
社区矫正人员位置信息挖掘
2019-04-01 09:10郭红钰
计算机应用与软件 2019年3期
王 晟 郭红钰
(华北计算技术研究所公安系统部门 北京 100083)
0 引 言
社区矫正工作是司法体制改革工作的重要内容,随着司法体制改革工作的开展,社区矫正得到了快速的发展。目前,在社区矫正领域并没有对社区矫正人员在界内的行为轨迹进行分析,只是对人员是否有越界的行为进行检测。
矫正人员再犯风险评估是社区矫正的一项基础性工作,具有迫切的现实需求。实际中,矫正人员再犯风险主要来自于自身环境和社会环境两个方面,其中:自身环境信息包括家庭背景、受教育程度、健康状况等数据,但这些信息更多是静态的甚至可以伪装,难以反映矫正人员的真实状态。而和社会环境相关的动态信息对矫正人员再犯影响更大,这些信息往往隐含在矫正人员日常动态行为中。目前,社区矫正人员佩戴了具有GPS功能的定位手环或手机,能准确获取出行位置信息[3]。为此,需要获取和分析矫正人员的轨迹大数据。
本文研究的是社区矫正人员的轨迹信息,将监测的人员位置信息和时间地理位置等相结合[11],试图发现人员轨迹的规律[7],旨在对社区矫正人员的轨迹信息进行拆分归类,给监管业务提供支持。
1 轨迹分段
轨迹是符合一定条件的点所形成的图形,或者说,符合一定条件的点的全体所组成的集合,叫做满足该条件的点的轨迹。一个社区矫正人员一天的轨迹包含了这个人整天的活动地点和路径,这些轨迹错综复杂,既有该人员的活动地点,也包含着其途经往返的点。从整体上来分析轨迹信息是很困难的,也不能够提取到与其他人员的共同点。所以在社区矫正领域对人员轨迹的分析首先就是要将该轨迹来进行分段处理[13],这样能够将一个整体的难处理的问题分解成一个个细小的子问题,也容易对各个轨迹特征进行分析统计。
1.1 轨迹特征点识别
定义1轨迹:设gi为一个移动物体的第i个GPS信号点,那么一连串的含有时间标记的GPS点则可以表示该移动物体从g1移动到gi的轨迹TR,TR={g1g2…gigi+1…gn}。
定义2轨迹特征点:在一条轨迹中选取一些点,这些最能代表轨迹特征的点就被称为轨迹特征点。
在将轨迹分段前,首先就是要简化轨迹,找到社区矫正人员的轨迹特征点。如图1所示。

图1 社区矫正人员的轨迹图
可以看到,该人员外出经过一系列的地点,最终又回到了起点。总体上说,只能判断该人员在这一天外出了,但是他外出时,到底目的地是什么并不清楚。在社区矫正领域,人员的活动情况和时间紧密相连,在一个场所停留时间足够长才表示该人员在该场所活动。
同时在该场地内部的行为轨迹,我们并不关心。换句话说,本文关心的是该人员在某个时间是否到过某个场地。在现有的轨迹识别算法中,取特征点时一般是根据轨迹的变化角度、变化速度等[5]。然而在一个场地内的轨迹曲曲折折,变化快慢与否对本文来说无关紧要。如何去掉这些次要因素,选取需要的轨迹特征点是本文解决的一个问题。
考虑到人员行为的时间和位置特点,本文对具有噪声的基于密度的聚类方法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法进行了改进,从而实现了特征点的选取。
1.2 DBSCAN算法
DBSCAN这是基于密度的算法,它能够较为效率地去除噪声点,聚类后的结果是将数据分成了若干个簇,簇的形状可以是任意的,没有要求。
在DBSCAN算法中,首先需要设置两个参数Eps和MinPts。Eps代表的是检索时的半径;MinPts代表的是判断是否是核心点时需要包含点的最小数目。该算法将输入点分为三种:核心点、边界点和噪声点。核心点是指在该点的半径为Eps的范围内有最少MinPts个数的点;边界点指在该点同样大小的范围内没有MinPts个数的点并且该点在其他核心点的Eps邻域内;最后剩余的点就是噪声点。在该算法中,从一个点向外扩散的时候需要满足一定的条件——密度相连[18]。
DBSCAN算法的目的是找到密度相连对象的最大集合。算法的具体过程描述如下:扫描全部数据集,找到其中任意一个核心点,寻找从该点出发的所有密度相连的数据点。将该簇标记为已查找,重新扫描标记为未查找的点的数据集,寻找没有被聚类的核心点,重复以上步骤,直至数据集中没有新的核心点。
1.3 改进的DBSCAN算法
通过DBSCAN算法可以找到不同形状的簇,但是对于社区矫正数据来说,时间是一个很重要的属性,同一个场所,在白天和晚上活动有可能会带来很大的不同。比如说,白天去别人家和晚上去别人家就会有区别,白天在街上闲逛与晚上在街边蹲点就不一样等。DBSCAN算法无法区分不同时间经过同一个位置的数据,所以本文通过引进时间变量来解决这个问题。给每个点加入时间属性来代表该点采集的时间,在DBSCAN算法中遍历每个点,判断它的Eps邻域时需要按照时间顺序来往前和往后统计,即加入TEps代表时间邻域。统计对象p的邻域内的点需要同时满足Eps和TEps,这样就把不同时间相同位置的数据区分开来了。
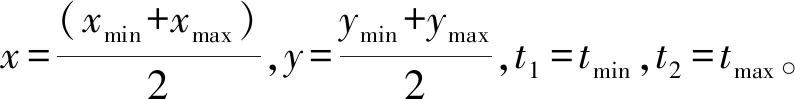
1.4 轨迹分段
时空轨迹分类的过程主要分为轨迹预处理、特征提取、建立分类器3个阶段[8]。将运动轨迹作为整体聚类会丢失相似子轨迹段,而相似子轨迹段在实际应用中用处很大[9]。
在获得了轨迹的特征点后,下一步可以进行轨迹分段了。上文提到,在社区矫正领域,时间是很重要的属性,同一个地方,在不同的时间点停留有着很大的区别。在一般轨迹分段的时候所采用的轨迹角度和速度变化[4]在社区矫正领域反而并不重要。所以,本文按照时间属性进行分段。
首先根据业务特征给出需要分割的时间段,比如一般意义上的白天和黑夜的时间段,或者禁止外出的时间段等。然后分别扫描各时间段内的所有点,如果该特征点的持续时间在多个时间段内,那么在这些时间段中都包含该点。最后将各组的点按照时间顺序连线就得到了分段后的轨迹。其伪代码如下:
SET T1,T2,T3,…,Tn
//设置分类时间段
GET p(x,y,t1,t2)
//获取特征点
WHILE i //遍历分类的时间段 IF (t1in ti) or (t2in Ti) then p in List 是一个重大人生角色的转变,从一个天真烂漫,倍受宠爱的少女,变为一个要哺育宝宝的妈妈。尤其是一些较年轻的新手妈妈,自己好像还是一个孩子,一下子要面对孩子的哭闹,半夜要给宝宝喂奶,换尿布,这些突如其来的变化,会给心理造成一定的影响。 //将符合条件的特征点放入所属的集合中 END 轨迹分段后要对分段后的轨迹进行聚类,这是为了对多个人员或者同一个人员多个天数的数据进行比对,这样才可以获得轨迹的共性,进行进一步的分析。 将轨迹分段后,可以对多个对象的轨迹片段进行聚类,这样可以为社区矫正人员的行为分析、预测和异常行为监控等做准备。 轨迹聚类的算法有很多,比如针对空间网络的聚类[10]、基于结构相似的轨迹聚类[4]等。对于轨迹聚类来说,如何衡量两个轨迹之间的距离或相似性是需要解决的核心问题[2]。传统的异常点检测算法中衡量对象之间距离的方式无法直接用来检测两个轨迹之间的距离[1],这是由于轨迹是由若干个点组成的,无法单独去比较其中的一个点。目前来说,Lee等[17]提出的TROAD检查方法利用模式识别领域的Hausdorff距离来计算轨迹子段之间的距离是一种有效的方式。在该方法中的Hausdorff距离是由需要测量的两个有向线段之间的平行距离、垂直距离和夹角三个部分加权求和求得的。这个方法考虑的是轨迹的空间特性,但是对于社区矫正领域,两个轨迹的方向、水平距离和垂直距离都不能代表它们是否相似。我们需要考虑更多的是轨迹特征点的实际意义[15],而与到达轨迹特征点的途径无关。这是因为在两个不同的城市有着相同类型的建筑,分别经过这两个建筑的轨迹是相似的,而它们的方向、水平距离和垂直距离都毫无意义。考虑到这个因素,结合地理位置信息[16]来表示轨迹距离会更好些。 将采集的GPS坐标和地图坐标对应,在地图上标识出坐标后可以识别周围的建筑物信息。由社区矫正的业务特点将建筑物分为几类,比如医院、娱乐场所、体育场所和餐馆等。赋予这几类建筑所占的权重,将轨迹经过的建筑物的权重进行比较,权重相差越小则轨迹距离越短,越相似。具体的轨迹距离可以这样表示:两个轨迹之间的距离d(tr1,tr2)=|M(tr1)-M(tr2)|,M(tri)表示该轨迹的权重,一条包含n个点的轨迹的权重可以这样表示: M(tri)=f(t1)·(a1M1)+f(t2)·(a2M2)+…+ f(tn)·(anMn) 式中:f(ti)表示该时间段的权重系数;Mi表示该建筑物对应的权重;ai标识在该场所的持续时间。 输入:Eps—半径 MinPts—给定点在E邻域内成为核心对象的最小邻域点数。 D—集合。 输出:目标类簇集合 方法:Repeat 1) 判断输入线段是否为核心对象 2) 找出核心对象的E邻域中的所有直接密度可达线段。 Until 所有输入线段都判断完毕 Repeat 针对所有核心对象的E邻域内所有直接密度可达线段找到最大密度相连对象集合,中间涉及到一些密度可达对象的合并。 Until 所有核心对象的Eps邻域都遍历完毕 本文采用的数据是社区矫正人员的轨迹数据,选取了一个人的轨迹数据。由于数据的保密性,本文对数据的信息做了处理,不显示其周围具体的建筑信息和身份信息等,只用事先根据业务特点分好的建筑类型来表示其活动场所。可以看到该人员这天的密集活动区域有几个,通过上文的轨迹特征点选取算法,选取特征点后的轨迹如图2所示。 图2 简化后的轨迹图 可以看到,该人员在这一天从A点(家)出发去了C点(医院)然后回到了B点(家)。通过对该人员的其他更多天数的轨迹经过同样的处理后,经过聚类发现其大致与这一天的轨迹图形是一样的,但是目的地不一样,更多的目的地是超市和饭店。由此可以得出:这一天该人员的轨迹与平常不一致,经过分析可以知道该人员是去了医院。这样,通过对轨迹的聚类可以提取出人员的日常轨迹特征,为社区矫正业务提供支持。 本文选择的数据是社区矫正人员的轨迹数据集,从中选择了数人的百余天的数据进行分类,结果如表1所示。 表1 数据统计对比 本文用a、b、c来代表三个人。由表1可以知道a基本上都在家中,偶尔出超市买点东西,有几天去了医院;b超过三分之二的天数都去了超市,而且在数据处理的过程中发现都去的同一家超市,有可能b在这个超市工作也有可能真的是每天去超市养成的习惯;c则是全部都在家,并且在数据处理时,发现轨迹点都是同一个点,这有可能是腕表失效或信号太弱等情况。 通过对轨迹数据的分段、简化[14]、聚类后可以发现他们的轨迹是有规律的,提取出这些特征后可以为以后的业务需求提供数据支持。 本文通过学习研究DBSCAN算法,在社区矫正领域得以改进、应用,成功地将社区矫正人员的行为轨迹拆分并加以聚类,能较好地将他们的日常轨迹和异常轨迹区分开来。2 轨迹聚类
2.1 轨迹距离
2.2 轨迹聚类算法
2.3 聚类效果
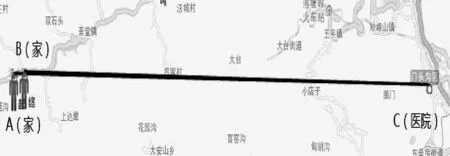
3 实验结果统计分析

4 结 语
猜你喜欢
农业工程学报(2022年7期)2022-07-09
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
科技传播(2019年23期)2020-01-18
人民调解(2019年2期)2019-03-15
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化(高中版.高一使用)(2018年1期)2018-02-10
理科考试研究·高中(2016年10期)2017-01-17
太空探索(2016年9期)2016-07-12
Coco薇(2015年7期)2015-08-13
