
一种改善光照对深度人脸识别影响的方法
2019-04-19 05:24陈思佳
计算机技术与发展 2019年4期
贺 辉,陈思佳,黄 静
(北京师范大学珠海分校 信息技术学院,广东 珠海 519087)
0 引 言
人脸识别一直以来都是计算机视觉领域的一个研究热点,相比指纹识别、虹膜识别等识别方式,人脸识别有更多优势,因此,基于人脸识别技术的应用也越来越广泛。随着深度学习的兴起,越来越多的领域采用深度学习模型作为主要模型,而在计算机视觉领域,卷积神经网络(convolutional neural network,CNN)成为了最有效的模型之一,人脸识别也不例外,基于卷积神经网络分类模型的方法具有明显优于以往机器学习模型的效果[1]。神经网络如此强大的一个主要原因是深层神经网络拥有的“万有逼近”能力:深层神经网络可以逼近任意连续函数。而卷积神经网络具有强大的采样能力,能够自动提取图像集中的主要成分[2]。然而,虽然人脸识别率已经接近100%,但是市面上人脸识别设备的应用却很少,主要原因还是模型训练集远远不能覆盖现实中所有的影响因素,而在这些影响因素中,光照是最具代表性的一种。虽然卷积神经网络本身十分强大,在数据集足够好的时候可以几乎不采用任何图像预处理方式,但是当数据集不够全面,或者说缺少足够多的数据时,光照对识别率的影响很大。因此,改善光照对人脸识别的影响对实现人脸识别在工业上的应用有着极其重要的意义[3-4]。
在光照问题上,近年来并没有提出与CNN相结合的方法,主要原因是人为提取高质量的特征十分困难,并且人为干涉会降低模型提取到的特征的质量[5],因此现在的主流主张是让模型自主提取特征。例如,特征脸方法[6]是人脸识别领域内的经典方法,利用PCA(principal component analysis)方法计算多张人脸照片的协方差,并求出其特征值和特征向量,接着利用特征值保留最大的若干特征向量,最后利用特征向量对原图像进行投影,这样就达到了保留主成分而降维的目的;基于光照不变表示的方法[7-8],认为映射到人眼中的图像和光的长波(R)、中波(G)、短波(B)以及物体反射性质有关;局部二值模式法(local binary patterns,LBP)在人脸识别中应用广泛,对光照、年龄、表情等变化都有很强的鲁棒性[9-10],它通过与周围像素的对比,具有旋转不变性和灰度不变性等特点,但是经它处理后的图像并不符合直觉,换句话说,并不能轻易地由人眼分辨。实际上,经过LBP处理后的图像一般不直接用于识别,而是将区域分块直方图连成一个特征向量,放入分类器中做分类,显然这种方法并不适合与卷积神经网络相结合,因为它本身就是一种采样操作,降低了图片的可识别性。
既然CNN具有生物视觉神经的特点,那么人为干涉实际上是可以提高模型提取特征的质量的,就像近视眼镜对于近视眼一样。基于这样的考虑,结合直方图均衡化预处理后图像的特点,文中提出了一种类视网膜大脑皮层增强法,并通过实验进行验证。
1 算法描述
1.1 类视网膜大脑皮层增强法(SRRM)
视网膜-大脑皮层(Retinex)理论[7]认为世界是无色的,人眼看到的世界是光与物质相互作用的结果,也就是说,映射到人眼中的图像和光的长波(R)、中波(G)、短波(B)以及物体反射性质有关,如式1所示。
I(x,y)=R(x,y)L(x,y)
(1)
其中,I是人眼中看到的图像;R是物体的反射分量;L是环境光照射分量;(x,y)是二维图像对应的像素位置。
基于Retinex理论,有学者提出了SSR(single scale Retinex)方法[8],通过估算L来计算R,具体来说,L可以通过高斯模糊和I做卷积运算求得,如下:
logR=logI-logL
(2)
L=F*I
(3)
其中,F是高斯模糊滤波器;“*”表示卷积运算。
通过选择不同的高斯周围空间常数(Gaussian surround space constant)对图像处理有比较大的影响,小的常数对细节和动态区域压缩有比较好的效果,但是整体色彩容易失真,大的常数反之,这也是SSR方法的不足之处。
针对这个问题,有学者提出了MSR(multi-scale Retinex)方法[11-13],MSR使用了多种常数,并用权值的方法将它们混合在一起,如下:
(4)
(5)
其中,σi为高斯周围空间常数;wi为每个待混合图像的权值,一般来说:
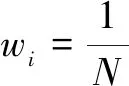
(6)
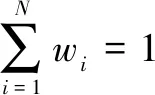
(7)
其中,N为选用高斯周围空间常数的数量。
然而SSR和MSR对于色彩恢复在灰度上的都有些问题,主要原因在logR恢复到[0,255]色彩空间的方式,也就是恢复到R的方式。针对这个问题,Parthasarathy等提出了带色彩恢复的多尺度视网膜增强算法(multi-scale Retinex with color restoration,MSRCR)[14],如式8~10:
(8)
(9)
Ri=G(CilogR-b)
(10)
其中,Ci是色彩恢复函数;α、β、G都是经验参数;b是经验偏移量;S是色彩通道数。
为从根本上消除MSRCR方法导致的图像关键点不明显的缺点,结合直方图均衡化在增强图像对比度上的优点,提出了一种类视网膜大脑皮层增强法(similar Retinex reinforcement method,SRRM)。
SRRM方法同时克服了直方图均衡化方法导致的图像多处变化大的缺点,也即经过SRRM处理后的图像具有关键点外的变化度小和有利于目视判读的优点,也即该方法同时保留了灰度增强和视网膜大脑皮层法的优点。
算法基本步骤如下:
输入:人脸图像矩阵;输出:增强结果矩阵。
Step1:将图像转为RGB图,并对图像利用MSRCR进行处理;
Step2:将处理后的图像转为灰度图,进行直方图均衡化处理。
1.2 基于深度学习的人脸识别分类器
基于CNN的人脸识别分类器非常多,它们一次次地刷新了LFW的记录[1],甚至有些网络模型拥有非常好的鲁棒性,即便不对数据做过多处理也可以得到非常好的效果[15]。为验证文中提出的预处理方法的有效性,这里使用一种相对并不复杂的CNN结构。
将输入图片作为输入层;第二层是卷积层,卷积核尺寸为5×5,步长为1;第三层是池化层,池化核的尺寸为2×2,步长为2;第四层是卷积层,卷积核尺寸为5×5,步长为1;第五层是池化层,池化核的尺寸为2×2,步长为2;第六层是全连接层,神经元数量为256;最后一层也是全连接层,神经元数量为68,即训练集类别。将最后的输出结果输入到softmax函数中做分类。
2 实验及结果分析
文中选用CMU_PIE人脸光照数据库作为实验数据集,CMU_PIE数据集中的Pose9是正脸居中裁剪好的人脸数据,一共包含1 632张人脸图片,包含68个来自多个国家的人的人脸,其中每人有24张尺寸为64×64的灰度图片,包含3张暗光照下不同表情的图片和21张不同角度的环绕光照图片。
为了保证数据集倾斜情况的发生,对每张人脸,分别取19张图片作为训练集,5张图片作为测试集,这样训练集有1 292张图片,测试集有340张图片,训练集和测试集不相交。实验同时对比了文中提出的SRRM方法与特征脸方法、LBP方法[16]、MSRCR方法、直方图均衡化方法分别对图片进行预处理后的CNN的识别效果,对于每张图片,CNN每次会返回最有可能的预测结果,实验中根据分类器的识别率作为标准。为了保证实验结果的客观真实,对于每种图像处理方法的训练集和测试集,都进行了10次随机选取,对于每次选取的数据,又进行了10轮神经网络的训练,最终的实验结果是100组实验结果取均值,总体技术路线如图1所示。各种方法预处理实验结果如图2~图5所示,最终的人脸识别精度比较如表1所示。
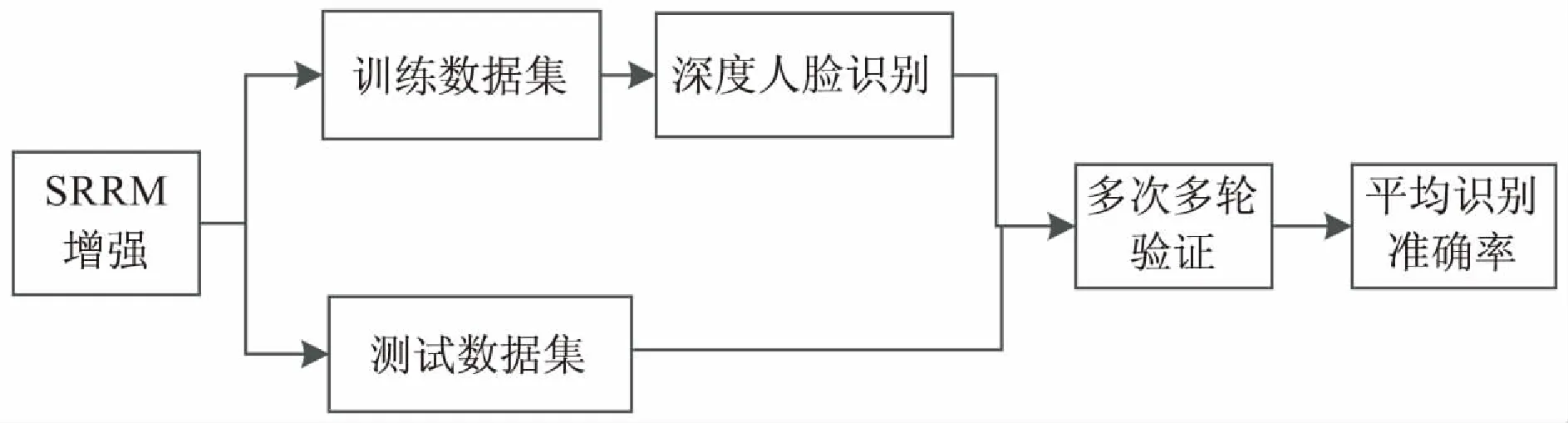
图1 总体技术路线

图2 LBP处理
(注:第一行是原图,第二行是处理后的图像)
从图2可见,虽然LBP表现出了强大的人脸识别问题解决能力,但是经它处理后的图像并不符合直觉,换句话说,并不能轻易地由人眼分辨。最后的识别结果也表明LBP不适合与卷积神经网络结合,因为它本身就是一种采样操作,降低了图片的可识别性。从图3可见,MSRCR可以比较好地保留人脸轮廓,消去图中的光照和阴影与皮肤信息,但是对比度不高,一些轮廓细节不明显。由图4可见,直方图均衡化预处理也有明显的缺点:变化后的图像灰度级可能会减少,使某些细节不明显甚至消失;均衡化后的灰度范围取决于原图像的灰度范围,因此对灰度范围过小的图像对比度增强的效果有限。而从图5中可以看出,SRRM方法同时保留了灰度增强和视网膜大脑皮层法的优点。

图3 MSRCR处理
(注:第一行是原图,第二行是处理后的图像)

图4 直方图均衡化处理
(注:第一行是原图,第二行是处理后的图像)
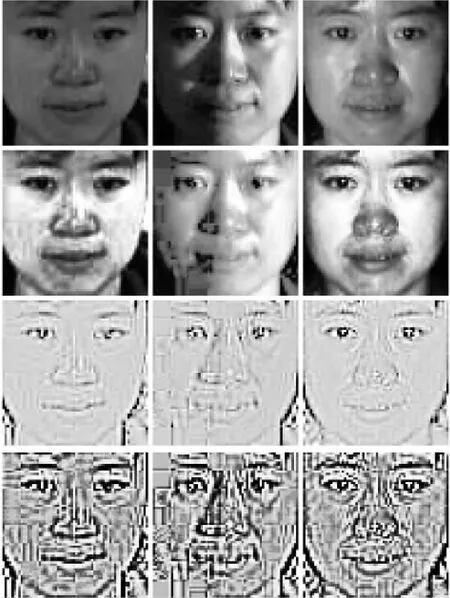
图5 SRRM处理
(注:第一行是原图,第二行是经直方图均衡化处理后的图像,第三行是经MSRCR处理后的图像,第四行是经SRRM处理后的图像)
需要特别说明的是,当预处理方法为PCA时,会先将数据集分为训练集和测试集,再让PCA模型对训练数据集拟合,最后再分别对训练集和测试集进行重构预处理,以此来避免预处理方法对测试集的拟合。
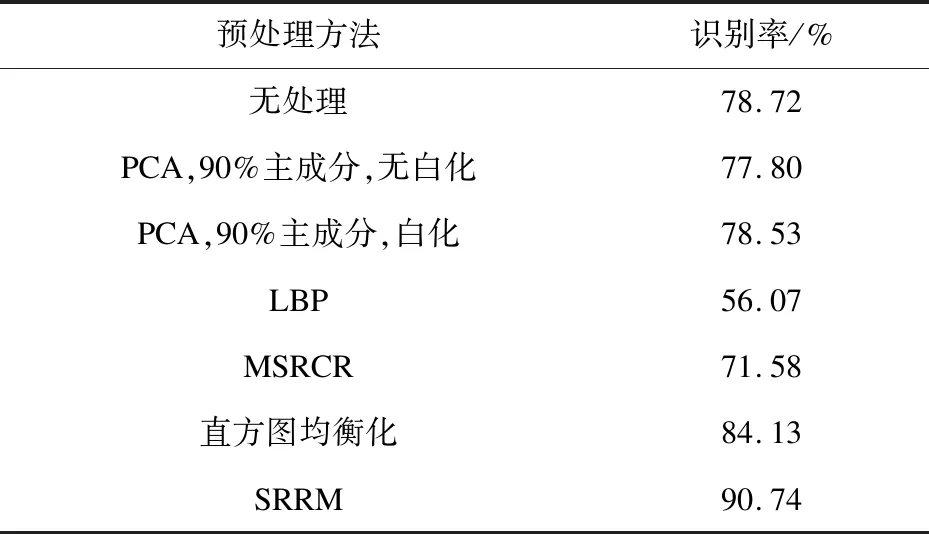
表1 多种光照预处理方法与CNN结合后的 实验结果
表1结果显示,SRRM方法相比其他图像预处理方法,在光照处理上拥有更好的效果,明显提升了CNN在光照影响环境下人脸识别的能力。
3 结束语
提出了一种新的光照预处理方法:视网膜大脑皮层增强法(RRM),并与多种典型的光照预处理方法进行了对比实验。实验结果证明,该方法在处理光照不均图像并与CNN结合后的效果远超其他方法,有效地提升了CNN在不均匀光照环境下对人脸识别的能力。更重要的是,提出的CNN和以往的分类器不同,它的识别方式应该符合直觉,也就是说图片应该可以被人眼识别,并通过实验证明了这种想法的正确性,对解释CNN这个复杂的黑盒模型非常有帮助。对于比较极端的光照情况(如半张脸完全被黑暗覆盖),虽然该方法也有复原图像的能力,但是在一些细节上有比较大的瑕疵,针对这个问题,除了一些光照补偿算法外,可以考虑利用人脸的对称性复原人脸,从已经做过的实验结果来看这应该比子空间匹配更有利。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康体检与管理(2022年4期)2022-05-13
现代临床医学(2021年2期)2021-03-29
建材发展导向(2021年23期)2021-03-08
计算机应用(2020年11期)2020-11-30
中学生数理化·高一版(2017年2期)2017-04-25
初中生世界·八年级(2017年3期)2017-03-24
中小企业管理与科技·上旬刊(2016年12期)2017-01-05
数码影像时代(2009年8期)2009-09-07
