
基于手机信令数据的地铁乘客路径识别研究
2019-04-02 10:47丁敬安张欣海
中国电子科学研究院学报 2019年11期
丁敬安,张欣海
(1.杭州三汇数字信息技术有限公司,浙江 杭州 310053;2.安徽工业大学管理科学与工程学院,安徽 马鞍山 243032;3.中国电子科学研究院,北京 100041;4.社会安全风险感知与防控大数据应用国家工程实验室,北京 100041)
城市轨道交通具有容量大、速度快、时效高等特性,成为人们出行方式之一。城市轨道交通形成的网络与其它的复杂网络一样存在脆性,就其封闭式空间设计来说,如果出现人流激增及对流情况,很容易出现踩踏等安全事故,严重可能导致轨道交通网络节点的瘫痪,影响交通网络的正常调度。合理的客流预警与客流引导能够缓解网络整体的压力,保证网络正常的运行,同时客流预警又能够为安全应急管理的提前部署提供有力的支持。
轨道交通网络建设成本较高,国内普遍为多运营商合作建设,当乘客在不同运营商建设的线路间换乘时,存在不同线路票务清分的问题,目前大部分轨道交通网络采用的是最短路径法进行票务清分。随着交通网络复杂性的提高,换乘点增加使得传统票务清分机制在一票换乘的场景下不再适用。然而通过识别乘客路径合理区分乘车区间,可以解决最短路径票务清分机制的不合理性问题。
准确地识别乘客的进出站、换乘点、起讫点及时间等出行特征是人流预测、客流诱导、应急管理及票务清分等工作的基础[1-4]。在轨道交通网络中没有形成闭环时,乘客精确的出行特征可应用AFC(Automatic Fare Collection System,城市轨道交通自动售检票系统)数据计算,而当多条线路相交形成闭环时,仅提供乘客起讫点信息的AFC数据无法通过模型精确计算乘客的出行路径[5-6]。通过站点安装Wi-Fi采集器采集用户手机的MAC地址标识,虽然MAC标识能够准确定位乘客位置识别乘客路径,但是数据的采集需要用户手机Wi-Fi功能的开启,否则无法识别乘客[7]。利用手机信令数据识别乘客轨道交通路径,主要是通过单轨道LAC(Location Area Code,位置区域码)值相同识别站点基站,不同轨道LAC值不同原理识别换乘站点,模型能够准确识别乘客路径。但同一轨道LAC值唯一原理存在片面性,部分城市存在同线路多段LAC值和地面站点LAC与地下站点LAC不同的情况[8-9]。
本文利用乘客正常位置更新的手机信令数据以及轨道交通网络内部站点经纬度识别站点的基站,通过站点基站过滤出乘客信令数据,再利用图模型计算轨道交通网络内节点间最短距离(时间)以及节点间的最短路径,通过位置信令数据的迭代,识别出乘客的进出站点、时间及换乘站。经实验验证,上述方法对运营商A、运营商B、运营商C的基站识别准确率分别为:79.197%、72.941%、92.893%;对运营商A用户、运营商B用户、运营商C用户的乘客路径识别准确率为:70%、70%、85%。
1 地铁站点基站识别方法
1.1 手机信令定位信息产生原理
在轨道交通系统内,用户在使用移动通信业务时,通过请求当前基站进入通信网络完成信息交互,该过程会在基站留下注册与交互信息数据即信令数据[8]。手机信令数据中包括的字段有信令截获的时间戳(capturetime)、用户号码(msisdn)、位置区码编码(lac)、小区识别码(cellid)和基站经纬度(lng、lat)等。
由于轨道交通系统的隧道结构设计,屏蔽外部基站信号严重[10],通常为保证轨道交通系统内的移动通信服务,一个站点会布设一个基站,在客流量比较密集的换乘站点会增设多个基站。实际数据分析发现,针对站点基站的位置区域编码存在多站点位置区域编码相同情况,亦存在相邻站点位置区域编码不同的情况,且不同运营商间还存在差异性。针对站点位置位于地下或半地下情况,站点内部基站LAC值一定异于地面范围基站的LAC值;当站点位于地面且站点没有增设基站时,移动用户会请求附近小区基站进行通信,该站点的用户交互的基站LAC值即为当前小区基站LAC值。
在轨道交通系统内,手机用户在相同或者不同的位置区域编码区间内移动时,会与位置区域编码对应的基站产生交互并留下记录时间、小区编码和基站的经纬度,从而留下用户位置信息。通过信令的位置信息序列,能够准确地识别出用户的行程轨迹。
1.2 地铁站点基站识别方法
轨道交通系统内,如何进行地铁基站的准确识别,进而刻画移动用户的轨迹行程,是一个值得研究的问题。
针对地铁基站的识别,本文通过地图POI数据过滤地铁站点经纬度数据集,再利用GeoHash算法[11](GeoHash本质上是空间索引的一种方式,其基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码。以GeoHash方式建立空间索引,可以提高对空间兴趣点数据进行经纬度检索的效率)把站点经纬度转成算法编码的网格记为geohash,通过站点所在的geohash计算该网格相邻两层网格,网格集合记为G,网格集合组成的区域即站点范围区域。结合地铁首末时刻表T计算站点车辆通行的时间差a,通过迭代用户信令数据D,判断用户经过相邻站点时间阈值是否小于等于t,拟合出高质量地铁乘客。
通过高质量地铁乘客信令数据,识别站点范围人流密集区域,通过人流密集区域内用户信令数据,识别出乘客交互的基站。
基站识别算法描述:

输入:信令数据D,时刻表T,地图POI;
1.从地图POI获取地铁站点经纬度数据集:
A={(lng1,lat1),(lng2,lat2),…,(lngn,latn)},坐标系转换为WGS-84坐标系得到数据集:;
2.计算站点经纬度所在的网格及网格邻居构成的区域集合G={geohash1,geohash2,…,geohash25}。
3.设站点数n1,最大停留阈值t,判断用户经过的站点数N≥n1,且乘客在起始站点停留时长t1≤t;
4.结合时刻表T,计算车辆在站点间的时间差a;
5.迭代用户信令数据集D,判断乘客站点间的弹性时间差t2≤a+Δt,其中a为车辆站点间时差,Δt为弹性时长,过滤得到高质量乘客信令数据集D1;
6.在数据集D1中,以网格、站点名、运营商(geohash、station_name、operator)为窗口计算geohash下的人流量count值;
7.station_name、operator为窗口对geohash下的count值进行排序记为rank,station_name、operator、lac(位置区域码)为窗口对geohash下的count值进行排序记为rank1;
8.设参数a1、b,以条件:rank≤a1,rank1≤b,过滤得到站点基站;
9.end for.
输出:地铁基站表S
在基站识别算法中,假设存在两个站点A、B以及两站间站点数总和n2,则A站到B站的花费时间T如公式(1)所示:
(1)
在图1中,给出了地铁基站能识别流程图,流程主要包含两部分:高质量乘客信令过滤、站点基站识别。
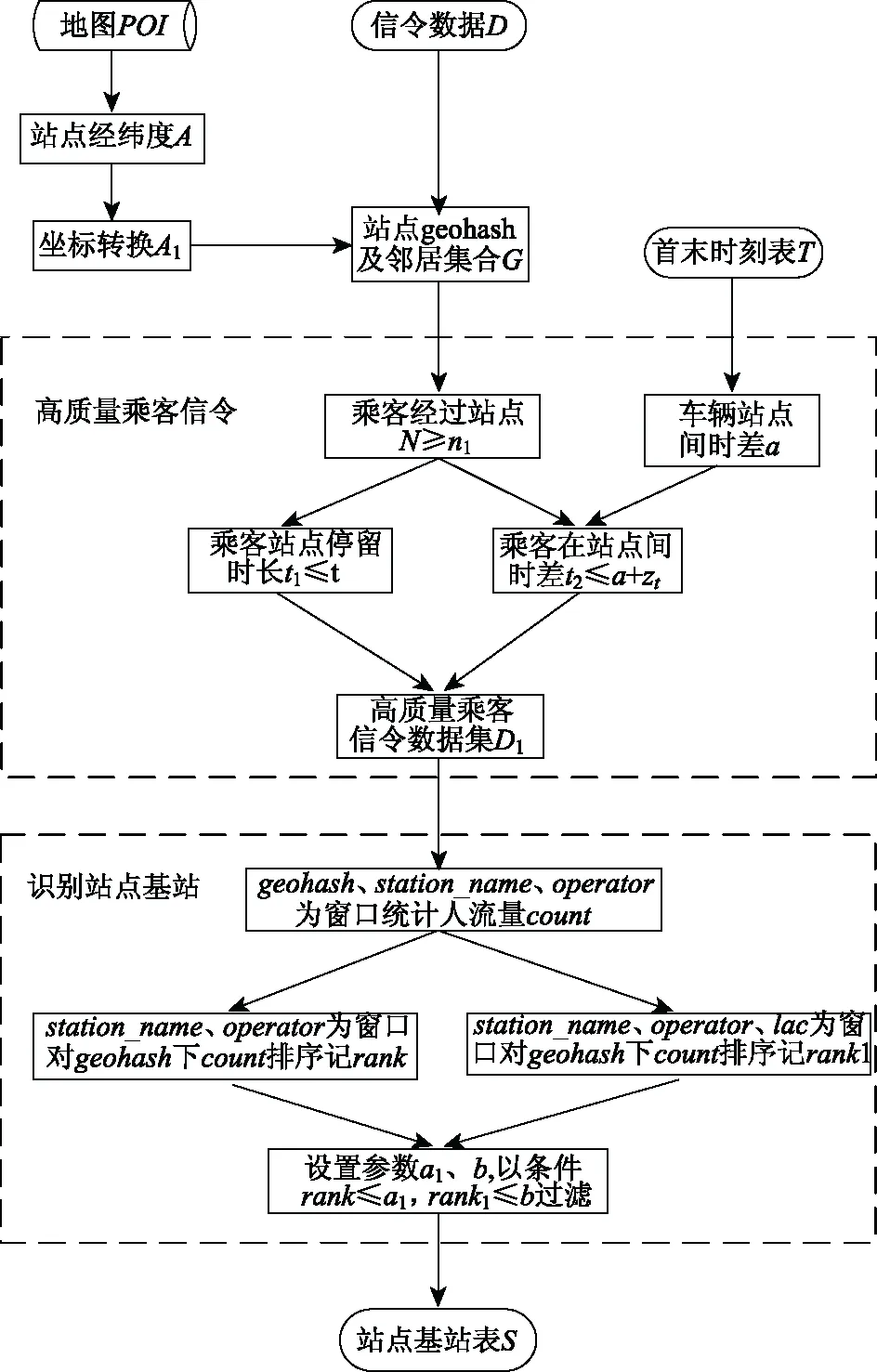
图1 地铁基站识别流程图
2 地铁乘客路径识别方法
通过基站识别模型算出地铁基站,结合地铁基站过滤当天与基站交互的用户,获取乘客轨道交通系统内产生的信令数据。利用首末时刻表T,计算站点间时间差,作为数据集T1。结合图计算构建乘客路径识别模型,其中把站点作为图的节点,利用弗洛伊德图算法[12-13](Floyd)计算站点之间最短时间距离及最短路径,通过最短时间距离迭代用户的信令数据,切分用户轨道交通轨迹线。通过最短距离迭代用户的信令数据,计算系统内换乘点。
Floyd算法是利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,在求解过程中没有给出节点间的路径,后面的学者在此基础上进行改进,给出基于最短路径的节点间路径。
在路径识别算法中,先计算T1中节点间邻接矩阵adj,再通过Floyd算法计算节点间最短时间距离dist,最后给出节点的最短路径path。
Floyd算法描述:
输入:邻接矩阵adj;
1.设adj中w[u][v]为节点u、v的连边权重,节点个数为V;
2.在距离矩阵distv×v中,初始化最小值为∞,路径矩阵Nextv×v中,初始化最小值为null;
3.节点间距离dist[u][v]=w[u][v],节点间路径next[u][v]=v;
4.对于每个节点与自己的距离设为distv,v=0;
5.设k,i,j为从1到V的变量;
6.循环判断dist[i][j]>dist[i][k]+dist[k][j]是否成立;
7.成立则dist[i][j]=dist[i][k]+dist[k][j],next[i][j]=next[i][k];
8.节点间最短路径计算,判断next[u][v]=null是否成立;
9.是则return[],否则path=[u];
10.当u≠v时,u=next[u][v],则path.append(u);
输出:dist、path

在Floyd算法中,u、v两点间的最短路径可以简化如公式(2)所示:
dist[u][v]=min(dist[u,v],dist[u][k]+
dist[k][v])
(2)
其中dist[u][v]为节点u、v间上次迭代计算出的距离,dist[u][k]+dist[k][v]为当前迭代计算出的节点间距离。
通过迭代乘客信令数据,比较乘客经过站点间时间a与距离dist[u][v]大小,切分乘客当天轨迹线,最后利用路径path判断节点计算是否存在换乘点。
路径识别算法描述:
输入:信令数据D、地铁基站表S;
1.通过基站表S,过滤乘客信令数据D,得到D2;
2.计算站点间邻接矩阵adj,利用floyd算法计算站点间最短距离矩阵dist和最短路径path;
3.在D2中计算乘客经过站点间的时间差t2;
4.判断t2≤dist[u][v]+Δt是否成立;
5.是则继续信令迭代,否则计算行程的起讫时间及起讫点;
6.按照起讫时间切割轨迹线;
7.轨迹以乘客标识、日期及行程号(id、date、journey)进行8.轨迹标识并生成乘客路径path1;
8.判断path1是否存在站点丢失;
9.是则path1中u、v站点间插入path(u,v);
10.结合path1,判断乘客数据是否存在换乘站点x;
11.存在,判断path1[len(x-1)]与path1[len(x+1)]是否在一条轨道线上,“是”则不为换乘点,“否”即为换乘点;不存在,无换乘点。
12.end for.
输出:轨迹线表journey(时间、起讫点、换成点、完整路径)
在图2中给出了乘客路径识别的流程图,主要包含三个部分:图计算、轨迹切分、轨迹特征计算。轨迹特征包含起讫点、起讫点时间、换乘点等。
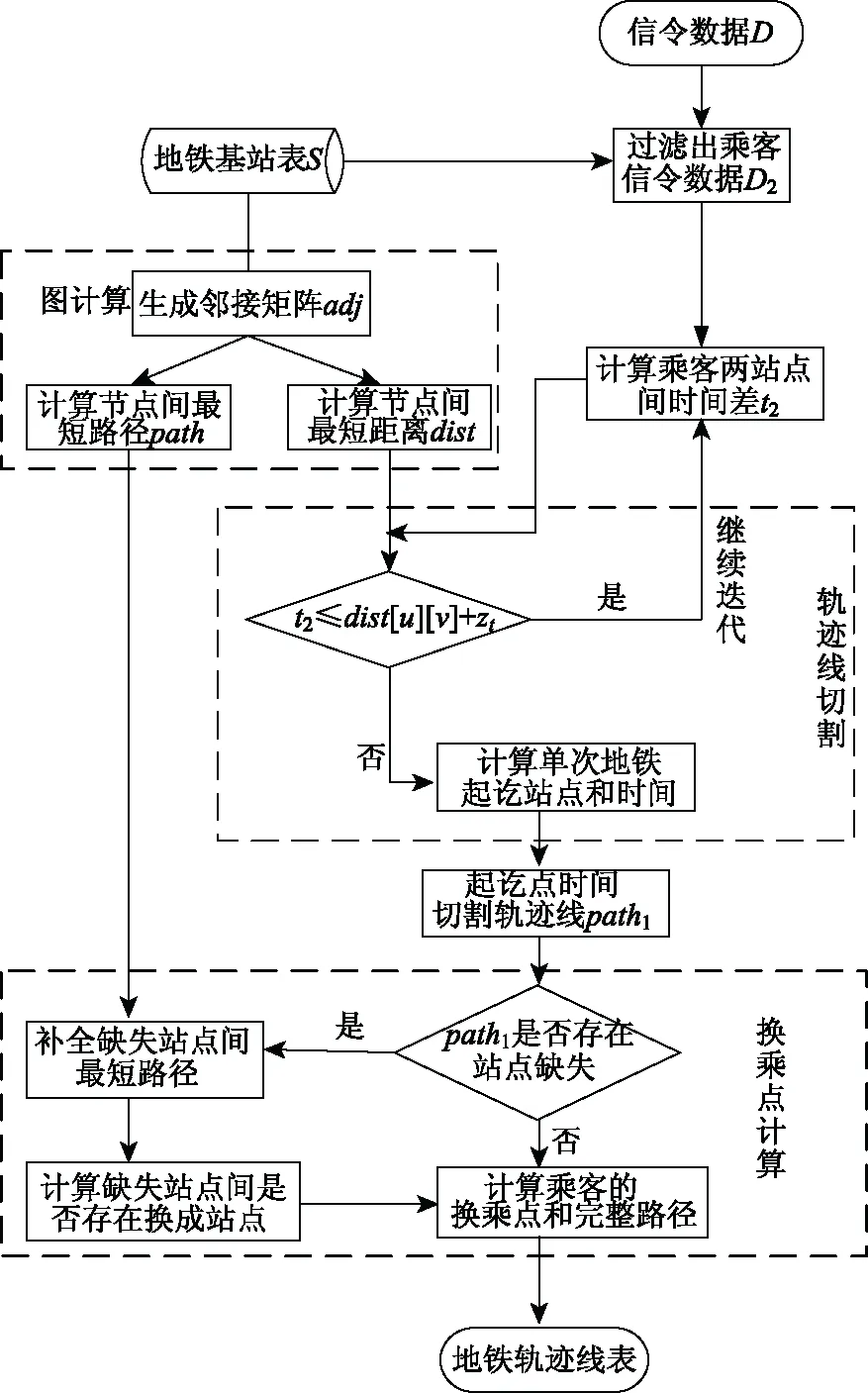
图2 地铁路径识别流程图
3 实例分析
3.1 实验数据
以测试城市轨道交通网络为对象进行研究分析。截至2019年3月,该市轨道交通网络运营线路3条,共设车站79座(换乘站不重复统计),换乘车站5座。
实验基站信令数据来源于测试城市移动通信服务商,地铁站点位置数据来源于地图POI数据。由于站点源数据坐标为GCJ-02坐标系,需转换成WGS-84坐标系再进行计算。
表1中给出了站点经纬度的部分数据,包含字段:station_name、line、lng、lat、lngwgs84、latwgs84,line为线路编号,lng、lat为基于GCJ-02坐标系的站点经纬度坐标,lngwgs84、latwgs84为转换后的WGS-84坐标系站点经纬度坐标。
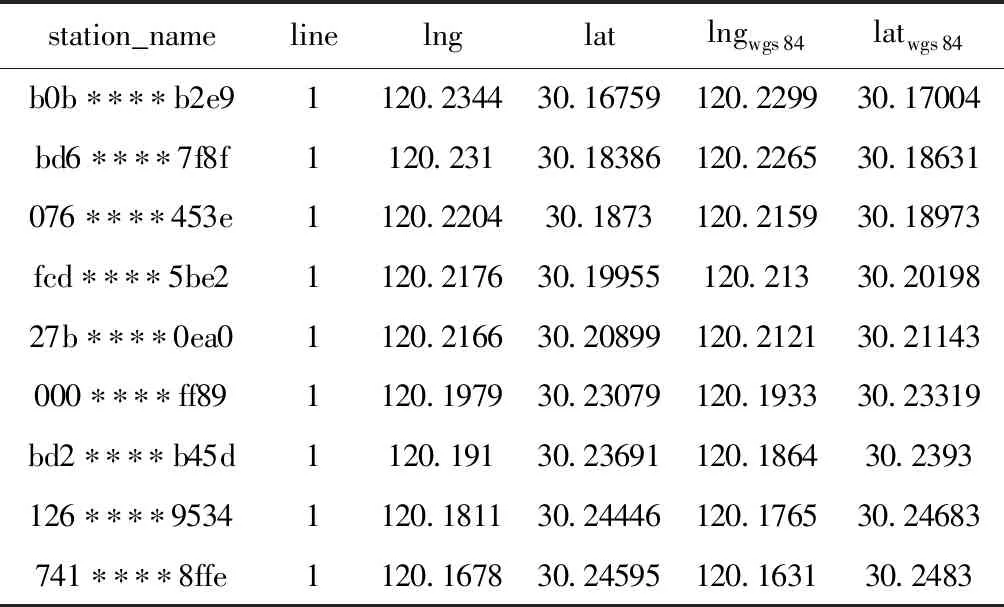
表1 站点经纬度
表2中给出车辆经过站点的首末时刻表,站点经添加字段:last_time、first_time,last_time是车辆经过站点最晚时间,first_time为车辆经过站点最早时间。
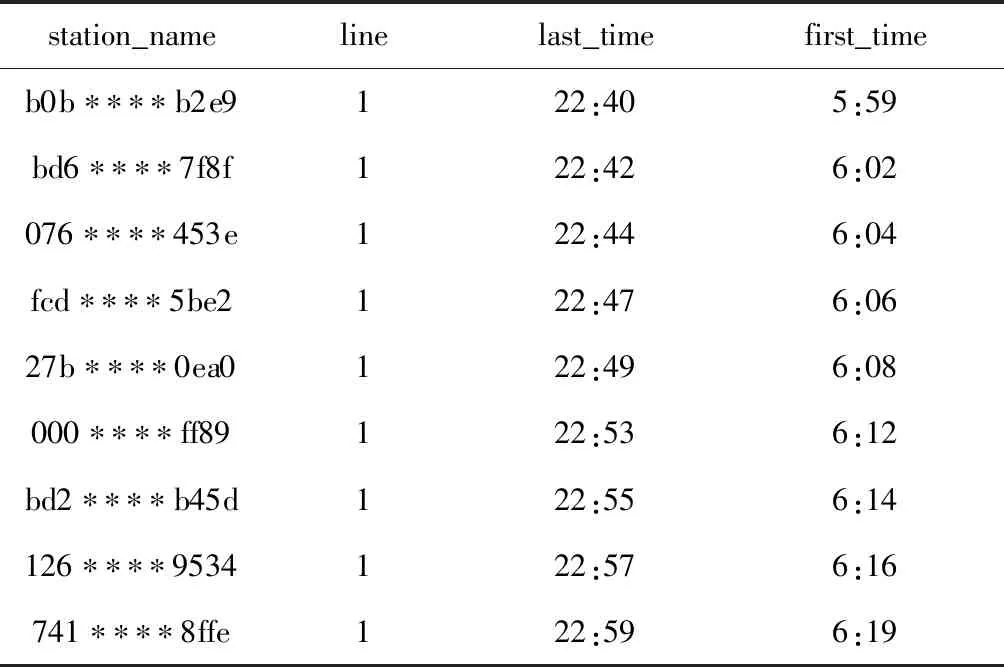
表2 首末时刻表
表3中给出测试号码的信令部分数据,字段包含:capturetime、md_id、ecgi、lac、cellid、lngs、lats,其中lngs、lats为乘客连接站点基站的经纬度,其中md_id为对msisdn加密得到的用户标识。
3.2 评价指标
针对基站识别与路径识别模型,可以作为二分类问题处理,基站识别结果表中是地铁基站标签为1,不是地铁基站标签为0。同理分析乘客信令数据,进出站、换乘点及时间相符合标签为1,否则为0。所以本文选用查全率与查准率作为模型评价指标,衡量模型在样本数据集上的泛化能力,表4中给出了分类结果的混淆矩阵[14-16]。

表3 信令数据集(样例数据)
表4 分类结果混淆
查准率P和查全率R定义为:
(3)
(4)
公式中TP、TN、FP和FN指的是模型预测值落入这些类别中的次数,因此,查准率表示正确识别正确分类的数目除于所有预测值的个数。
3.3 实验与分析
本文实验环境如下:操作系统为Linux version 3.10.0-327.el7.x86_64,Intel®Xeon® CPU E7-4820 v2@2.00 GHz, 总处理器核心数量64个,实验内存为512 GB,主要实验平台为python version 3.6.1版本和阿里云计算平台。
(1)数据预处理
①无效数据处理
在数据解析过程中,存在部分数据无法解析完整,即存在部分数据无效,无效的数据参与计算会加大服务器计算压力,同时会浪费一定计算资源。比如基站的经纬度为空值或者基站标识为空等。
针对路径识别问题,信令数据中没有乘坐地铁的信令数据即视为无效数据,进行提前过滤。
②异常值处理
异常值处理包含信令位置数据发生漂移问题,比如一定阈值范围内存在某点与其它点之间的距离很远不符合实际,需要排除。
针对信令数据存在缺失的情况,结合地铁基站库数据判断信令至少出现在两个以上站点,且两站之间的时间差不能超过一定阈值。
(2)基站识别与结果分析
①基站识别
经过分析发现部分地铁线路和路面主干道重合,导致地铁乘客行程数据会混杂路面行人行程,同时乘客进入站点需要进行安检和等车,换乘时需要站内行走,所以经过多次迭代发现选择设置参数n1=6,站点停留阈值t=600 s,站点间时间差补偿值Δt=300 s较为合理,geohash、lac相关参数a1-1,b=1。
以一天内移动通信用户的信令数据集D、站点经纬度数据集A及首末时刻表T为基础,通过基站识别算法识别站点基站。表5中给出了火车东站站点部分基站数据,标准包含字段:geohash、lac、ecgi、cellid、station_name、operator_net,其中geohash为站点基站所在的geohash。表中ecgi部分空值表示为2G、3G基站非4G基站,operator_net的值01代表运营商A,03代表运营商B,06代表运营商C。在站点基站表中总计包含基站1851个,其中运营商A基站共计274个,运营商B站点基站共计170个,运营商C站点基站共计1407个,运营商C站点基站占比最大。
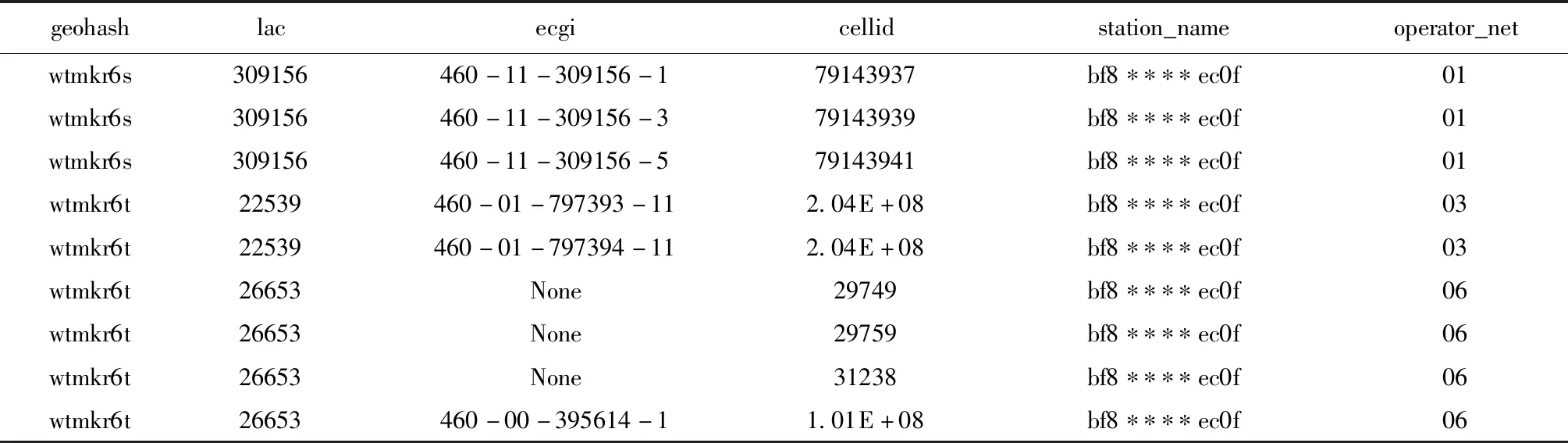
表5 站点基站
图3给出了站点基站7位geohash编码网格地图显示,共计包含155个7位geohash网格。
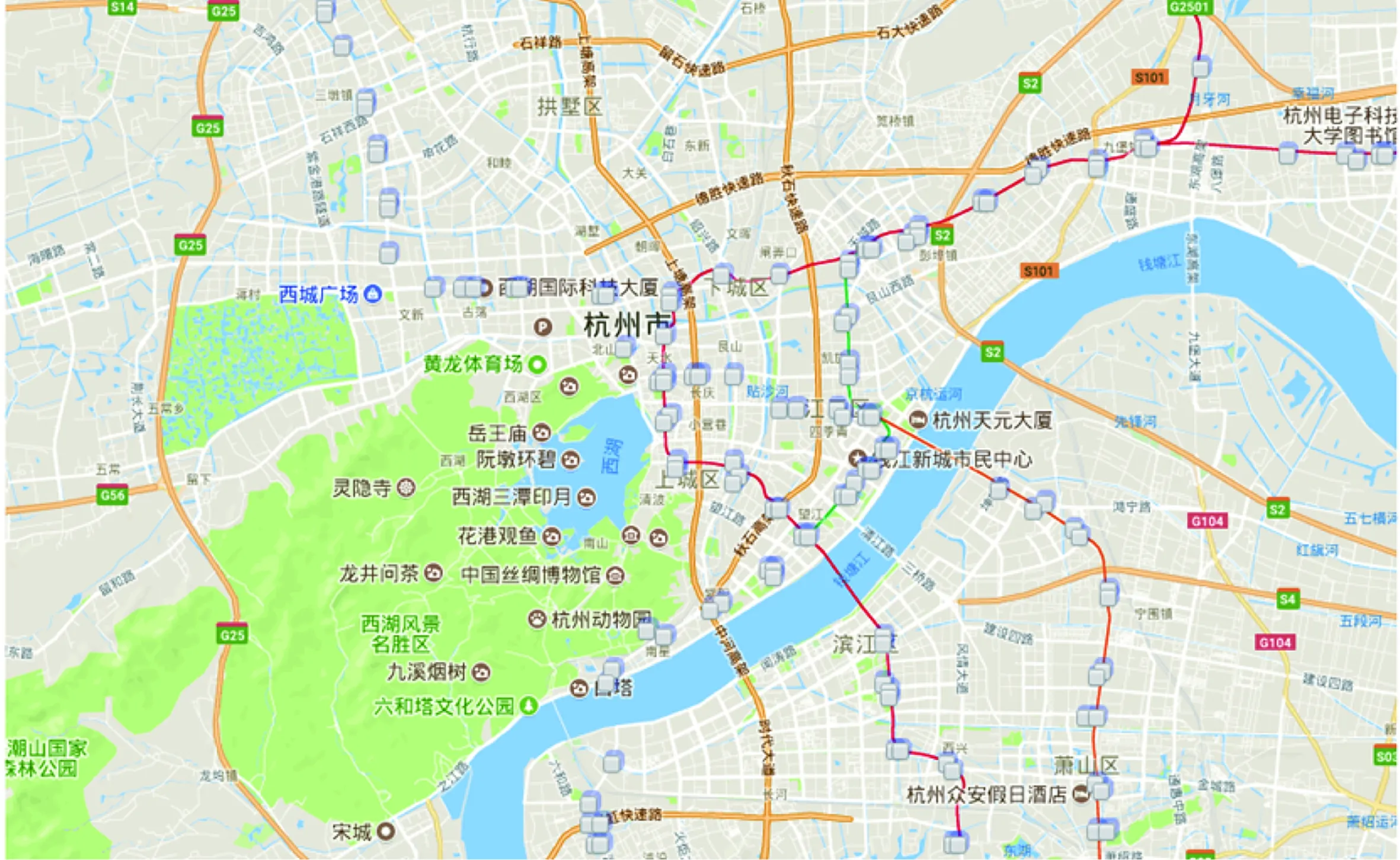
图3 基站位置显示
② 结果分析
在数据探索过程中,发现地铁3条线路,运营商C、运营商B站点lac值唯一,而运营商A不唯一。通过lac的固定值过滤运营商C、运营商B站点基站得到表St,其中运营商C站点基站1358个,运营商B站点基站个数为193个。结合查全率与查准率指标评价基站识别模型的效果。
表6中给出了模型识别的基站个数、真实的站点基站个数、TP、FP、FN、查准率及查全率。从表中能够看出运营商A基站的查全率为空,主要因为运营商A真实站点基站未知,所以没有计算出查全率。表6中运营商A、运营商B站点基站查准率、查全率全部低于运营商C相关指标,通过数据分析和真实基站地图显示,发现运营商A基站有14个站点基站不在站点范围内,运营商B有11个不在站点范围内,运营商C有2个不在站点范围内,出现基站漂移情况。
(3)乘客路径识别与结果分析
① 路径识别
交通网络中站点作为图节点,站点间时间差作为图节点间的连边权重,通过Floyd算法计算节点间最短时间距离及最短路径。设站点间时间差补偿值ΔT=300 s,迭代乘客信令数据比较乘客站点间时间差与车辆站点间运行时间差,给出乘客起讫时间及起讫点,切割乘客行程轨迹。利用节点间的最短路径补全乘客信令缺失无法计算换乘点情况。
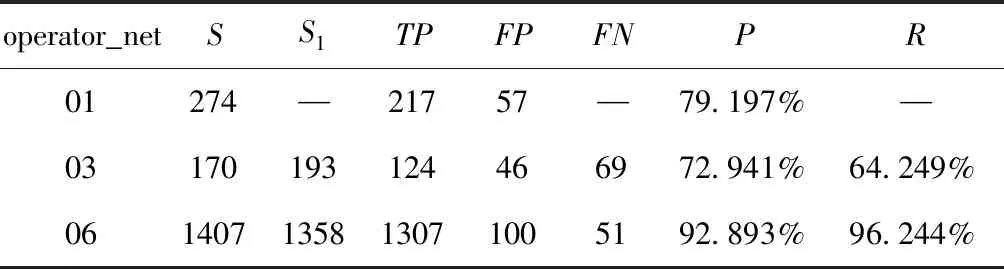
表6 基站识别结果
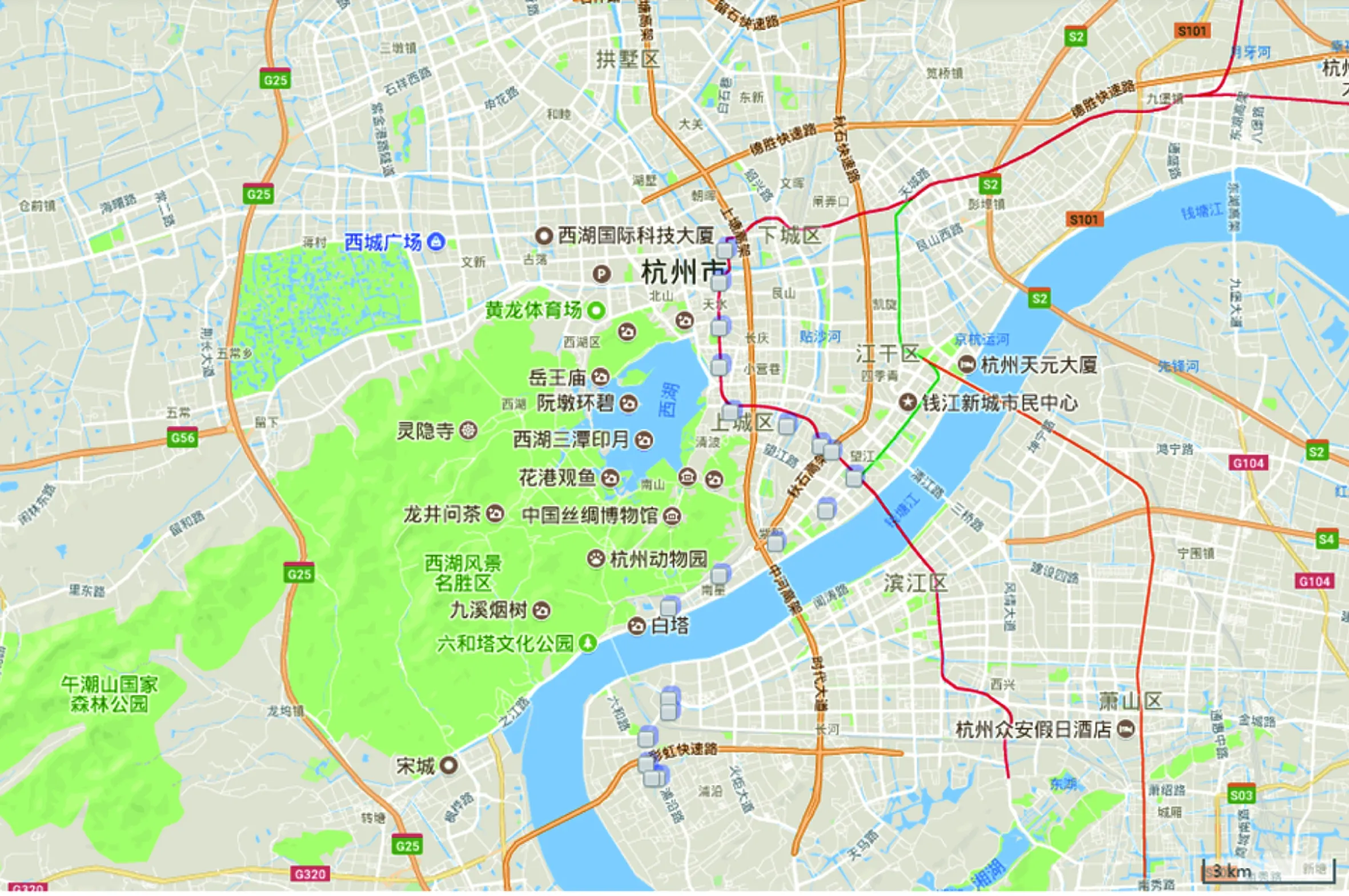
图4 地铁轨迹
随机抽样测试号码60个,每个运营商20个号码进行验证。以两个测试号码为例,表7、8中给出两个测试号码当天的地铁行程进出站时间、行程标识、进出站、换乘点等特征。
图4中给出了其中某个测试号码具体乘车路径以及进出站点和换乘站点,从图4中可以看出,测试号码在“000****ff89”站点进行了地铁线路切换。
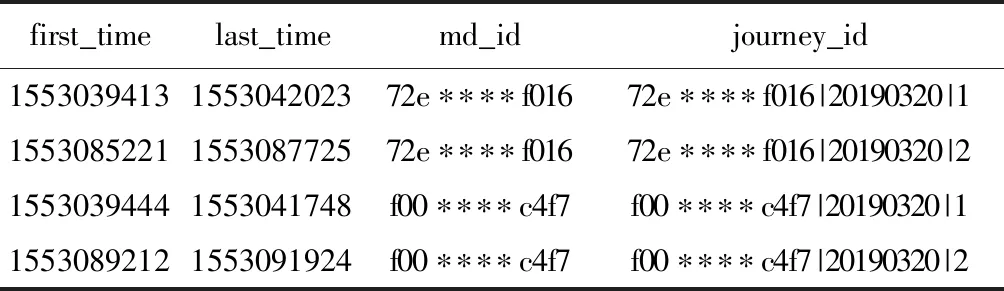
表7 乘客地铁轨迹特征(一)
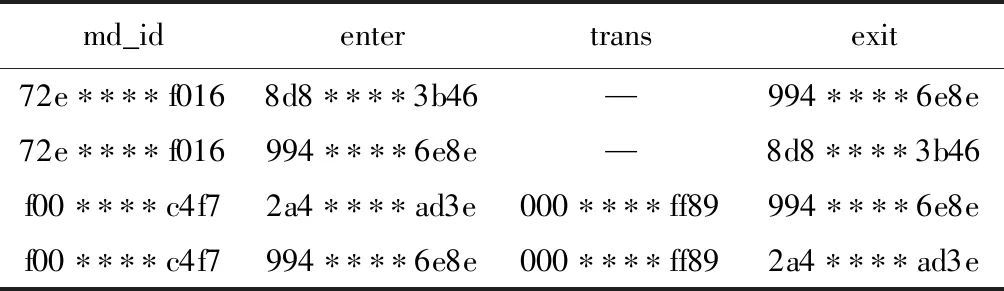
表8 乘客地铁轨迹特征(二)
② 效果分析
针对路径识别模型,分运营商随机抽取60个号码进行验证,把模型识别出的乘客进出站时间,进站时间向前推300 s,出站时间向后推300 s,再次过滤乘客当天的信令数据,验证路径识别算法进出站、换乘点及进出站点时间的识别是否正确。
表9中给出路径识别样本数据的评测效果,运营商A、运营商B识别率在70%,运营商C识别率在85%,目前分析主要原因应该是运营商C在地铁内部系统内建设基站较多、信号强度较稳定。

表9 路径识别结果
4 结 语
本文主要的工作是对轨道交通系统内乘客的路径识别,在不明确地铁基站的情况下,以地铁站点经纬度和用户信令数据为基础,构建地铁站点基站识别模型,实验结果表明,基站识别模型能够准确地识别地下站点基站,同时能够解决无法识别地面站点基站的问题。
在地铁站点基站识别基础上,按照站点基站过滤乘坐地铁的用户信令数据,结合站点之间列车运行时间差切片单次地铁行程,当天用户可能出现多个切片即多次行程。当信令数据存在缺失的情况下,需要判断缺失片段时间差是否满足站点间时间差,相符合则合并到当次行程,否则作为下一切片。实验结果表明,模型能够较准确地识别轨道交通系统内的乘客路径。
今后的工作将更加深入地研究轨道交通系统节点之间的人流量预测以及节点的脆弱性分析,以防止人流较大情况下出现踩踏事件等情况,提前预警风险。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20
铁路通信信号工程技术(2019年10期)2019-11-06
电子制作(2019年14期)2019-08-20
北方工业大学学报(2019年5期)2019-03-30
中国交通信息化(2019年2期)2019-03-25
消费导刊(2017年24期)2018-01-31
党的生活·党员电教与远程教育(2017年9期)2017-10-17
故事会(2016年21期)2016-11-10
互联网天地(2016年2期)2016-05-04
大陆桥视野(2015年22期)2015-01-06
