
基于序列注意力机制的卷积神经网络异常检测
2019-04-12 06:38王国胤李智星王化明姚钟毓梁馨元
郑州大学学报(理学版) 2019年2期
李 苑,王国胤,李智星,王化明,周 政,姚钟毓,梁馨元
(重庆邮电大学 计算机科学与技术学院 计算智能重庆市重点实验室 重庆 400065)
0 引言
互联网为人们提供了优质的工作与生活环境,但同时也给人们带来了一定的安全隐患.WordPress SEO by Yoast插件在2015年被曝出有高危的SQL注入漏洞,该漏洞导致了大量敏感信息的泄露.2016年,2.7亿的Gmail、Yahoo和Hotmail账号遭到泄露,黑客将窃取得到的数据进行交易.2017年,GitHub企业版被曝出具有SQL注入漏洞,本次漏洞的产生是由文件中内置的对象关系映射造成的.
为了解决这些攻击造成的威胁,越来越多的学者在网络异常检测这一领域开展了科学研究.文献[1]指出大多数的攻击是通过恶意的统一资源定位符(unified resource locator,URL)所发出的请求造成的.Vishnu等人[2]采用机器学习方法如贝叶斯、支持向量机等来预测跨站脚本攻击(XSS攻击).文献[3]利用人工审核的方式对一些PHP源代码进行分类.然而,现存的这些方法在研究的过程中大多数是使用人工特征工程进行的,因此它们仍然有一些问题亟待解决.首先,人工选择特征和一些先验知识的方式是无法适应网络的迅猛发展和极速演变的.例如在MySQL 5.0之后的版本中,/*!50000 select */中的select会被当作是一个关键字来被执行,而在MySQL 5.0以前的版本中,select是被当作注释而不被执行的.其次,恶意代码通常是隐藏在攻击者发出的看似正常的请求中,但是现有的大多数基于机器学习的研究方法只能识别并判断出这些网络请求是否为异常,但无法对异常请求中的恶意代码区域进行定位.例如URL中/search.html?kw=../../../../winnt/win.ini $%$00.htm.它包含的“../”这一小部分是用于尝试访问敏感系统文件路径的.
文献[4]在短文本分类任务的研究工作中使用卷积神经网络进行文本分类.文献[5]尝试使用聚类、主成分分析和关联规则挖掘对日志进行分析来检测网络中的异常情况.随着深度学习的迅猛发展,深度学习也被应用于异常检测中.文献[6]将3个神经网络组合进而对URL进行分类检测,他们首先使用第1个神经网络生成一些URL,随后利用第2个神经网络来对其进行分类,最后利用第3个神经网络来检验给定的URL是否为恶意的URL.文献[7]提出了DeepLog方法,该方法结合深度学习,可以从日志本身正常执行的数据中进行学习,得到相应的日志模式.面对复杂且多变的网络环境,我们需要能够有效监测未知攻击的方法.
Conneau[8]提出一个新的VD-CNN方法,该方法可以随着网络层深度的增加,利用小规模的卷积神经网络和池化操作来完成文本分类的工作.卷积神经网络能够进行特征自学习,可以有效地避免人工特征工程所带来的弊端[9],但是这些方法无法对恶意代码片段进行定位.神经网络中的注意力机制最初是起源于人类的视觉注意力机制[10],目前注意力机制被成功地应用于很多任务中,例如阅读理解[11]、摘要总结[12]和句子表示[13]等.Xu等人[14]提出了将卷积神经网络与长短期记忆网络(long-short term memory,LSTM)相结合使用的方法.
LIRL与文本均是由字符序列组成,并且包含语义信息,因此本文考虑将恶意URL检测任务转化成为一个文本分类任务,提出了一种基于序列注意力机制的卷积神经网络(sequential attention based CNN,SA-CNN).为了能够有效地寻找到恶意代码区域,我们在卷积层与池化层中间引入一个新的注意力层.注意力层用来对单词(token)的区分度进行编码.因为恶意代码通常是由较小区域内的相邻单词构成,所以这些相邻的单词之间往往又具有一些相似的区分度.因此,本文在注意力层又增加了一个外部语言模型,来对这些较小区域内的相邻单词进行建模分析.
1 基于序列注意力机制的卷积神经网络模型
进行网页浏览和网络服务调用都需要使用到URL,因此很多攻击者选择了URL作为攻击的入口.受文献[4]的启发,本文提出一种全新的异常检测方法:基于序列注意力机制的卷积神经网络模型.
1.1 问题定义
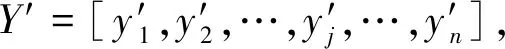
1.2 方法概述
区别于文献[4,15]中的网络结构,SA-CNN模型的结构框架如图1所示.它是由5层网络结构组成,分别为词嵌入层、卷积层、注意力层、池化层和全连接层,其中还包括了一个特殊的注意力层.
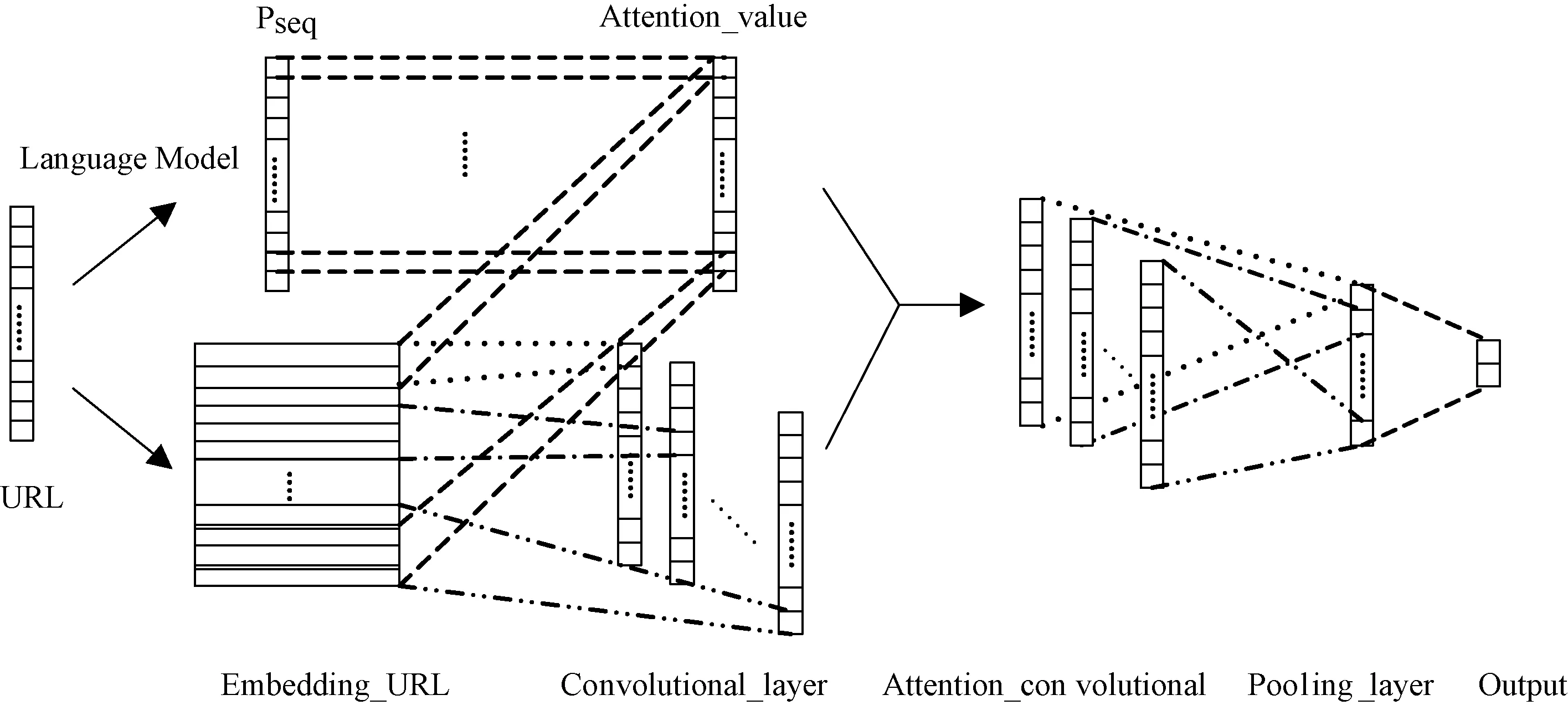
图1 SA-CNN结构框架Fig.1 The framework of SA-CNN
1.3 具体结构介绍
1.3.1URL预处理 通常情况下,URL是由一个字符序列构成的.本文定义了一组特殊字符,并使用它们作为划分URL的依据.利用空格对其分割,这些特殊字符集合为{() [ ] | @ + -=: /;,^ <>* ! ? { } # &.“”’ %}.根据这些特殊字符,所有的URL可以被划分为一系列的单词(token).我们以一条真实的URL解释token划分方式和char划分方式的区别.
原始URL: /account/?action=file:∥/etc/passwd.
token划分: / account / ? action=file: / / / etc / passwd.
char划分: / a c c o u n t / ? a c t i o n=f i l e: / / / e t c / p a s s w d.
char划分方式比较简单,它将一些具有意义的字符串拆开了,比如“file”、“etc”、“passwd”.但是token划分方式并未将这些字符分割开,保持了这些字符的连续性.
1.3.2词嵌入层 为方便计算,集合当中的每一条URL,即xi可以通过谷歌研发的word2vec模型[16]将单词转换为词向量,即xi=[v1,v2,…,vk,…].本文所提出的SA-CNN采用的是word2vec中的CBOW模型.将训练得到的词向量作为下一层的输入.
1.3.3卷积层 卷积层接受词嵌入层的词向量作为输入.一个卷积层中可以包含多个大小不同的滑动窗口.使用这些滑动窗口来提取特征并且以此方式来防止过拟合.每一个滑动窗口对应着一个卷积滤波器.H=[h1,h2,…,hk,…]表示的是不同大小的卷积滤波器.我们重新定义了一个连接符号⊕的操作,v1,k:m,k=v1,k⊕v2,k…⊕vm,k.假定卷积滤波器f,对应的滑动窗口大小为h,在xi中第k个特征是通过ci,k=Wf·(vi,k⊕vi,k+1⊕…⊕vi,k+h-1)+bf产生.将所有的特征连接起来,可以得到一个特征图ci=[ci,1⊕ci,2⊕…].
1.3.4注意力层 本文采用上下文注意力机制和语言模型(LSTM/ Markov)相结合的方式来进行异常检测.注意力层位于卷积层与池化层之间.该模型可以给恶意代码区域赋予更高的注意力值,以便于能够有较大的可能性被池化层选择处理,以备后续异常检测使用.本文尝试对当前单词的3个上下文(SA-CNN-3)和5个上下文(SA-CNN-5)使用序列注意力机制.此处以3个上下文为例说明注意力层的工作原理.
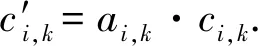
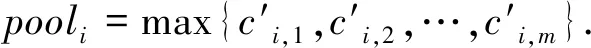
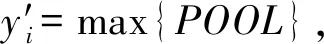
2 实验
2.1 实验数据
为了验证本文所提出的SA-CNN模型的有效性,我们在TREC、20NG这两个公开短文数据集上和一个URL数据集上进行实验.其中,URL数据集来自于知名互联网安全公司,数据集信息总结如表1所示(其中CN表示类别的数量).

表1 数据集信息汇总Tab.1 Summary of datasets 个
TREC[18]数据集是一个问题分类的数据集,它主要包含人、地点、数字等6个类别的问题.20NG数据集是著名的文本分类数据集,本文从中选取了每个文档的Subject这一项作为短文本分类的数据进行分析实验.URL数据集是由正常的URL和本地文件包含、SQL注入、跨站脚本攻击和命令注入攻击这4种攻击类型共同组成.
2.2 参数设置
词嵌入的大小设定为128,卷积层使用的是多卷积核方式,卷积滤波器大小分别为3、4、5,且每种滤波器个数为64个.批处理大小设定为32,epoch的数目设为200,采用dropout技术以防止过拟合产生.
2.3 实验结果与分析
SA-CNN与原始CNN[4]方法在URL数据集上效果基本持平;SA-CNN优于机器学习方法中的DT和LR的效果.本文所提出的SA-CNN可以很好地定位恶意代码区域,并对其进行可视化展示,在该方面SA-CNN要远远优于原始CNN[4]方法.
2.3.1token划分和char划分 图2所示为原始CNN[4]和SA-CNN3(LSTM)在URL数据集上的实验结果.由于恶意URL在通常情况下仅仅是URL当中的一小部分,而如果此时采用accuracy作为评估指标并不适用,因此本文采用F1对URL的实验结果进行评估.我们可以看到,使用token划分方式的结果要优于使用char划分方式的结果.这说明对URL检测时,使用token划分的方式是行之有效的.相比于原始CNN[4]方法,SA-CNN在F1评估指标[19]下没有表现出较大的优势,可能是原始的CNN[4]本身的性能就很高,极难对其进行改进.
表2所示是SA-CNN在两个短文本数据集上的实验结果, 表明SA-CNN的性能要优于原始CNN方法[4].

图2 恶意URL数据的F1结果Fig.2 TheF1on malicious URLs data
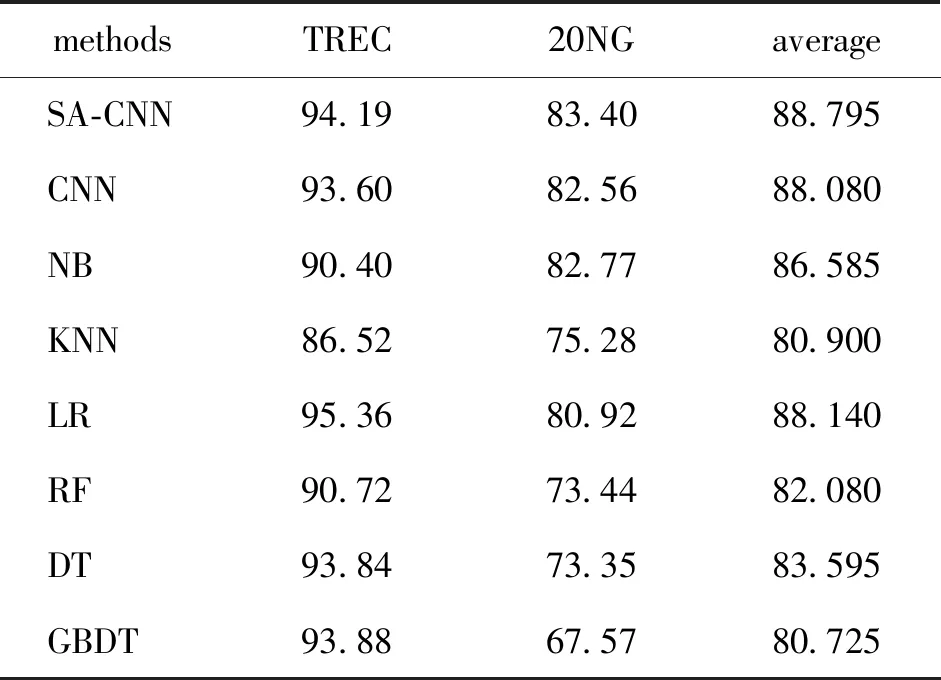
表2 在TREC和20NG上的实验结果Tab.2 Accuracies on TREC and 20NG %
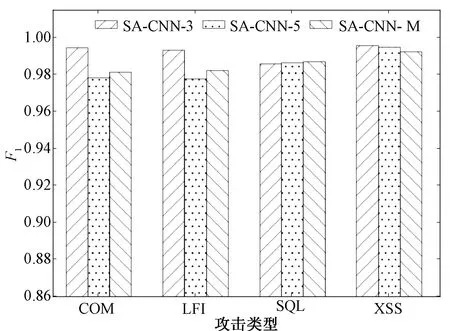
图3 SA-CNN 3种结构token划分结果Fig.3 The result of three stuctures on token division
我们也使用贝叶斯、逻辑斯特回归、KNN、GBDT等方法在TREC和20NG数据集上进行实验对比.相比于这些机器学习的方法,SA-CNN表现出更好的性能.这说明序列注意力机制不仅在URL数据集上有效果,同样在短文本数据集上也有良好的表现.
2.3.2LSTM模型和Markov模型 针对SA-CNN模型本身,本文也进行了相关研究和实验.图3为SA-CNN在token划分方式下分别使用LSTM和Markov语言模型在URL数据集上的实验结果.从图3中可知,SA-CNN-3(LSTM)更加适合使用token划分方式进行异常检测,它的F1值远高于SA-CNN-5(LSTM)和SA-CNN-3(Markov).考虑到URL的长度限制和单词之间的相关性,URL检测任务推荐使用SA-CNN-3(LSTM).
2.3.3上下文长度影响 表3所示SA-CNN在两个短文本数据集上的实验结果,TREC数据集的平均长度为10,20NG的平均长度为5.我们由表3可以观察到,SA-CNN-5(LSTM)在TREC数据上的表现优于其他的方式,因此文本的平均长度对于模型选择是具有一定影响的.
结合上文所述的token划分方式,影响URL异常检测的结果除了划分方式以外,URL的长度也是一个可能的原因.当URL的长度较短时,我们可以考虑使用SA-CNN-3(LSTM)来进行异常检测.通过研究SA-CNN本身,我们可知SA-CNN-3(LSTM)和SA-CNN-5(LSTM)更适用于长度稍长的URL数据检测,并且两个模型可以达到较好的检测效果.当URL长度较短时,URL本身也并不能为异常检测提供较多的信息,因此也限制了模型对其进行检测的效果.所以不论是在异常检测上,还是在文本分类问题上,我们都需要对文本的长度进行考虑,随后再选择合适的模型进行尝试.
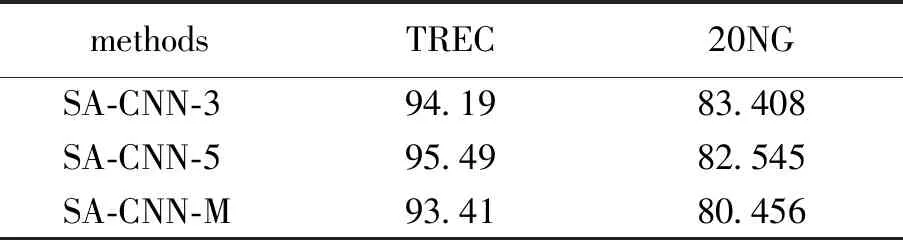
表3 TREC和20NG的结果Tab.3 The result of TREC and 20NG %
2.3.4可视化结果分析 为了简单起见,本文提供了一些具体例子来更加直观地说明结果.如图4所示,颜色越深,则表示注意力的值越高.通过比较颜色深浅,我们可以很容易知道哪些部分是恶意代码区域.如图中第2条所示,本地包含文件攻击尝试通过代码“../”访问服务器上的敏感文件.在第3条中的char(106)则是测试服务器是否可以执行SQL函数的语句.由于passwd、script、 (;)和passw都是恶意的URL中具有攻击性的部分,所以它们都具有很高的注意力值.而html 和 com11的注意力值较为低,因为它们是正常代码区域中的一部分.有一个很有趣的事实是:当“.”这个token位于正常的URL中时,它具有较低的注意力值,此时它的周围是oo4xccc和html,恶意代码区域的“.”则具有很高的注意力值.而此时,它的上下文是“/”和“./”.这也就是说由外部的语言模型(LSTM/Markov)所产生的上下文信息是有效且有意义的.

图4 中文图题恶意URL注意力值可视化结果Fig.4 Visualization of attention on malicious URLs
3 总结
本文提出了一种基于序列注意力机制的卷积神经网络(SA-CNN)来检测恶意URL.该方法不仅可以检测URL是否为正常的,同时也可以帮助定位恶意代码区域.在真实的URL数据集上的实验表明:(1) 本文所提出的划分URL的方式是行之有效的.(2) SA-CNN具有极高的检测率,同时可以成功定位恶意代码区域.(3) SA-CNN在短文分类任务中也是一个有效的方法.在未来的工作中,我们的研究将主要集中于两个方面:首先,尝试对更多类型的攻击进行检测;其次是基于词汇和注意力方面的研究.我们将针对如何对URL划分进行探索,该划分能使它的每一块具有全部功能的信息,而不是每块只具有单独的关键词.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
计算机研究与发展(2022年1期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
计算机应用(2020年12期)2020-12-31
甘肃教育(2020年22期)2020-04-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
文苑(2015年9期)2015-09-10
