
基于卷积神经网络的主变压器外观缺陷检测方法
2019-05-17 02:46位一鸣
浙江电力 2019年4期
位一鸣,童 力,罗 麟,杨 珊
(1.国网浙江省电力有限公司舟山供电公司,浙江 舟山 316021;2.国网浙江省电力有限公司电力科学研究院,杭州 310014)
0 引言
目前,变电设备状态检修技术主要是根据电压、电流等电气量和油温、油压等物理量来判断设备的运行状态[1]。随着变电站智能化程度的提升以及智能运检技术的逐步普及,开始出现利用图像识别、文本挖掘等人工智能技术辅助开展设备健康状态判断[2-3]。目前,变电站运维人员通常采用照相机、摄像机等手持终端设备对站内主要电气设备进行图像采集;除此之外,大量的巡检机器人、分布式摄像头已经布置于变电站,负责图像的采集和现场的监控。视觉图像能够反映设备存在的缺陷问题,通常包括漏油、锈蚀、断路器开合及零部件损坏等。然而,变电站设备数量众多,一方面需要有经验的运维人员来进行缺陷识别,另一方面单纯依赖人工,难以做到实时地或预防性地获取设备的缺陷状况。
基于人工智能的图像识别技术发展已经十分成熟,在人脸识别、自动驾驶等领域已经有了较为广泛的应用;与此同时,在能源、机械等工业领域,利用图象识别技术对设备外观进行图像检测也有许多深入的研究与应用。在电力行业中,图像识别技术在输电线路绝缘子外观检测方面已经有了初步应用。供电公司利用无人机对输电线路绝缘子进行图像采集后,召集运维专业人员对各种类型缺陷进行分类打标,得到高质量的输电线路缺陷图像样本集;在此基础上,利用红外分析方法[4-5]完成缺陷定性,基于角点、梯度[6-7]等图形特征或基于目标检测方法[8-9]进行绝缘子缺陷的定位。对于变电设备,现阶段的图像识别技术主要基于红外热图[10],但红外图无法有效展示出设备的外观缺陷,依旧需要基于可见光的检测方式。以变压器为例,目前基于可见光的变压器外观缺陷检测技术,大多局限于单一部件,并且对图像采集的条件有较高要求,而机器人巡视采集的图像无法满足变压器精确分析的技术需求[11]。
研究表明,无论是变电或输电设备,在利用可见光图像进行外观缺陷识别检测时,主要面临以下两方面问题:
(1)定位不准,即设备定位依靠预先设置完成,但图像采集设备(如巡检机器人)的行进误差往往会导致目标对象无法出现在采集图像的准确位置,导致检测失准。
(2)负样本数量不足,因为变电站内采集的设备图像多为正样本,包含锈蚀、漏油等外观缺陷的负样本数量等级不匹配,会导致算法模拟训练过拟合、泛化能力差等问题,造成误检。
本文以变电站内的主变压器(以下简称“主变”)为对象,提出了一种基于CNN(卷积神经网络)的主变外观缺陷检测方法。首先,针对定位问题,利用SSD 算法精准截取目标设备,用于检测外观缺陷。然后,针对负样本不足问题,利用基于VGG-Net 的风格迁移算法,生成缺陷样本用于扩充样本集,提升判别模型的泛化能力。 最后,利用实际运维采集的主变图像样本集进行算法验证,校验本文所提方法的变压器外观缺陷识别检出能力,对方法的有效性和可行性进行验证。
1 基于机器视觉的主变外观缺陷检测
目前,智能化变电站内主要的图像采集设备包括巡检机器人、分布式摄像头以及各类手持终端设备。相比于手持终端,巡检机器人、分布式摄像头更加适用于无人值守变电站内采集设备图像。 对于分布式摄像头,电网公司出于安全考虑,运维人员只能调取实时画面,无法获取变电站监控系统硬盘内的视频数据,因而无法作为图像识别算法的数据样本。巡检机器人拥有强大的计算能力,不仅能够完成图像采集,还具备离线/在线分析的能力。综上,巡检机器人更加适用于变电站内主变外观缺陷检测所需图像的采集平台。通常,基于机器视觉的电力设备外观缺陷识别与检测由采集样本、目标提取和外观检测3 个环节组成。
(1)采集样本,即获取待检测对象的图像样本集。本文以国网浙江省电力有限公司的12 座变电站中利用智能巡检机器人采集到的主变样本图像构成样本集,图1 为主变样本图像示例。
(2)目标检测,即提取图像中的被检测目标设备。由于图像采集设备(巡检机器人)摄制位置、角度可能存在误差,导致无法实现目标对象的精确提取,因而需要对目标设备进行定位识别。
(3)外观检测,即利用深度神经网络算法建立学习模型,对图像中被提取的设备进行外观缺陷的识别和检测,并给出结果供运维人员分析和判别。
2 基于深度学习的变压器目标提取

图1 主变样本图像示例
由于图像采集过程中各种因素的偏差问题,在进行外观检测缺陷识别前需要对图像进行目标提取。目前,针对电力设备应用场合,主要采用提取固定特征的目标提取方法,如角点特征、微分特征及统计直方图等。这些方法基于特定的特征,依赖人工调整参数阈值,在使用时存在判断逻辑复杂、稳定性较差等问题,并且会随着光线、场景的变化造成检测失准。为了实现目标对象的准确提取,本文提出了基于深度神经网络算法实现目标检测,即利用大量变电站内主变图像样本数据训练机器学习模型,来提取图像中目标物体的位置,这样做可以带来更高的准确性和更强的泛化能力。
目前,常用目标检测方法包括RCNN 算法[12]、Fast-RCNN 算法[13]、Faster-RCNN 算法[14]。RCNN算法是利用Selective Search 完成对图像的分割,并利用色差、纹理等特征进行区域合并,筛选出目标区域,再对目标区域用CNN 作出判别,其工作原理如图2 所示。但是,由于变电站中获取到的图像样本背景、纹理均较为复杂,使得Selective Search 算法提取目标区域往往耗时较长,并且以纹理相似度作为分割标准使得检测准确度太低,因而该算法不适用于主变设备的目标检测。在此基础上,Fast-RCNN 算法、Faster-RCNN算法提出用神经网络取代Selective Search 完成预选框的选取。这样在计算速度、准确率上均有所提升,但是仍旧无法避免目标位置检测与目标种类识别需要各经历一次神经网络计算的问题,使得计算量依旧偏大。
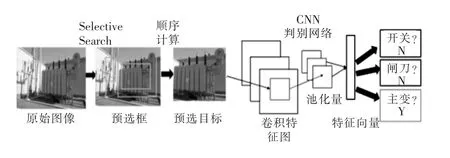
图2 基于RCNN 的目标检测流程
为了解决上述问题,有学者提出YOLO[15]算法,通过网格将图像切分为固定的“小块”,并对每个“小块”利用多尺度滑窗进行目标检测,再利用神经网络计算目标位置与目标类别,其目标检测流程如图3 所示。这样一来,经历一次神经网络就可同时得到目标位置和类型。但是网格划分的尺度大小会显著影响检出效果,算法性能上存在着大目标和小目标难以有效兼顾的问题。
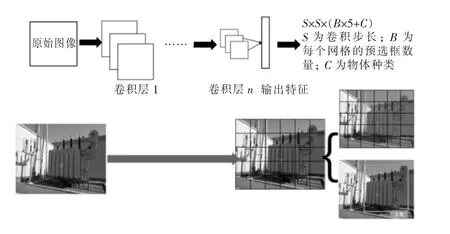
图3 基于YOLO 算法的目标检测流程
综合以上算法的优缺点,本文提出基于SSD深度学习的目标提取方法。在YOLO 算法的基础上,结合SSD[16]算法进行神经网络学习,利用不同层次的卷积层实现多尺度滑窗目标检测,其检测流程如图4 所示。首先,经过第1 层卷积处理后,特征图像包含了丰富的局部特征,利于检测小尺度目标,因此本文中用于对特征图进行划分的网格比较密集,为3×3 网格。随后,每个网格根据特征图的结果,输出当前网格总共B 个尺度的检测框相应目标位置以及置信度p、对目标所有C 个可能类型的判定结果。 随着卷积层的加深,特征图中包含的局部特征逐渐减少,整体特征逐渐增加,更加利于大尺度目标的检测,因此用于对特征图进行划分的网格愈发稀疏。在图4中,第2 层的卷积图为2×2 网格,第3 层卷积图中只有1 个网格。最终对于SSD 算法而言,第i层输出的结果总数为Si×Si×(B×5+C),其中Si为第i 层卷积步长。最后,将不同层次的特征图检测结果进行汇总、去重,得到最后的精确检测结果。
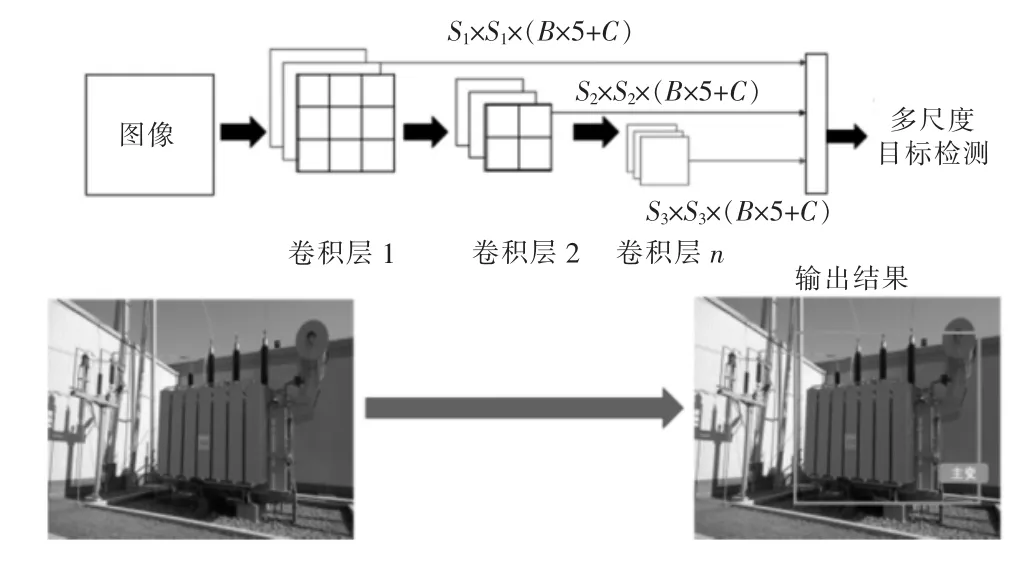
图4 基于SSD 算法的目标检测流程
可以看到,相较于YOLO 算法只在一种网格划分细度下进行目标检测,SSD 算法利用了多层特征图不同密度的网格进行目标检测,对大尺寸目标和小尺寸目标都有良好的识别能力。相比于前述几种典型方法,SSD 算法兼顾了运算速度与检测准确率,因此本文采用SSD 算法完成主变图像目标检测。
3 基于CNN 算法的变压器外观检测
本文提出基于Le-net 算法[17]的外观判别神经网络,用于实现对提取的变压器设备外观缺陷的准确识别。设定的主变外观缺陷检测目标为锈蚀和漏油两类最常见的典型缺陷,而在日常巡检工作过程中,这两类缺陷图像通常难以采集。本文通过网络进行这两类缺陷图像的样本收集工作,并基于风格迁移算法对设备缺陷负样本进行扩充,以有效解决负样本不足的问题。
3.1 基于Le-net5 的判别网络
主变的锈蚀、漏油等外观缺陷具有如下特点:与正常区域有明显的像素差异,缺陷区域范围随机性较大。因此,用于实现主变外观缺陷检测的算法需要在特征提取时能明显区分局部区域之间的差异,并能对图片全部区域进行描述。由于进行外观检测的图像是已经过SSD 算法目标检测提取出的设备区域,使得图像中不再有复杂背景,因而不需要复杂的网络(诸如Alexnet、Googlenet)来提升判别模型的泛化能力。 除此之外, 由于GBDT、SVM、BP-network 等基于统计学习的分析方法缺乏对局部特征的表述能力,因此本文提出基于Le-net5 算法构建判别网络,充分利用Le-net5 算法对于局部特征与全局特征的良好描述能力,来完成主变外观缺陷的识别检出。基于Le-net5 算法的判别网络结构如图5 所示。

图5 基于Le-net5 算法的判别网络结构
相较于简单的BP-network,Le-net5 的卷积层与池化层对于局部特征与全局特征都有良好的拟合能力;相对于复杂的深度神经网络,Le-net5具有结构简单、易于计算的特点。如图5 所示,首先将原始图像经过多层卷积、池化处理,使原本大尺度的RGB 三维度图像简化为多维度、小尺度的特征图;随后,利用全连接层网络,将特征图连接为列向量化的图像特征;最后,利用softmax 判别模型,对图像中的设备外观状态进行判别,最终完成典型缺陷的识别检出。基于上述方法,在具备良好样本集的前提条件下,Le-net5算法对类似的缺陷分类问题具有十分出色的检出效果。但是在样本数量不足,尤其是负样本数量欠缺的情况下,基于Le-net5 的判别模型容易产生过拟合,无法取得理想的缺陷检出效果。
3.2 基于VGG-Net 的风格迁移数据增生
相较于输电设备,针对变电设备开展图像识别应用存在着负样本数量少、异常区域小的问题。为了生成训练模型并提升模型的泛化能力,需要人为补充负样本。目前,已有的生成模型的框架有GAN、VAE 等[18-19];但是在生成模型的同时,需要大量的样本进行训练。在本文所述应用场景中,主变的外观缺陷缺少足够数量的负样本,难以为生成模型的构造提供良好的数据集。
尽管在实际生产运维中难以收集足够数量的主变外观缺陷负样本,但可以采集到许多其他设备的生锈、油污样本,这些样本中包含了重要纹理特征。因此,本文提出利用VGG-Net 算法,在保留图像内容的前提下完成风格迁移。 在文献[20]中,有算法将图像视为由纹理与内容两部分构成;通过浅层的卷积层便可提取到局部表征纹理的特征,而通过深层的卷积层便可提取到图像的内容特征。假设某l 层得到的运算响应为:

式中:Nl为该层卷积核个数;Ml为卷积核大小;R 为卷积的取值空间。
以Fl,ij表示l 层第i 个卷积核所在位置j 的输出,此时l 层的Content Loss(内容损失)为:
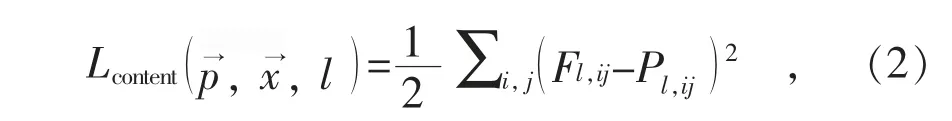
由于图像内容需在深层网络中提取,因此式(1)中l 层即为最深层。
l 层的Style Loss(风格损失)为:
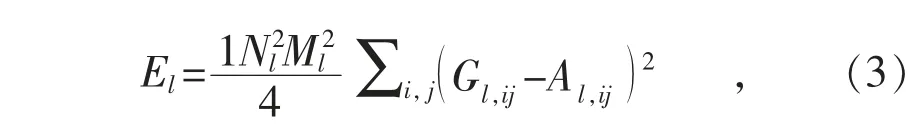
式中:Al和Gl为图像对于l 层的响应。
由于图像是由多层构成,其总的风格损失为:
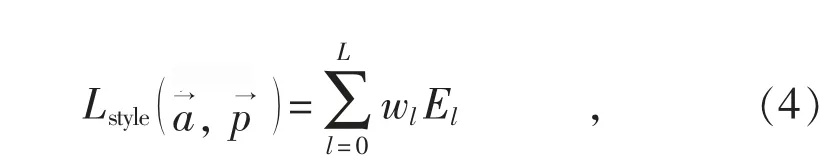
总的损失为:

式中:α 和β 为内容损失与风格损失的计算系数,可以根据需要调整。
最终,基于VGG-Net 风格迁移的负样本生成流程如图6 所示。
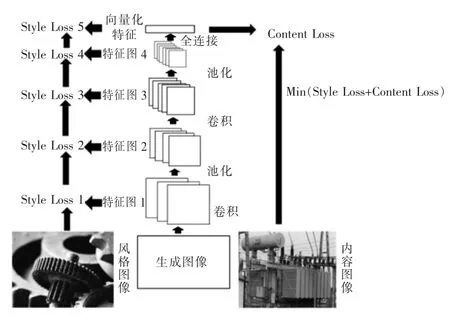
图6 基于VGG-net 风格迁移的负样本生成流程
在实际条件下,主变的锈斑、漏油位置通常是不固定的,而生成的异常图像全图都包含了异常纹理。因此,为得到较为真实的异常图像,需要将正常图像与异常图像进行融合,如图7 所示。
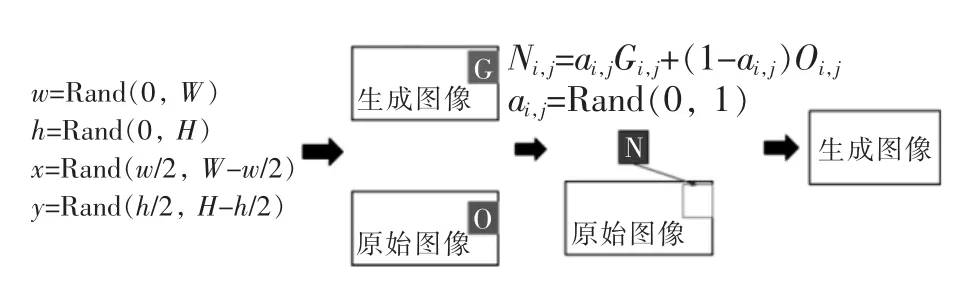
图7 生成图与原始图融合流程
本文采用了一种随机缺陷区域融合方法,以获得较为真实的缺陷图像。
4 算法验证
根据在国网浙江省电力有限公司12 座变电站采集到的主变图像所形成的样本集, 本文在Tensorflow 框架下对所提检测方法进行测试验证,执行算法运算的硬件配置如表1 所示。

表1 算法运行硬件配置
4.1 目标检测
如前所述,搭建基于SSD 深度学习算法的目标检测模型,关键参数如表2 所示。
在进行目标检测前,将采集到的样本划分为训练集和测试集,基于训练集对模型进行训练后,在测试集上对算法模型进行检验。训练集数量为1 000,测试集数量为200,经过10 000 次迭代后,得到的结果如表3 所示。与此同时,将本文所提SSD 算法与前述Faster-RCNN、YOLO 算法的图像处理速度和正确率进行对比,结果如表4所示。
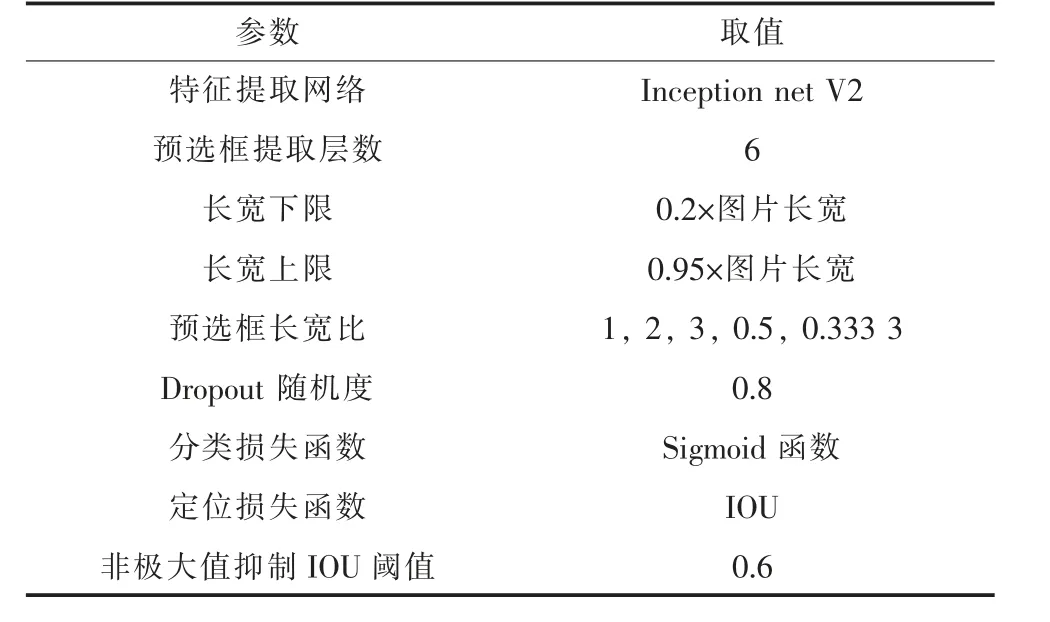
表2 SSD 模型关键参数

表3 基于SSD 算法模型的目标检测效果

表4 其他算法效果对比
可以看到,SSD 算法计算出的目标区域与标注区域的平均重合率能够达到95%,并且预先标注的变压器关键部位未出现遗漏现象; 相比于YOLO 算法,SSD 算法的图片处理时间虽然慢了6 ms,但是检测区域重合率高出了7%; 尽管Faster-RCNN 的检测区域重合率最高,但处理速度要慢得多。由此可见,本文所提出的SSD 算法能够做到正确率与速度兼顾,满足设备外观检测的需求。图8 所示为几个实际变电站图像样本目标检测结果示例,其中实线方框对应目标检测区域,虚线方框对应标注区域。显然,标注区域与目标区域基本重合,表明本文所提方法能够准确地提取变压器对象。

图8 测试样本变压器目标检测示例
4.2 基于实际样本集的外观检测
在本文采集到的样本中,正样本1 000 张,漏油样本50 张,锈蚀样本50 张。按照50%的比例分配训练样本和测试样本,即固定负样本数量为25 张,调整正样本数量,使得训练样本的正负样本比例分别为20:1,10:1,5:1 进行3 组测试对比。将softmax 层阈值设定为0.5,迭代次数设为10 000 次,得到验证结果如表5 所示[21]。
可以看到,当正负样本比例为20:1 时,准确率高达99%,召回率仅为52%,但外观缺陷难以检出。在此基础上,固定负样本数量,减少正样本数量,在较小正负采样比条件下进行测试,可以看到召回率明显升高, 分别达到了68%和80%,但是准确率却下降至83%;尽管外观缺陷可以基本检出,但是存在正常样本被大量误检的问题。由以上验算结果可知,在负样本不足的情况下,模型泛化能力较低,不论如何调整正负样本的比例关系,准确率-召回率综合评价指标均无法提升(在0.34~0.41 的范围变化),难以满足实际工程应用的要求。本文进一步对多种模型的外观检测效果进行了比对,在正负样本比例5:1 的条件下,得到比对实验结果如表6 所示。

表5 基于真实样本的实验结果

表6 不同模型算法的真实样本比对实验结果
可以看到,相对于简单的BP 网络等,Le-net的正确率有明显的提升(可以达到83%);而相比于其他更加复杂的网络,几个主要的技术指标均相差不大,算法复杂度的提升并没有带来应用效果的显著提升,因此选择Le-net 作为目标检测的模型是合理的。
4.3 基于风格迁移模型的样本扩充与改进判别模型
为了进一步提升算法模型的性能,需要增加负样本,本文利用风格迁移进行图像样本集扩充,图9 所示即为负样本生成流程。
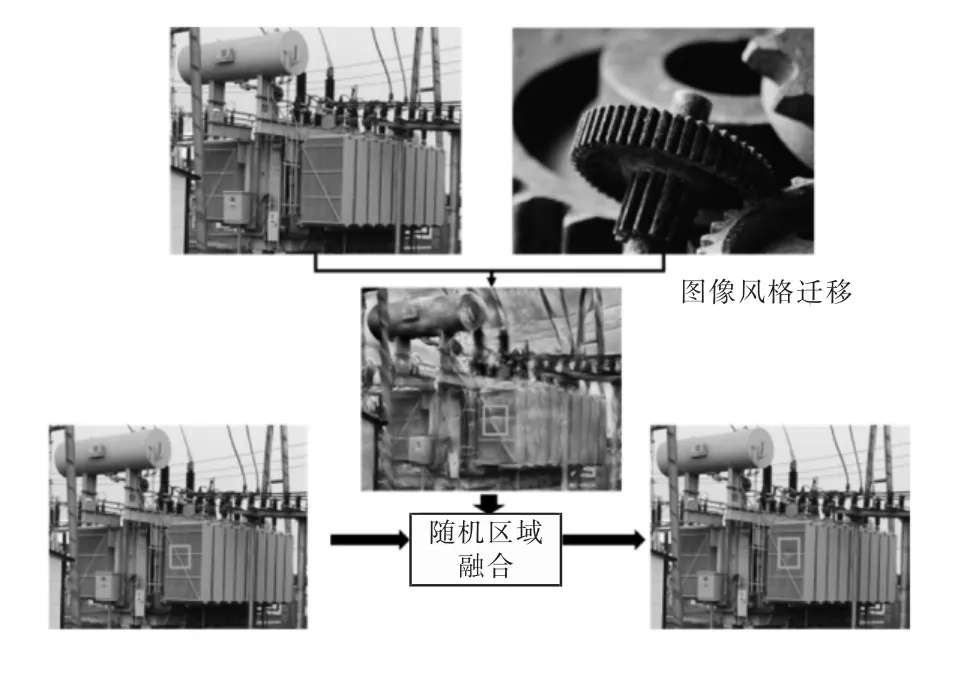
图9 负样本生成流程
按照上述方法,将负样本扩充150 张,使得总负样本数量达到200 张。此时,依然固定正样本数量为1 000 张,通过增加负样本数量以改变正负样本采样比,得到的比对实验结果如表7 所示。可以看到,随着负样本数量的增加,尽管准确率略有下降(由100%降至98%),但是召回率明显提升(达到了100%),在5:1 的正负样本训练比例下,测试中异常样本的检出率已经达到了100%,并且正常样本的误检率也提升到了可以接受的范围,算法性能满足工程应用的技术要求。
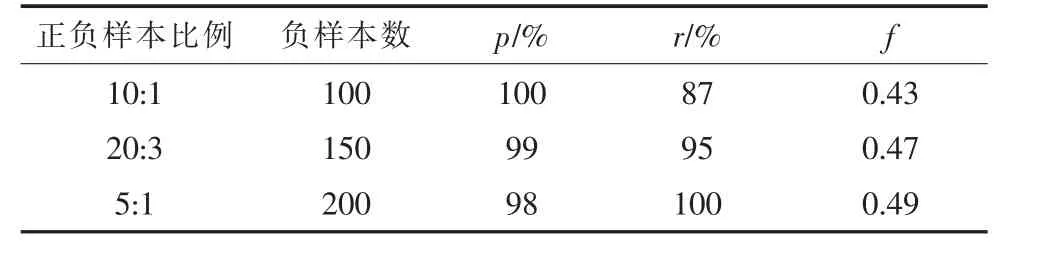
表7 基于扩充样本的实验结果
5 结语
本文针对巡检机器人采集的主变图像,提出了一种基于CNN 的主变外观缺陷机器视觉识别检测方法,能够实现采集图像“目标自动抓取、外观缺陷自动分析”的功能。该方法具有如下特点:
(1)使用的SSD 算法可以对主变设备进行准确定位,保证检测结果无遗漏。
(2)通过风格迁移与随机缺陷区域生成对样本进行扩充,得到了较为真实的负样本,丰富了样本集。
(3)在扩充后的样本集上训练的外观缺陷判别模型相较于扩充前的性能有了明显提升,缺陷检出率、正常误检率都有了明显的改善。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学苑创造·A版(2022年4期)2022-06-18
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年14期)2021-08-23
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年8期)2017-06-05
