
基于大数据算法的电话号码与客户编号对应关系 的识别研究与实现
2019-04-01 09:10刘鲲鹏宫立华
计算机应用与软件 2019年3期
刘鲲鹏 盛 妍 何 薇 宫立华
1(国家电网有限公司客户服务中心 天津 300309)2(北京中电普华信息技术有限公司 北京 100085)
0 引 言
国网95598客服人员在受理客户来电业务时,需要对客户户号进行核对,以便解决客户来电诉求。由于大部分客户无法提供客户户号,坐席人员需要通过询问客户用电地址信息与现有档案用电地址进行匹配,获取客户户号。这种方式势必会造成坐席服务效率低下,引起客户情绪浮躁等问题。
另一方面,目前中心标签是以电话号码为对象构建,省公司标签是以用户号为对象构建,为实现中心和省公司标签共享,需要构建电话号码和用户号之间的动态精准匹配关系,支撑以电话号码为对象的客户画像和以用户号为对象的客户画像,实现中心和省公司在标签对象上的融合应用[1]。鉴于此,识别客户来电号码与户号的对应关系势在必行。
1 设计思路
从业务数据入手,客户档案中的户号和联系方式为静态数据,而95598数据、IVR数据和网站数据都属于动态数据,其中的号码与户号关系为动态关系[2]。本文从动态关系出发,更新、补充、完善静态数据,通过计算匹配度得分对号码和户号的对应关系进行识别。
2 研究内容
2.1 对应关系识别
2.1.1 有电话号码有户号情况
1) 数据源:
(1) 近两年户号不为空的95598工单数据(注:根据数据探索结果确定时间范围)。
(2) 客户档案数据。
2) 研究步骤:
(1) 数据加工。提取95598工单业务中记录户号与号码的工单,并加工关系基表(户号、号码、来电频次、时间点、地址、姓名等)。
(2) 正确性校验。为保证对应关系的准确性,对提取的对应关系进行数据校验,排除无效关系。对应关系在档案中成功匹配,无需进行校验,规定此情况匹配度得分最高;对应关系在档案没有匹配成功:此类情况需对工单数据中的用电地址信息、客户姓名与档案进行准确性校验。同时,再结合用户拨打行为特征,如拨打频次、最近拨打时间、来电时间点、拨打业务类型等行为综合校验对应关系的准确性。在数据校验的过程中,计算关系匹配度得分,根据匹配度得分确定关系可靠性。
计算匹配度得分:借助于大数据文本挖掘技术[3],对涉及到文本校验因素,进行分词并计算文本相似度,进而将文本相似度作为因素指标[4];对拨打行为指标(如号码拨打次数、拨打时间点、最近拨打时间、拨打事件类型、用电地址在历史工单中出现次数、客户姓名在历史工单中出现次数、同一户号是否在历史工单中出现,出现该户号的频次等因素)可作为行为量化因素指标;通过使用层次分析法、熵值法、因子分析法等大数据建模方法,构建指标权重划分模型,计算各个因子指标权重,进而计算关系匹配度得分[5]。
说明:在校验过程中,若不满足以上因素的检验条件,则将不满足条件的来电号码放到下一分类情况(即有号码无户号情况)进行关系识别。
3) 匹配流程:
有号码有户号情况下对应关系匹配流程图如图1所示。
2.1.2 有电话号码无户号情况
1) 电话号码记录在档案情况:
(1) 数据源:
① 近两年户号为空且来电号码在档案中有记录的95598工单数据(根据数据探索结果确定时间范围)。
② 提取步骤2.1.1中判别无效关系且号码出现在档案的95598工单。
③ 客户档案数据。
(2) 研究步骤:
① 数据加工。提取近两年户号为空且来电号码在档案中有记录的95598工单,并通过电话号码获取档案中的户号;提取2.1.1节中判别无效关系且号码记录在档案的工单;加工95598工单数据基表(记录工单编号、来电号码、客户编号、用电地址、客户姓名、拨打频次、最近拨打时间等内容)、客户档案数据基表(记录客户编号、用电地址、客户姓名、联系号码等内容)。
② 正确性校验。校验准则:此类情况需对工单数据中的用电地址信息、客户姓名与档案进行准确性校验。同时,再结合用户拨打行为特征,如拨打频次、最近拨打时间、来电时间点、拨打业务类型等行为综合校验对应关系的准确性。在数据校验的过程中,计算关系匹配度得分,根据匹配度得分确定关系可靠性。
计算匹配度得分:需借助于大数据文本挖掘技术,对涉及到文本校验因素进行分词并计算文本相似度,进而将文本相似度作为因素指标;对拨打行为指标(如号码拨打次数、拨打时间点、最近拨打时间、拨打事件类型、用电地址在历史工单中出现次数、客户姓名在历史工单中出现次数、同一户号是否在历史工单中出现、出现该户号的频次等因素)可作为行为量化因素指标;通过使用层次分析法、熵值法、因子分析法等大数据建模方法,构建指标权重划分模型,计算各个因子指标权重,进而计算关系匹配度得分。
在校验过程中,若不满足以上因素的检验条件,则将不满足条件的来电号码放到下一分类情况(即有号码无户号且号码未记录在档案情况)进行关系识别。
(3) 匹配流程:
号码记录在档案情况下对应关系匹配流程图如图2所示。
2) 号码未记录在档案情况:
此类情况由于来电号码未记录在档案中,无法通过电话号码获取相应的户号,因此需要引入大数据模挖掘术,通过文本挖掘、构建模型,识别疑似户号。
(1) 数据源:
近两年户号为空且来电号码在档案中没有记录的95598工单数据(根据数据探索结果确定时间范围);提取2.1.1节中判别无效关系且号码未记录在档案的95598工单;提取电话号码记录在档案中判别无效关系的号码工单客户档案数据。
(2) 研究步骤:
① 数据加工。提取近两年户号为空且来电号码在档案中没有记录的95598工单;提取电话号码记录在档案中判别无效关系的工单;加工95598工单数据基表(工单编号、来电号码、客户编号等)、客户档案数据基表(客户编号、用电地址、客户姓名、联系号码等)。
② 因素指标。在寻找疑似户号的过程中,需要构建因子指标,判别待识别来电客户的通话行为、身份信息、地址信息等因素是否与现存对应关系的行为一致或者相近,最终寻找此来电号码的疑似户号。现存对应关系可分为两类:基于2.1.1节和电话号码记录在档案中识别出的对应关系;其余的为档案数据中已存在的对应关系。基于以上数据源,因子指标按照数据结构分为非结构化指标与结构化指标两类。非结构化指标:客户用电地址、客户姓名、受理内容中提取信息量(户号、电话号码、姓名等)、处理意见中提取的信息量(户号、电话号码、姓名等)等文本内容。结构化指标:来电频次、来电时间点、通话时长、各个业务类型的来电频次、来电时长以及最近来电时间等通话行为。
③ 数据建模识别户号。非结构化指标相似度计算方法:基于以上几类文本数据,采用大数据文本挖掘技术,对其进行文本分词,进而将非结构化数据转化为结构化处理。将分词之后的各个文本内容根据出现频次,构造向量空间,利用余弦夹角度量方法、最长公共子序列方法、最小边际距离算法等,计算各个对应文本的相似度,相似度作为建模因子指标。通过输入非结构指标(即文本挖掘计算出的相似度),以及结构化因素指标,构建KNN数据模型计算每个号码对象与现存对应关系的相似度,最终来确定该号码对应的疑似户号,实现号码与户号的匹配。现存对应关系可分为两类:基于2.1.1节和电话号码记录在档案中识别出的对应关系;其余的为档案数据中已存在的对应关系。在训练KNN模型的同时,需确定出合适的K值作为户号类别归属的判别,在筛户号归属的同时,需遵从如下原则:
在邻近的K个可选户号归属中,若属于2.1.1节与电话号码记录在档案中的对应关系优先选取该户号(号码关系相对可靠),否则按照模型相似度得分来分配疑似户号归属。
(3) 匹配流程:
号码未记录档案情况下对应关系匹配流程图如图3所示。

图3 号码未记录档案情况下对应关系匹配流程图
综合两类情况找寻的户号信息,进行合并处理,形成户号与号码的对应关系。在合并后的对应关系中,对应关系存在如下三种情况:
(1) 号码与户号1对1;
(2) 号码与户号1对多;
(3) 号码与户号多对1。
针对号码与户号多对多的情况,需进行优先级划分。
2.2 优先级划分
对于一户多号、一号多户的对应关系,需制定关系优先级,选取最可靠的对应关系。制定如下规则对其进行优先级划分:
(1) 针对有号码有户号分类情况,按照匹配度得分,选取一户多号、一号多户最为可靠的关系;
(2) 针对有号码无户号且号码出现在档案分类情况,按照匹配度得分,选取一户多号、一号多户最为可靠的关系;
(3) 针对有号码无户号且号码未出现在档案)分类情况,按照模型相似度得分,选取一户多号、一号多户最为可靠的关系。
综合三部分对应关系,针对合并之后出现一户多号、一号多户的情况再次进行优先级划分,划分规则遵从如下规定:
满足条件第一种对应关系的优先级最高;满足条件第二种对应关系的优先级次之;满足条件第三种对应关系的优先级最低。
3 模型算法
为实现来电号码与客户号的动态匹配,需引入大数据分析、挖掘技术,校验关系准确性以及识别来电号码的疑似户号。在进行关系动态匹配的过程中,需用到如下三方面大数据技术:
(1) 文本挖掘技术:需对用电地址、客户姓名、工单受理内容等文本进行分词,并计算文本相似度得分;
(2) 权重划分模型:通过权重划分模型输出各个因子指标权重,进而计算对应关系匹配度得分,校验准确性[6];
(3) KNN模型:针对未找到户号的来电工单,构建KNN模型,通过模型输出该号码的疑似户号。
3.1 文本挖掘
3.1.1 中文分词技术
中文分词指的是将汉字序列切分成若干个词[7]。中文分词是文本挖掘的基础,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个词,则匹配成功[8]。常用的几种机械分词方法如下:
(1) 正向最大匹配法(由左到右的方向);
(2) 逆向最大匹配法(由右到左的方向);
(3) 最少切分(使每一句中切出的词数最小);
(4) 双向最大匹配法(进行由左到右、由右到左两次扫描)[9]。
3.1.2 词向量技术
自然语言理解的问题要转化为机器学习的问题,构造词向量[10],并计算相似度得分:
编辑距离,表示从一个字符串转化为另一个字符串所需要的最少编辑次数,这里的编辑是指将字符串中的一个字符替换成另一个字符,或者插入删除字符。编辑距离的核心就是如何计算出一对字符串间的最小编辑次数,我们可以使用动态规划的思想来计算其最小编辑次数[11],两个字符串a=a1a2…an,b=b1b2…bm 的编辑距离递归计算公式如下:
(1)
(2)
(3)
式中:w表示增删改三种操作的权重,一般定义为:

(4)
di0=i表示从b=b1b2…bi删除为空的编辑次数;d0j=j表示从空插入成a′=a1a2…aj所需的编辑次数;dij则是对动态规划中分解子问题的过程。其逻辑关系较为复杂,算法时间复杂度较高。
3.2 权重划分(熵权法)
熵权法作为一种客观赋权法,其优势在于可以避免赋予权重的主观性,符合数学逻辑且具有较为严格的数学意义[12]。熵权法的基本运算过程如下:
3.2.1 原始数据矩阵标准化处理
由于得到的原始数据差异较大,首先需要对数据进行无量纲化的处理。
(5)
对正指标无量纲化处理公式为:
(6)
对负指标无量纲化处理公式为:
(7)
得到新的矩阵记为Aij。
3.2.2 指标熵值的计算
(8)
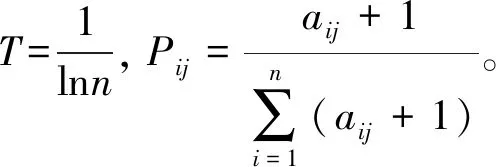
3.2.3 各指标权重的确定
(9)
3.2.4 计算综合得分
(10)
式中:Wj表示每个指标占的权重,Aij表示的是调整后的Xij值。
在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;可根据各项指标的变异程度,利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
3.3 KNN模型
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。该方法在决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别[13]。
KNN算法实现步骤综述:
(1) 计算样本数据之间距离;
(2) 按照距离的递增关系进行排序;
(3) 选取距离最小的K个点;
(4) 确定前K个点所在类别的出现频率;
(5) 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
4 模型构建
4.1 因子指标设计
针对寻找到的对应关系需进行关系校验,通过文本挖掘算法计算文本相似度得分,进而将文本相似度得分以及拨打行为指标作为构建权重划分模型的输入因子,通过模型计算相似度得分,校验关系可靠性。因子指标设计成宽表,如表1所示。

表1 宽表

续表1
4.2 模型结果输出
4.2.1 计算各类因素指标权重
通过文本分词构造词向量,并计算出地址相似度、姓名相似度得分作为模型的输入因子,进而再结合拨打行为、拨打偏好等行为指标,构建权重划分模型,模型输出各类指标权重如表2所示。

表2 模型指标权重
4.2.2 计算对应关系匹配度得分
依据各类指标权重值,计算对应关系(户号与号码对应关系)匹配度得分,得分分布如表3所示。
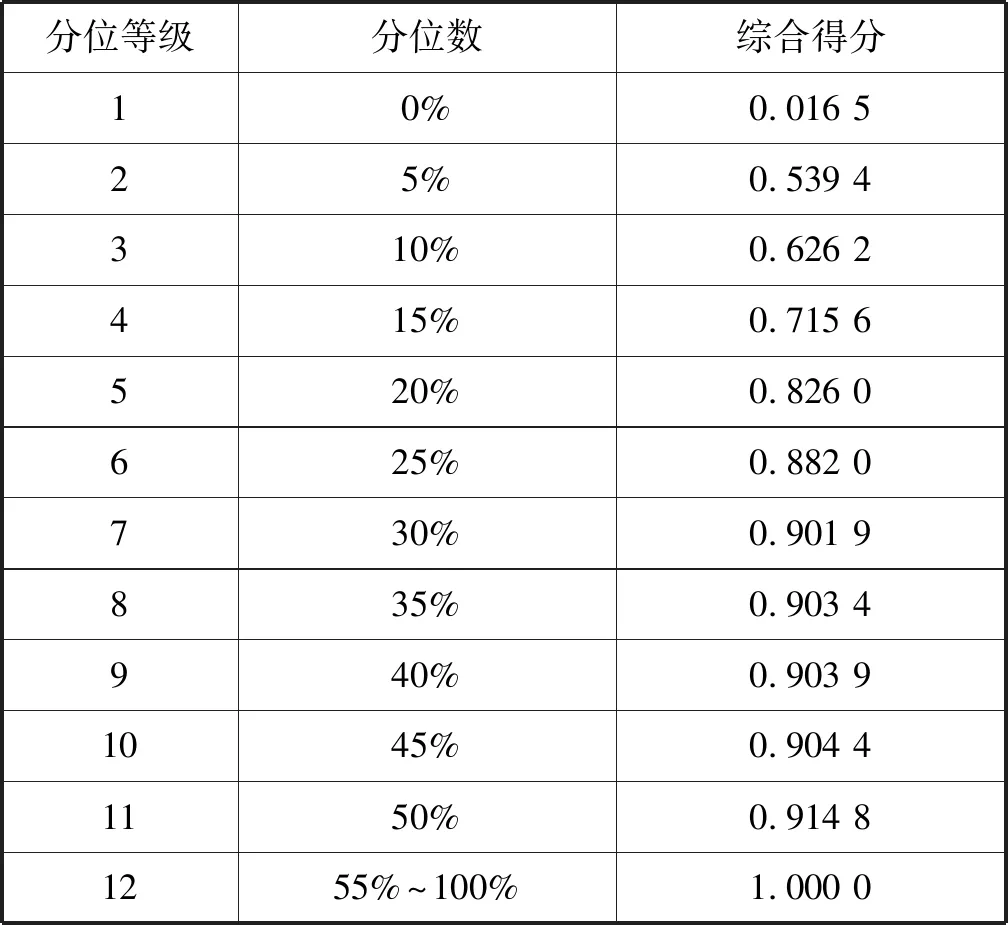
表3 得分分布表
4.3 模型效果评估
4.3.1 结果验证
选取浙江省2016/04/01至2017/04/01工单数据作为建模数据,通过构建权重划分模型,计算对应关系匹配度得分。选取未来5个月内(2017/04/01-2017/08/31)有过拨打且记录客户户号的工单作为模型验证集,对模型输出结果进行关系验证,并将数据作十分位,分别验证模型模型的命中率、覆盖率情况,验证结果如表4所示。
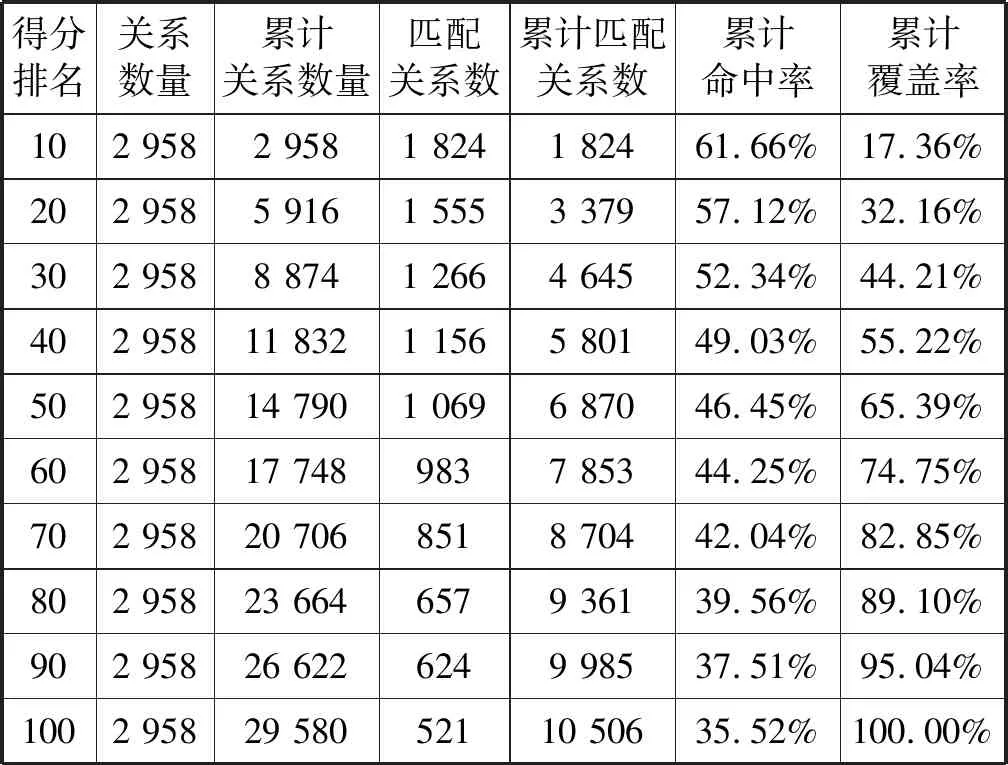
表4 模型结果表
从表4可知,分值越高,模型命中率越高,符合分值越高,户号与号码对应关系越紧密的趋势特征。模型命中率在分值排名前70%以内都高于40%,并且在分值前70%模型覆盖率达到了82.5%,故建议选取分值排名前70%作为模型预测有效对应关系。
4.3.2 不足之处
(1) 目前此方法主要是以95598工单数据为主线寻找户号与号码对应关系,后期可从智能互动网站、掌上电力、缴费等渠道获取对应关系进行扩充;
(2) 此方法在进行KNN模型识别匹配过程中,计算复杂度较高,对匹配数据集按照地址范围进行缩减,一定程度上会降低对应关系准确性;
(3) 此方法在构建权重划分模型时,通过模型计算各类指标的权重,但一定程度上会忽略业务影响,后期可结合专家评分,综合评判各类因素权重得分。
4.3.3 不可控因素
(1) 由于95598话务工单地址信息记录不规范,导致地址相似度得分存在偏差;
(2) 由于95598话务工单姓名记录不规范,导致姓名相似度得分存在偏差;
(3) 95598受理内容信息记录不规范,导致截取客户户号信息、用电地址等信息不准确;
(4) 客户档案信息录入不及时、且存在一户多号情况(如开发商楼宇信息,针对一个户号对应小区所有业主信息)。
5 结 语
从浙江省近1 年受理工单情况入手,通过构建统一身份识别模型,共有效识别出对应关系272万,涉及工单量为431.74万工单,覆盖浙江省近1年工单总量的67.35%,即有67.35%的受理工单通过模型有效识别出户号。
综合以上,本文创新点如下:
(1) 基于大数据平台分布式计算环境,对海量全业务95598工单数据、客户档案数据进行数据分析、数据建模,弥补传统数据抽样建模的不足,进而提升模型预测准确度;
(2) 创新性地引入文本相似度计算方法,对工单用电地址、客户姓名进行分词,进而构造词向量空间,计算文本相似度;
(3) 创新性地使用权重划分模型,对各项因素指标实现客观权重评级;
(4) 创新性地引入KNN模型算法,实现对应关系(户号与号码对应关系)增量有效识别;
(5) 基于大数据平台分布式计算环境,采用分布式计算方法(MapReduce计算、Spark内存计算),并行地实现数据加工处理、模型计算,提升模型计算高效迭代性,实现模型快速、高效精准输出。
猜你喜欢
科技与创新(2022年22期)2022-11-18
科技视界(2021年5期)2021-07-12
科学与财富(2021年33期)2021-05-10
债券(2021年1期)2021-02-04
债券(2020年4期)2020-08-04
小学生学习指导(低年级)(2020年6期)2020-07-25
故事会(蓝版)(2020年1期)2020-01-19
奥秘(创新大赛)(2019年10期)2019-10-24
商周刊(2018年26期)2018-12-29
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
