测算法架构
基于深度卷积神经网络的目标检测模型主要由两部分组成,首先是特征提取网络,多由图像分类模型通过迁移学习得到,具有强大的特征提取能力;然后是检测网络,比较有代表性的包括Faster R-CNN、YOLO和SSD等的检测部分,完成从特征图到检测结果的计算。由于本文面向车载工况,硬件平台算力和能耗受限,要求车辆检测算法拥有高准确率低计算量的特点,故而需要设计轻量高效的模型架构。本文使用MobileNet V2图像分类模型作为特征提取网络,改进并应用SSD检测部分,完成车辆检测模型的搭建。
2.1 特征提取部分
MobileNet V2图像分类模型是谷歌于2018年1月公布的轻量级卷积神经网络模型[9],应用了深度可分离卷积(depthwise separable convolution)、倒置残差模块(inverted residuals block)和线性瓶颈(linear bottlenecks)等精细化模型设计技巧,在计算量很小的情况下获得了相当高的分类精度,是非常适合嵌入式端部署的深度卷积神经网络,如表1所示。

表1 MobileNet V2性能
MobileNet V2模型结构如表2所示。输入图像大小为224×224×3;首先经过一个卷积层,卷积核大小为3×3×32,步长为2;然后经过17个大小不同的网络模块,模块中应用了深度可分离卷积、倒置残差模块和线性瓶颈等高效网络设计;最后使用1×1卷积层和平均池化层处理,输出分类结果向量。

表2 MobileNet V2结构
MobileNet V2中的网络模块主要包括两种,步长为1的模块包含残差连接,步长为2的模块不包含残差连接。如图1所示,每个模块中先使用1×1卷积完成维度控制和层间信息交互,然后使用深度可分离卷积完成主要的特征提取任务。当步长为1时,模块输入和输出的特征图大小相同,可部署残差连接进一步提高网络特征提取能力和性价比。
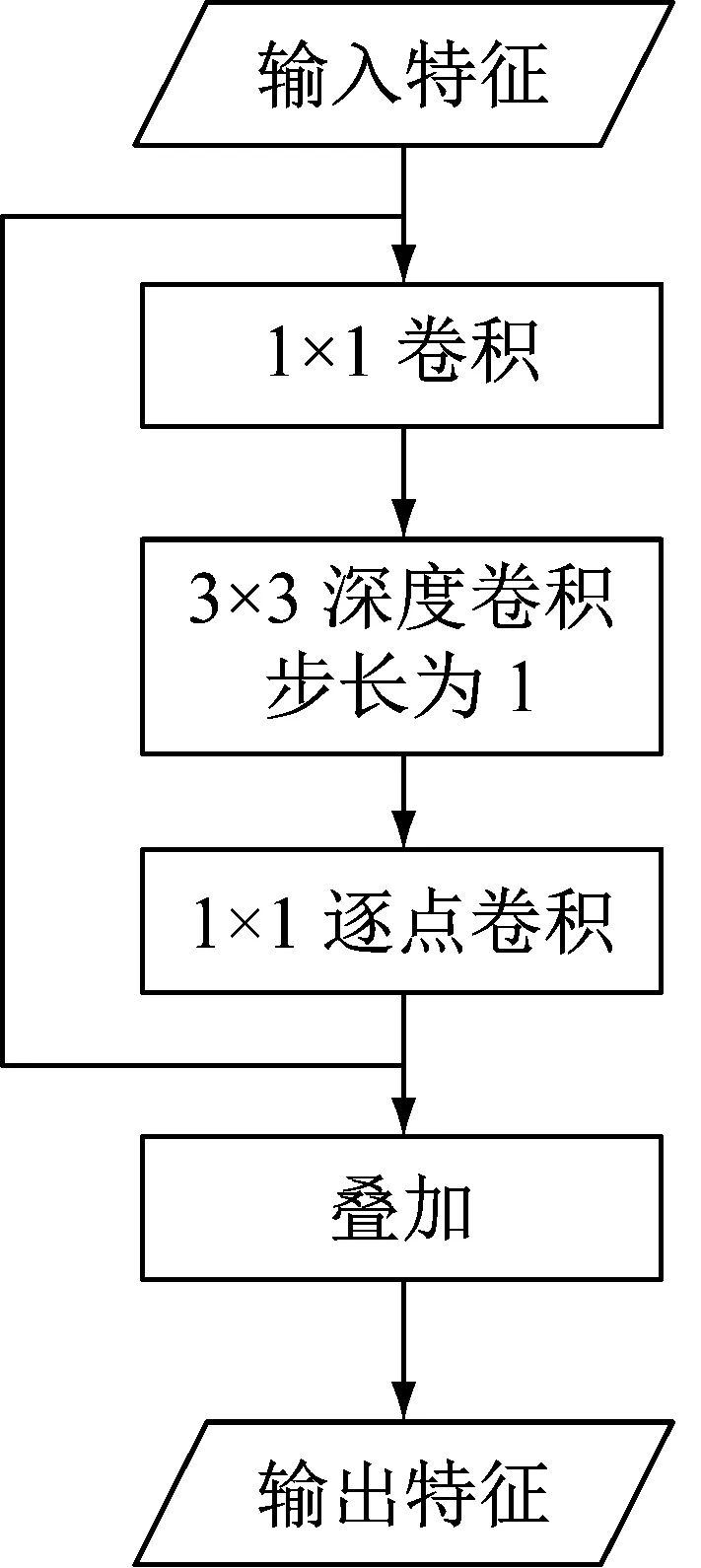
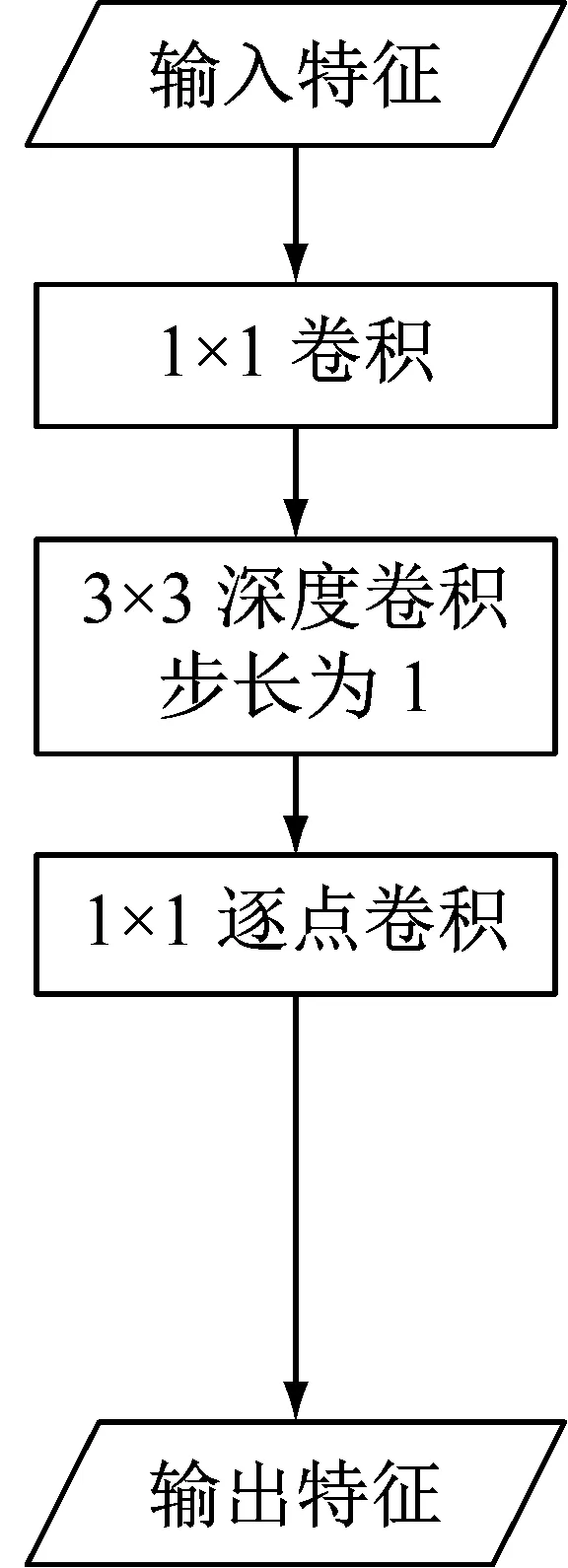
图1 MobileNet V2网络模块
2.2 检测网络部分
检测网络部分的任务是根据特征提取部分输出的高层次抽象特征进行目标检测。以Faster RCNN为代表的two-stage框架使用RPN网络对图片各位置进行初步筛选,然后对筛选结果再进行进一步的目标识别和边界框微调。以SSD为代表的one-stage框架不使用RPN网络,而是将候选区域生成、分类和边界框微调同时进行。一般来说,one-stage框架检测效率高,但会损失一些准确度。
SSD作为非常优秀的one-stage目标检测模型,初始的特征提取网络为VGG16,有很好的特征提取能力。但由上文所述,VGG16等大型深度卷积网络因计算量大等问题不适宜应用到嵌入式端,故本文采用MobileNet V2轻量级卷积神经网络作为特征提取部分。而SSD的one-stage目标检测框架具有高效准确的特点,故本文以SSD检测框架作为模型检测部分的基础网络。SSD的检测网络在特征提取网络末尾增加若干层尺寸逐渐减小的卷积层,进一步提取多层次特征;然后对各层次的特征图通过卷积运算,获取其输出;最后根据该输出判断各像素点的检测结果。
3 车辆检测模型搭建
3.1 车辆检测数据集
本文选用KITTI数据集作为训练和测试数据。KITTI数据集是针对自动驾驶领域计算机视觉算法的权威评测数据集。该数据集支持立体图像(stereo),光流(optical flow)、视觉测距(visual odometry)、目标检测(object detection)、跟踪(tracking)和图像分割(semantics)等计算机视觉算法在车载环境下的性能测评。KITTI数据集中的图像数据由车载设备真实采集而来,采集场景包括市区、乡村和高速公路等,检测目标包括行人、自行车、货车和小轿车等,并存在遮挡等情况。目标检测数据集由7481个训练图像和7518个测试图像组成,包括总共80256个标记物体。
3.2 车辆检测典型工况提取
KITTI数据集由车载设备在不同驾驶场景实地采集而来,对真实路况有很好的代表性。为了提取车辆检测的典型工况,本文采用了k-means聚类算法对KITTI数据集中的车辆标注信息进行处理,提取出行驶工况下车载摄像头所捕捉的车辆大小和长宽比的典型数据,用以优化目标检测网络对车载车辆检测工况的检测性能。
K-means算法是基于距离聚类的代表性算法,根据两个对象之间的距离远近来判断其相似度,相似度高的对象判定属于同簇,最终将所有对象分成紧凑且独立的k簇,完成聚类任务。使用k-means算法对KITTI数据集的车辆标注信息进行聚类处理,可得到一系列真实路况中最常出现的典型车辆边界框,从而作为优化车辆检测算法的依据。原始的k-means算法以欧式距离作为两元素间距离的衡量标准。针对目标检测问题,聚类元素为车辆边界框,若使用欧式距离作为衡量标准,则大尺寸边界框之间的微小差距都将大于小尺寸边界框之间的显著差距,故而本文选用交并比(Intersection over Union, IOU)作为距离公式。交并比定义为两矩形边界框交集与其并集的比值,可衡量边界框之间的相似度,并且不受边界框尺寸的影响。如图2所示。

图2 交并比
我们将数据集中所有车辆边界框中心点固定在一起,然后以IOU作为边界框之间的距离公式,对边界框做k-means聚类。聚类算法以IOU为距离标准将数据集中的车辆边界框分为若干簇,各簇的中心点边界框拥有最能代表该类的边界框形状和大小。提取各簇的中心点边界框信息,如表3所示。这些典型的车辆边界框可作为优化检测部分网络的依据。

表3 中心点边界框信息
3.3 默认边界框参数优化
SSD为所有进行检测的特征图的每个位置设置了一组默认的边界框,这些边界框有不同的大小和长宽比,对应原始图像的不同区域。经过检测网络后,对应特征图中每个像素点都相应输出了一个向量,该向量中包含该像素点对应的各默认边界框包含各检测目标的概率、该默认边界框的微调数据等检测结果。将得到的检测结果与默认边界框参数融合之后,即可得到最终的检测结果。SSD将不同层次的特征图送入检测网络,并设定了不同尺寸和长宽比的默认边界框,较好地覆盖了原始图像中各种大小和形状的检测目标。实验发现,将正方形默认边界框修改为瘦高和宽扁的默认边界框,可以带来2.9%的mAP提升。由此可见默认边界框设置的合理性对模型检测精度有显著影响。
SSD框架中默认边界框尺寸设置算法为,
(1)
其中,sk为第k层特征图上的默认边界框尺度;smin为最低层次特征图上默认边界框尺度,设为0.2;smax为最高层次特征图上默认边界框尺度,设为0.9;m为设置边界框的特征图总层数;k为特征图层数;
SSD框架中默认边界框长宽比设置为,
(2)
相应的边界框长宽为,
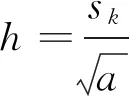
(3)
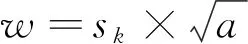
(4)
对于,增加边长为的边界框。即每个特征图的监测点对应设置了六个默认边界框。SSD中默认边界框的合理设置带来了显著的检测精度提升,但针对车辆检测工况,该默认边界框设置并不是最优的,本文使用先验的数据驱动的方式设置更为合理的默认边界框。在2.3.2节中,我们通过k-means算法提取了车辆检测工况下车辆边界框的典型值,本文以该数据为指导,可设置更加贴近车辆检测数据集的默认边界框参数。如表4所示。
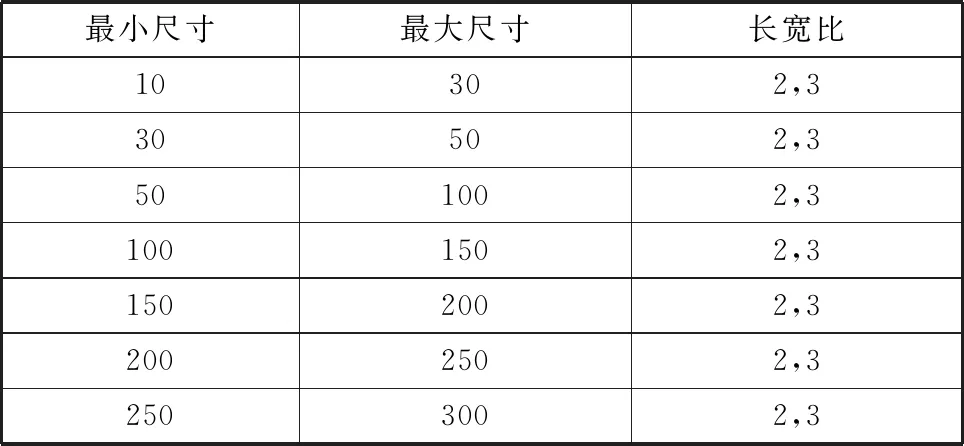
表4 默认边界框参数
3.4 特征图设置优化
SSD检测框架使用了不同层次不同尺度的特征图同时进行检测,显著提高了检测精度。在整个卷积神经网络中,一般来说越靠前的特征图分辨率越高,信息越详细,感受野越小;越靠后的特征图分辨率越低,信息越抽象,感受野越大。增加较底层的特征图可提高模型对小目标的检测能力,如SSD检测框架中增加特征提取网络中比较靠前的特征图conv4_3,明显提高了检测模型的精度。根据k-means聚类结果可以看到,车辆检测工况中小型目标非常多,因此本文在SSD检测框架下适当增加靠前的特征图以提高对小目标的检测能力。
3.5 网络结构
本文搭建的车辆检测算法模型结构主要包含特征提取网络和检测网络。特征提取网络选用MobileNet V2模型,输入图像改为300×300,去掉其最后两层,网络结构如表5所示。
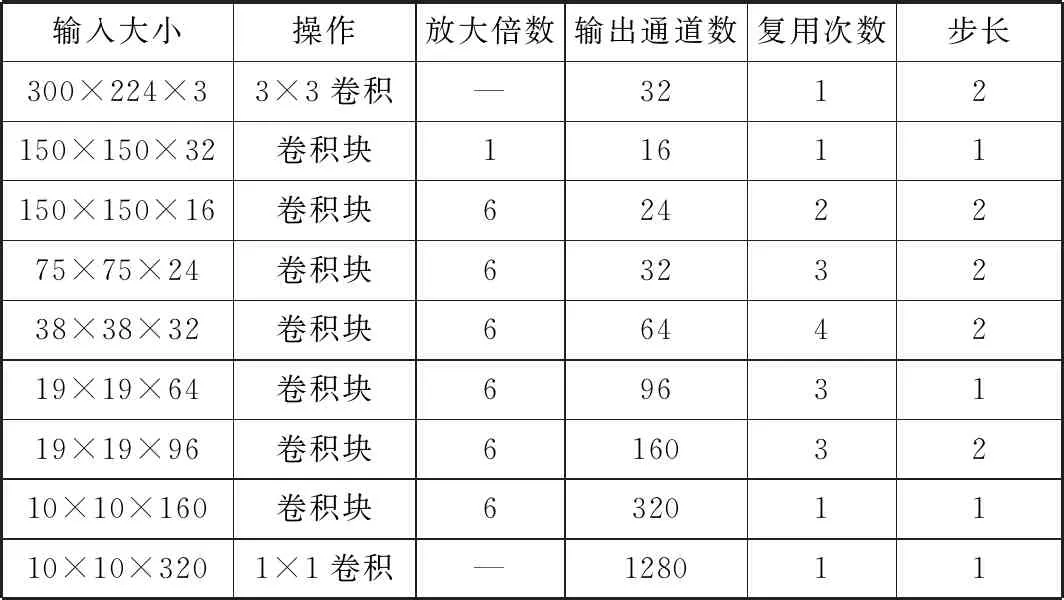
表5 特征提取部分网络结构
检测网络以SSD检测网络为基础做了优化和修改,增加的特征提取层结构如表6所示。

表6 增加的特征提取层
提取了六层特征图进行多尺度检测,各层参数和默认边界框设置如表7所示。

表7 目标检测网络结构
4 车辆检测模型实现
4.1 损失函数
本算法的损失函数采用SSD检测框架中的损失函数,主要由概率损失和位置损失两部分组成,公式如下,
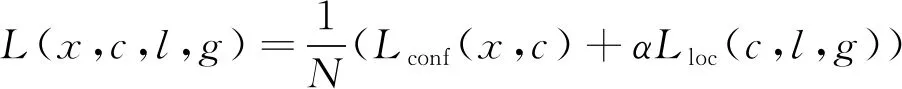
(5)
其中,L为损失函数;x为概率真实值;c为预测概率;l为预测边界框位置;g为边界框位置真实值;N为存在目标的默认边界框数量;Lconf为概率损失;α为概率损失和位置损失之间的比例系数,交叉验证设置为1;Lloc为位置损失。
概率损失采用的是softmax损失函数,公式如下,
(6)

位置损失采用的是smooth L1损失函数,公式如下,
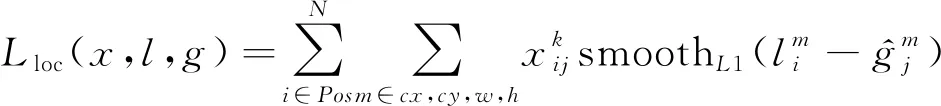
(7)
Smooth L1损失函数在比较大的误差区域使用线性函数,而不是指数函数,比较稳定,在0附近使用平方函数使其更加平滑,在回归问题中应用广泛,其公式如下,
(8)
4.2 数据增广
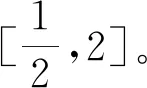
4.3 训练过程
本文使用Caffe深度学习框架进行实验,首先下载KITTI车辆检测数据集,并提取其车辆边界框标注信息。然后将数据集转换为Caffe支持的LMDB格式。然后使用Caffe框架搭建网络结构,配置数据增广和损失函数,完成整体算法模型搭建。最后使用处理好的数据集,选择合适的训练参数对模型进行训练。经过多次实验和检查验证,最终训练参数如表8所示。
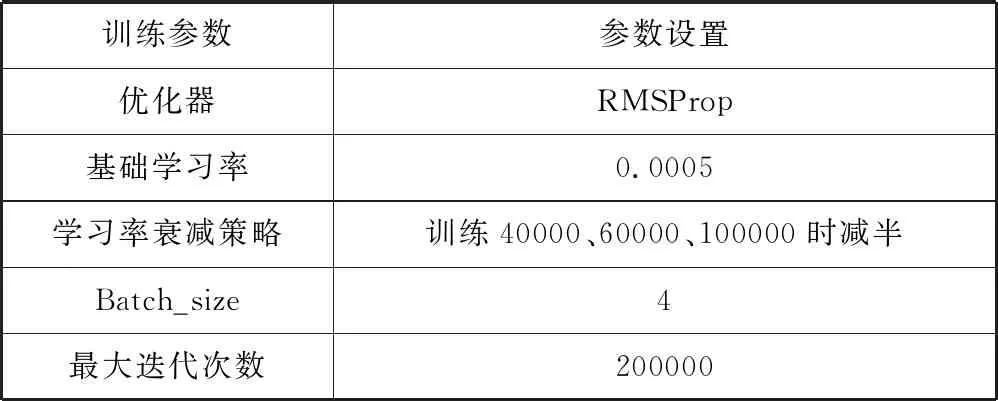
表8 训练参数设置
多次实验迭代后,以最合适的训练参数进行训练,在本文硬件条件下,用时约10小时。最优训练条件下,模型mAP与训练进度关系如图3所示。由图可知,本文模型收敛快速稳定,且精度很高。
4.4 模型测试
针对KITTI车辆检测数据集,测试了本文构建的车辆检测算法mAP和计算耗时。
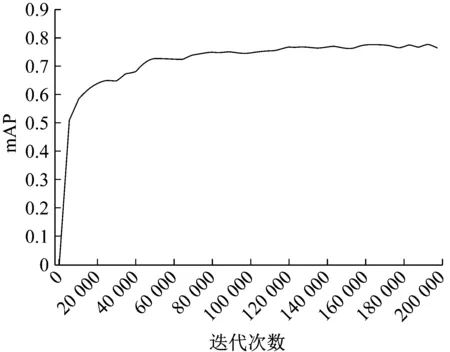
图3 模型训练过程
如图4所示,本模型在实验条件下,一次前向运算耗时36.2 ms,检测帧率可达27.6。检测效果如图5和图6所示。可以看到,在存在阴影、遮挡和不同姿态的工况下,该模型都可以较好地完成车辆检测任务,且生成的边界框非常准确。
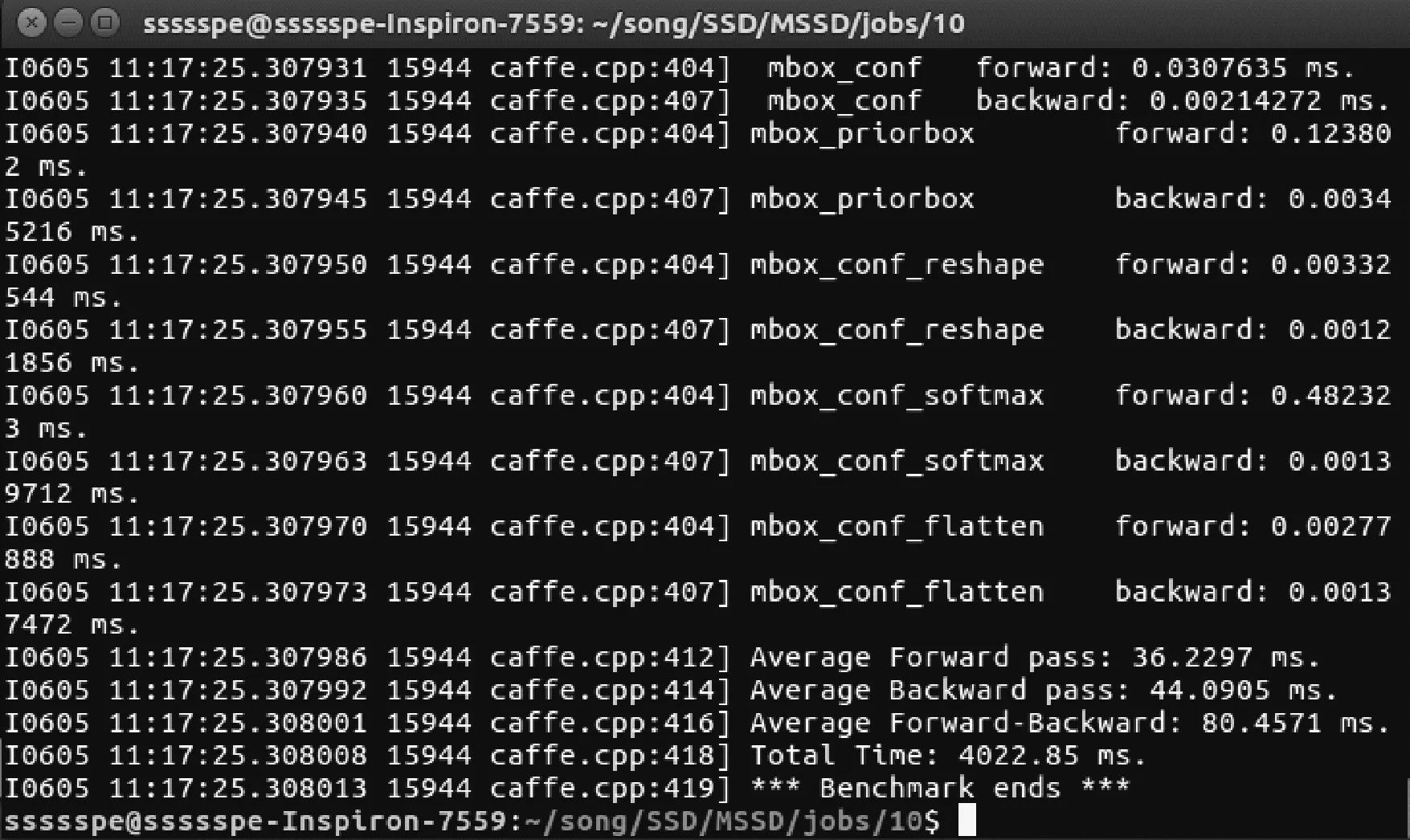
图4 模型运行时间测试

图5 模型检测效果测试

图6 模型检测效果测试
本文对原SSD模型、原MobileNet V2 SSDLite模型以及经过本文构建的模型在模型性能、计算耗时以及模型存储空间需求等方面进行了对比。
如表9所示,以VGG16为特征提取网络的原SSD模型在该车辆检测工况下取得了最高的性能得分,但计算量巨大,计算耗时长,存储空间需求高;而以MobileNet V2和SSDLite为主体框架的检测模型大幅降低了计算耗时,将计算需求和存储需求降到嵌入式端可以考虑的范围,但有较大的精度损失;本文中经过优化的模型则在保持低计算耗时和存储空间需求的情况下,取得了较高的检测性能,实现了精度与速度的双重优化,是优秀的适合于车辆检测工况的算法模型。
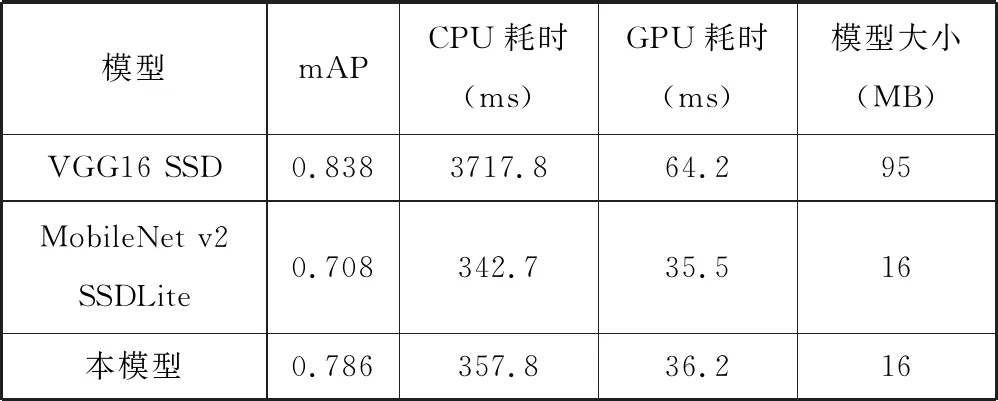
表9 各模型性能对比
5 结论
本文对深度卷积神经网络在车辆检测领域的应用进行研究,针对深度学习模型在嵌入式平台难以应用的问题,对算法架构进行了精细化设计和优化。为了解决深度学习模型计算量和存储需求太大的问题,本文采用MobileNet V2轻量级图像分类网络和SSDLite目标检测框架作为车辆检测算法主体,通过高效化网络设计大幅降低了计算和存储需求。通过使用k-means聚类算法提取了车辆检测特征工况,并根据其结果优化了模型检测部分,在几乎不增加计算量的情况下提高了算法的准确率,最终搭建完成的车辆检测模型准确率高、计算速度快。
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
证券法律评论(2018年0期)2018-08-31 02:33:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
外语学刊(2014年6期)2014-04-18 09:11:49
电视技术(2014年19期)2014-03-11 15:38:20
