
主题关键词信息融合的中文生成式自动摘要研究
2019-04-11 12:14:44侯丽微胡珀曹雯琳
自动化学报 2019年3期
侯丽微 胡珀 曹雯琳
自动摘要旨在从给定的文本中自动生成能表达原文主题的精简形式,以缓解信息过载造成的阅读压力.自动摘要过程大致可分为抽取式和生成式两类,抽取式摘要从原文中选取若干重要句子直接组合成摘要,生成式摘要的产生则相对自由灵活,有望生成更接近人工撰写的流畅摘要,并且在技术实现上更具挑战性.
目前,随着大数据和人工智能技术的发展,以及深度学习和表示学习在各个领域的推广渗透[1−3],传统自动摘要方法逐渐从抽取式朝着生成式演化,特别是基于循环神经网络(Recurrent neural network,RNN)的编码器–解码器模型正成为当前应用最广泛的生成式摘要模型,并在句子级的摘要生成任务(新闻标题生成、句子压缩等)中取得了较显著的效果.近年来,已有学者如Bahdanau等[4]提出在此模型的解码器部分加入对输入序列的注意力机制,用于提取原始文本中丰富的上下文信息以避免信息覆盖问题,导致该问题的原因是简单的RNN编码器–解码器模型中的编码器是将信息从前到后一步步压缩成一个固定长度的上下文语义向量,但这种信息传递编码方式会使得前面的信息被后面的信息覆盖而失效.此外,因为该机制将注意力均匀分布在文本的所有内容上,因而使得全文中的主题信息在摘要的生成过程中并没有被合理地区分利用,同时主题关键词是主题信息常见的表示形式.鉴于此,本文尝试提出了一种新的融合主题关键词信息的多注意力机制,并融入到循环神经网络的编码器–解码器模型中以补充强化原文中的主题信息,从而更好地引导摘要生成.具体而言,先使用无监督方法识别文本的主题关键词,然后综合主题关键词注意力机制,输入序列注意力机制及输出序列注意力机制三者联合辅助最终的摘要生成.在NLPCC 2017的中文单文档摘要评测任务上,本文提出的模型的实际摘要效果的ROUGE(Recall-oriented understudy for gisting evaluation)值比参赛队中第一名成绩还显著提高了2~3个百分点,充分验证了本文模型的有效性和先进性.
1 相关工作
现有自动摘要方法主要分为抽取式和生成式.抽取式摘要根据特定的约束条件(如摘要长度)直接从原文中抽取若干重要的句子,这些句子经重新排序后组成摘要.生成式摘要往往涉及对原文内容的语义理解和重构,且多采用更灵活的表达方式(如新词、复述等)间接凝练出原文的主旨要点.相比于抽取式摘要,生成式摘要更接近人类撰写摘要的形式.但由于生成式摘要通常需要复杂的自然语言生成技术,因此过去的研究大多注重抽取式摘要模型设计或句子打分排序算法的设计.
抽取式摘要首先给文本中的每个句子依重要度打分,然后根据此分数来对句子排序,进而选出得分最高且冗余小的句子组成摘要.现有方法中,句子重要度计算通常会结合考虑各种统计学和语言学特征,例如句子的位置、词频、词汇链等.句子抽取则大致分为无监督和有监督两种,其中无监督方法主要包括基于质心的方法[5]、基于图模型的方法[6−8]以及基于隐含狄利克雷分布(Latent Dirichlet allocation,LDA)主题模型的方法[9−10]等,有监督的方法则包括支持向量回归[11]和条件随机场模型[12]等.同时还有研究综合考虑了各种最优化的摘要生成目标函数,例如整数线性规划[13]、子模函数最大化[14−15]等.除此之外,还有些抽取式摘要研究结合了主题信息来辅助摘要的生成,例如基于动态主题模型的Web论坛文档摘要[16],也有研究提出使用超图模型来协同抽取文本关键词与摘要[17].同时,有研究者还尝试了结合图像、视频以及文字来联合生成多模态的摘要[18].
生成式摘要更接近人类自然撰写摘要的方式,是高级摘要技术的追求目标.随着智能技术的发展以及数据量的不断增长,当前对生成式摘要的需求和研究越来越多.近几年,神经网络模型在生成式摘要的一些具体任务(如标题生成、单句式单文本摘要生成等)上取得了一定的效果.Rush等[19]在一个大型语料库上训练了神经注意力模型并用于单句式摘要,之后Chopra等[20]在注意力机制的循环神经网络模型上扩展了Rush等的工作.Nallapati等[21]在基于循环神经网络的序列到序列模型上应用各种技术改善效果,例如在解码器阶段采用的分层注意力机制和词表限制.Paulus等[22]将输出信息尝试融入到输出的隐藏层向量中,以避免产生重复的信息,同时提出使用强化学习的方式训练模型.Ma等[23]通过最大化原文本和摘要之间的语义相似性,确保生成与原文本在语义上表达一致的摘要.Tan等[24]通过序列到序列模型与传统的图模型方法融合,以增加对句子重要度的考虑来生成摘要.Li等[25]提出使用变分自动编码器(Variational auto-encoder,VAE)提取出生成的摘要中的高维信息,然后让该信息辅助解码器对原文本进行注意力提取.还有一些工作在注意力机制、优化方法和原文信息的嵌入等方面进行了改进[26−29].然而,值得注意的是以上模型的注意力机制均仅限于均匀考虑整个原文本的所有信息而忽视了原文本中隐藏的重要主题信息的影响.鉴于此,本文提出将原文本中的主题关键词信息抽取出来,并自然地融入神经网络中以更好地区分引导生成摘要,模型中我们具体采用了多种注意力机制的联合策略.
2 背景模型:序列到序列模型和注意力机制
2.1 序列到序列模型
序列到序列模型又称为编码器–解码器模型,核心是利用RNN学习一个序列的所有信息,并浓缩到一个向量中,再利用另一个循环神经网络将此信息解码出来,进而生成另一个序列.具体结构如图1所示.
现有的实践发现[30],门控RNN比简单RNN效果更好,如长短期记忆(Long short-term memory,LSTM),双向门控RNN比单向RNN效果好.因此,本研究提出的模型在编码阶段采用了双向LSTM,在解码阶段采用了单向LSTM.

其中,编码器作用是将输入文档的信息映射为一个上下文语义向量c,每一个表示最新生成的词是由前i−1个词联合嵌入的上下文语义向量c生成的.具体过程为先对每一个文档d进行分词,每个词w被gensim工具包1http://radimrehurek.com/gensim/中的word2vec训练为一个向量以作为输入序列.在该阶段,每个输入序列通过LSTM生成一列蕴含高维信息的隐藏层向量.接下来,通过这些隐藏层向量来计算上下文语义向量c,具体计算方式为
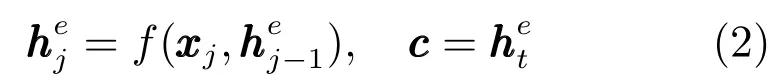
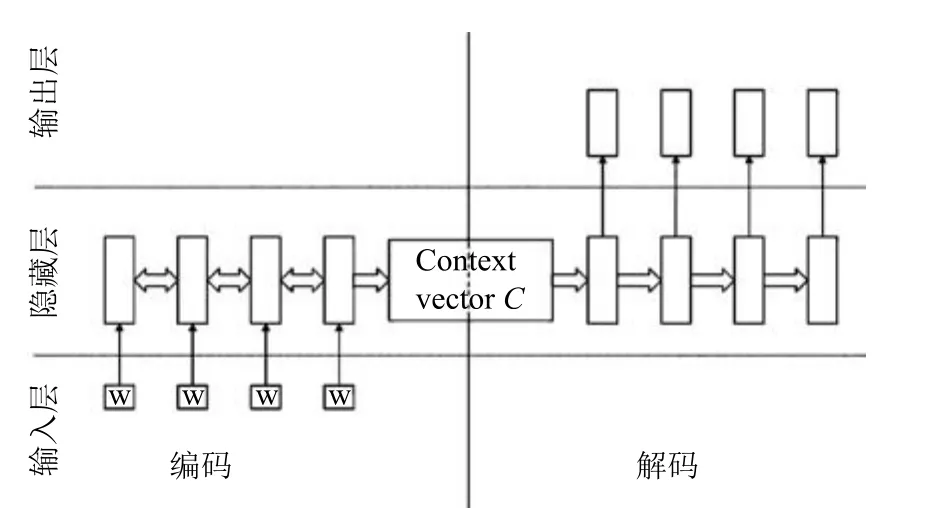
图1http://radimrehurek.com/gensim/ 序列到序列模型Fig.1 The sequence-to-sequence model
解码器的作用是生成输出序列.在此阶段,解码器利用编码器压缩后的语义向量c结合当前时间点解码器隐藏层的输出状态以及上一时间点中的输出词来生成候选词,具体的条件概率计算方式为
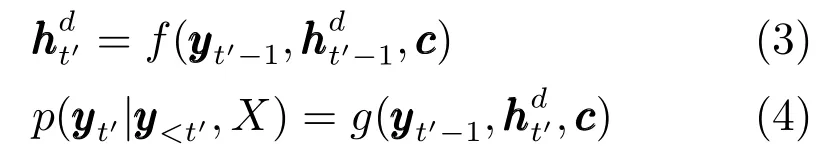
上述编码器–解码器模型虽然经典,但局限性也很明显.由于解码器从编码器中获取信息的唯一途径是一个固定长度的上下文语义向量c,因而编码器需要将整个原文本的信息压缩到一个固定长度的向量中,由此导致了三个弊端:1)仅靠一个固定长度的上下文语义向量往往无法完整地表示整个文本的全部信息,因而自然会影响解码器的信息解码效果;2)由式(2)可知,一般上下文语义向量c是由编码器最后一个LSTM输出的隐藏层状态向量获取的,因此在编码器阶段先输入的内容所携带的信息会被后输入的信息稀释或覆盖,且输入序列越长,这个现象越严重;3)由图(1)可见,解码器在所有时间点上都共享了同一个固定长度的上下文语义向量c,因此解码器生成的序列信息不足且固化,更合理的情况应该是解码器能根据输入序列x中不同部分的不同语义信息来生成不同的输出结果y.为了解决上述问题,Bahdanau等[4]提出了在序列到序列的模型中加入注意力机制,该机制能在一定程度上缓解这些问题.
2.2 注意力机制
引入注意力机制不仅为了减轻基本序列到序列模型中上下文语义向量 c的信息负担,还要对后续生成内容有针对性地生成一组对应的注意力权重以改进模型的实际生成效果,具体结构如图2所示.

图2 注意力机制Fig.2 The attention mechanism
由图2可知,在解码过程中,注意力机制使用动态改变的上下文语义向量来获取编码器中的原文语义信息,当生成每一个词yi的时候,编码器会动态产生与之对应的语义向量ci.这里的关键是如何定义不同解码时间的注意力系数αij,具体为
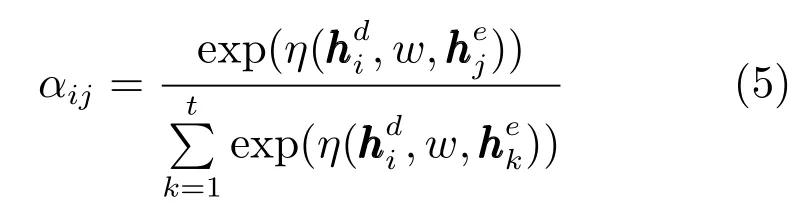
其中,η由一个多层感知器实现,采用tanh作为激活函数.代表在解码阶段时间i的LSTM 隐藏层向量,代表在编码阶段时间j的LSTM隐藏层向量,w为注意力权重矩阵.
通过上述公式计算得到注意力系数之后,便可结合编码器中所有隐藏层向量和注意力系数生成解码阶段时间i的上下文语义向量ci,具体为
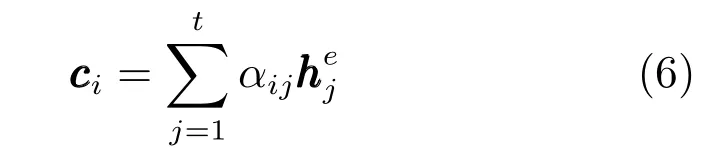
由于在每个时间点,解码器会根据当前解码器的隐藏层向量来引导编码器产生的上下文语义向量ci生成对应的输出序列,因此在生成摘要的某个部分时,注意力机制将帮助模型选择与此部分高度相关的原文信息,进而有望生成更好的相关摘要内容.
通常训练好一个序列到序列模型需要较大规模的数据,在数据量相对较少的情况下可能存在效果欠佳的情况,在文本摘要领域,虽然注意力机制的引入在一定程度上解决了一些问题并提升了模型的效果,但生成的摘要离人类撰写的摘要还有一定差距,因此如何将文本更深层次的信息有效地嵌入到模型中来生成更好的摘要仍需继续研究.为了解决上述问题,本文提出在序列到序列模型中引入主题关键词信息来优化现有生成式摘要模型的效果,并且提出了一种新的融入主题关键词信息的多注意力序列到序列模型,通过联合注意力机制将文本中多维重要信息综合起来实现对摘要的引导性生成.通过在NLPCC 2017中文单文档摘要评测数据集上的实验,本文提出的模型非常有效.目前,在生成式摘要领域,融合主题关键词信息以联合注意力方式优化摘要生成效果的设计思路尚未见文献报道.
3 提出的模型:主题关键词信息融合的多注意力序列到序列模型
在现有模型基础上,本文提出采用联合多注意力融合机制以提升摘要生成效果,模型的具体结构如图3所示.
本节将对图3中重要标识部分(主题关键词注意力机制和输入输出信息注意力机制)进行详细介绍,首先介绍主题关键词抽取,然后对模型中主题关键词注意力机制进行详细的说明.最后对模型中的输入输出信息注意力机制进行简要的介绍.
3.1 主题关键词注意力机制
1)主题关键词抽取
按照认知科学的观点,人类必须先识别、学习和理解文本中的实体或概念,才能理解自然语言文本,而这些实体和概念大都是由文本句子中的名词或名词短语描述的[31].因此本文通过发掘文章中的重点实体和概念来辅助模型理解自然语言文本.一个词在文本中出现的频率越高,产生的效力就越强,对文本的表达能力也越强,而这些实体或概念就称为文本的关键词.文本的主题关键词表征了文档主题性和关键性的内容,是文档内容理解的最小单位[32].因此本文提出将主题关键词信息融入到序列到序列模型中以实现在主题信息引导下的摘要生成.
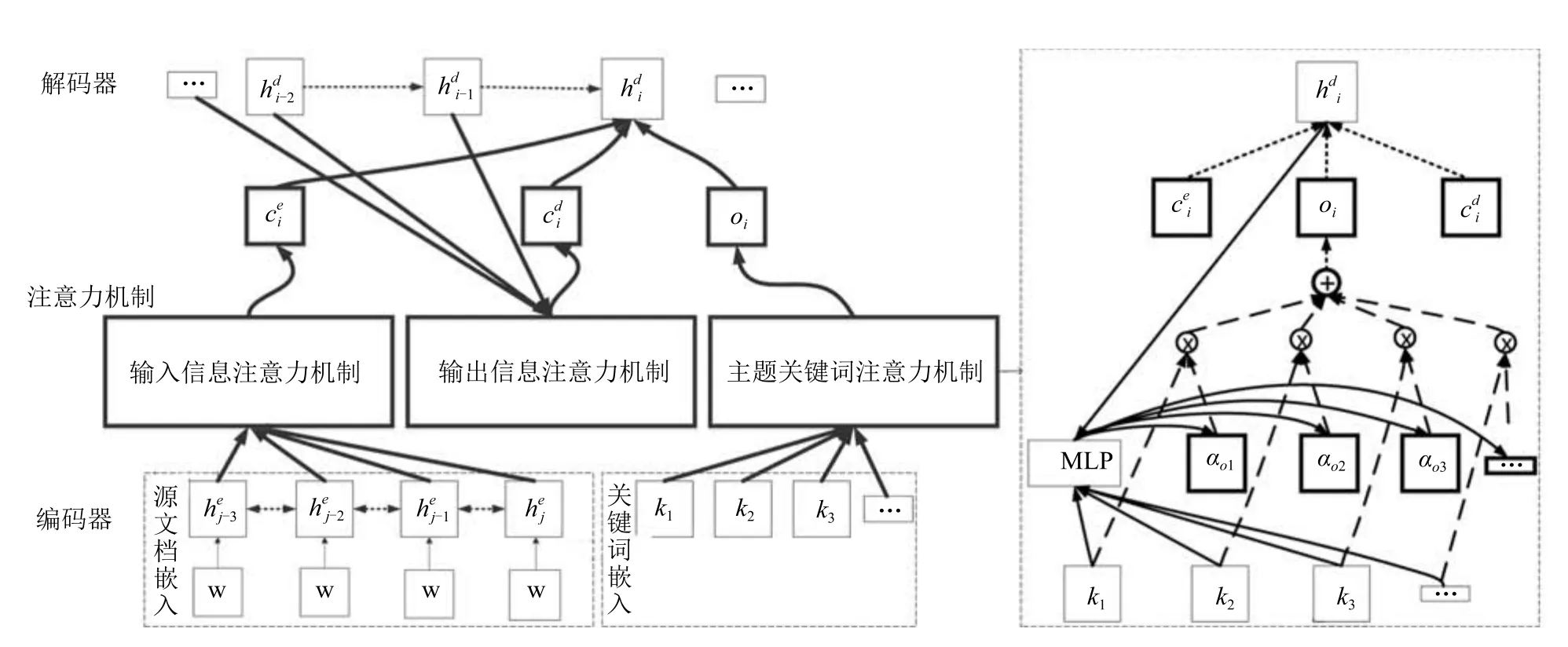
图3 主题关键词信息融合的多注意力序列到序列模型Fig.3 The multi-attention sequence-to-sequence model based on keywords information
本文使用的主题关键词抽取方法为HanLP开源工具包提供的主题关键词提取算法TextRank2http://hanlp.linrunsoft.com/doc/_build/html/extract.html#extract-keyword,并对每个文档提取出10个最重要的主题关键词.TextRank[33]是一种基于图模型的主题关键词抽取算法,基本思想源自谷歌的PageRank算法,核心是利用投票机制迭代计算图中每个结点的全局得分,然后取出得分最高的若干词作为主题关键词.与LDA和隐马尔科夫模型(Hidden Markov model,HMM)等模型不同,TextRank不需要事先对多篇文本进行学习训练,因简洁有效获得了较广泛的应用.
2)主题关键词注意力机制实现
人类撰写文章或摘要,都会预先设定一些内容框架并提取重要的实体信息,然后根据框架和实体信息构建语言.受此启发,本文通过自动提取文本的主题关键词组成一个文本的框架,然后将模型对文本的注意力引到这些预先提取的主题关键词信息上,由此生成基于主题信息的摘要.
图3右半部分对主题关键词注意力机制的基本结构进行了直观呈现.该机制将提取出的主题关键词通过注意力机制融入到模型中,通过主题关键词中蕴含的语义信息来引导模型生成更完善的摘要.
在编码阶段,由于原文本的输入形式是使用word2vec训练得到的词向量,因此为了保持词嵌入信息的一致性,对从原文中抽取出的主题关键词,直接利用word2vec训练出的词向量作为输入,其中n为主题关键词的数量.
在解码阶段,主题关键词注意力机制通过解码器解码当前输出的LSTM隐藏层状态向量中的信息来获得对所有主题关键词信息的不同注意程度.通过此机制,该模型在生成摘要的过程中能自然融入文本中的主题信息来生成基于主题引导式摘要.本文提出的主题关键词注意力机制中注意力系数的具体计算方法为
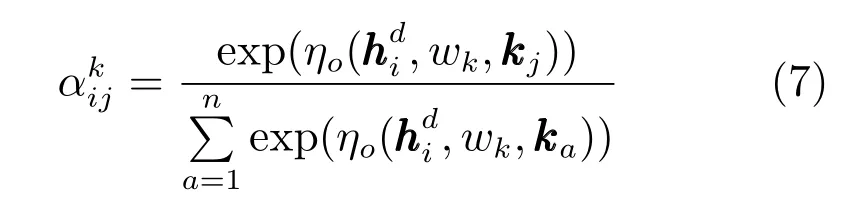
通过式(7)得到当前解码器时间点i对主题关键词的注意力系数后,便可结合主题关键词的嵌入向量生成上下文语义向量,具体为
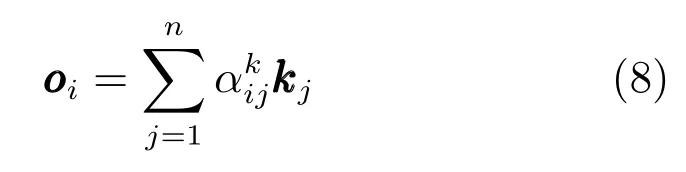
其中,n表示主题关键词个数,kj表示第j个主题关键词的向量表示.
3.2 输入输出注意力机制
图2中的输入输出注意力机制是将输入序列和输出序列的注意力结合起来共同嵌入到解码器当前时间点的输出序列中,这样既能考虑输入序列的信息,又可以通过对输出序列信息的回顾来避免信息的冗余和重复.
输入序列的注意力机制将原文中隐含的信息提取出来嵌入到输出序列中,其上下文语义向量表示为.
输出序列注意力机制与输入序列注意力机制的实现方式类似,但意义不同,解决的问题也不同.由于注意力机制的序列到序列模型在生成摘要的过程中存在重复信息的问题,而在该模型中加入对输出序列的注意力机制可在一定程度上缓解此问题,因此,本模型也一并加入了输出序列的注意力机制来优化摘要的生成结果,具体实现方法为
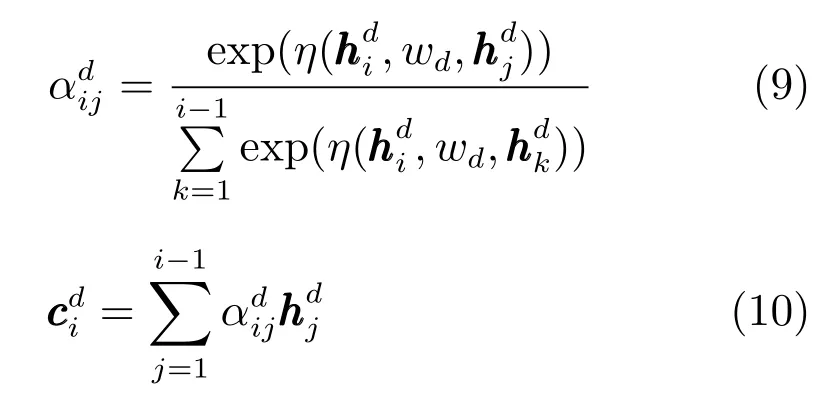
3.3 多种注意力融合
在获得主题关键词注意力和输入,输出注意力之后,我们将这两种注意力联合嵌入当前解码器的输出向量中以获得输出词的条件概率.通过此方法,输出向量中不仅包含输出序列的信息,也自然融入了原文本中的语义信息以及主题关键词信息,结合这些信息有望输出更优质的摘要.为了不加重网络的训练负担,本文仅采用线性加和的方式将多种注意力机制获得的上下文语义向量融合到一起,实验证明该种融合方式有效.具体融合方式为:先利用线性组合将三个注意力机制获得的上下文语义向量联合嵌入到解码器的第i个时间点隐藏状态中,然后使用softmax层得出词表中词的输出概率,具体计算方法为
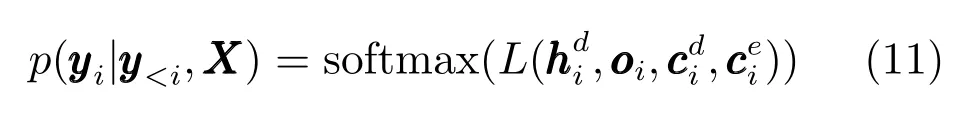
其中,L表示线性组合linear,表示解码器当前时间点i的隐藏层向量,表示文章主题关键词通过主题关键词注意力机制计算得出的上下文语义向量,表示之前所有输出向量通过输出信息注意力机制计算得出的上下文语义向量,表示输入向量通过输入信息注意力机制计算得出的上下文语义向量.
4 实验
4.1 数据集
本研究的实验语料采用NLPCC 2017的中文单文档摘要评测数据集,此数据集是今日头条提供的公开新闻数据,包括50000个文本–摘要对,每篇文章的长度从10~10000个中文字符不等,每篇摘要的长度不超过60个中文字符.在实验中,将其中49500个文本–摘要对作为训练集和验证集,另外500个作为测试集.
4.2 评价标准
评价方法采用自动摘要领域常用的基于召回率统计的摘要评价工具ROUGE(Recall-oriented understudy for gisting evaluation)[34].ROUGE由ISI的Lin和Hovy提出,基于机器摘要和人工标准摘要中的n元词(即n-gram)匹配情况来生成量化的评价结果.ROUGE指标由一系列具有细微差别的计算方法组成,包括ROUGE-1,ROUGE-2,ROUGE-3,ROUGE-4,ROUGE-L等.ROUGE-1.5.5工具包已被DUC和TAC等国际著名的文本摘要评测会议作为标准的评价工具采用.
本实验使用了ROUGE的五类评价指标,分别为ROUGE-1,ROUGE-2,ROUGE-3,ROUGE-4和ROUGE-L.直观看,ROUGE-1可以代表自动摘要的信息量,ROUGE-2、ROUGE-3以及ROUGE-4则侧重于评估摘要的流畅性,而ROUGE-L可看成是摘要对原文信息的涵盖程度的某种度量.其中ROUGE-N的计算方法为
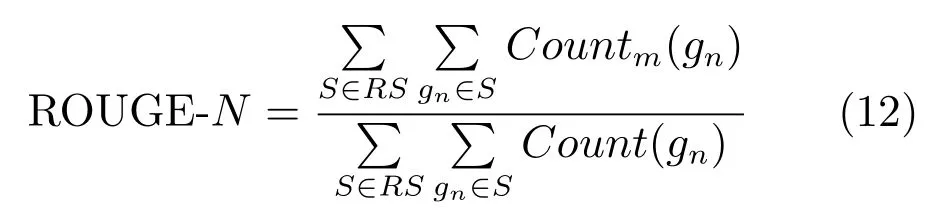
其中,RS表示参考摘要,该摘要为人工生成的标准摘要.gn表示n元词,Countm(gn)表示系统生成的摘要和标准摘要中同现的相同n-gram的最大数量,Count(gn)表示标准摘要中出现的n-gram个数.
ROUGE为每类评价指标分别计算了准确率P、召回率R和F值(其中,F=2PR/(P+R)),由于F值综合考虑了评价指标的准确率和召回率,因此本文统一将F值3ROUGE参数:-n 4-U-z SPL-l 60作为实验的最终结果汇报.
4.3 实验步骤
在数据预处理过程中,使用jieba4https://pypi.python.org/pypi/jieba/开源分词工具对文本进行分词,再用subword模型5https://github.com/rsennrich/subword-nmt对分词后的数据进行更细致的切分.通过这些操作,最终形成包含28193个中文词的词典.实验中采用subword模型可以减小词表的大小,同时解决序列到序列模型中常遇到的罕见词问题(即UNK问题).为了使词内信息得到合理的保存,本文使用的subword模型仅对词内信息进行切分和重组而不组合词间信息,因而先将分词后的词语以每个词为单位切分成字,然后使用subword模型将该结果使用2-gram的方法抽取出频率较大的词内组合,将此组合从之前的词中分离出来独立变为一个词.采用此方法可以极大地减少字典的冗余度,同时保留部分词信息,最终的分词结果为词组和字的混合文本.
接下来,利用gensim 工具包中的word2vec对词典中的每个词进行词嵌入训练,训练集为NLPCC 2017的中文单文档摘要评测任务分享的全部数据集,每个词的向量维度均设置为256维,通过预训练可以在一定程度上优化模型的效果.
本文使用tensor flow实现了基于主题关键词注意力的序列到序列模型,编码器层为一层双向的LSTM,解码器为一层单向的LSTM.LSTM 隐藏层维度设为128.在训练阶段,本文使用的优化函数为Adam[35],学习率设置为0.001,并在训练过程中利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,最小学习率设置为0.0001,在训练过程中,损失开始下降很快,训练几轮后,损失逐渐趋于平稳,且在几百个batch内损失值固定在1点多的范围内,数值不继续降低,模型趋于收敛.
在测试阶段,使用beamsearch方法生成最终的结果.beamsearch是一种启发式搜索算法,是对优先搜索策略的一种优化,能降低内存需求,根据启发式规则对所有局部解进行排序,以找到与全局解最近的局部解,此方法常应用于序列到序列模型中优化解的生成.
4.4 对比模型
选取5种基准模型与本文提出的模型进行比较,5种方法中的3种方法(即LexPageRank[6],MEAD[36]和Submodular[15])是目前最典型的抽取式摘要方法,由开源工具包PKUSUMSUM[37]提供,另外两种方法是生成式摘要方法的代表.
LexPageRank[6]是一个基于图模型的摘要算法,它将PageRank算法应用到文本句子关系表示及摘要抽取中.
MEAD[36]方法则通过联合考虑句子的4种常用特征来为其打分,包括质心、句子的位置、公共子序列及关键词.
Submodular[15]方法利用子模函数的收益递减特性来挑选重要句子生成摘要.
UniAttention[20]是基本的注意力序列到序列模型,实现了对原文本输入信息的注意力机制考虑及摘要生成.
NLP_ONE[38]是在NLPCC 2017的中文单文档摘要评测任务中获得第一名的参赛模型,包含了输入序列的注意力机制和输出序列的注意力机制,但它没有对主题关键词信息进行融合考虑.
pointer-generator[29]是ACL 2017公开发表的一个最新的同类模型,使用pointer机制解决了输出信息错误和罕见词的问题.
4.5 实验结果分析
第4.4节中的5种模型与本文提出模型的具体实验结果比较如表1所示.由表1的结果可见:
1)生成式摘要方法在ROUGE的F值比较中比抽取式摘要方法平均高4~10个百分点,这说明在自动生成短文本的摘要任务中,生成式方法更有效.
2)由UniAttention模型与本文模型的对比结果可见,将文本关键词的注意力信息和输入输出序列的注意力信息共同融入到序列到序列模型中可以显著地提高模型的摘要效果(具体可提升3~4个百分点).
3)本文对NLP_ONE,pointer-generator和本文模型的实验数据进行了统计显著性分析,发现结合主题关键词信息和原文本中多维信息来引导摘要生成能有效地提高现有基于RNN注意力机制的生成式摘要模型的摘要效果,充分说明主题关键词信息在生成式摘要中发挥了积极的引导作用.
4)本文所提模型产生其摘要的实际效果举例如表2所示.表2展示了从3个序列到序列模型生成的摘要中抽取的5例摘要,从表2可以看出,生成式摘要技术尽力去学习和模拟人类撰写摘要的方法,生成的摘要根据需要表达的主题信息和语义信息引导词语组合而成,而不仅仅由抽取的句子简单拼凑而成,因而在生成短文本摘要时,相比抽取式摘要,生成式摘要的文本流畅性、句间连贯性以及信息丰富性均更胜一筹.
5)对比表2中的机器自动生成摘要的内容可以发现:本文提出的模型在学习摘要的生成过程中,更注重内容信息的表达,同时也抓住了文本中的关键主题信息,使生成的摘要的信息量更充足.在同等数据集的条件下,相比未融入主题信息的序列到序列模型,本文提出的模型效果更优,因为该模型将更多的主题信息显式提取出来用于指导摘要的生成,特别是主题关键词信息协助模型更有针对性地选择与主题相关的词语来构成摘要.
4.6 存在的问题
根据实验结果,尽管生成式摘要相比抽取式摘要在中文短文本摘要生成任务中效果较好,但仍需相对较大的数据来协助训练以生成高质量的摘要.通过对实验数据的细致分析可以发现:由于数据分布不均匀使得模型对训练样本较多的内容其学习效果比数量较少的内容学习效果好.虽然主题关键词的融入在内容上对文本的信息进行了补充,使得生成的摘要可以抓住文章的重点信息,但在表达的流畅度方面,样本量越大往往效果越好.例如表2中原文为天气和受贿内容的生成摘要比其他类型的摘要生成效果好,若训练样本充足,则生成的摘要和原标准摘要在内容和表达上均能达到90%以上的匹配度.因而在训练数据量有限的情况下,如何更好地生成拟人式高质量摘要仍是需要进一步深入探索的问题.
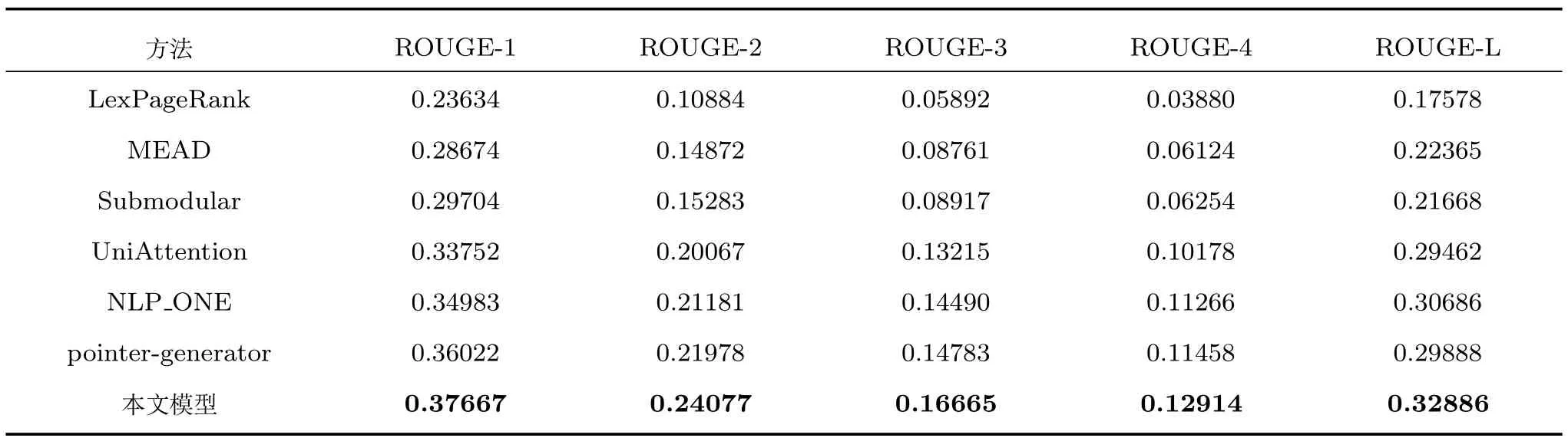
表1 摘要评价结果Table 1 The results of summaries

表2 生成摘要对比示例Table 2 The examples of the generative summaries
5 结束语
本文提出了一种新的基于神经网络的生成式中文自动摘要方法,不仅融入了对输入序列的注意力及输出序列的注意力的区分性考虑,还自然嵌入了文本中的关键主题信息下的注意力,最终的实验及评价结果证实了引入关键词信息对提升中文生成式摘要模型的显著效果.未来尚有很多可以拓展的工作,例如在LCSTS等中文大规模文摘数据集上进行实验,将神经网络模型应用到多文档多句子式的生成摘要中,以及如何更有效地提取文本中全局和局部的不同粒度或不同模态的关键主题信息.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
