
学习分析视角下的个性化预测研究
2019-05-08 03:23张琪王红梅庄鲁赖松
中国远程教育 2019年4期
张琪 王红梅 庄鲁 赖松
【关键词】 学习分析;学习预测;数据挖掘;人格特质;个性化建模;智能学习系统;预测效能;数据驱动教学
【中图分类号】 G434 【文献标识码】 A 【文章编号】 1009-458x(2019)4-0038-08
一、引言
教育智能时代,教学范式的变化正顺应个性化教育的需求,以学习者为中心教学模式的深度应用驱动新技术的普及与常态化。技术在学习场景中的无缝切换,对学习时空的全方位覆盖,对学习方式的个性化支持,无不突显出技术以常态化形式“无缝内嵌”学习过程之核心特征。以学习分析为核心的“数据驱动教学”成为破解“千校一面”“千人一面”教育格局的主要力量。在学习分析多样化研究领域中,基于“嵌入式”日志数据的学习预测(预警)是重要的研究趋向。通过对日志数据的挖掘与建模,可以分析学习者个体与群体的行为信息,帮助教师尽早洞察学习者的学习进度与质量,并对学习者真实水平进行评测(丁梦美, 等, 2017)。
在学习结果预测方面,目前大多数研究将学习者视为整体进行评估,缺少个性化的分类形式与预测指标,统一的数据建模很难针对不同学习者获得较好的预测效能。此外,也鲜有较为全面的数据挖掘算法的比较研究。本研究以学习分析支撑的数据驱动教学为落脚点,以实验校一学期的互联网+教学实践为研究对象,基于人格特质分类对不同特征群体进行建模,利用数据挖掘技术进行预测与评估,以判断学习者的潜在学习危险。这不仅是预防辍学、以评促学的需要,更是契合“互联网+教育”需求,实现智能教育与个性化学习支持的必然趋势(李爽, 等, 2018)。
二、文献综述
教育大数据为基于学习分析的预测研究提供了多方面的可能性。Morris等(2005)发现学习者在Blackboard上观看内容页的数量与其最终成绩显著相关,讨论信息总数、发送邮件数量与作业情况对未能通过课程的判定准确率达到74%;Romero等(2013)通过聚类算法预测学生是否成功通过课程,最佳准确率为90.3%;Yu等(2014)建立了包含在线时间、同伴交互数量、教师交互量、总登录频率、下载次数与学习时间间隔规律等在内的预测因子。Rafaeli等(1997)对混合学习环境中学习者平台行为数据进行了分析,研究表明学习者的阅读量与在线提问数量导致了学习成绩的差异;Wong(2013)构建了混合学习环境下预测学习绩效的在线学习行为指标,包括登录次数、章节平均学习时间、在线测试完成次数及时间、查看和下载资源数量以及论坛参与频率;Zacharis(2015)对混合学习环境的研究表明,阅读量、发布消息数量、内容创作数量、测验成绩与文件浏览数量对学生成绩预测准确率为52%,分类预测准确率为81.3%;A Pardo等(2017)结合学习动机策略问卷与在线学习活动共同预测学习投入,研究表明可以更全面地理解成功的学习状态。赵慧琼等(2017)利用多元回归分析法分析影响学生学习绩效的预警因素,在此基础上构建了干预模型;胡祖辉等(2017)比较了基于关联规则、决策树与逻辑回归3种算法对学习结果的预测精度,认为关联规则挖掘算法的总体性能最好。
由此可见,学术界围绕各类LMS平台、MOOC课程、混合学习环境中的预测因子与教育数据挖掘技术展开了较为深入的研究,结果显示预测指标的多样性以及预测精度的差异性。在过去十年中,有大量理论和研究集中在学习者个性特征如何影响其行为与信息加工。学术界普遍接受的观点认为,学习者优先处理与人格特征相和谐的情感刺激,同类学习者在学习过程中会表现出相似行为倾向(Mischel, 1999)。但从研究方法上看,多数研究还是将学习者视作一个整体进行预测,并未针对他们的个性特征进行分类建模,差异性研究的缺失使得预测模型精度不足(肖巍, 等, 2018),很难满足构建个性化干预系统的需求;从算法上看,学习结果预测(数值预测与分类预警)仍缺少较为全面的数据挖掘方法在预测精度以及鲁棒性方面的比较研究。
三、研究问题
本研究拟构建适合不同特征群体的预测模型,利用多样化的数据挖掘算法对预测精度进行比较。对于学习者个性特征的划分,目前的理论探讨集中在西方对学习风格与认知风格的相关研究上,鉴于地域差异以及学习者(尤其是中学生)学习风格存在差异(张琪, 等, 2018),加之将传统环境下的研究结论直接应用于在线学习环境是否妥当等问题,制约了基于学习风格与认知风格模型设计自适应教学系统的合理性(葛子刚, 等, 2018)。众所周知,在混合(在线)学习环境中学习的本质是社会性学习,涉及无形资源(多媒体信息与数字化资源)的信息交换。因此,人格特质已广泛应用于在线学习环境的评估研究。
人格与在线学习行为的紧密联系源于网络信息的特征。在线学习涉及大量基于任务的学习、信息选择策略以及优秀观念的产生(Burt, 2004),在此类人工情境下学习者的信息加工符合中介范式和调节范式(陈莉, 2005)。其中,中介范式认为人格特质对情绪加工的显著作用是间接的,即人格影响心境状态,而心境状态又影响情绪加工;调节范式认为心境狀态对情绪加工的作用受人格特质影响或受其调节。此外,人格特质具有较好的稳定性。其稳定性与独特性在很大程度上归功于其核心成分——特质(Trait)。特质使个体对不同种类的刺激以某种相对一贯、稳定且相同的方式进行反应,是个体的“神经特性”(Matthews, et al., 2003)以及“支配个人行为的能力”(Allport, 1937)。
鉴于人格特质在识别个体差异、跨文化普适性以及与在线学习行为的关联性等方面具备优势,故本研究利用“大五人格”识别学习者特征。基于“大五人格”的“开放性”和“外倾性”维度的高低水平划分不同人格类型(张琪, 等, 2018),建立相应预测模型,解析不同人格类型相应的显著预测因子。具体来说,本研究的研究问题包括3个:
问题1:学习平台采集的学习行为指标与不同人格特质群体学习结果之间是否呈显著相关?
问题2:对于具有不同人格特质的学习群体,哪些学习行为指标对于预测学习结果是重要的,是否存在共性的行为指标?
问题3:从统计学角度看,什么样的数据挖掘算法在数值型与分类预测中具备最佳精度与鲁棒性?
四、研究过程
(一)研究场景
本研究基于高中实验校“互联网+”混合学习场景。在智慧学习平台支撑下,教学中心、学习中心、管理中心、资源中心全局数据无缝衔接。学习者有明确的学习目标、任务和时间安排,基于“四维驱动”教学模式开展学习。“四维驱动”教学模式是指“以导学任务单驱动学生的自主学习,以层级式问题驱动学生的合作探究,以学习数据分析驱动教师的按需教学,以课堂即时评测和成果分享驱动知识内化”。“四维驱动”教学模式强调4个方面的特征:一是以层级式任务为导向,以衔接课前与课后的活动贯穿始终;二是基于移动学习终端,以教育云平台作为支撑环境;三是平台模块功能与教学模式深度融合,技术以常态化形式“无缝内嵌”于学习过程之中;四是派生出操作性和指导性极强的全学科常态化教学设计流程。
学生在一学期的课程学习中充分利用PAD终端进行学习,课程持续进行16周,后2周为期末考试。研究选取全体高一年级662名学生为样本,基于语文与英语两门课程的学习行为数据展开分析。将两门课程期末成绩与平时成绩加权分(期末成绩占70%,课堂表现占30%)的平均分作为最终成绩,以相对客观地量化学习结果。
(二)采集行为指标
采集的行为指标来自LMS平台的页面系统、交互系统、课件点播系统、测试系统和笔记系统。其中,页面系统包括课程页面浏览总次数与总时间;交互系统包括文本型提问数量、文本型回答数量、媒体型提问数量、媒体型回答数量与教师推荐发言数量;课件点播系统以交互电子教材(视频)形式呈现,根据内嵌客观问题权重自动判分,包括课件点播次数、课件点播时长与交互课件得分;测试系统包括及时测评剩余时长(班级学生最长作答时间减去各学生作答时间)、及时测评分数与课后测验平均分数;笔记系统包括学习笔记数量(序号之和)与学习笔记长度(字符串长度之和)。
(三)人格特质识别
本研究采用NEO-FFI大五人格简化问卷测量人格特质水平(Costa & McCrae, 1992)。已有研究表明,该问卷具有与完整版相同的信度和效度(Kurtz & Sherker, 2003),其中“开放性”和“外倾性”维度各为12个题项,采用5级计分。“开放性”Cronbach α为0.736,均值为40.32,标准差为5.91;“外倾性”Cronbach α为0.831,均值为41.19,标准差为4.76。将各维度数值标准化,分别映射到区域[0,3]与[-3,0],即每一维度划分为高低两类,最终得出4种人格类型P={P1, P2, P3, P4}。P1、P2、P3、P4分别代表“高开放、高外倾”“低开放、高外倾”“低开放、低外倾”“高开放、低外倾”4类人格群体。样本数量分布分别为31.11%(P1)、21.45%(P2)、25.23%(P3)和22.21%(P4),人数分布大致均匀。
五、研究结果
(一)不同人格特质群体行为指标与学习结果的相关性
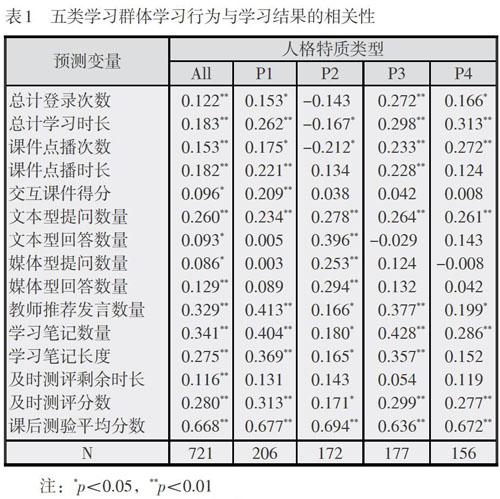
表1给出了不同数据集学习行为与学习结果相关分析的数据。基于全集样本的相关分析结果表明,15个行为指标与学习结果均呈显著正相关。其中,课后测验平均分数与学习结果呈现高相关(r=0.668),教师推荐发言数量(r=0.329)、学习笔记数量(r=0.341)与学习结果呈现中相关,其余指标均为低相关。
对于“高开放、高外倾”学习者,11个行为指标与学习结果呈显著正相關。其中,课后测验平均分数与学习结果呈现高相关(r=0.677),教师推荐发言数量(r=0.413)、学习笔记数量(r=0.404)、学习笔记长度(r=0.369)、及时测评分数(r=0.313)与学习结果呈现中相关,其余指标均为低相关。
对于“低开放、高外倾”学习者,9个行为指标与学习结果呈显著正相关。其中,课后测验平均分数与学习结果呈现高相关(r=0.694),文本型回答数量(r=0.396)与学习结果呈现中相关,其余指标均为低相关。值得一提的是,总计学习时长(r=-0.167)和课件点播次数(r=-0.212)与学习结果均为低负相关。
对于“低开放、低外倾”学习者,10个行为指标与学习结果呈显著正相关。其中,课后测验平均分数与学习结果呈现高相关(r=0.636),教师推荐发言数量(r=0.377)、学习笔记数量(r=0.428)、学习笔记长度(r=0.357)与学习结果呈现中相关,其余指标均为低相关。
对于“高开放、低外倾”学习者,8个行为指标与学习结果呈显著正相关。其中,课后测验平均分数(r=0.672)与学习结果呈现高相关,总计学习时长(r=0.313)与学习结果呈现中相关,其余指标均为低相关。
(二)不同人格特质群体的学习建模
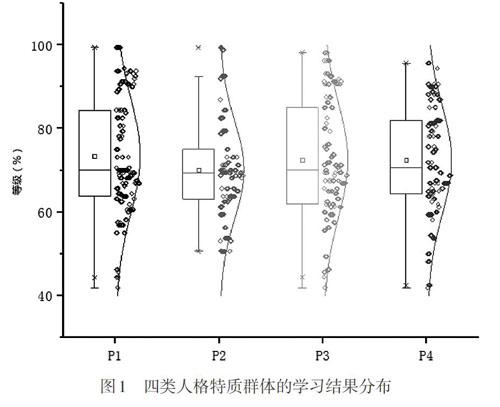
以15个行为指标为自变量,学习结果为因变量,利用逐步回归进行数据建模。将所有具有低显著水平的预测因子从模型中删除。图1给出了不同人格特质群体学习结果分布的箱线图。箱线图的优势是不受异常值的影响,是相对稳定的数据离散分布可视化形式。从图1可以看出各群体均服从正态分布,“低开放、高外倾”群体的学习结果平均水平与波动程度低于其他群体。
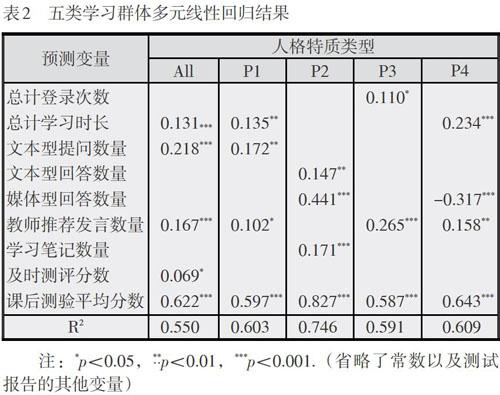
容忍度与方差膨胀系数的结果排除了各回归方程的多元共线性问题。表2给出了5类学习群体对应的回归方程预测变量。其中,全集数据样本中总计学习时长、文本型提问数量、教师推荐发言数量、及时测评分数、课后测验平均分数5个变量依次进入回归方程(F=174.141, P=0.000),对学习结果解释力为55%;“高开放、高外倾”学习群体,总计学习时长、文本型提问数量、教师推荐发言数量、课后测验平均分数4个变量依次进入回归方程(F=50.340, P=0.000),对学习结果解释力为60.3%;“低开放、高外倾”学习群体,文本型回答数量、媒体型回答数量、学习笔记数量、课后测验平均分数4个变量依次进入回归方程(F=174.141, P=0.000),对学习结果解释力为74.6%;“低开放、低外倾”学习群体,总计登录次数、教师推荐发言数量、课后测验平均分数3个变量依次进入回归方程(F=46.451, P=0.000),对学习结果解释力为59.1%;“高开放、低外倾”学习群体,总计学习时长、媒体型回答数量、教师推荐发言数量、课后测验平均分数4个变量依次进入回归方程(F=43.916, P=0.000),对学习结果解释力为60.9%。
为了进一步考察各回归方程中课后测验平均分数(最高权重)与学习结果的关系,以散点图形式给出了两者可视化关系,见图2。散点图是识别变量之间潜在相关趋势的有效方法(Field, 2005)。图2再次表明,课后测验平均分数与不同人格特质学习者的学习结果之间呈正相关,且为线性趋势。
(三)不同数据挖掘方法的预测效能比较
基于Python 3.7环境,利用28种回归算法比较预测精度,包括ElasticNet回归、Linear回归、MLP回归、SMO回归、RandomTree回归、RandomForest回归、SVM回归等。利用皮尔逊相关系数(PCC)、一致性相关系数(CCC)、平均绝对误差(MAE)与均方根误差(RMSE)以及5倍交叉验证,判别具有最佳精度和鲁棒性的数据挖掘方法。其中,皮尔逊相关系数是预测分值与实际分值的皮尔逊相关;一致性相关系数考察连续变量之间的一致性与重现性;平均绝对误差是绝对误差的平均值,能反映预测值误差的实际情况;均方根误差用来衡量预测值与实际值之间的误差大小。图3给出了不同算法的分析结果。

如图3所示,对于皮尔逊相关系数,RandomForest回归最高(0.859),其次是KStar回归(0.841);对于一致性相关系数,RandomForest回归最高(0.850),其次是KStar回归(0.837);对于平均绝对误差,KStar回归最低(4.176),其次是JR回归(6.490)和RandomForest回归(6.635);对于均方根误差,RandomForest回归最低(10.906),其次是KStar回归(11.663)。由此可以看出RandomForest回归为最佳的预测算法。
利用分类算法对课程风险进行识别预测,学习结果低于60分的学习者被视为“具有风险”,60分至80分被视为“表现良好”,高于80分被视为“学业优秀”。本研究比较了24种分类算法的预测精度,包括JR、RandomTree、RandomForest、SVM以及SMO等。利用準确率(Precision)、正确率(Accuracy)、召回率(Recall)、F值(F-Measure)以及5倍交叉验证,判别具有最佳精度和鲁棒性的数据挖掘方法。其中,正确率指分类正确的样本数与样本总数的比率;准确率即查准率,指检索相关文档数与检索出文档总数的比率;召回率即查全率,指检索相关文档数与所有相关文档数的比率;F-Measure为查准率与查全率加权调和平均值。图4给出了不同算法的分析结果。

如图4所示,在准确率方面,RandomForest最高(0.905),其次是KStar(0.891)和MODLEM (0.875),NaiveBayes最低(0.563);在正确率方面,RandomForest最高(0.913),其次为MODLEM (0.887)与KStar(0.873),ConjunctiveRule(0.498)最低;在召回率方面,KStar最高(0.870),其次是RandomForest(0.859)和PART(0.830),SMO(0.591)最低;在F-Measure方面,RandomForest最高(0.879),其次为KStar(0.871)与MODLEM(0.830),SMO(0.529)最低。可以看出,RandomForest在预测学习者失败风险方面效果最好。
六、分析与讨论
(一)研究结论
猜你喜欢
现代企业(2022年5期)2022-05-31
大众投资指南(2021年35期)2021-02-16
意林·全彩Color(2019年7期)2019-08-13
趣味(语文)(2018年7期)2018-06-26
电力与能源(2017年6期)2017-05-14
考试周刊(2016年88期)2016-11-24
赤峰学院学报·自然科学版(2015年20期)2015-12-26
信息通信技术(2015年6期)2015-12-26
中国康复(2015年4期)2015-04-10
电子设计工程(2014年18期)2014-02-27
