
序决策信息系统中基于差别信息树的分配约简
2019-04-12 06:39张晓燕徐伟华
郑州大学学报(理学版) 2019年2期
杨 蕾,张晓燕,徐伟华
(1.重庆理工大学 理学院 重庆 400054;2.西南大学 数学与统计学院 重庆 400715)
0 引言
粗糙集理论是由波兰数学家Pawlak[1]提出的,它是一种用来处理不精确、不完全数据问题的一种理论,其研究的主要内容之一是属性约简(知识约简)[2-6].所谓属性约简,就是在保持知识库的数据分类能力不变的条件下,删除其中不相关或不重要的属性,从而达到减少冗余数据和简化规则的目的,实现了知识的简化.在Pawlak粗糙集的背景之下,不同的学者根据不同的约简思想,已经给出了不同的属性约简算法[7].文献[8]提出了基于差别矩阵的属性约简算法,因差别矩阵的直观简明性而受到了广大学者的关注.文献[9]给出了基于差别矩阵的Rough集属性约简算法以及属性约简的完备算法.文献[10]也给出了一种基于差别矩阵的属性约简完备算法.不仅如此,根据差别矩阵的不同定义,人们也提出了很多有效的关于属性约简的启发式算法,但是这些算法要想得到约简就必须用到差别矩阵中所有的非空元素.文献[8]指出,每一个信息系统对应的差别矩阵中所有非空元素的合取构成了该信息系统的属性约简集,由合取运算可知,差别矩阵的重复元素和父集元素在求取属性约简时起不到任何作用,但这些元素却占用了大量的存储空间,同时也增加了求取约简的时间.为了消除差别矩阵中重复元素的出现,文献[11]提出了一种新的差别矩阵存储方法,实现了差别矩阵的压缩储存.为了消除差别矩阵中冗余的父集元素,文献[12]给出了一种基于差别信息树的属性约简算法,该算法不仅能消除差别矩阵中的重复元素,而且在大多数情况下亦能消除父集元素的影响,实现对差别矩阵的压缩储存.
由于差别信息树是在等价关系下差别矩阵的基础上提出的,而等价关系下的差别矩阵是一个对称矩阵.因此,在求信息系统的约简时可以只用差别矩阵中的上三角元素或者只用下三角元素.当研究序信息系统时,因为由序信息系统得到的差别矩阵具有非对称性,所以基于差别信息树的属性约简并不一定适用于不协调序决策信息系统下的属性约简.本文在差别信息树的基础上提出了基于分配可辨识矩阵的差别信息树,给出了适用于不协调序决策信息系统的分配约简算法.
1 预备知识
定义1[13]设一个决策信息系统为四元组I=(U,AT∪DT,F,G),而三元组I=(U,AT,F)为信息系统,其中:U={x1,x2,…,xn}是有限对象集;AT={a1,a2,…,ap}是有限条件属性集;DT={d1,d2,…,dq}是有限决策属性集,且AT∩DT=∅;F={f|U→Va,a∈AT}是U与AT的关系集,Va为a的有限值域;G={g|U→Vd,d∈DT}是U与DT的关系集,Vd为d的有限值域.
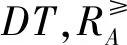
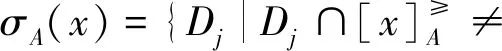

定义5[13]设I≥=(U,AT∪{d},F,G)为不协调序决策信息系统,记
⊂σAT(xj)},
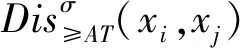
分配可辨识公式的极小析取范式中的所有合取式是不协调序决策信息系统的分配约简.
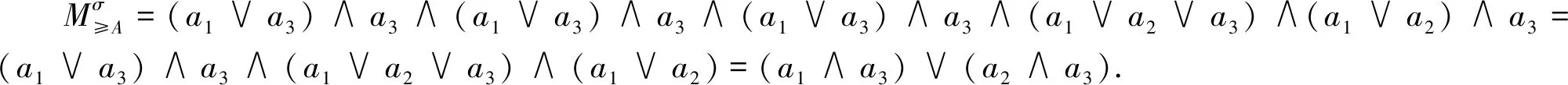
所以表1中不协调序决策信息系统的分配约简为{a1,a3}与{a2,a3}.
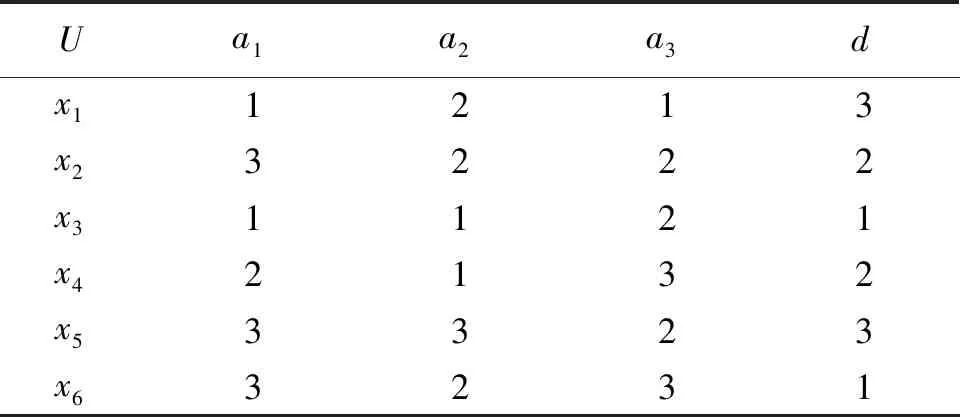
表1 一个不协调序决策信息系统Tab.1 An uncoordinated ordinal decision information system

表2 分配可辨识矩阵Tab.2 Assignment identifiable matrix
2 基于分配可辨识矩阵的差别信息树的设计与实现
定义7[12]差别信息树是一棵有序树,其中序体现在它的条件属性的顺序是一个从左到右的序列,其顺序不能更改或颠倒.
差别信息树的特征有以下几个方面:① 差别信息树的每个节点最多有|AT|个孩子节点,其中|AT|为带决策的信息系统中条件属性的个数.② 差别信息树的每个节点由前缀指针、后继指针、节点名、同名指针组合而成.其中前缀指针指向该节点的前缀节点(即父亲节点),后继指针指向该节点的后继节点(即孩子节点),节点名标记了该节点所对应的条件属性名,同名指针指向该差别信息树中与该节点具有相同节点名的其他路径中的节点.③ 差别信息树的子树同样是一棵有序树,其中条件属性的顺序同样不能更改或颠倒.
算法1序决策信息系统中基于分配可辨识矩阵的差别信息树的构建算法.
输入: 一个不协调序决策信息系统I≥=(U,AT∪{d},F,G);
输出: 该序决策信息系统所对应的差别信息树.
getDI-tree(decision tableI≥)
{
(1) 创建差别信息树的根节点TN,并令TN为null;

While(B≠∅)
{
A.选择B中最左边的元素为a;
B.if(TN所有子节点中存在属性名为a的子节点N)
{
如果N是一叶子节点,则采用不扩展路径策略,不构建B中剩余属性对应的节点;
如果a为B中最后一个元素,则采取删除子树策略,从差别信息树中删除以节点N为根的子树,但保留节点N;
否则令TN=N;
}
else
{
a) 创建一新节点N′,节点N′作为TN一子节点,同时初始N′的属性名为a,并通过该节点的同名指针连接到与该节点具有相同属性名的节点上,从而构成了一个同名属性节点链;
b) 令TN=N′;
}
C.令B⟸B-{a};
}
}
例2根据算法1及表2给出该序决策信息系统中基于分配可辨识矩阵的差别信息树的构建过程:
1) 创建序决策信息系统基于分配可辨识矩阵的差别信息树的根节点.根据分配可辨识矩阵中的每一个条件属性子集,将子集中的属性次序按序决策信息系统中条件属性从左到右的顺序排列.
2) 构建分配可辨识矩阵中第一个属性子集{a1,a3}所对应的路径〈a1,a3〉,将该路径插入到要构建的差别信息树中.
3) 根据可辨识矩阵中第二个属性子集{a3}创建另一条新的路径〈a3〉.
4) 对于第三个与第五个属性子集{a1,a3},因为它们与第一个属性子集完全相同,所以第三个与第五个属性子集{a1,a3}所对应的路径也映射到〈a1,a3〉上.
5) 同4),将第四个、第六个与第九个属性子集{a3}所对应的路径映射到〈a3〉上.
6) 对于第七个属性子集A={a1,a2,a3},创建另一条新的路径〈a1,a2,a3〉,它与属性{a1,a3}共享前缀〈a1〉.
7) 对于第八个属性子集{a1,a2},因为{a1,a2}⊂A,采用删除子树策略,从路径〈a1,a2,a3〉中删除a2之后的所有节点,即路径〈a1,a2,a3〉被修改为〈a1,a2〉.
图1给出了所构建的基于分配可辨识矩阵的差别信息树.在构建过程中采用不扩展路径策略以及删除子树策略,将相同的分配可辨识属性集映射到同一条路径中.将具有相同前缀的分配可辨识属性集{a1,a2}与{a1,a2,a3}映射到同一条路径〈a1,a2〉中.分配可辨识矩阵中属性集{a1,a2,a3}与{a1,a3}共享前缀〈a1〉,达到对分配可辨识矩阵的压缩储存,从而减少了构建基于分配可辨识矩阵的差别信息树的时空复杂度.

图1 基于分配可辨识矩阵的差别信息树Fig.1 Discernibility information tree based on assignment identifiable matrix
定理1基于分配可辨识矩阵的差别信息树中包括了能够获得不协调序决策信息系统的分配约简所需要的所有属性.
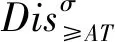
定理2基于分配可辨识矩阵的差别信息树中,所有只有一个节点的路径所对应的分配可辨识属性集,构成了该序决策信息系统中条件属性集的核cored(A).
证明由基于分配可辨识矩阵的差别信息树的构建过程可知:假设该信息树中某一节点的属性名为a,并且该树中存在某一条路径仅包含属性名为a的节点,则存在分配可辨识属性集{a}与该路径对应.在分配可辨识矩阵中,若a∈A且{a}为分配可辨识矩阵中的一个非空元素,则称a相对d在A中是必要的.A的所有必要属性的集合构成了A相对d的核,即cored(A).
定理3设R是基于分配可辨识矩阵的差别信息树中根节点的所有子节点所代表的条件属性集合,则σR(x)=σA(x)成立.
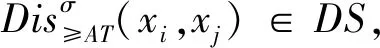
基于定理3,只要删除R中所有不必要的条件属性,就可以得到该序决策信息系统的一个完备约简.
给定一个不协调的带决策的序信息系统I≥=(U,A∪{d},F,G),如果该序信息系统中有|U|个对象以及|A|个条件属性,则在分配可辨识矩阵中最多可以得到|U|2个非空的条件属性的子集(即差别信息).假设分配可辨识矩阵中实际的非空条件属性的子集数为M(一般情况下M≪|U|2),由例2的构建过程可以看出,一棵差别信息树最多可以有M条不同的路径,并且每一条路径中最多可以有|A|个节点,所以一棵差别信息树中最多可以有M|A|个节点,又由于在基于分配可辨识矩阵的差别信息树中,许多路径都存在共享前缀,导致差别信息树中的实际节点数远小于M|A|.因此,在最坏的情况下,基于分配可辨识矩阵的差别信息树的空间复杂度为O(|A|*|U|2).
另外,在构建基于分配可辨识矩阵的差别信息树的过程中,向差别信息树中插入路径的次数最多为|U|2次,并且在构建路径的过程中最多比较并插入|A|个节点,删除Mi(其中i∈{1,2,…,|U|2})个节点.因此,基于分配可辨识矩阵的差别信息树的时间复杂度为|A|*|U|2+(M1+M2+…+M|U|2).已知在一棵差别信息树中最多可以有|A|*|U|2个节点,则M1+M2+…+M|U|2的值至多为|A|*|U|2.综上所述,基于分配可辨识矩阵的差别信息树的时间复杂度也为O(|A|*|U|2).
3 基于分配可辨识矩阵的差别信息树的分配约简算法
为了验证所提出的序决策信息系统中基于分配可辨识矩阵的差别信息树的有效性,算法2给出了基于该差别信息树的分配约简完备算法.
算法2序决策信息系统中基于分配可辨识矩阵的差别信息树的分配约简算法.
输入: 序决策信息系统中基于分配可辨识矩阵的差别信息树;
输出: 不协调序决策信息系统的一个分配约简.
Step1创建一个空集R.
Step2获取基于分配可辨识矩阵的差别信息树中只有一个节点的路径,将这些节点对应属性名放在一个集合R′ 中.
Step3如果R′≠∅,则对于∀a∈R′,在由分配可辨识矩阵得到的差别信息树中删除包含属性a的所有路径.
Step4令R⟸R′.
Step5如果由分配可辨识矩阵得到的差别信息树中只含有根节点,则转Step 7.
Step6在由分配可辨识矩阵得到的差别信息树中,选择根节点最右边的子节点,假设该子节点为b,令R⟸R∪{b},并从由分配可辨识矩阵得到的差别信息树中删除含有节点{b}的路径,转Step 5.
Step7输出R,算法结束.
例3基于图1,算法2的求解过程如下:
1) 创建一个空集R.
2) 从基于分配可辨识矩阵的差别信息树中获取只含有一个节点的路径〈a3〉,令R⟸{a3},然后删除信息树中含有属性名为a3的全部路径.
3) 此时基于分配可辨识矩阵的差别信息树中仅含有一条路径〈a1,a2〉,选取根节点最右边的子节点a1,令R⟸R∪{a1},然后删除信息树中含有属性名为a1的全部路径.
4) 此时图1给出的基于分配可辨识矩阵的差别信息树只剩下根节点,输出R⟸{a3,a1},算法结束.因而{a3,a1}即为通过基于分配可辨识矩阵的差别信息树所求得的一个约简.

4 结论
在差别信息树的基础上提出了一种能压缩储存分配可辨识矩阵的数据结构,即基于分配可辨识矩阵的差别信息树.和直接通过分配可辨识公式的极小析取范式求分配约简相比,通过该差别信息树可以大大缩短求取不协调序信息系统的分配约简的时空复杂度.但是从基于分配可辨识矩阵的构建过程可知,将分配可辨识属性集插入到差别信息树中用到的条件属性的顺序是决策表中属性的原始顺序,没有考虑属性重要度以及核属性对基于分配可辨识矩阵的差别信息树在构建过程中的影响,并且通过该差别信息树只能得到决策表的一个约简.下一步的工作是结合属性重要度以及核属性来完善该差别信息树的构建,看能否实现对分配可辨识矩阵的进一步压缩储存.
猜你喜欢
哈尔滨轴承(2022年1期)2022-05-23
洛阳师范学院学报(2021年2期)2021-03-31
航空发动机(2020年3期)2020-07-24
小型微型计算机系统(2019年9期)2019-09-09
汉语世界(The World of Chinese)(2019年3期)2019-07-01
数学大王·趣味逻辑(2019年5期)2019-06-13
计算机与生活(2019年3期)2019-04-18
电子制作(2018年11期)2018-08-04
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
消费导刊(2017年20期)2018-01-03
