
基于共享表示的跨领域中文模糊限制语识别
2019-04-12 06:22周惠巍宁时贤杨云龙林英玉李思嘉
郑州大学学报(理学版) 2019年2期
周惠巍,宁时贤,杨云龙,刘 壮,林英玉,李思嘉
(1.大连理工大学 计算机科学与技术学院 辽宁 大连 116024;2.台湾逢甲大学 资讯电机学院 台湾 台中 40743)
0 引言
模糊语言是一种常见的语言现象,模糊限制语(hedges)用来指“把一些事情弄得模模糊糊的词语”,表示不确定性的观点[1].由模糊限制语所引导的信息称为模糊限制信息.2010年国际计算语言学协会将模糊限制信息检测定为CoNLL(conference on computational natural language learning)共享任务[2],极大促进了英文模糊限制语的识别研究.
中文模糊限制语在不同领域中的作用存在差异.传统的机器学习方法假设训练数据和测试数据分布相同.但是由于中文模糊限制语存在领域特性,使得现有的基于某个领域训练得到的识别模型很难直接应用于其他领域.同时,中文模糊限制语语料缺乏,语料标注费时费力,为每个领域都标注大量训练语料是不现实的.文献[3]指出可以利用资源丰富的领域(源领域)的模糊限制语语料,辅助资源贫乏的领域(目标领域)的模糊限制语的识别,从而减少目标领域的数据标注代价.
早期的模糊限制语识别是基于词典匹配的方法,该方法取得了较高的召回率,但是精确率却很低.机器学习的方法弥补了这个缺点.基于分类的passive aggressive方法在新闻领域获得了70.53%的模糊限制性句子识别F值[4].基于序列标注方法识别中文模糊限制语,在构建的《计算机学报》语料上获得43.2%的F值[5].在科技文献、股市和产品评论3个领域,构建基于特征的序列标注模型,分别获得73.27%、70.29%和68.57%的F值[6].
上述模糊限制语识别方法的训练数据和测试数据均采用同领域的语料,即假定训练数据与测试数据具有相同的分布.然而,模糊限制语的使用具有领域特性.文献[3]将迁移学习用于跨领域英文模糊限制语识别.当训练数据与测试数据分布不一致时,迁移学习能够在不增加标注成本的情况下,提高系统在测试数据中的检测性能.迁移学习主要分为两种:基于特征的迁移学习[7]和基于实例的迁移学习[8].文献[7]的特征迁移算法FruDA引入源领域和目标领域的公共特征,实现源领域知识向目标领域的迁移.文献[8]的实例迁移学习算法TrAdaBoost通过迭代,调整源领域与目标领域训练样例的权重,从而挑选出与目标领域数据分布相似的源领域训练样例.
近年来,随着深度学习的兴起,神经网络被用于领域间共享特征表示的学习,并取得了较好的结果.文献[9]利用两种语言间拼写的相似之处,学习两种语言的共享字符表示,同时学习各语言的私有词表示,用于跨语言序列标注任务.文献[9]共享字符表示学习方法,难以学习到没有共同字符的两种语言间的共享特征.为了克服这一问题,文献[10]采用一个共享的BLSTM(bidirectional long short-term memory)模块和多个语言特定的私有BLSTM模块分别学习多语言间的共享表示和各语言的私有表示.同时,在共享BLSTM模块中引入了对抗学习,使得共享模块变得与语言无关,从而获得不含有私有特征的更纯净的共享表示.文献[11]利用多个中文分词语料库学习共享表示,并引入对抗训练方法抽取不同分词标准间的共享特征,有效提高在各个语料上的分词性能.
本文研究跨领域中文模糊限制语的识别,针对目标领域训练数据非常稀少的情况(仅200个标注样例),提出一种基于共享表示的跨领域中文模糊限制语识别方法.训练时,利用源领域大量标注数据和目标领域少量标注数据,交替学习各个领域的数据;同时引入对抗训练[12]获得更纯净的共享表示.本文提出的方法能够有效利用源领域和目标领域信息,取得了比传统的迁移学习方法更好的跨领域识别性能.
1 基于共享表示的跨领域中文模糊限制语识别模型
文献[11]提出融合对抗训练的共享-私有模型,本文称其为Sh-pri模型.我们借鉴文献[11]的方法,基于跨领域中文模糊限制语识别的实际问题,提出一种共享-对抗(Sh-adv)模型,用于跨领域模糊限制语识别,如图1所示.
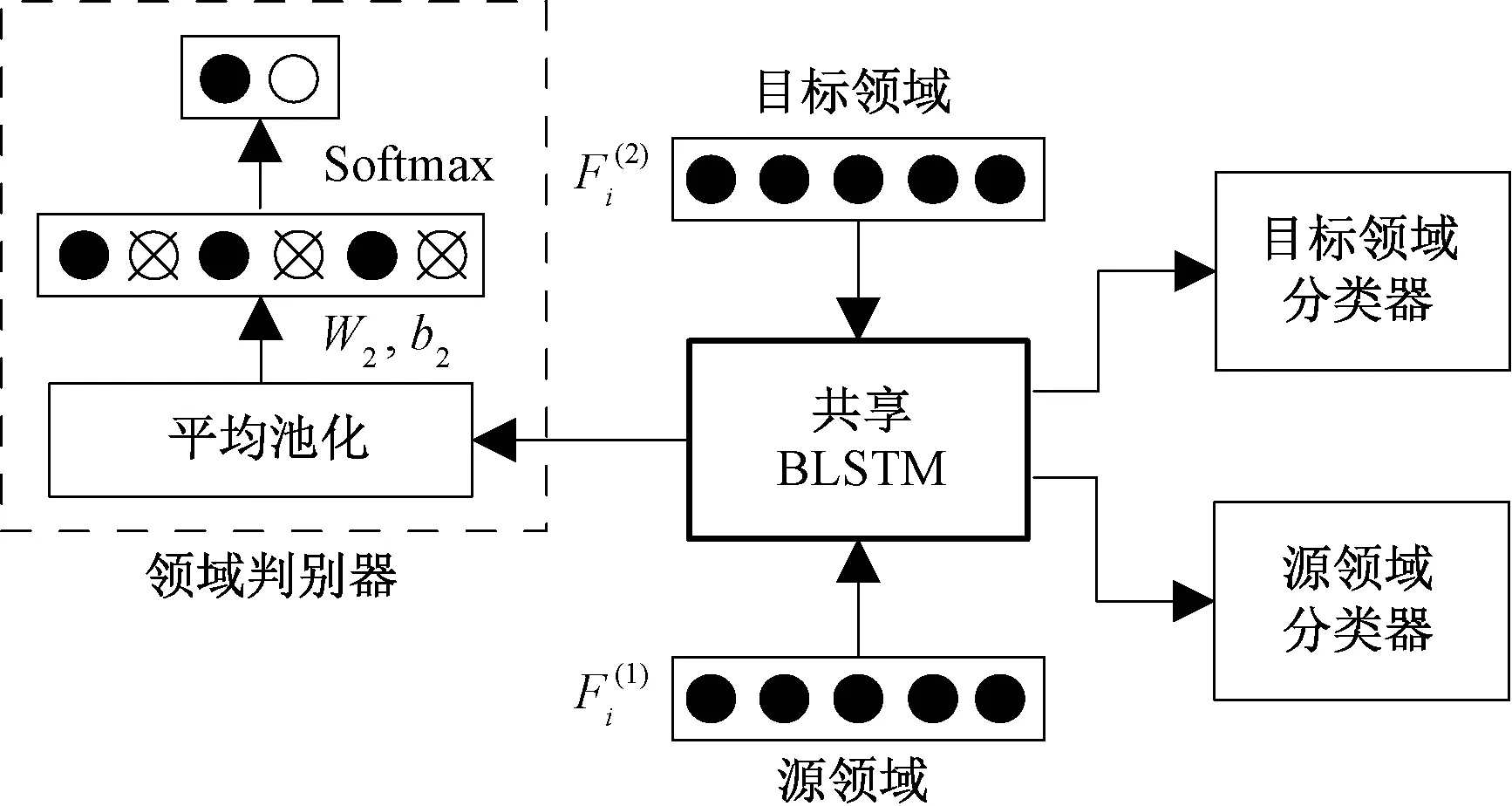
图1 共享-对抗模型Fig.1 The architecture of Sh-adv model
两个模型均采用了共享表示学习和对抗训练的思想,利用共享BLSTM模块学习源领域和目标领域间的共享语义表示.Sh-pri模型在学习共享语义表示的同时,学习了各领域私有语义表示.Sh-adv模型未学习私有语义表示,而是直接引入领域判别器模块,与共享BLSTM进行对抗训练,获得剥离领域私有特征的更纯净的共享表示.因为本文假设目标领域训练数据极其稀少(仅200个标注样例),在整体模型中引入私有BLSTM模块无法充分学习到目标领域的私有语义表示.而源领域训练数据远远大于目标领域,共享语义表示可能受到私有语义表示的影响,降低目标领域的模糊限制语识别性能.
1.1 数据处理及特征抽取
1.2 共享-对抗(Sh-adv)模型

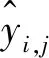
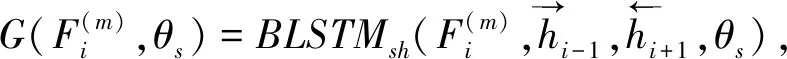
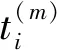
2 实验结果与分析
2.1 实验数据及设置
实验采用文献[14]构建的中文模糊限制语语料库(https:∥github.com/DUT-NLP/CHScope),包含维基百科、生物医学文献的实验结果、摘要和讨论4部分语料,共24 414句,约100万词.各部分模糊限制语的个数分别是1 958、1 622、2 759和4 674.维基百科中,33.78%的句子包含模糊限制信息;生物医学文献中,实验结果中27.8%的句子、摘要中25.28%的句子和讨论中47.69%的句子包含模糊限制信息.为检测维基百科和生物医学两个领域间的跨领域中文模糊限制语识别性能,共设置了6组实验,如表1所示.

表1 实验设置Tab.1 Experiment setup
为减小偶然性,每组数据进行实验时,我们都做了五折交叉实验,将目标领域数据平均分为5份,取每份中的200个实例作为训练数据,其余4份作为测试数据.实验采用F值对模型进行评价,公式为
F=2PR/(P+R),
其中:P表示准确率;R表示召回率.
我们从万方数据库下载了6.19 MB的生物医学文献摘要和106 MB的中文维基百科语料库,加上实验所用的4.16 MB语料,共计117 MB的语料用于训练词向量.采用Word2vec工具训练词向量.词性向量和共现特征向量均为随机初始化,通过模型训练进行调整.词向量、词性向量和共现特征向量分别是100维、50维和10维.模型采用随机梯度下降策略进行参数更新,对抗学习的权重系数λ=0.05.
2.2 基线方法
为了探知共享表示对跨领域中文模糊限制语识别的影响,我们比较了下列4种基线方法,分别是:线形核函数的支持向量机SVM,单层的无共享机制的双向长短期记忆神经网络BLSTM_NO,以及两种性能优异的迁移学习的方法:FruDA[7]特征迁移学习和TrAdaBoost[8]实例迁移学习.基线方法使用Target Only(TO)、Source Only(SO)、Target+Source(T+S)3种数据形式.
Target Only(TO):仅使用目标领域的200个标注数据训练获得识别模型.
Source Only(SO):仅使用源领域的标注数据训练获得识别模型.
Target+Source(T+S):同时使用TO数据和SO数据训练获得识别模型.
测试时,模型对目标领域测试数据进行检测.另外,FruDA和TrAdaBoost方法使用T+S数据进行训练,所用的特征与本文其他方法相同,参数设置全部采用默认值.4种基线方法在6组实验的平均F值如表2所示.
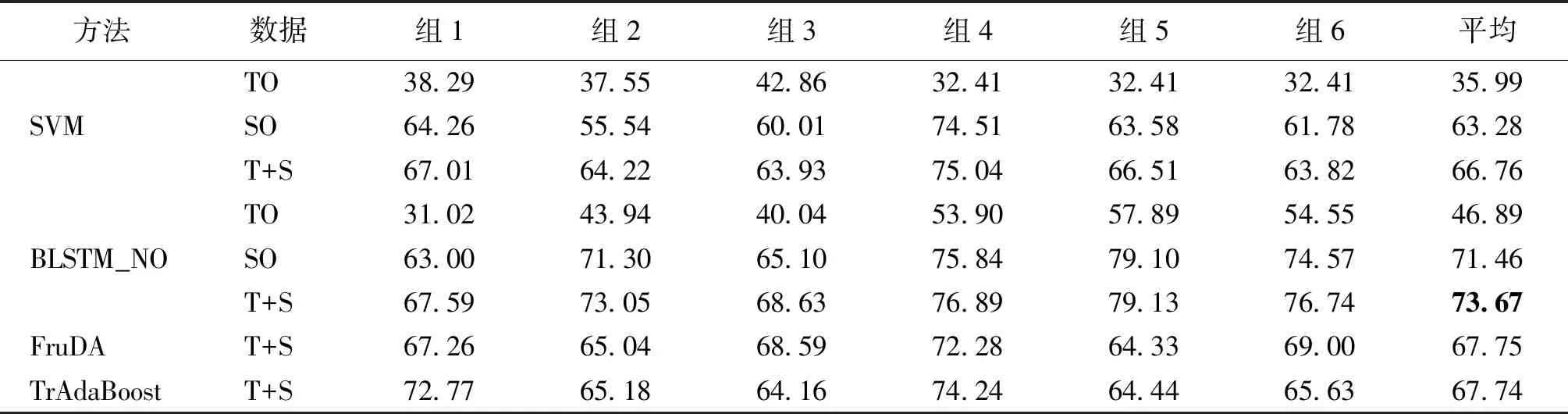
表2 基线方法的跨领域中文模糊限制语识别F值Tab.2 F-value of cross-domain Chinese hedge cue detection by baseline methods %
注:黑体表示F值的最高平均值.
从表2的实验结果可以看出:1) TO数据的实验结果最差,SO数据有较大提升,T+S数据表现最佳.说明使用源领域数据辅助学习能够获得两个领域间相似的数据分布,为生物医学领域和维基百科领域的数据迁移提供了可行性;2) FruDA方法和TrAdaBoost方法在T+S数据的平均识别结果均低于BLSTM_NO方法,说明BLSTM模型能够更好地学习深层语义信息,帮助模型进行跨领域的模糊限制语识别.
2.3 共享表示方法
表3比较了Sh-pri模型和我们提出的Sh-adv模型在6组跨领域中文模糊限制语识别实验的F值.另外为验证共享表示方法中判别器的效果,我们去掉了Sh-pri模型和Sh-adv模型中的判别器模块,进行了Sh-pri-only和Sh-only模型的实验.

表3 共享表示方法的跨领域中文模糊限制语识别F值Tab.3 F-value of cross-domain Chinese hedge cue detection by shared representation methods %
注:黑体表示F值的最高平均值.
从表3可以看出共享表示方法均好于基线方法,说明共享表示在跨领域中文模糊限制语识别中的有效性.另外,比起带有私有语义表示学习模块的Sh-pri模型和Sh-pri-only模型,仅使用共享语义表示的Sh-adv模型和Sh-only模型的识别性能更好.在目标领域训练数据量稀少的情况下,很难学习获得目标领域的私有语义表示.同时,在整体模型训练中引入源领域私有语义表示学习,会影响目标领域的模糊限制语识别性能.相反从不同领域间抽取共性特征能够更好地实现跨领域模糊限制语识别.在融合对抗训练后,Sh-adv模型取得了模糊限制语识别实验75.43%的最高平均F值(表3中黑体表示),均好于其无对抗训练的模型.但是对抗机制所带来的提升并不明显,其主要原因可能是共享模块试图通过共享参数来保持共有特征的不变,然而目标领域训练数据太少,无法使得私有特征完全从共享表示中剥离,也就无法获得更纯净的源领域和目标领域共享表示.
3 结论与展望
本文提出了一种基于共享表示的跨领域中文模糊限制语识别方法.通过大量的源领域训练数据和少量的目标领域训练数据(200个),利用对抗学习策略学习源领域和目标领域间的共享语义表示.在生物医学和维基百科领域的实验中,共享表示方法取得了较好的跨领域中文模糊限制语识别性能.本文仅研究了两个领域间的跨领域中文模糊限制识别,如何利用多个源领域的数据,辅助目标领域的模糊限制语识别,是本文下一步的主要研究工作.
猜你喜欢
军事文摘(2022年17期)2022-09-24
北京航空航天大学学报(2022年8期)2022-08-31
家庭影院技术(2021年8期)2021-11-02
厦门大学学报(自然科学版)(2021年4期)2021-06-22
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
计算机应用与软件(2018年9期)2018-09-26
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
