
基于情绪图标的弱监督情绪分类
2019-04-12 06:40:42李寿山
郑州大学学报(理学版) 2019年2期
张 璐,王 路,李寿山
(苏州大学 自然语言处理实验室 江苏 苏州 215006)
0 引言
情绪分析是自然语言处理领域的一个研究热点,通过分析人们发布的文本推测他们的主观感受.情绪分类是情绪分析的基本任务,旨在判断文本表达的情绪类别,例如高兴、生气等.随着社交媒体的迅速发展,情绪分类得到了越来越多的关注.在过去十年里,情绪分类已经被应用在一系列现实场景中,例如股票市场、在线聊天和新闻分类等[1-3].
在以往的研究中,传统的情绪分类方法主要着眼于监督学习方法,这些方法需要充足的标注样本来训练模型.但在很多场景下,标注样本有限,并且获得大量标注样本需要极大的成本.
在社交媒体中,有很多样本包含情绪图标,而这些情绪图标有时包含明确的情绪信息.
利用自动标注样本最直接的方式是将它们和人工标注样本混合,扩大标注样本的数量.简单混合不是个好选择,因为自动标注样本中会存在不少噪声,甚至错误标注样本.例如,例2和例3包含了相同的情绪图标却表达了相反的情绪.通常来说,自动标注样本的数量远远大于人工标注样本的数量,简单混合可能会由于噪音而影响人工标注样本的性能.所以,我们需要一个更好的模型从另一个角度来利用人工标注样本.
本文提出了一种基于少量人工标注样本和大量含有情绪图标的自动标注样本的弱监督学习方法.不同于简单混合两类样本,我们提出了一种联合学习方法Aux-LSTM.具体而言,我们将基于自动标注样本和人工标注样本的两个情绪分类任务分别看作主任务和辅助任务.主任务通过辅助任务的共享LSTM层获得主任务的辅助表示,将此辅助表示加入到主任务中进行联合学习.实验结果表明,本文提出的联合学习方法远优于混合方法.
1 相关工作
文本情感分析通常包含情感分析[4-5]和情绪分析[6-7].迄今为止,已经有很多关于情绪分析的研究工作[7-13],本文主要研究情绪分类问题.
早期的一些情绪分类研究利用规则来决定情绪类别,例如Kozareva等[14]首先采用统计方法利用上下文词语与情绪关键词的共现关系对文本进行情绪分类.自此以后,大多数情绪分类研究都采用基于机器学习的方法.这些基于机器学习的方法大体上可以被分为两类:监督学习方法和半监督学习方法.
监督学习方法将情绪分类当作一个监督学习问题,利用标注样本使用不同的特征训练一个分类器[3,15-19].半监督学习方法将情绪分类当作一个半监督学习问题,利用少量标注样本和大量未标注样本训练一个分类器.与有监督的情绪分类相比,与半监督情绪分类有关的研究比较少.Liu等[3]提出了一种协同学习算法,利用未标注数据中的信息提升情绪分类的性能.Li等[10]提出了一个双视图标签传播算法,将源文本和回复文本分别看作两个视图.
本文属于半监督情绪分类,与已有的半监督情绪分类方法相比,本文强调了社交网络中情绪图标的重要性,并通过一种联合学习的方式加以利用.文献[11]提出了一个类似的方法,利用情绪关键词从网络上获得大量样本,并将这些样本作为自动标注数据训练一个粗粒度情绪分类系统.但是,这种方法并没有考虑人工标注样本和自动标注样本同时出现的情况.实验结果表明同时利用人工标注样本和自动标注样本比仅仅利用自动标注样本的效果更好.
2 语料库构建和分析
2.1 人工标注样本
数据来自新浪微博,我们使用Huang等[20]的标注体系,一共标注了2 953条微博.表1展示了7种情绪类别的样本分布,很显然,分布相当不平衡.大约有1/3的样本属于高兴类别,而只有1%的样本表示恐惧.
本文关注粗粒度的情绪分类,所有的情绪类别被映射成了两个基本类别,即正面情绪和负面情绪.如表2所示,我们忽略了中性情绪,并将剩余的6类情绪映射为正面情绪和负面情绪.表3展示了经过映射以后各个类别的样本分布情况.

表1 每种情绪类别的样本分布Tab.1 The number of sentences in each emotion category

表2 情绪间的映射关系Tab.2 Mapping relationships between emotions
2.2 自动标注样本
我们利用情绪图标来获得大量自动标注样本.表4展示了正面和负面情绪类别中情绪图标的数量以及一些例子.如果一条微博中包含的正面(负面)情绪图标数目多于负面(正面)情绪图标数目,那么它就会被标注成正面(负面)情绪.以这种方式,我们可以快速获得超过100 000条自动标注样本.
3 方法
本节主要介绍我们提出的联合学习方法Aux-LSTM,同时利用人工标注样本和自动标注样本进行情绪分类.

表3 经过映射后每种情绪类的样本分布Tab.3 The number of sentences in each emotion category after mapping

表4 每种情绪类别中情绪图标的数目Tab.4 The numbers of emotions in each emotion category
3.1 基于LSTM的情绪分类方法
首先,我们用T表示输入,经过LSTM[21]层得到新的表示h,
h=LSTM(T).
接着,将LSTM层的输出连接到全连接层:h*=dense(h)=φ(θTh+b),其中:φ是非线性激活函数,这里使用Relu,h*表示全连接层的输出,θ和b分别代表权重和偏置.
然后,为了防止过拟合,我们采用了dropout层,公式为:hd=h*·D(p*),其中:D表示dropout操作,p*表示dropout的概率,hd表示dropout层输出.
最后,我们使用sigmoid层给出预测概率,公式为:p=sigmoid(Wdhd+bd),其中:p表示情绪类别的预测概率,Wd表示需要学习的权重矩阵,bd表示偏置.
我们的情绪分类模型通过最小化交叉熵损失函数来优化,具体公式为:
其中:loss表示情绪分类的损失函数;m是样本数目;k是情绪类别数;yij表示第i个样本属于第j个类别;pij代表对应的预测概率.
3.2 基于联合学习的情绪分类方法
图1描述了我们的Aux-LSTM方法,它包含了一个主任务和一个辅助任务.我们把使用人工标注样本的情绪分类任务当作主任务,把使用自动标注样本的情绪分类任务当作辅助任务,旨在利用辅助表示帮助提高主任务的分类性能.这种方法的主要思想是通过主任务和辅助任务共享辅助LSTM层,同时利用人工标注样本和自动标注样本.

图1 Aux-LSTM的总体框架Fig.1 The overall architecture of Aux-LSTM
3.2.1主任务 主任务的表示分别由主LSTM层和辅助LSTM层生成:
hmain1=LSTMmain(T),hmain2=LSTMaux(T),
其中:hmain1和hmain2分别表示主LSTM层和辅助LSTM层的输出.
接着,我们将两个LSTM层的输出分别连接到两个全连接层,并将两个全连接层的输出进行拼接后,连接到另一个全连接层,得到新的表示:
⊕denseaux11(hmain2)),

3.2.2辅助任务 辅助任务的表示由辅助LSTM层生成,辅助LSTM层是嫁接两个分类任务的共享LSTM层,使用与主任务中辅助LSTM层相同的权重对输入进行编码,haux=LSTMaux(T).
3.2.3联合学习 在联合学习方法中,我们对主任务和辅助任务的损失函数进行线性组合得到联合学习的损失函数:
其中:λ表示权重参数;yijmain和yijaux分别表示主任务和辅助任务中第i个样本属于第j个类别;pijmain和pijaux分别表示对应的预测概率;l是L2正则化参数;θ代表所有的参数.我们使用Adam[22]作为优化算法,神经网络中所有矩阵和向量初始化采用均一分布[23].
4 实验
在这个部分,我们将系统分析同时利用人工标注样本和自动标注样本的联合学习方法在情绪分类上的效果.
4.1 实验设置
如第3节所述,所有的人工标注语料和自动标注语料都来自新浪微博.在主任务中,我们随机挑选人工标注样本的5%、10%和20%作为训练数据集,另选20%作为测试集.在辅助任务中,我们随机选取2 000、4 000、6 000、8 000和10 000条自动标注样本作为训练集,测试集与主任务中一致.
本文实验采用一元词特征,每条微博被表示为一个词袋模型.我们采用正确率作为评价指标来衡量预测标签与真实标签之前的差距.
4.2 单个情绪分类任务的实验结果
在这部分,我们将汇报单独使用人工标注样本或自动标注样本的情绪分类结果.我们实现了几种情绪分类方法.
SVM (support vector machine):使用libSVM工具包实现,所有参数通过验证集进行调整.
ME (maximum entropy):使用Mallet工具包实现,所有参数通过验证集进行调整.
LSTM:使用Keras工具包实现,具体参数如表5所示.
表6展示了3种基本方法使用不同比例的人工标注样本时的结果.从表中我们可以看出,SVM表现最差,与其他两者相比,LSTM表现不错,这可能是因为LSTM模型更能捕捉序列信息.所以,我们将LSTM模型作为联合学习方法的基本分类器.

表5 LSTM中的参数设置Tab.5 Parameter settings in LSTM
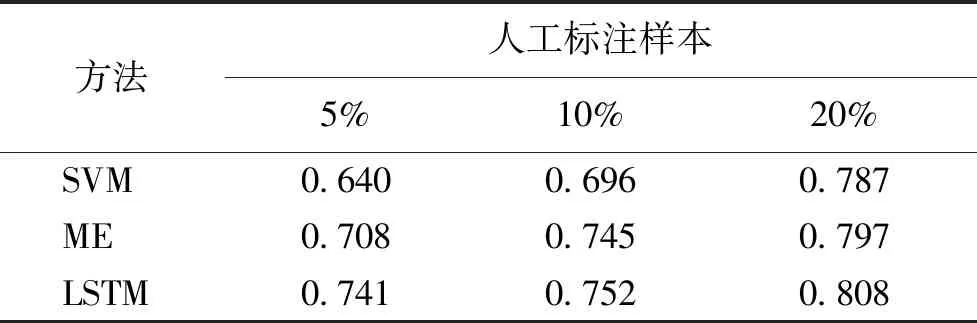
表6 不同的方法使用不同比例的人工标注样本时的结果Tab.6 The results of different classification methods using human-annotated data
表7展示了3种基本方法使用不同数目的自动标注样本时的结果.从表中我们可以看出,不同的方法对样本数量的适应性不同,没有一种方法完全优于另外两种.例如,当我们使用2 000条训练样本时,SVM表现最好,但是使用10 000条训练样本时,ME表现最好.

表7 不同的方法使用不同数量的自动标注样本时的结果Tab.7 The results of different classification methods using auto-annotated data
此外,我们进一步发现,当使用LSTM时,训练样本数目从2 000增长到6 000,正确率随着训练样本数目的增长而提高,但是当训练样本从6 000增长到10 000,正确率反而下降了.这与人工标注样本上的实验结果不同,这种现象表明正确率并不能总是随着自动标注样本数目的增长而提高,由于自动标注样本存在噪声甚至是错误,所以我们在使用自动标注样本时要很小心.
4.3 联合学习情绪分类任务的实验结果
为了充分比较,我们实现了两种情绪分类的联合学习方法.
混合模型:简单混合人工标注样本和自动标注样本,并训练了一个LSTM分类器进行情绪分类.与单个LSTM模型相比,这个混合模型包含更多的训练样本.
Aux-LSTM:利用辅助表示进行联合学习,在这个模型里,我们同时考虑利用人工标注样本的情绪分类和利用自动标注样本的情绪分类这两个任务.这个方法旨在利用情绪图标的额外信息提升情绪分类的性能.
图2~4分别展示了使用5%、10%和20%的人工标注样本时各种方法的分类结果.使用5%的人工标注样本时,基于人工标注样本的LSTM模型的性能总是低于基于自动标注样本的LSTM模型.这是可以理解的,因为人工标注样本的数目太少.当我们混合这两个数据集时,我们的方法Aux-LSTM总体上优于混合模型,尤其是自动标注样本数目增大时.与基于人工标注样本的LSTM模型相比,我们方法的提升很显著,大约6%,这就印证了自动标注的有效性.

图2 使用5%的人工标注样本时各种方法的分类结果Fig.2 Performances of different approaches to emotion classification with 5% human-annotated data
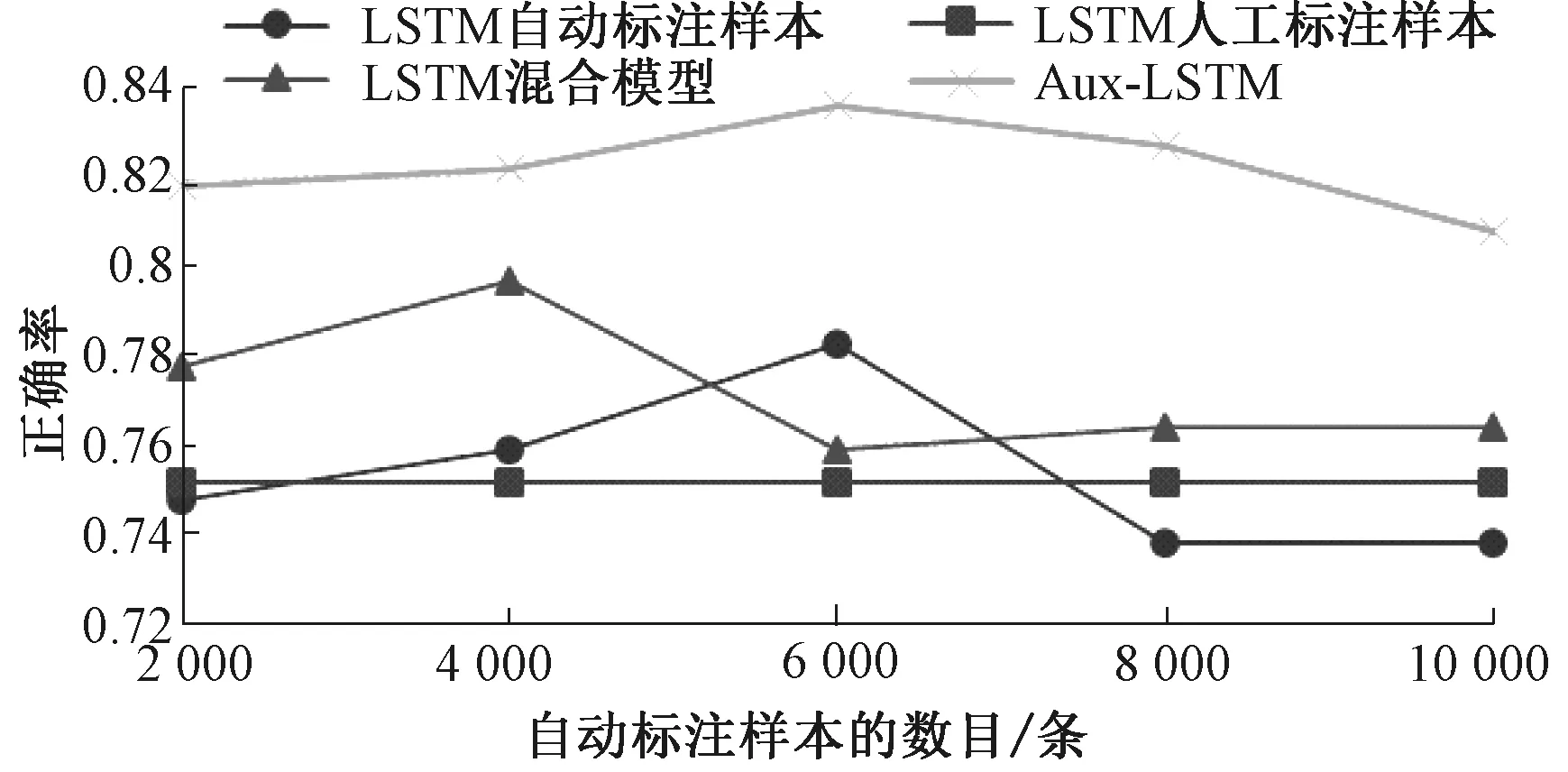
图3 使用10%的人工标注样本时各种方法的分类结果Fig.3 Performances of different approaches to emotion classification with 10% human-annotated data
使用10%的人工标注样本时,基于人工标注样本的LSTM模型的性能与基于自动标注样本的LSTM模型相当.当我们混合这两个数据集时,我们的方法Aux-LSTM明显优于混合模型.与基于人工标注样本的LSTM模型相比,我们方法的提升依旧显著,大约6%.
使用20%的人工标注样本时,基于人工标注样本的LSTM模型的性能优于基于自动标注样本的LSTM模型.当我们混合这两个数据集时,我们的方法Aux-LSTM仍然优于混合模型,在所有方法中分类性能最好,尽管与基于人工标注样本的LSTM模型相比,我们方法的提升只有2%.
4.4 参数敏感性和错误分析
在我们的联合学习模型中,有一个参数λ用来平衡两个情绪分类任务的重要性.我们在自动标注样本的数目固定为6 000时测试这个参数的敏感度.图5展示了在不同人工标注样本数目的情况下,情绪分类性能随λ变化的情况.从这张图中我们可以看出,这个参数并不敏感.当λ从0.6变化到0.75时,我们的方法表现始终很稳定.
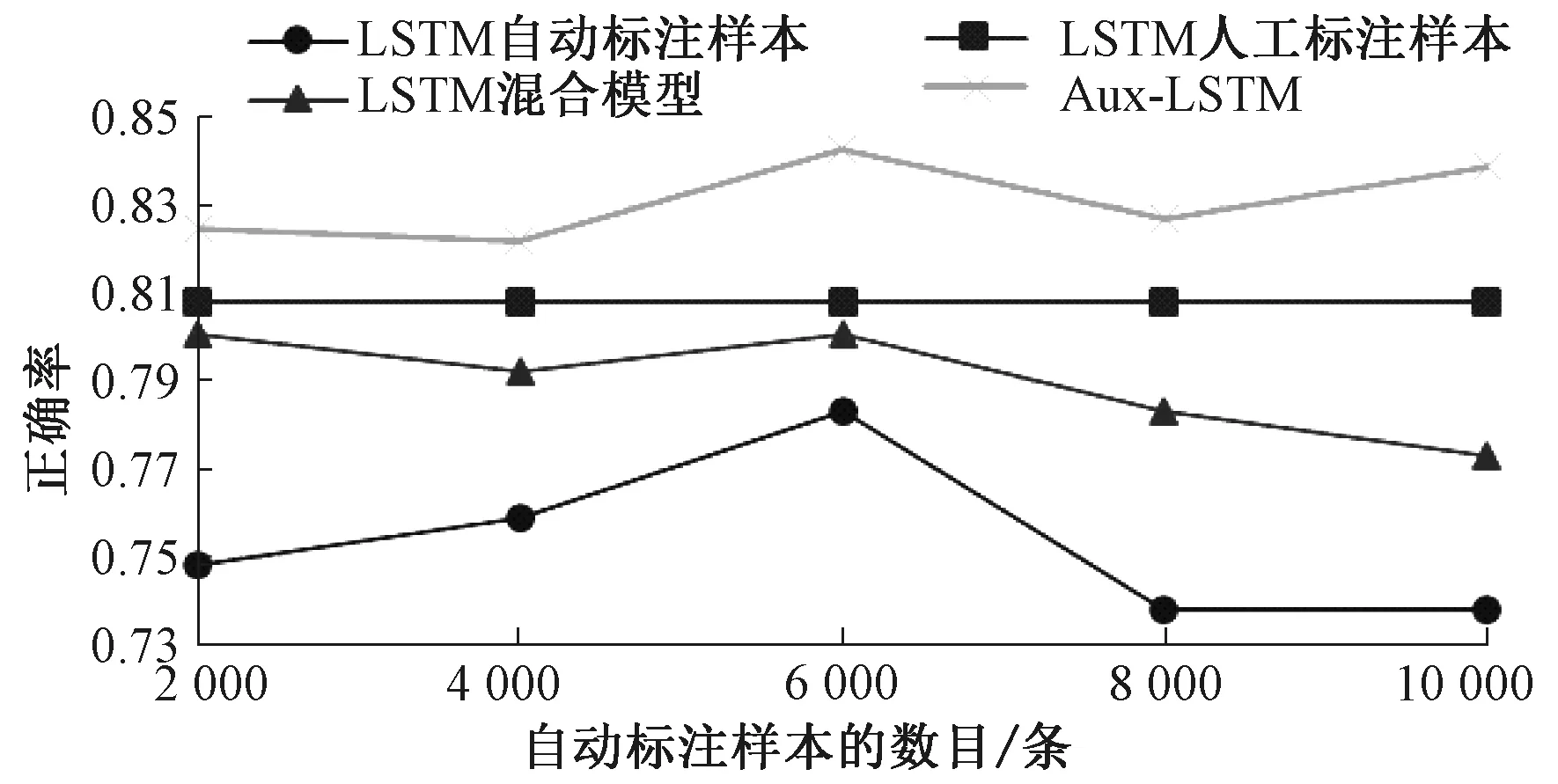
图4 使用20%的人工标注样本时各种方法的分类结果Fig.4 Performances of different approaches to emotion classification with 20% human-annotated data

图5 参数敏感性的测试结果Fig.5 The result of parameter sensitiveness
我们的方法虽然取得了84%的分类性能,但是仍然有很大提升空间.通过分析结果,我们发现主要有以下两种错误:1) 一些微博同时包含正面和负面的关键词,分类器很难分辨.例如,例4中的“好看”表达了正面情绪,而“比较差”表达了负面情绪.2) 一些微博太短,增加了分类器分类的难度.例如,例5只有两个字,无法判断属于哪个情绪类别.
例4:这个相机颜色好看,像素比较差.例5:嗷嗷!
5 结论
本文首先利用未标注样本中的情绪图标信息获得大量自动标注样本,紧接着提出了一个联合学习方法,即Aux-LSTM,来同时利用人工标注样本和自动标注样本.我们通过辅助任务的共享LSTM层获得主任务的辅助表示,并将此辅助表示加入到主任务中进行联合学习.实验结果表明,使用自动标注是提升情绪分类性能的有效方式,我们提出的联合学习方法优于一些基准方法.
在将来的研究中,我们考虑利用更多的上下文信息来提升我们的方法,并将Aux-LSTM模型应用到细粒度的情绪分类任务中.
猜你喜欢
军事文摘(2022年8期)2022-11-03 14:22:01
河北理科教学研究(2021年3期)2022-01-18 05:34:24
发明与创新(2021年39期)2021-11-05 07:15:28
小学科学(学生版)(2021年3期)2021-04-13 08:26:18
哈哈画报(2021年11期)2021-02-28 07:28:45
计算机应用文摘(2019年24期)2019-05-30 17:13:30
计算机应用文摘·触控(2019年24期)2019-01-08 07:15:51
中华老年口腔医学杂志(2016年1期)2017-01-15 14:24:42
材料科学与工程学报(2016年1期)2017-01-15 13:33:48
电影评介(2016年24期)2017-01-04 05:41:44
