
编程困难检测概述
2019-04-22 12:03王瑞文
现代计算机 2019年8期
王瑞文
(四川大学计算机学院,成都 610065)
0 引言
在21世纪,IT行业在全球经济中所占的比重变得越来越大,而编程能力也逐渐成为科研和工程领域的高端人才不可或缺的技能之一,而且越来越多的工作被程序所取代,社会对编程技能的需求以及编程的效用也不断增加。在McKinsey全球研究院于2013年发布的《至2025年决定世界未来经济的12大颠覆技术》中,排名前六位的都是与编程密切相关的技术,且大约占到了经济规模的90%[1]。但是,无论是刚接触编程的学生还是专业的程序员,在编程中都不可避免地遇到各种困难,这些困难则会阻碍他们的学习或者开发进度。
在编程教学方面,如果能够检测到学生在编程中遇到的困难,并在恰当的时机由系统自动地给予学生适宜的反馈,例如在内容上提示学生应当如何改善代码,或者在情绪上给予支持及鼓励,增强其学习动机。另外,可以将自动检测得到的学生困难信息提供给教师,例如每个学生遇到困难的次数、经常出现的困难类型等。依据这些补充信息,教师可以进一步了解各个学生的特点,以及在不同知识点上的掌握程度,如此一来,教师就可以针对性地为各个学生提供个性化的教育,做到因材施教。
在工业生产方面,专业程序员也常常面临编程困难,这些困难如果得不到解决,则会明显地限制开发进度,降低程序员的生产力。Herbsleb等人[2]发现,如果团队成员均处于同一建筑物中,其生产力要高于成员分散于各地的团队,其原因在于前者能够使成员之间互相帮助更多。Herbsleb和Grinter[3]的一项早期研究指出了这一现象的原因之一:分散在不同地点的团队成员之间相对地会在询问帮助上感到更加不舒服,因为他们之间的互动比共处一地的团队少很多。而Teasley等人[4]的研究则进一步证明了这一事实。他们发现处于同一个房间的团队,其生产力要高于成员分散于不同房间的团队。这是因为共处于同一房间的开发者可以看到以及听到其他人在做什么,这使得他们可以在注意到某人遇到困难时为他提供帮助。这些研究共同表明——团队之间互相帮助越多,其困难就能越顺利地得到解决,从而促进团队生产力的提高。因此,自动地检测开发者遇到的编程困难,并适时地提供恰当的困难上下文信息提供给团队中的其他开发者,促进他们之间的互助,可以提升团队生产力。
综上所述,无论是从教育界的视角还是工业界的角度来看,检测开发者在编程中遇到的困难都具有很重要的意义。本文对已有文献进行了概括分析,对编程行为数据收集工具进行了介绍,对已有工作进行了概括与分类,总结了当前编程困难检测研究的进展。
1 编程行为数据收集
对于编程困难检测而言,特征数据的收集至关重要。但是在对于开发者行为数据的收集,能够采集到什么编程语言的行为数据,能够采集到什么层次的哪些行为数据,取决于所使用的IDE以及行为记录工具。Ihantola等人[5]在他们对于教育数据挖掘的综述中总结了多款可用于编程数据收集的工具,见表1前10行。
对于编程行为数据收集工具来说,其能收集的数据类型越丰富越好。Yoon等人[6]开发的FLUORITE1http://www.cs.cmu.edu/~fluorite/research.html可以记录Eclipse下Java编程的多种事件级信息。他们宣称该工具可以记录Eclipse代码编辑器内的全部低层次事件。FLUORITE分为两个部分:其logger部分能够记录各种编程事件并保存到xml文件中;其analyzer部分可以用来检测代码编辑模式、对收集到的数据进行统计和可视化。Fluortie记录三种类型的事件:
●命令(Command):直接由用户动作引发的事件,包括:输入文本、移动文本光标、通过键盘或鼠标选中文本、调试以及各种编辑器命令(如复制、粘贴、撤销)。
●文档变化(Document Change):执行任意命令导致文件变化时被记录的事件。该类型事件会记录文档变化的内容、位置、时间等信息。
●注解(Annotation):这类事件用于让开发者向调查人员提供注解。用户可以点击注解按钮,然后在下图所示弹出来的对话框中添加注解。
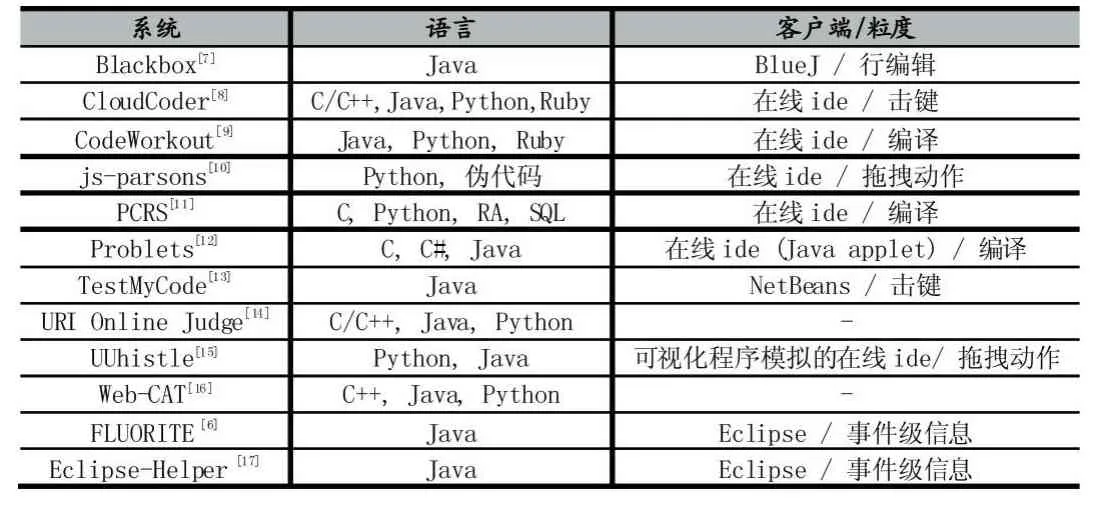
表1 已有的编程数据收集工具示例
Fluorite在记录这些事件的同时还记录了各个事件的内容:如插入删除的文本、文本光标移动时的位置、打开的文件、事件的时间戳等。在Fluorite的基础之上,Long等人[17]开发了EclipseHelper这一困难检测实验平台,它集成了实时困难检测、标记困难标签、可视化编程行为数据与预测结果等功能。
2 编程困难检测分类
编程中的困难可以被定义为:开发者(或观察者)可以感知到的开发速度低于正常[18]。
对于各种编程困难检测研究,我们可以从各种不同的方面对其进行分类。依据算法是否能够实时地检测编程困难,我们可以将它们分为在线(online)的方法以及离线(offline)的方法。依据算法是否需要使用额外的传感器设备来捕捉编程时的数据,我们可以将它们分为有传感器(with sensor)的方法以及无传感器(sensor free)的方法。
2.1 在线 vs离线
依据算法是否能够在开发者编程的过程中即时地检测出困难,可以将编程困难检测分为两类:在线编程困难检测以及离线编程困难检测。
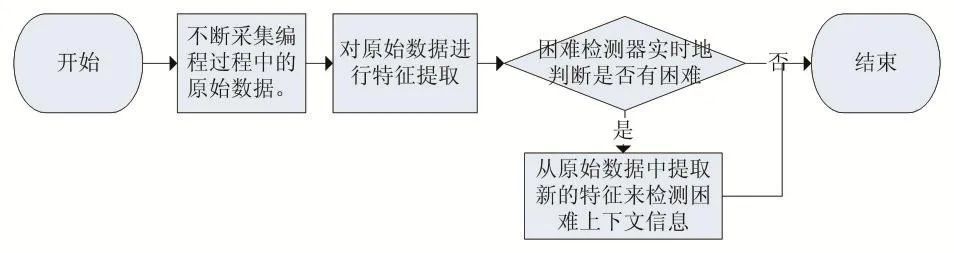
图1 在线困难检测流程
如果一个困难检测器能够在开发过程中连续不断采集开发者信息的同时,利用这些信息实时地检测出开发者是否遇到了困难,那么我们称这种检测方法是在线的。在线编程困难检测的一般流程如图1所示。首先,程序需要在开发者编程的同时,持续地采集各种变成情境下的原始数据。然后将得到的这些原始数据进行特征提取,将得到的特征作为训练好的困难检测分类器中,实时地判断开发者是否遇到了困难。如果开发者遇到了困难,则可以从原始数据中提取新的特征来检测更多困难上下文信息,如困难类型。在线困难检测中,通常使用开发者的生理心理数据(如心率、肌电、脑电图等)或行为数据以及一些代码的统计数据作为数据源。在线困难检测如Cater的研究[19],Cater手动检查了被试在遇到困难时的行为变化,总结出了五类开发者遇到困难时可能有明显变化的行为:文件导航(打开文件、切换文件等);编辑(文本插入、删除);移除代码(方法或类);调试;切入切出IDE(Integrated Development Environment,集成开发环境)。依据这五类行为的比率,Carter使用决策树成功地在开发者编程的同时检测出了他们的困难。
如果一个困难检测器需要在开发者完成一次编程之后,才能收集到所需的所有数据或者才能开始训练检测器模型,不能做到实时地检测困难。那么我们称这种检测方法是离线的。在离线的困难检测中,通常是对开发者在编程过程的不同阶段进行分析。例如,Piech等人[20]利用学生在编程过程中的代码快照对其开发路径进行了建模,以此展示学生的进度,并确定他们在哪里遇到困难。他们记录学生每次编译时的代码快照,利用K-Mediods算法对来自不同学生的代码快照进行聚类,再使用隐马尔可夫模型训练出一个有限状态机,如图2所示。这一状态机可以表示学生在编程时如何在各种高层状态之中转移。这些高层状态代表着学生在编程时的不同里程碑阶段。使用这一方法,可以在学生完成编程练习之后,建模他们的编程进展过程,从而识别出学生在编程中何时遇到了困难。学生在编程过程中,可能在连续多个代码快照中均停留在一个高层状态,这种状态则被称为“下沉状态”,它指示着学生可能遇到了严重的编程困难。
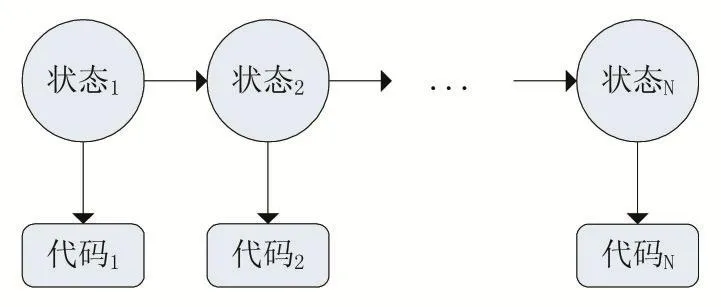
图2
某一学生在开发一个程序过程中状态转移的隐马尔可夫模型。结点“codet”表示学生在时刻t的代码快照,而结点“statet”表示的是学生在时刻t所处的高层状态。N是该学生的代码快照数量[20]。
2.2 有传感器 vs无传感器
依据算法在采集特征数据时是否需要使用额外的传感器,可以将编程困难检测分为两类:有传感器方法和无传感器方法。这两类方法有各自的优缺点。
有传感器方法指在标准设备之外的传感器来收集数据的方法。使用传感器可以收集到更丰富的,更多类型的数据。常见的传感器数据包括:被试的心率、皮肤电导等生理特征、被试的面部照片(表情)、按键压力、坐姿,等等。其中很多数据与困难相关。例如微表情[21]可以很好地揭示出一个人的情绪,而开发者在遇到编程困难时,常常伴随着困惑、沮丧等情绪。Kapoor等人[22]使用多种传感器来预测孩子何时感到沮丧。他们认为:沮丧感与身体姿势,面部表情,施加于鼠标的压力和皮肤电导的变化相关。为了验证这一猜想,他们在24名中学生解决汉诺塔问题的时候,从相机、姿势座椅、压力鼠标和无线蓝牙皮肤电导测试收集这些数据。在编程过程中,为了收集类标数据,参与者需要点击“我很沮丧”按钮。当参与者没有点击“我很沮丧”按钮时,他们被标记为不沮丧。他们训练了几种分类算法来输出模型,如支持向量机(Support Vector Machines,SVM)。他们的结果显示SVM算法达到了70.83%的查准率。Fritz等人[23]则使用了心理-生理传感器收集了15位专业程序员在编码时的数据,包括眼动仪、皮肤电活动传感器、脑电图。他们使用这些数据来预测开发者是否遇到了困难。对于训练集外的开发者,其查准率达到了64.99%,查全率达到了64.58%。对于训练集外的编程任务,其查准率达到了84.38%,查全率达到了69.79%。
虽然有传感器方法可以搜集到更全面的特征信息,从而提升算法准确度。但是它也存在明显的弊端。首先,传感器的布置就会造成额外的开销,尤其是许多专用设备造价高昂使用复杂,导致方法难以普及。其次,使用传感器可能会对被试造成干扰,并且会涉及到用户的隐私。
无传感器方法虽然收集的数据类型不如有传感器方法丰富,但是它不需要额外布置其他设备,比较易于普及。另外它也不会对开发者造成过多的干扰。无传感器方法通常使用开发者在开发时的行为日志、代码快照等数据。行为日志可以体现出开发者的行为模式。例如,Jadud等人[24]依据编程时的编译事件信息,提出了错误商(Error Quotient,EQ)这一概念。错误商可以用于发现开发者在什么时候遇到了语法上的困难,即难以解决编译错误。它是使用以下算法计算的:
给定编译会话,e1到en:
(1)配对连续编译(e1,e2),(e3,e4),(e5,e6),…,(en-1,en)
(2)对有编译错误的对赋予一个数值罚分。
①如果两边都有编译错误,则分配8的罚分。
②如果两边有相同的编译错误,则额外再加上3的罚分。

图3 Kapoor工作[22]中的系统架构
(3)将分配给每一对的分数除以11(每对可能的最大值)
(4)将每对编译的分数相加
(5)将总分除以编译对的总数n-1
他们通过反复试验来确定罚分的数值。完美的错误商数为0.0,这意味着学生能够修正语法错误。相反,1.0的错误商数意味着每次学生编译代码时,编译都以相同的语法错误结束。另外他们还对比发现了EQ指标和作业、考试的平均成绩之间存在相关性。
也可以将传感器数据与编程行为数据结合起来进行编程困难检测。Carter发现了他们原始的困难检测方法[6]具有较高的假阴率,于是进一步精练了行为特征集并加入传感器特征[25]。Carter分别使用Microsoft Kinect Camera和Creative Interactive Gesture Camera来捕捉用户的坐姿,判断用户是否前倾、后倾。他们发现在结合坐姿特征以及编程行为特征之后,可以明显改进检测结果,降低假阴率。
3 结语
编程困难检测作为编程数据挖掘的一个分支,与教育界以及工业界密切相关。在检测到用户遇到困难之后,可以采取多种措施来辅助编程过程。对于学生,我们可以给予他一定情感支持来保持其学习动机。对于专业开发者,我们可以为他提供一定的代码内容上的支持,引导他解决困难。目前的各种编程困难检测方法存在不足,如在用户空闲时不能准确地区分用户是在思考编程还是去做与编程无关的事情;在检测到困难后给予用户的反馈不足等缺点。本文概述了编程困难检测中的数据收集、通用流程、方法分类,希望可以促进编程困难检测研究的进展。
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
天津科技(2022年5期)2022-05-31
电脑知识与技术·经验技巧(2019年3期)2019-06-25
新高考·高二数学(2016年7期)2017-01-23
经济(2016年29期)2016-12-27
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
CHIP新电脑(2016年3期)2016-03-10
电脑爱好者(2015年4期)2015-09-10
股市动态分析(2015年16期)2015-09-10
