
基于融合感知的场景数据提取技术研究
2019-05-17 02:45李英勃于波
现代计算机 2019年9期
李英勃,于波
(中国汽车技术研究中心数据中心,天津 300393)
0 引言
驾驶场景数据是描述车辆在行驶时所遇到的周围环境、道路、物体等静态因素以及行人、车辆、障碍物等动态交通目标的数据,是智能网联汽车自动驾驶技术研发的重要基础,是自动驾驶算法开发以及自动驾驶和辅助驾驶产品测试的核心资源。可以说,自动驾驶算法好不好,技术可靠不可靠,有很大一部分和训练时所用的场景数据的质量和数量相关。目前,包括中国汽车技术研究中心、中国汽车工程研究院、上海汽车城在内的很多企业和机构,都在积极推进中国驾驶场景数据采集工作。
驾驶场景数据采集主要通过数据采集平台,即场景数据采集车进行。如伊必汽车(Elektrobit)、恒润科技等企业纷纷推出了自己的场景采集平台。这种采集平台可以收集采集车本车CAN线信号,获取油门、方向盘转角,本车速度、方向、GPS信息,以及车载传感器信号,如激光雷达信号、毫米波雷达信号、单目摄像头图像、双目摄像头图像以及360o环视摄像头图像等信息。驾驶场景提取工作的目的,是将这些在道路上通过摄像头、激光雷达等传感器采集到的信号,还原成真实的道路场景的描述,供智能网联汽车开发企业测试其产品使用。换句话讲,场景数据抽取就是从这些数据中提取出本车的速度、方向以及控制信息,道路信息以及交通目标、障碍物的类别、大小、速度、方向、运动轨迹等信息,再转换为对于驾驶场景的描述,以Open-Scenario的格式进行存储。
以前这些信息的提取多采用人工方式提取,通过比对不同传感器返回的信号值,同时对比视频数据,手动标出目标,找出目标的速度,然后总结成场景数据,编写OpenScenario文件。这种方法工作量大,速度慢且准确率低,容易出现人为错误。
本文提出一种方法,通过机器视觉技术和深度学习技术,从视频图像出识别出行人、车辆等交通目标,并估计目标的距离和速度。然后比对从视频图像中提取出来的目标信息和其他传感器(如激光雷达和高精度地图)信息,得到动态和静态元素的位置,速度和运动轨迹等信息,在通过实现设定好的判断规则,将驾驶场景数据转化为一连串的驾驶场景描述,并最终自动转化成OpenScenario格式进行存储。本文提出的基于卡尔曼滤波的目标追踪,采用了对每一帧均进行识别,再通过追踪算法找到帧与帧之间不同目标的联系的办法,比起deep-sort等追踪算法,虽然在实时性上有损失,但是精确度有提高。由于场景提取并不是在采集驾驶场景时实时完成的,所以可以容忍以实时性上的损失换取提高追踪的精确度。
1 相关研究工作
在视觉感知方面,基于深度学习的图像技术取得了令人瞩目的成果。Karen Simonyan和Andrew Zisserman在2015年提出了VGG16模型[1],使对VOC数据集进行目标识别的精度达到98%。Ross Girshick基于VGG16模型提出了一种利用识别作为图像检测方法的技术R-CNN[2],在图像中提出候选框,然后对框中的物体进行识别,最后通过精修框的位置识别物体的方位。这个思路也成为后来R-CNN系检测算法的思想基础。后来,Ross Girshick等人又通过共享特征提取和RPN候选框提取网络,两次改进R-CNN算法,分别提出了 Fast R-CNN[3]和 Faster R-CNN[4]算法。Faster RCNN也成为性能最好的“提框-识别”两步图像检测算法。Faster R-CNN虽然检测准确性高,但检测速度还是较慢。为了进一步提升识别速度,Ross Girshick等人又提出了将提框和识别一步完成的方法,开发了YOLO 算法[5],同时,Wei Liu、Alexander C.Berg等人提出了SSD算法[6]。相比于Faster R-CNN模型,这两个算法大幅提升了图像检测的速度,但是同时也不可避免地牺牲了一部分识别精度。
对于目标位置的检测,基于图像的方法,成本较低的可以采取单目定位的方法[7]。双目摄像机可以利用人眼成像的原理,更精准地获取目标位置和距离。随着不同传感器之间相互匹配和融合技术[8]的不断发展,使用RGB-D技术或深度图像技术的目标感知定位技术逐渐普遍了起来。其中,利用图像融合激光雷达,组成RGB-D传感器对目标进行识别和定位的技术就是其中一种常用的技术[9]。本项研究就是采用的摄像头加激光雷达的融合感知平台。
卡尔曼滤波[10]是一种常用的对目标速度状态进行估计的算法,扩展卡尔曼滤波[11]是卡尔曼滤波的改进形式,能够对非线性系统状态进行预测。本项目采用扩展卡尔曼滤波作为目标追踪的主要依据和算法基础。
2 场景采集平台配置
场景平台采集车采用长城VV7SUV为运载车辆,感知系统由激光雷达和摄像头组成。其中激光雷达的型号为禾赛-40P,线数为40线,可以扫描周围约200米范围,安装在车顶部。视觉采集系统安装在车前挡风玻璃内侧,采用罗技,观察角度为前方60度。
场景采集的数据为高速道路数据,采集的图像如图1所示,采集的激光雷达用pcl点云库的pcd格式存储,存储格式为二进制格式,点云图像如图2所示。

图1

图2
3 场景数据提取
3. 1 驾驶场景数据构成
驾驶场景数据分为静态元素数据和动态元素数据。静态元素数据是指场景的道路、环境、路上及周边设施等静态物体的信息;动态元素数据是指交通参与者,包括行人、车辆的方向、速度等信息。以此来分,场景数据的提取也分为静态元素提取和动态元素提取两个部分。
我们首先对场景的静态信息进行分析。在本项目中,静态元素数据主要依靠高精度地图信息提供。通过使用高精度地图,可以极大地简化场景采集平台对感知系统的依赖,将采集平台对周围环境的感知转换成了一个定位问题,包括车道信息、车道线、交通灯、交通指示牌的内容和位置等信息,通过输入本车位置信息即可以知道周围所有静态元素的位置以及部分静态信号的内容。但动态的交通信号信息,如交通信号灯状态,或者变化的交通指示牌(如学校的警示牌等),依然需要依靠视觉系统获取。

图3 高精度地图
对于动态元素的分析则更依赖于平台的融合感知结果。在动态元素感知当中,我们要识别周围的行人,车辆以及其他交通参与者,并对这些元素进行跟踪,计算他们的运动方向和速度,以此预测元素未来的位置。其中,感知的部分,我们采用深度学习技术,对图像中的人、车,连同上文提到的交通信号灯信息进行识别;动态元素的位置则通过配合图像和激光雷达获得。
3. 2 深度学习提取图像信息
无论是静态元素中的交通信号灯还是动态元素中的行人,车辆,都主要依靠视觉进行。项目中我们使用了深度学习技术从图像中提取场景元素。由第2节的研究可以知道,SSD和YOLO虽然速度快,但损失精度。我们采用了Faster R-CNN网络,利用RPN提取潜在目标框,通过精修,对目标框的位置的大小进行调整,以获得较高目标位置精度,为下一步图像与点云匹配创造良好的条件。
3. 3 坐标系转换实现激光点云信息与图像信息匹配
(1)激光雷达信息和图像信息匹配
图像信息和激光雷达信息匹配,主要通过时间匹配和空间匹配来完成。在时间维度上,场景采集车采用的激光雷达的频率为10赫兹,约为每秒10帧点云图片,图像信息为30帧/秒。因为是原始数据融合,所以没有识别物体,不能使用插值等方法估计精确时刻目标物体在图像或点云数据中的位置。为了保障激光点云与图像能够匹配上,我们采用以快配慢的方法,以激光雷达点云图像的时间点为基准,寻找时间上最接近的图像匹配雷达点云数据。即:
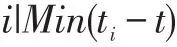
其中t为雷达点云图像时刻,i为图像帧数,ti为第i帧图像的时间。
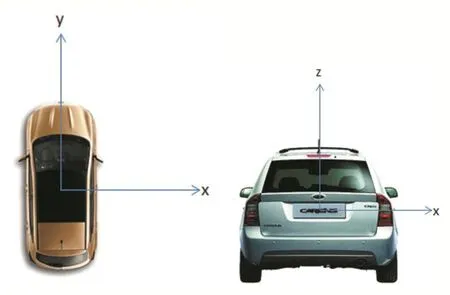
图4 车辆坐标系
在空间匹配技术方面,本项目以车辆坐标系为图像信息和点云信息匹配的坐标系。以车辆行进方向为x轴正方向,车辆右侧方向为y轴正方向,以车辆上方方向为z轴正方向。(如图4所示)项目通过匹配图像和激光点云信息,将目标物体的位置以这个坐标系的坐标进行输出。
空间匹配技术的关键在于将激光雷达中点的坐标与图像投射到同一个坐标系的二维空间当中。我们将摄像头的成像平面作为这个投射的二维空间,以图像左上角坐标为原点,横轴向右为x轴方向,纵向向下为y轴方向。然后建立一个3D坐标点转换为2D点的坐标转换矩阵,将空间中的点投影在成像平面上。投影的原理如图5所示,其中f为焦距。
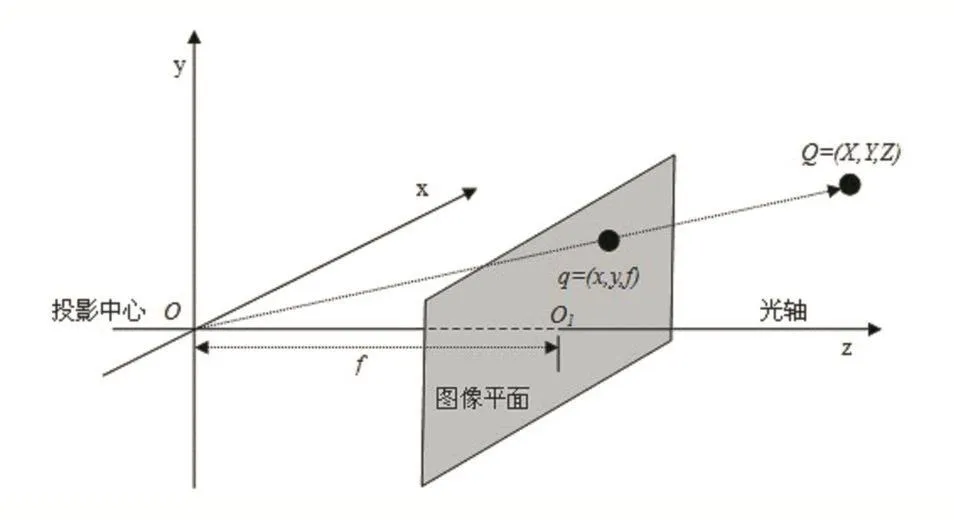
图5 相机投影
相机焦距 f、像素长度(dx,dy)是相机的内参。为了获取相机的内参数据,我们首先对相机进行了标定。标定采用了棋盘标定法,使用OpenCV函数Calibratecamera()函数进行标定,得到相机内参。

表1 摄像头内参标定
根据相机投影原理,通过几何算术推导,我们可以得出:

其中,(X,Y,Z)为点在空间中的坐标,(u,v)为在图像中的成像坐标。这样,我们就可以将空间中任意一点投影到成像平面上。现在,我们可以尝试把雷达点云数据通过矩阵计算投影到图像上。投影效果如图6所示。

图6 点云与图像匹配
如果我们用激光雷达的距离信息近似表示它周围所有像素点的实际坐标系中的距离信息,我们就将激光雷达和摄像头组成了一个RGBD深度摄像头。通过对图像中物体的位置进行判断,就可以通过物体像素点所对应的激光雷达点在实际坐标系中的坐标获得物体的实际位置。
(2)图像识别
我们使用神经网络模型对图像进行识别,使用的网络为Faster R-CNN,通过模型返回目标框的四个角点的图像坐标,以及识别到的物体种类。效果如图7所示。

图7 图像检测效果
图7中目标框基本框出了物体的位置,但并非框中所有的点均是物体。我们必须选择框中的部分像素为基准,取它的坐标为物体的位置。一般来说,目标物的图像能够覆盖框中心点,所以我们选择框中心点的坐标位置为感知目标的坐标。
我们对所有目标框中的物体进行了识别,并用此方法获得了所有目标的坐标方位,如图8所示。

图8 融合感知效果
3. 4 基于图像和点云信息的目标追踪
为了追踪目标的运动轨迹,我们使用扩展卡尔曼滤波算法过滤探测误差并对物体的运动轨迹进行跟踪。假设xt={pt,vt}为物体在t时刻的系统状态。那么物体在t时刻的位置与它在t-1时刻的位置,t时刻的系统对他的改变相关。那么t时刻对物体状态的估计应该为:

由于是对实际运动轨迹的估计,我们需要对状态转移矩阵At加入噪声模型:

由于x’是估计的目标位置,并不是目标真正的位置,而是我们用来估计真正目标位置x的工具。我们用x^t表示t时刻时观测到的目标位置,我们用矩阵H表示真正位置到观测位置的转换矩阵,则真实的观测值用估计值和真实观测值的加权值进行表示:

其中卡尔曼系数K由滤波增益阵算出:

其中:

我们将观察到的目标坐标和速度代入卡尔曼滤波系统,对目标位置进行预测和修正,卡尔曼滤波可以修正小的系统误差,使目标运动轨迹更加平滑。
4 场景采集效果对比与结论
我们在试验场采集了场景,对障碍物进行了精确的标定,并对车辆的行进路线进行了详细的规划和记录。由此,我们可以计算出障碍物对于车辆的相对位置信息。同时,我们还用CalmCar的基于视觉的驾驶场景采集系统同时进行了测量。
图9(1)是探测到的目标移动轨迹,图9(2)是单目视觉感知系统CalmCar获得的结果,图9(3)是探测到的目标轨迹加入卡尔曼滤波后的目标移动轨迹,可以观察到的融合感知加入卡尔曼滤波后的目标运动轨迹更平滑,更贴近目标真实的运动轨迹。通过比较,从结果总体看,融合感知提出驾驶场景的精度要高于仅依靠视觉感知的CalmCar的结果。
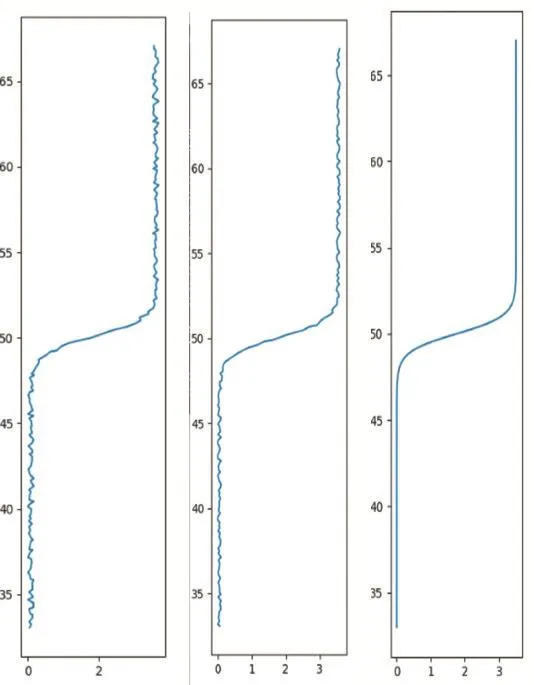
图9 从左到右为探测到的路径、CalmCar探测到路径、融合感知路径
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年4期)2022-04-24
制导与引信(2021年2期)2021-09-08
汽车观察(2021年8期)2021-09-01
北京航空航天大学学报(2021年7期)2021-08-13
科技研究·理论版(2021年20期)2021-04-20
计算机与网络(2020年19期)2020-12-04
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
少儿科学周刊·儿童版(2015年2期)2015-07-07
