
基于密度峰值和社区归属度的重叠社区发现算法
2019-05-10 02:15彭胜波张瑛瑛陈羽中
小型微型计算机系统 2019年5期
郭 昆,彭胜波,张瑛瑛,陈羽中
1(福州大学 数学与计算机科学学院,福州 350116)2(福建省网络计算与智能信息处理重点实验室,福州 350116)3(空间数据挖掘与信息共享教育部重点实验室,福州 350116)4(国网信通亿力科技有限责任公司,福州 350003)
1 引 言
在现实世界中存在大量复杂网络,如社交网络、生物网络、文献引用网络.研究表明,这些复杂网络普遍存在着一定的社区结构,各社区内部节点连接较为紧密,社区间连接较为稀疏[1].社区发现研究的就是如何准确的识别出复杂网络中的社区结构.
传统的社区发现算法是将网络划分成若干个互不相连的社区,网络中每个节点和边只能隶属一个固定社区.包括模块度优化方法[2-4],层次聚类算法[1,5],标签传播算法[6,7]和信息论算法[8-10].然而,真实网络中,社区之间通常是互相交叉,彼此联系的,这种情形下,网络中的节点不再仅隶属于单个社区,而是同时被包含到多个相关联的社区中.因而,研究重叠社区结构具有更重要意义.
目前,重叠社区发现算法主要包括基于派系过滤的算法、基于局部社区的算法、基于多标签传播的算法和基于链接聚类的算法等.最近,Wang等人[11]提出了一种基于密度峰值聚类的社区发现算法LCCD,该算法利用密度峰值选取网络的局部结构中心,然后扩展局部结构中心来发现社区,具有较高的社区精度,且能识别网络的核心点和孤立点.但是,LCCD算法还存在时间复杂度较高和不能较好的应用于重叠社区发现等不足.针对这些问题,提出一种基于密度峰值和社区归属度的重叠社区发现算法OCDPCB(Overlapping Community Detection based on Density Peaks and Community Belongingness),利用密度峰值聚类来生成非重叠社区,基于社区归属度生成重叠社区.主要贡献如下:
1)提出一种基于节点直接邻居和间接邻居的距离度量方法,具有近似线性的时间复杂度;
2)设计一种聚类中心点的局部密度阈值和跟随距离阈值计算方法,根据这两个阈值自动选取聚类中心点,可以解决密度峰值聚类算法中聚类中心需要人为选定问题;
3)提出社区归属度计算方法,并对采用密度峰值聚类算法生成的社区边界节点进行社区归属计算,根据社区归属度把社区边界点划分到对应社区中,可以较好的识别出网络的重叠社区.
2 相关工作
目前,重叠社区发现可以分为基于派系过滤的算法、基于局部社区的算法、基于标签传播的算法和基于链接聚类的算法等.Palla等人[12]提出的基于派系过滤的CPM算法,其核心思想是基k极大团发现重叠社区.类似的算法还包括文献[13,14],该类算法能较准确的识别出网络中的重叠社区结构,但是具有较高的时间开销,且不适用于稀疏网络.基于局部种子社区优化和扩展的重叠社区发现算法首先寻找网络的初始种子社区,之后通过贪心策略并结合局部适应度函数对已有种子社区进行扩展发现重叠社区,节点加入顺序会对社区发现结果稳定性造成影响.代表算法有LFM[15]算法、DEMON[16]算法、OCDW[17]算法、i-SEOCD[18]算法.基于标签传播的重叠社区发现算法[19-21],该类算法为每个节点保留多个标签,每个标签对应一个社区.Evans等人[22]提出了一种基于线图和链接切分的算法LGLPOC,该算法对网络的边进行划分,将边集映射成节点集,能够自然地识别出重叠社区.Ahn等人[23]提出边社区发现算法LC,采用Jaccard相似度衡量边相似度,以自底向上的方式对边进行合并,直到目标函数达到最大值,最后将边社区转化节点社区.朱牧等人[24]提出了一种基于链接密度的社区发现算法DBLINK,通过密度聚类的方式检测出噪声边,在聚类的过程中忽略噪声边,避免社区结构的过度重叠.然而,该算法未对社区边界边和噪声边进行合理处理,会造成社区边界模糊和出现丢失部分节点和边的情况.Zhou等人[25]提出了一种基于密度的链接聚类的算法DBLC,该方提出了一种相似度策略来处理边界边和噪声边,解决了社区边界模糊问题,但未考虑噪声边可能形成独立的小社区,降低了社区发现精度.另外,该算法的时空复杂度较高.
Rodriguez等人[26]于2014年提出了密度峰值聚类方(Density Peaks Clustering,简称为DPC),该方法只依赖于节点之间的距离,根据节点分布的局部密度选择聚类中心,能够获得稳定的聚类结果.近年来,密度峰值聚类被很好的应用到社区发现中.李玉[27]提出了CSDPC算法,该算法首先结合余弦相似度和节点间的最短路径,把网络的连边关系映射成节点间的距离,之后再通过密度峰值聚类算法进行社区发现,能够发现有效的社区结构.隋鹏[28]提出了IA-UDR算法,该算法通过模拟真实网络中用户的多种亲密关系来表示节点之间的距离,并改进了密度峰值聚类算法的中心选取策略,IA-UDR算法可以得到较好的社区划分,且具有较好的泛化性.上述基于密度峰值聚类的社区发现算法虽然具有良好的稳定性,且具有较高社区发现精度,但是没有解决密度峰值算法存在的时间复杂度较高、聚类中心需要人为选定以及不能很好的应用到重叠社区发现的问题.
3 OCDPCB算法
3.1 基本概念
设G=(V,E),其中V={Σvi|i=1,2,…,n}表示网络中的节点集合,E={Σei|i=1,2,…,n}表示网络中的边集.下面主要介绍社区发现的基本概念和定义.
定义1.社区集合.设C={Ci},其中Ci表示在网络G上生成的第i个社区,C表示生成的所有社区集合.
定义2.节点直接邻居.∀v∈V,DNB+(v)表示包括节点自身的邻居节点集合,DNB(v)表示不包括节点自身的邻居节点集合.
定义3.节点间接邻居.节点的间接邻居是指节点邻居的邻居,节点v的间接邻居INB(v)定义为:
INB(v)=t|t∈DNB(u)∧u∈DNB(v)
(1)
定义4.余弦相似度.两节点u,v的余弦相似度σ(u,v)定义为:
(2)
其中,|DNB(u+)|表示节点u的直接邻居节点个数.
定义5.社区边界点[11].社区Ci的边界点BCi定义为:
BCi={v|d(v,w)≤dc∧v∈Ci∧w∉Ci}
(3)
3.2 密度峰值聚类
DPC算法可以较好的用于网络聚类.该算法基于以下两个假设:1)簇中心的局部密度相对较大;2)簇中心与更高局部密度的节点的距离相对较远.下面对DPC算法聚类过程做个简单介绍.
1)局部密度计算,节点的局部密度定义如下:
(4)

(5)
其中ρi是节点i的局部密度,dij是节点i和节点j间的距离,dc是距离阈值,可以选择dc使得节点的平均邻居数大约是数据集中节点总数的1%~2%.
2)跟随距离计算,节点的跟随距离定义如下:
(6)
其中,δi是节点i到其他具有更高局部密度节点的最小距离,也即节点i的跟随距离.
3)节点分派到簇,在得到节点的ρi和δi后,可根据ρi和δi画出一个决策图,图中具有高δ值和相对较高ρ值的节点会被选为簇中心.在簇中心确定之后,余下的非簇中心节点将会按照局部密度从高至低分派到密度比当前节点大且距离当前节点最近的节点所在的簇中.
DPC算法能够保证节点分配过程的可靠性,且算法对距离阈值dc和对大数据集具有较好的鲁棒性.但由于DPC算法在计算节点间距离时需要计算任意两点间的距离,所以改算法的时空复杂度较高;另外,簇中心的选取需要根据决策图人为指定,在结构复杂的网络中,这种方式无法较为准确的选取簇中心.最后,节点的跟随策略决定了DPC算法不能进行模糊聚类.
3.3 算法设计思想
OCDPCB算法由以下几个步骤组成:
1)节点间距离计算:由于复杂网络的拓扑中只包含节点及其连边关系,只有把这些连边关系映射成节点之间距离才能采用密度峰值聚类算法进行节点聚类,考虑到真实网络中节点与直接邻居、间接邻居的关系较为密切,而与其他节点较为疏远,同时为了降低算法的时间复杂度,在计算节点间距离时,只计算节点与直接邻居、间接邻居间的距离.距离可以通过节点间的路径长度和路径数目来度量,路径越短,两点间距离越近;相同长度的路径数目越多,两点间距离越近,节点间的距离采用公式(7)计算.
(7)
其中,d(u,v)表示节点u,v间的距离.当u∈DNB(v)时,节点u,v间距离由长度为1的路径所表示的距离和长度为2的路径所表示的距离相加计算得到.而当u∉DNB(v)时,节点u,v间距离只需考虑由长度为2的路径所表示的距离.
2)局部密度计算:在获取到节点间距离后,继续根据距离计算节点的局部密度.为了增加节点局部密度取值的多样性以及减小算法在小数据集上受到大的统计误差的影响,这里可以通过引入高斯核函数对DPC算法中求取节点的局部密度方法做出改进,改进后的局部密度计算方法如公式(8)所示.
(8)
其中,rho(u)表示节点u的局部密度.
3)跟随距离计算:经过步骤2)得到节点的局部密度后,接下来便可以根据公式(6)求取节点的跟随距离,并根据跟随距离选取跟随节点.跟随节点定义如下:
定义6.跟随节点.节点u的跟随节点fol(u)定义为:

(9)
其中,del(u)表示根据公式(6)计算得到的节点u的跟随距离.
4)非重叠社区生成:首先,计算网络节点局部密度和跟随距离的平均值;其次,根据定义(7)求取社区中心点集合.最后,根据DPC算法生成社区.为了解决DPC算法不能较好的应用到重叠社区发现中,在生成社区的过程中,需要记录社区边界点,后续步骤可以对社区边界点进行社区归属判断来生成重叠社区.社区中心点定义如下:
定义7.社区中心点.社区集合C的中心点CC定义为:
(10)
其中,ui∈V,avg(del(ui))表示网络中节点的平均跟随距离,avg(rho(ui))表示网络中节点的平均局部密度,λ、γ为调节参数.γ·avg(rho(ui))社区中心点的局部密度阈值,λ·avg(del(ui))为社区中心点的跟随距离阈值,∀v∈V,只要del(v)和rho(v)分别不小于跟随距离阈值和局部密度阈值,即可被自动选为社区中心点.
5)重叠社区生成:在初步生成非重叠社区后,接下来需要对社区边界点进行社区归属判断来把它们划分到合适的社区中.首先,计算社区边界点对各社区的归属度大小.其次,计算社区边界节点的社区归属度阈值.最后,比较社区归属度和社区归属度阈值,把边界点划分到满足条件的重叠社区集合中.社区归属度和归属度阈值分别采用公式(11)、公式(12)计算,重叠社区集合如定义7所示.
(11)
其中,affi(v)表示节点v对社区Ci的社区归属度,σ(u,v)表示节点v和节点u之间的余弦相似度,d(u)表示节点u的度.
(12)
其中,affth(v)表示节点v的社区归属度阈值,CI={i|v∈Ci},表示与节点v有边连接的社区,|CI|表示集合CI中元数数目,β为调节参数,用来度量边界点的社区归属度均匀分布情况,由定义可知β≥1.
定义8.重叠社区集合.节点v所在的重叠社区集合Soc(v)定义为:
Soc(v)={Ci|affi(v)>affth(v),∀i∈[1,|C|]∧v∈Ci}
(13)
3.4 算法实现
根据上述设计思想,给出算法的总体实现步骤如下.
算法1.OCDPCB算法
输入:复杂网络G=(V,E)
输出:重叠社区C
1. (Pd,dmax,dmin)=calDist(V); /*节点间距离计算*/
2. (Rho,dc)= calRho(V,Pd,dmax,dmin);/*局部密度计算*//*跟随距离计算*/
3. (Nnb,Del,Rl)= calDelta(Rho,Pd,dmax);
/*非重叠社区生成*/
4. (C,BC)= genNonOveCom((Rho,Rl,Del,Nnb,dc));
5.C=genOveCom(C,BC); /*重叠社区生成*/
6.outputC;
3.5 节点间距离计算
计算节点间的距离时只考虑节点与直接邻居、间接邻居间的距离,距离计算的步骤如函数1所示.
函数1.calDist(V)
输入:网络节点集V
输出:节点间距离字典Pd,距离最大值dmax, 距离最小值dmin
1.Pd=empty map;
2. FOR eachv∈V
3. FOR eachu∈DNB(v)
/*向Pd中添加元素<(v,u),d(v,u)>,(v,u)为
Pd的键,d(v,u)为Pd的值*/
4.Pd.put(<(v,u),d(v,u)>);
5. FOR eachr∈DNB(u)
6. IFd(v,r)∉PdTHEN
7.Pd.put(<(v,r),d(v,r)>);
8. END IF
9. END FOR
10. END FOR
11. END FOR
12.dmax=max{dis|dis=Pd.get((u,v)),u∈V∧v∈V};
13.dmin=min{dis|dis=Pd.get((u,v)),u∈V∧v∈V};
14. outputPd,dmax,dmin;
函数1主要步骤如下:
1)初始化节点间距离字典Pd为空;
2)利用公式(7)计算节点与直接邻居节点间的距离,并把该距离添加到距离字典Pd中(第3~4行);
3)利用公式(7)计算节点与间接邻居节点间的距离,并把该距离添加到距离字典Pd中(第5~9行);
4)求出节点间距离最大值dmax和最小值dmin(第12-13行);
5)输出距离字典Pd,dmax,dmin(第14行).
3.6 局部密度计算
根据函数1计算得到节点间距离后,继续根据该距离计算节点的局部密度,节点局部密度计算的步骤如函数2所示.
函数2.calRho(V,Pd,dmax,dmin)
输入:网络节点集V,节点间距离字典Pd,距离最大值dmax,距离最小值dmin
输出:节点局部密度字典Rho,距离阈值dc
1.Rho=empty map,np=0,nb=0;
/*根据DPC算法的dc选取规则,np应该在[0.01,0.02]内取值*/
2. WHILE(np<0.01‖np>0.02) DO
3. FOR eachdis∈Pd
4. IF(dis.value<=dc) THEN /*dis.value表示字典
元素的值*/
5.nb+=2;
6. END IF
7. END FOR
8.np=nb/|V|2;
9. IF(np>=0.02) THEN
10.dmax=dc;
11.dc=0.5×(dmax+dmin);
12. ElSE IF(np<0.01) THEN
13.dmin=dc;
14.dc=0.5×(dmax+dmin);
15. END IF
16. END WHILE
17. FOR eachu∈V
18.Rho.put(
19. END FOR
20. outputRho,dc;
函数2主要步骤如下:
1)初始化节点的局部密度字典Rho为空,网络所有节点的dc-邻域内节点数nb及nb与网络节点总数的比例np为0(第1行);
2)根据DPC算法中距离阈值的选取规则计算阈值dc(第2~16行);
3)根据dc和公式(8)计算网络中每个节点的局部密度(第17~19行);
4)输出局部密度字典Pd,距离阈值dc(第20行).
3.7 跟随距离计算
函数3.calDelta(Rho,Pd,dmax)
输入:节点局部密度字典Rho,节点间距离字典Pd,距离最大值dmax
输出:节点跟随邻居字典Nnb,节点跟随距离字典Del,排序后的局部密度列表Rl
1.Rl=empty list,Nnb=empty map,Del=empty map,NB=Ф;
2. add each element inRhotoRl;
3. sort(Rl); /*对Rl按局部密度大小降序排序*/
4. FOR(0≤i≤|Rl|)
5. IF(i=0) THEN
6.Nnb.put(
对应的节点*/
7.Del.put(
8. ELSE
9.NB=DNB(cp)∪INB(cp);
/*根据公式(6)和定义6求取节点cp的跟随距离del(cp)和跟随邻居fol(cp)*/
10.Nnb.put(
11.Del.put(
12. END IF
13. ENF FOR
14. outputNnb,Del,Rl;
函数3主要步骤如下:
1)初始化局部密度列表Rl、节点跟随邻居字典Nnb,跟随距离字典Del和邻居节点集合NB为空(第1行);
2)把Rho中的元素逐个添加到Rl中,并对Rl按局部密度值大小降序排序(第2~3行);
3)根据公式(6)和定义(6)求取节点的跟随邻居和跟随距离(第4~13行);
4)输出节点跟随邻居字典Nnb,跟随距离字典Del和排序后的局部密度列表Rl(第14行).
3.8 非重叠社区生成
函数4.genNonOveCom(Rho,Rl,Del,Nnb,dc)
输入:节点局部密度字典Rho,局部密度列表Rl,节点跟随距离Del,节点跟随邻居字典Nnb,距离阈值dc
输出:非重叠社区C,社区边界点BC
1.C= empty map,Cn=empty map,BC=Ф;
2. FOR eachv∈CC/*CC为根据定义(7)计算的社区中心*/
3.Cn.put(
4. END FOR
5. FOR eachu∈Rl
6. IF(uk∉CC) THEN /*uk为Rl中元素u对应的节点*/
7.nnb=Nnb.get(uk);
8.cI=Cn.get(nnb);
9. IF(cI∈Cn.values()) THEN
10.BC=BC∪uk,ifuk∈BCi; /*i表示社区标号*/
11.Cn(uk)=cI;
12. ELSE
13.Cn(uk)=uk;
14. END IF
15. END IF
16. END FOR
17. FOR(eachu∈Cn.keys())
18.cI=Cn.get(u);
19.C.put(
20. END FOR
21. outputC,BC;
函数4主要步骤如下:
1)初始化非重叠社区字典C、节点及其所在社区标号字典Cn和社区边界点集合BC为空(第1行);
2)给社区中心点分配社区标号(第2~4行);
3)根据DPC算法中节点分派规则给社区非中心点分配社区,并根据定义(5)计算社区边界点(第5~16行);
4)把网络中非社区中心点又没有找到跟随节点的其他节点中密度最大的作为社区中心(第13行);
5)把节点及其所在社区标号字典Cn转换成社区C(第17~20行);
6)输出非重叠社区C,社区边界点BC(第21行).
3.9 重叠社区生成
函数5.genOveCom(C,BC)
输入:非重叠社区C,社区边界点BC
输出:重叠社区C
1.Aff=empty map ,Oc=empty map ,S=Ф;
2. FOR eachv∈BC;
3. FOR eachi∈CI/*CI表示与节点v有边连接的社区标
号集合*/
Aff.put(
4. END FOR
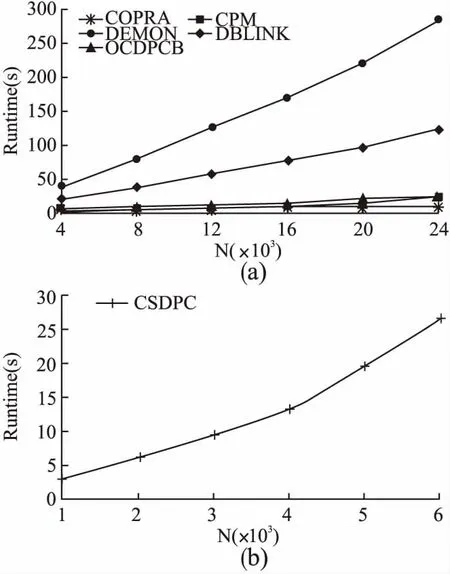
5. IF(β·min(affi(v) 6.affth(v)= min(affi(v)); 7. ELSE 8.affth(v)= avg(affth(v)); 9. END IF 10. FOR eachi∈Aff.keys() 11. IF(Aff.get(i)≥affth(v)) THEN 12.S=S∪i; 13. END IF 14. END FOR 15.Oc.put( 16. END FOR 17. FOR eachv∈Oc.keys() 18. FOR eachcI∈Oc.get(v) 19.C.put( 区标号*/ 20. END FOR 21. END FOR 22. outputC; 函数5主要步骤如下: 1)初始化社区归属度字典Aff、社区边界点及其归属社区标号字典Oc和重叠社区标号集合S为空(第1行); 2)计算社区边界点的社区归属度,并添加到社区归属度字典Aff中(第2~4行); 3)根据公式(12)计算社区边界点的社区归属度阈值(5~9行); 4)计算社区边界点的归属社区标号(第10~15行); 5)把社区边界点划分到相应的社区中(第17~21行); 6)输出重叠社区C(第22行). 设网络节点数为n,边数为m,网络的平均度为k,社区边界点数为no,社区数目为C,计算距离阈值dc时需要的迭代次数为I,节点所属的平均重叠社区数为om. 首先分析算法的时间复杂度.函数calDist()中,步骤(2)~步骤(11)计算的是节点与其直接和间接邻居的距离,因此其时间复杂度为O(k2n).步骤(12)~步骤(13)求取距离的最大值、最小值时只需遍历一次节点间距离字典,时间复杂度为O(k2n).所以,函数calDist()的总时间复杂度为O(k2n).函数calRho()中,步骤(2)~步骤(16)在计算距离阈值时假设需要迭代I次,每次迭代的时间复杂度为O(k2n),所以计算距离阈值的时间复杂度为O(k2n·I).步骤(17)~步骤(19)根据节点间的距离计算节点局部密度的时间复杂度为O(k2n).所以函数calRho()的总时间复杂度为O(k2n·I).函数calDelta()中,步骤(3)对节点的局部密度排序的时间复杂度为O(nlogn).步骤(4)~步骤(13)求节点的跟随距离的时间复杂度为O(k2n).所以函数calDelta()的总时间复杂度O(n).函数genNonOveCom()需要存储节点及节点所在的社区标号,空间复杂度为O(n).函数genOveCom()需要存储社区边界点及其所在的社区标号,空间复杂度为O(no).因此,OCDPCB算法总的空间复杂度为O(k2n+k2n+n+n+k2n+no).在真实网络中,通常有k< 为了检测OCDPCB 算法的性能,分别采用人工数据集和真实网络数据集进行测试.实验环境为一台配置3.1GHz Pentium CPU,4G内存的PC机,操作系统为Windows7 64位.采用多种经典的重叠社区发现算法进行对比,所有算法都是基于Java编程语言实现. 1)人工数据集 采用LFR[29]工具生成人工模拟的网络数据集,生成网络数据基本参数信息如表1所示. 表1 人工网络参数 参 数说 明N网络节点数k节点平均度maxk节点最大度minc最大社区节点数目maxc最小社区节点数目on重叠节点数目om重叠节点所属社区数目mu社区混合参数 通过设置不同的on,om和mu参数值可以生成不同的网络结构,实验中所使用的人工网络信息如表 2所示. 表2 LFR基准网络信息 IDNkmaxkmincmaxcmuonomS110002050201000.1~0.71003S210002050201000.31002~7S310002050201000.340~2403S44k~24k2050201000.31003 2)真实数据集 为了检测算法在真实网络上的性能,选取了9个真实网络数据集,详细信息如表 3 所示. 表3 真实网络信息 名称节点数边数平均度聚集系数Karate[27]34784.590.571Enron subnet[30]619330.326Dolphins[27]621595.130.259Football[27]11561310.660.403Polblogs[11]14901671522.440.694Netscience[11]158927423.450.694Power[27]494165942.670.08CA-GrQc[18]1484512125116.120.53CA-CondMat[18]23133934394.040.634 4.2.1 实验方法 为比较 OCDPCB 算法的性能,选取COPRA 算法[19]、CPM 算法[12]、DEMON算法[16]、DBLINK算法[24]和CSDPC算法[27]作为对比算法.通过比较算法在不同人工数据集和真实数据集上的实验结果,分析OCDPCB 算法的精度和效率.实验过程中各算法的参数和CSDPC算法的聚类中心均通过多次实验取最佳值来设定,各算法的参数设置如表4所示. 表4 算法参数设置 算法名称参数设置COPRAv=2~15CPMk=5~9DEMONe=0.1~0.5DBLINKε=0.2~0.4,Minpts=2~10CSDPC—OCDPCBλ=0.8~1.1,γ=1.4~1.9,β=1.6~3.1 4.2.2 评价指标 由于 LFR 基准网络的真实网络结构已知,所以采用标准化互信息[29](Normalized Mutual Information,简称NMI)作为人工生成网络的评价指标.NMI的定义如下: (14) 其中,CA为标准社区划分的结果,CB为算法所得到社区划分的结果,矩阵N的行对应标准社区结果,列对应算法得到的社区检测结果,Ni·为第i行的总和,N·j为第j列的总和.当算法得到社区划分的结果与标准划分的结果越相近时,NMI 的值越接近1. 在真实网络中,采用重叠模块度EQ[31]衡量重叠社区发现的质量.EQ的定义如下: (15) 其中,Qx表示结果社区中节点x属于的社区数,Axy表示原始网络的邻接矩阵,kx表示节点x的度,m是原始网络的边数. 该部分主要基于人工网络来分析参数λ、γ和β对算法精度的影响. 4.3.1 参数λ的影响实验 为了分析参数λ对社区中心点跟随距离阈值的影响,固定γ=1.8,考虑到当λ=0时,生成的社区的NMI值接近0,所以在实验中控制λ值在[0.1,2.0]内变化,在人工网络S1上进行实验,实验结果如图1所示. 图1 参数λ的实验结果Fig.1 Experimental results of the parameter λ 图1中对每一个不同的mu值,参数λ在[0.6,1.4]内变化取值时,OCDPCB算法的NMI值大多呈现先增大、接着保持稳定、后减小的变化趋势.而当λ在[0.8,1.1]内变化取值时,NMI值较为稳定,因此,可以认为当λ在该范围内取值时对OCDPCB算法聚类中心点的跟随距离阈值没有明显影响,从而不会对社区中心点的选取造成显著影响而降低社区发现的精度,所以λ合适的取值范围为[0.8,1.1].另外,当λ≥1.1时,OCDPCB算法的NMI值在mu≤0.2时较为稳定,当mu>0.2时,NMI值存在明显的下滑,是因为当mu增大,网络结构变复杂,社区中心点不易区分,λ的变化会对社区发现结果造成较大影响. 4.3.2 参数γ的影响实验 为了分析参数γ对社区中心点局部密度阈值的影响,固定λ=0.9,考虑到当γ=0时,生成的社区的NMI值接近0,所以在实验中控制λ值在[0.1,2.4]内变化,在人工网络S1上进行实验,实验结果如图2所示. 图2 参数γ的实验结果Fig.2 Experimental results of the parameter γ 从图2可以看出,对于每一个不同的mu值,参数γ在[0.1,2.4]内变化取值时,OCDPCB算法的NMI值均呈现先增大、接着保持稳定、后减小的变化趋势.而当γ在[1.4,1.9]内变化取值时,NMI值较为稳定,因此,可以认为当γ在该范围内取值时对OCDPCB算法聚类中心点的局部密度阈值没有明显影响,从而不会对社区中心点的选取造成显著影响而降低社区发现的精度.所以γ合适的取值范围为[1.4,1.9].另外,当γ≥1.5时,OCDPCB算法的NMI值在所有mu取不同值的情况下,NMI值均较为平稳,表明社区中心点的选取对节点的局部密度敏感性较弱,是因为在求取节点的局部密度时改进了DPC算法中节点局部密度的计算方法,改进后的局部密度计算方法保证了节点局部密度取值的多样性,从而降低了社区发现结果对节点局部密度的敏感性.由图1和图2比较可知,OCDPCB算法对参数λ的敏感度高于参数γ. 4.3.3 参数β的影响 为了分析参数β对社区归属度阈值的影响,固定λ=0.9,γ=1.8,β值在[1.0,4.9]内变化,在人工网络S2上进行实验,实验结果如图3所示. 从图3可看出,对于不同的om值,参数β在[1.0,4.9]内变化取值时,OCDPCB算法的NMI值均呈现先增大、接着保持稳定、后减小的变化趋势,主要是因为当β值较小时,社区归属度阈值相对较大,边界点与大部分有关联社区的归属度小于归属度阈值,不能当作重叠节点划分到这些社区中,属过少的社区降低了社区发现的精度.当β值较大时,社区归属度阈值相对较小,边界点与大部分有关联社区的归属度大于归属度阈值,从而被当作重叠节点划分到这些社区中,隶属过多的社区也会降低社区发现的精度.而当β在[1.8,3.1]内变化取值时,NMI值较高且较为稳定,因此,可以认为当β在该范围内取值时,能够得到较为准确的社区归属度阈值,OCDPCB算法能根据该阈值正确的对社区边界点进行社区划分,从而获得较高的社区发现精度.在β相同值的情况下,om值越大,NMI值越低,是因为om增大,网络中重叠节点隶属的社区数增加,不同社区之间的联系变得更加紧密,OCDPCB算法更难准确识别出社区结构.另外,om值越大,NMI值取得最大值时对应的β值越小,是因为om增大,社区边界点隶属的社区数目增多,节点的最大社区归属度和最小社区归属度差值减小,从而取得合适社区归属度阈值时对应的β值减小. 图3 参数β的实验结果Fig.3 Experimental results of the parameter β 4.4.1 人工数据集上的实验结果 图4 不同mu值精度实验Fig.4 Experimental results of accuracy with different mu 图4为各算法在人工网络 S1上的实验结果.由图4可知,随着参数mu逐渐增大,各算法的NMI值逐渐减小.当mu≥0.6时,各算法的NMI值均较低.这主要是因为mu值过大导致社区间的联系较为紧密,社区结构不明显,各算法无法准确识别出网络的真实社区.DEMON算法的NMI值在多数情况下更低,在mu逐渐增大的过程中,NMI值下降趋势较为显著,且当mu≥0.6时,NMI值接近为0.这是因为DEMON算法需要对整个网络每个节点形成的局部社区进行融合形成最优的全局社区,容易形成多个独立社区,影响算法的精度.另外,DEMON算法在生成局部社的过程中采用了LPA算法,对社区结果也会造成不稳定.CPM算法的NMI值多数情况下较低且出现抖动现象,是因为CPM算法是通过扩展完全子图来发现k-派系社区,适用于社区内部连接较为紧密的网络.另外,CPM算法无法为不同的网络找到一个固定且精确的k值,这会造成算法结果不稳定.COPRA 算法在mu≤0.5时NMI值较大,但当mu>0.5时,NMI值急剧下降,因为 COPRA 算法是基于标签传播,在节点标签的选择上具有随机性,当网络结构变复杂时,较多的节点无法获取到正确的社区标签.CSDPC算法在mu≤0.3时,NMI值较大且下降较缓,但当mu>0.3时,NMI值急剧下降,NMI值变化趋势和OCDPCB算法类似,但OCDPCB算法在多数情况下获得了更好的结果.是因为CSDPC算法和OCDPCB算法均是基于密度峰值聚类原理,在网络结构较简单时,二者能够准确的识别出社区中心点以及其他节点需要跟随的节点,从而找到正确的社区并分派到其中.但当网络结构变复杂时,OCDPCB算法对含有重叠节点的社区边界点进行了社区归属判断,根据归属度把重叠节点划分到对应的社区中,进一步提高了重叠社区划分的准确性. 图5 不同om值精度实验Fig.5 Experimental results of accuracy with different om 图 5为各算法在人工网络 S2上的实验结果.由图5可知,随着参数om逐渐增大,除CPM算法外,其余五种算法的NMI 值逐渐减小,是因为参数om增大,网络中重叠节点隶属的社区数增加,此时不同社区之间的联系变得更加紧密,社区结构变得模糊.CPM算法的NMI值随着om逐渐增大,出现了抖动现象,是因为CPM算法在生成k-派系社区时,无法为不同的网络找到一个固定且精确的k值,这会造成算法在不同结构的网络上通过扩展完全子图获取社区的结果有较大差OCDPCB算法基于密度峰值聚类的原理,各节点能够准确的识别出跟随节点,从而选择加入到对应的社区中;另外,OCDPCB算法对社区边界点进行了社区归属判断,而重叠节点大多是社区边界点,因此根据归属度把社区边界点划分到对应的社区中,也能提高重叠社区划分的准确性. 图6 不同on值精度实验Fig.6 Experimental results of accuracy with different on 图6为各算法在人工网络S3上的实验结果.由图6可知,随着参数on逐渐增大,各算法的NMI值逐渐减小,是因为on增大,网络中重叠节点数增加,此时不同社区间的连接边数目增多,社区边界变得模糊,算法不能准确确定社区边界.除CSDPC算法外,其余五个算法在on≤200时,NMI值下降较为明显,on>200时,NMI值下降较缓并趋于稳定,表明这些算法在高度重叠的网络中也能保证一定的社区划分能力.在on≥240时,CSDPC算法的NMI值最低并呈下降趋势,是因为该算法不是重叠社区发现算法,只能把节点划分到唯一的社区中,而当网络中存在较多的重叠节点时,会导致这些重叠节点及跟随这些重叠节点的其他节点被误划分到对应的社区中.OCDPCB算法在多数情况下获得了更好的结果,是因为OCDPCB算法对社区边界点进行了社区归属判断,而重叠节点大多是社区边界点,因此根据归属度把社区边界点划分到对应的社区中,能提高重叠社区划分的准确性. 4.4.2 真实据集上的实验结果 图7为各算法在9个真实网络数据集上的实验结果.从图7可以看出,CPM算法和DEMON算法在所有网络上的模块度值较低,在Karate、Enron subnet、Power和CA-CondMat这四个数据集上的模块度值远小于其他算法,主要是因为CPM算法和DEMON算法都是基于扩展局部社区来寻求整过网络的最优社区,适合于稠密型网络,而以上四个数据集所代表的网络连接较为稀疏.除了在 Football 网络上OCDPCB算法的模块度略低于COPRA 算法外,在其他多数网络上都能取得更高的模块度,并且明显高于其他算法的模块度,主要是因为OCDPCB算法基于密度峰值聚类的原理,能够准确的识别出社区中心点以及其他节点的跟随节点,从而找到对应的跟随社区.另外,OCDPCB算法对社区边界点进行了社区归属判断,根据归属度把边界节点中的重叠节点划分到多个隶属的社区中,这两种策略提高了社区划分的准确性.CSDPC算法因其空间复杂度为O(n2),无法运行在较大规模数据集上,所以在CA-GrQc和CA-CondM-at数据集上,CSDPC算法的模块度为空. 图7 真实数据集上的实验结果Fig.7 Experiment result on the real data set 由于CSDPC算法具有较高的空间复杂度,无法适用于较大规模网络,所以该算法的效率实验在较小规模的人工数据集上进行,实验结果如图8(b)所示,其他算法的实验结果如由图8(a)所示.由图8可知,COPRA算法的运行速度最快,是由于COPRA算法基于LPA算法的原理,运行时间仅依赖于算法的迭代次数,其时间复杂度和LPA算法一样,均为线性级别,所以具有较高的效率.DEMON算法、DBLINK算法运行时间较长,但运行时间随网络节点数的增加近似线性增长,与这两种算法的时间复杂度为线性级别保持一致.CPM算法运行时间在网络节点数较少时比OCDPCB算法的运行时间略低,但当节点数逐渐增大时,CPM算法运行时间渐渐高于OCDPCB算法,是因为CPM算法的时间复杂度是指数级别,当网络节点增大时,CPM算法的运行时间将急剧上升.CSDPC算法的运行时间随着网络节点数增大急剧上升,是因为该算法在求取节点间距离时采用了Dijkstra算法,时间复杂度为O(n2log(n)).而OCDPCB算法在计算节点间距离时只考虑了节点的直接邻居、间接邻居,所以时间复杂度为近似为网络边数的线性函数,因此,OCDPCB算法能够适应大规模复杂网络. 图8 算法运行时间对比Fig.8 Comparison of algorithms′ running time 本文提出了一种基于密度峰值和社区归属度的重叠社区发现算法,该算法在计算节点间距离时只考虑节点与直接邻居和间接邻居的距离,有效的降低了算法的时间复杂度.另外,定量给出了聚类中心点的局部密度阈值、跟随距离阈值和局部密度均值、跟随距离均值之间的计算关系,通过该计算关系解决了密度峰值算法中这两个阈值需要人为指定的问题.最后,把密度峰值算法应用到社区发现中,并提出社区归属度计算方法,根据社区归属度对可能存在较多重叠节点的社区边界节点进行社区归属划分,可以较好的识别出网络中的重叠社区. 未来的工作将考虑结合离群点识别算法,通过离群点识别算法来选取密度峰值算法的聚类中心,以减少参数对算法的影响.另外,为了使OCDPCB算法能够适应于更大规模的社区挖掘,将考虑基于MapReduce模型实现算法的并行化,以适应大规模复杂网络的处理.3.10 复杂度分析
4 实验结果与分析
4.1 实验数据集
Table 1 Artificial network parameters
Table 2 Information of LFR Benchmarks
Table 3 Information of Real NetWorks
4.2 实验方法和评价指标
Table 4 Algorithm parameter settings
4.3 算法参数影响实验



4.4 算法精度实验




4.5 算法扩展性实验
5 总 结
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31山花(2022年5期)2022-05-12重庆大学学报(2022年2期)2022-02-28建材发展导向(2021年19期)2021-12-06艺术家(2021年8期)2021-11-27计算机仿真(2021年6期)2021-11-17计算机应用与软件(2021年7期)2021-07-16中国传媒大学学报(自然科学版)(2021年5期)2021-02-24智能计算机与应用(2020年4期)2020-08-31散文诗(2020年1期)2020-07-20
