
基于卷积神经网络的恶意软件检测与分类研究
2019-05-17 02:45齐彩云胡勇
现代计算机 2019年9期
齐彩云,胡勇
(四川大学电子信息学院,成都 610065)
0 引言
目前,恶意软件是信息安全领域的一个重要挑战。根据McAfee[1]的数据,在2018年第一季度,检测到超过7亿个恶意程序。2018年4月10日,Spring官方宣布Spring Data Commons存在远程代码执行漏洞(CVE-2018-1273),攻击者可构造包含有恶意代码的SPEL表达式实现远程代码攻击,直接获取服务器控制权限。GandCrab勒索病毒于2018年1月面世以来,短短一年内历经多次版本更新。从今年9月份V5版本面世以来,出现了多个版本变种,并将感染主机桌面背景替换为勒索信息图片。2018年5月,Talos团队发现一款名为VPNFilter的恶意软件。该恶意软件具有多种功能,可支持情报收集和破坏性网络攻击操作,可感染71款甚至更多物联网设备。
虽然越来越多的恶意软件出现,但是大多数新的恶意程序是已知的恶意样本变种的,这些恶意软件可以分为不同的类型,因而每个相同类型的恶意软件都具有高度相似的行为特征。因此,属于同一类型的恶意样本之间的这些共同的特征可以用于对未知程序的检测和分类。Nataraj等人将恶意代码二进制文件映射为图像,利用Gabor滤波器多尺度和多方向的特点提取图像的全局特征,然后使用最近临近算法对恶意代码那进行分类。Kancherla等人将恶意代码图像的强度特征和小波特征与Gabor滤波器提取的全局特征结合,然后使用这三种特征对恶意代码进行分类。Hanks等人将恶意代码图像的熵值映射到曲线上,然后计算曲线的相似度对恶意代码分类。Farrokhmanesh等人将恶意代码映射为灰度图,使用三种哈希算法提取恶意代码的指纹,然后计算图像指纹之间的距离对恶意代码分类。由于存在恶意代码二进制文件重新分配问题,所以上述恶意代码分类方法分类效果并不理想。
1 卷积神经网络研究现状
卷积神经网络是一种基于“输入-输出”直接端到端的学习方法,直接利用图像像素信息作为输入,最大程度保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是识别的结果。模型中的参数可以通过反向传播和梯度下降方法进行训练。卷积神经网络经过训练后可以自动学习原始数据的特征,并且可以提取学习到的特征并分类。卷积神经网络的下采样层和卷积层之间不是全连接的方式,层与层之间也是非线性映射的,通过局部感知野、权值共享、池化三个方面可以减少需要训练的参数。近几年,卷积神经网络在图像识别、自然语言处理、语音识别等方面应用广泛,并表现出了很大的发展潜力。在2012年,Image图像分类挑战赛[10]上就用到了卷积神经网络,其分类效果远远超过其他方法。因此,由于卷积神经网络有良好的图像分类性能,现在已经应用到了网络流量的检测与分类研究中[7-8]。文献[11]提出了一种基于离差标准化的卷积神经网络(MMN-CNN,Min-Max Normalization Convolutional Neural Network)对流量进行分类,设计了6种不同网络结构的卷积神经网络,将所设计的6种不同卷积层结构的卷积神经网络分别采用平均池化和最大池化进行性能对比,最终选择输入层为16×16,卷积层为3×3以及采用最大池化方法的模型,最终准确率高达99.3%。文献[12]提出了一种基于卷积神经网络的流量识别技术研究,将输入层设置为24×24,并根据TCP数据包的有序性和UDP数据包的无序性,对原始的网络数据进行了扩展,进一步提高了识别率.文献[13]提出了一种基于深度学习的恶意URL识别,通过正常URL样本训练得到URL中的字符的分布表示,将URL转化成二维图像,然后通过训练CNN模型对二维图像进行特征抽取,最后使用全连接层进行分类,并取得了精度为0.973和F1为0.918的结果。
根据以上研究成果,本文提出了一种基于卷积神经网络的恶意软件检测与分类方法[2-3],即使恶意代码二进制文件重新分配,在预处理阶段也可以将这些二进制数据形成和原恶意代码相似的图像,所以该方法可以更准确的将恶意代码分类,并且提高分类精度。实验表明,所提出的CNN模型的性能更高,其准确率为99.96%,这表明了其作为准确分类模型的可行性。
2 基于卷积神经网络的恶意软件检测方法
2. 1 恶意软件数据集
在2015年由微软主办的基于机器学习的数据分析竞赛Kaggle机器学习挑战赛上,将恶意软件数据集进行了分类,本文将其恶意软件数据集作为提出的基于卷积神经网络的恶意软件检测及分类系统的学习和验证数据[4]。表1显示了总共10868个恶意软件,包括9种不同类型,大约200GB。

表1 恶意软件数据集
2. 2 模型结构
在使用传统的基于机器学习的分类器检测恶意软件的研究中,可以发现传统机器学习的特点是需要根据人工选择的恶意软件特征来从已有的数据中拟合模型,从而用于分类。因此,本文提出了一种基于深度CNN的恶意软件检测系统,自动选择图像的最优特征。CNN通过对图像进行卷积和池化运算来提取图像的最优特征。它的运算由式(1)定义:
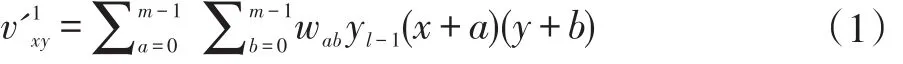
向量v'1的元素为式(1)中第一个卷积层的输出,并对前一层的输出向量yl-1进行卷积,filter为m×m的向量W。Max-pooling计算在池化层中进行,从输入N×N矢量的K×K区域选择一个最大值代表这一部分的特征,输出为矢量。
图1显示了基于卷积神经网络的恶意软件检测系统的总体结构。首先对恶意软件映像的二进制文件重复执行3×3卷积和2×2池化计算。最后,使用完全连接层。在图像分类中主要采用了卷积和池化的运算,并取得了较好的分类效果。在此系统中,输入恶意软件的图像就可以输出恶意软件的类型。
3 实验评估
3. 1 实验环境
本文实验环境及其配置如下:
●CPU:Intel i7-7700K
●内存:16GB RAM
●GPU:NVIDIA GTX 1080Ti
●编程语言:Python 3.5
●深度学习框架:TensorFlow 1.4.0

图1 恶意软件检测系统
为了评估使用方法的性能,本文使用了K-折交叉验证。将数据集分成K个大小相等的子样本。在K个子样本中,保留一个子样本作为模型测试的验证数据,其余子样本作为训练数据。这个过程重复的次数与折叠次数相同,每个子样本都只作为验证数据使用一次。此外,为了选择最佳模型,还使用了其他评价指标:精确度、召回率和F1得分。这是因为精度可能是一种误导性衡量标准。当存在较大的类别不平衡时,可能需要选择具有较低精度但对问题具有较大预测能力的模型(也就是说精度悖论)。其中模型可以预测多数类别的值,并且在少数或关键类别出现错误的同时实现高分类准确度。精度(P)是真阳性率(Tp)除以真阳性率(Tp)与假阳性率(Fp)之和所得商。
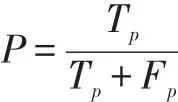
召回率(R)是真阳性率(Tp)除以真阳性率(Tp)与假阴性率(Fn)之和所得商。
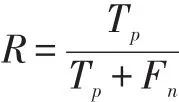
F1的分数是精度的加权平均值,定义如下:
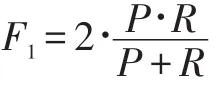
由于本文的目标任务是一个多类别分类问题,所以使用的是F1分数的一个改编版本,称为宏平均F1分数,它定义为每个类的单独F1分数的平均值。
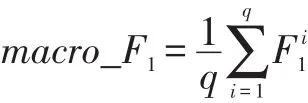
其中q是数据集中的类数,F1i是第i类的F1分数。因此,大类不会在小类上占主导地位。
3. 2 实验结果
为了保证输入到卷积神经网络的数据大小一致,所以本文将图像降采样到固定大小,将所需图像的高度和宽度设置为128×128。如果将图像的高度和宽度设为较低的值将不能保留所有重要的信息,而设置为较高的值在不提高总体精度的情况下会增加计算时间。例如,将图像降采样到16×16像素,则来自KELIHOS v.1类型和VUNDO类型的样本将会彼此无法区分,如果将图像降采样到64×64像素,则该模型正确分类VUNDO类型的样本的百分比是50.45%,如果将图像降采样为128×128像素,则该模型正确分类VUNDO的百分比将达到97.1%。此外,本文进行了5折和10折交叉验证来评估此恶意软件检测模型。表2和表3显示了对于5次交叉验证和10次交叉验证获得的检测结果。
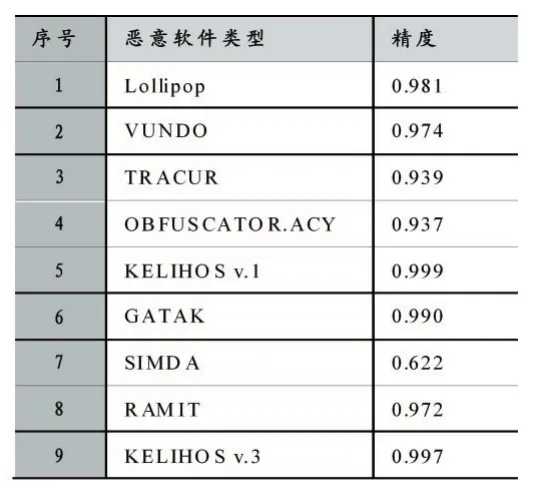
表22015 年的数据集使用128×128像素的图像进行5折验证
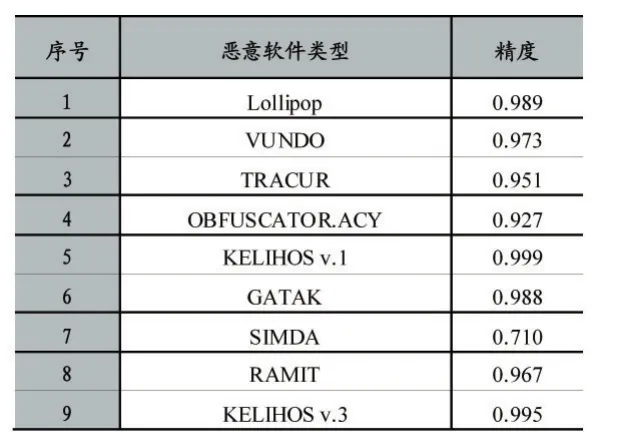
表3 2015年的数据集使用128×128像素的图像进行10折验证
表4显示了其他文献中的方法获得的结果,这些方法都是从数据集中提取基于图像的特征以对恶意软件进行分类。纳拉亚南等人[5]使用PCA提取前10、12和52个主成分,使用不同的机器学习分类算法对恶意软件进行分类。此外,Ahmadi等人[6]从图像中提取Haralick特征和LBP特征,并训练了集成树用于分类。他们的方法分别使用5倍和10倍交叉验证进行评估。由评估结果可以看出,本文的方法优于其他方法。
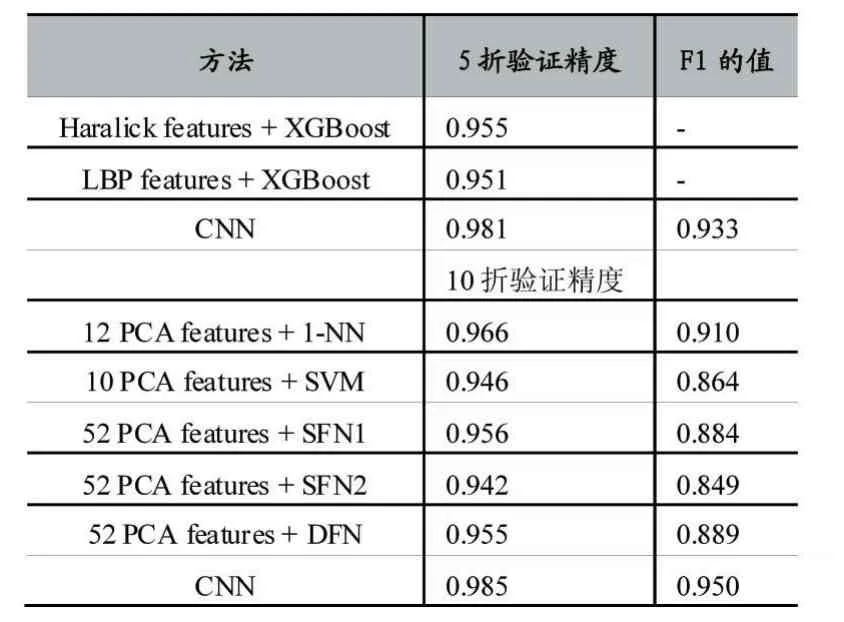
表4 2015年的数据集分类方法的性能比较
4 结语
本文提出了一种基于灰度图像可视化的恶意软件分类的深度学习系统,这是一种应用深度学习将恶意软件的二进制内容转换为图像的模式。该解决方案具有许多优点,允许在实时环境中检测恶意程序。首先,该系统与执行的文件无关,而是完全基于可执行文件的二进制代码。其次,将可执行文件转换为灰度图像的成本较低。第三,预测时间比其他方法要更短。第四,与以往基于恶意软件灰度图像表示的方法相比,该方法具有更高的分类准确率。
尽管本文提出的方法在准确性和分类时间方面能够优于其他的方法,但它存在一些与恶意软件作为灰度图像的可视化相关的问题。虽然可以看到属于同一类型的恶意软件的可视化具有相似的模式,但是由于某些压缩或加密的样本可能具有完全不同的结构,所以这种方法所达到的效果不佳。针对这种情况,笔者认为可以将卷积神经网络提取的特征与手动提取的特征相结合作为基于不同类型文件特征的机器学习模型的输入[9]。
猜你喜欢
计算机应用(2022年9期)2022-09-25
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
软件导刊(2022年3期)2022-03-25
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
智能计算机与应用(2018年2期)2018-05-23
