
基于混合地理加权Fay-Herriot模型的小域估计
2019-03-30 08:20李腾魏传华于力超
应用数学 2019年2期
李腾,魏传华,于力超
( 中央民族大学理学院统计学系,北京100081)
1.引言
近二十年来,小域估计(Small area estimation)作为抽样调查领域的一种方法,得到越来越多的重视.理论上,小域估计模型的设定以及有关的估计和检验等统计推断问题得到了深入的研究.应用上,小域估计方法已经在经济、社会、环境、卫生和流行病等多个领域的实际问题中得到应用.有关小域估计的详细介绍可参考著作[14].
小域估计方法主要分为基于设计的方法和基于模型两类方法,其中基于模型的方法能够充分利用到辅助信息而得到重视.一般来说,基于模型的小域估计方法所使用的模型一般分为区域层次模型和单元层次模型两类,其中区域层次模型使用较多的是Fay和Herriot[7]提出的能将直接估计和未知参数联系起来的一类随机效应模型,文献称之为Fay-Herriot模型,关于该模型的理论研究可参考文[1,9,16,21].
目前关于Fay-Herriot模型的研究和使用上大都假定了各个区域之间是不相关的,同时使用的是线性混合效应模型.然而,实际问题中因变量与自变量之间的关系不一定是线性形式,错误的模型设定会导致推断偏离实际情况,为了解决这一问题,多种非参数与半参数混合效应模型被用到小域估计中,具体内容可参考文[10,17].另外在很多类实际问题中,抽样区域之间并不是独立的,而是具有空间效应,从而多类空间混合效应模型被提出用以小域估计,有关文献可参考文[3,11,15].
空间效应一般分为空间自相关性和空间非平稳性两类,以往的研究大都是基于空间自相关性来建立空间混合效应模型.Chandra等[4]基于地理加权回归方法提出了一类空间变系数混合效应模型.地理加权回归模型是由Brunsdon等[2]提出来的一类空间变系数模型,模型系数作为地理位置比如经度纬度的光滑函数,可以直接刻画因变量和自变量之间的关系随着地理位置的变化而变化,关于地理加权回归的详细介绍可参考著作[8].实际数据分析中,更为普遍的情形是一部分系数是地理位置的光滑函数,另外一部分是常数,这种半参数空间变系数模型被称为混合地理加权回归模型,关于这类模型的研究可参考文[13,18―20].为了更好的刻画抽样区域之间的空间非平稳性,本文将在传统Fay-Herriot模型的基础上提出一类半参数空间变系数混合效应模型,并研究相应的小域估计量及其性质.
本文剩余部分做如下安排:第二节主要介绍半参数空间变系数混合效应Fay-Herriot模型的估计;第三节将进行小域估计量的均方误差估计;第四节对所提方法进行数值模拟;总结和展望将在最后一节给出.
2.模型的估计
假定目标总体U由m个小区域构成,且各小区域间都不重叠,每个区域可看做一个单元.若将第i个区域(i=1,2···m)的目标参数记为Yi,xi和zi为辅助变量.其中,xi的系数β是固定的,zi的系数α(ui,vi) 随地理位置(ui,vi) 变化而变化(u和v分别表示研究区域i的经度和纬度),bi是随机效应,yi为Yi的直接估计量,ei为抽样误差.根据上面的符号,区域层次的半参数空间变系数混合效应模型可记为如下形式

其中β为p×1维向量,α(ui,vi) 是q×1 维向量.常值系数β和系数函数α(ui,vi)对应于固定效应.bi为随机效应,且它的均值为0,方差为σ2b,随机误差项ei ∼N(0,Ψi),其中Ψi已知.同时假设不同区域间的随机误差项是相互独立的,Ψ= diag1≤i≤m(Ψi).为了将模型表达得更加清晰,将模型(2.1)记为如下矩阵形式

其中

y的协方差矩阵记为COV(b+e)=Σ,且有Σ=σ2bIm+Ψ.
现运用文[6,18]中的Profile最小二乘方法估对模型(2.1) 进行估计.模型中常值系数假设已知,那么(2.1)可记为

进一步模型可表示为以下的矩阵形式

Chandra等[4]所研究的空间变系数混合效应模型便是模型(2.3)这种形式,同时空间变系数混合效应模型中,Chandra等用局部常数方法来估计系数函数.本部分将采用局部线性方法对模型(2.3)中系数函数进行估计.设研究区域中某一点为(u0,v0),将(u0,v0) 到第i区域的距离设为d0i.利用Brunsdon等[2]在(u0,v0) 点构造一组权,使wi(u0,v0) =k(d0i/h),其中k(·) 为核函数,h为光滑参数(或窗宽),我们将在下文介绍.
根据Taylor展开公式,在(u0,v0) 邻域内有

其中α(u)(u0,v0) 和α(v)(u0,v0) 分别表示α(ui,vi) 关于经度u和纬度v的偏导数在(u0,v0)处的值.于是α(u,v) 在(u0,v0) 处的估计可通过使得
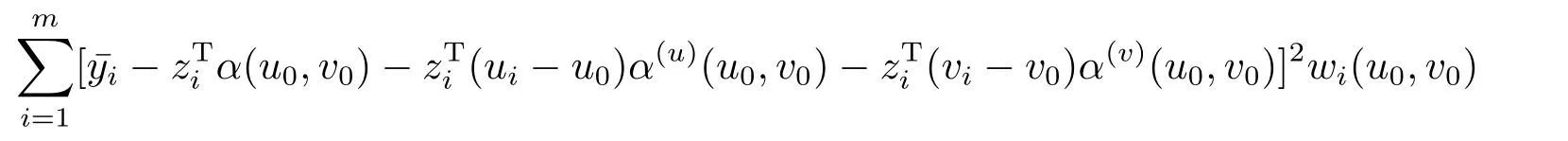
达到最小得到.由加权最小二乘法可得

其中Γ(u0,v0) = (Z,U(u0,v0)Z,V(u0,v0)Z),Z= (zT1,zT2,··· ,zTm)T,U(u0,v0) = Diag(u1−u0,u2−u0,··· ,um−u0),V(u0,v0)=Diag(v1−v0,v2−v0,··· ,vm−v0),W(u0,v0)=Diag(w1(u0,v0),w2(u0,v0),··· ,wm(u0,v0)).如果取(u0,v0) 为(ui,vi) ,则由(2.5)式得α(u,v) 在各样本点的估计为

从而M的估计可定义为

其中

将式(2.4)中M用其估计值代替,整理可得如下线性混合效应模型

整理得

从而定义β的广义profile最小二乘估计为


由混合线性模型的理论可知b的经验最佳线性无偏估计量(EBLUP)为

那么第i个区域的随机效应的EBLUP表示为

其中lTi为1×n维向量(0,0,··· ,0,1,0,··· ,0) ,在第i个位置取值为1,其他位置取值为0.
在对(u0,v0)处的模型系数函数值α(u0,v0)进行估计时候,每个样本点(ui,vi) 都对应一个权重wi(u0,v0).一般来说,距离(u0,v0) 近的观测值对(u0,v0) 的回归函数(或参数)估计影响程度大,距离远的观测值对其影响程度小.因此,设d0i为(u0,v0)到(ui,vi) 的距离,我们应将较大的权重赋予距离近的点,较小的权重赋予距离远的点,实际应用中可以采用Gauss核函数作为权函数

其中h称为光滑参数或窗宽,反映了拟合曲线的光滑性.h的大小通过“去一观测主题”交叉证实法来确定.
现在可得到小域估计中第i个未抽区域的目标参数估计量,即地理加权经验最佳线性无偏估计量.记为.该区域目标参数可根据模型参数估计量和本身的辅助变量进行估计,的具体表达式如下:

由于参数β,α(ui,vi)和bi的估计需要σ2b和Ψ作为辅助信息,但协方差参数θ=σ2b是未知的,我们可以类似于文[4],利用极大似然估计(ML)方法或约束的极大似然估计(REML)方法来对θ=σ2b进行估计,REML方法是ML方法的修正,它考虑了ML 方法估计固定效应造成自由度损失的问题.值得注意的是这两种方法其实都是profile似然估计方法,也就是将模型中的非参数部分消去,从而只剩下参数分量.由于估计方法不同,两种方法得到的估计值也是不同的.
ML算法
1) 计算各区域与样本点间的距离d;
2) 计算各区域对应的权重矩阵W(ui,vi);
3) 通过广义交叉验证确定光滑参数h;
4) 计算对数似然函数

将上式中的M用(2.7)中ˆM代替,可得如下的对数似然函数

5) 对l(β,α,θ)关于θ求一阶偏导,得s(β,α,θ)

其中Σ(θ)=∂Σ/∂θ=Im,Σ(θ)=∂Σ−1/∂θ=−Σ−1Σ−1;
6) 对-l(β,α,θ)关于θ求二阶偏导,得I(θ)

7) 假定θ初始值为0,通过得分算法对下式进行迭代,这里的a指第a次迭代过程.

8) 当迭代收敛时,我们得到θ的估计值
REML算法
1) 计算各区域与样本点间的距离d;
2) 计算各点对应的权重矩阵W(ui,vi);
3) 通过广义交叉验证确定光滑参数h;
4) 计算极大似然函数

5) 对lR(β,α,θ)关于θ求一阶偏导,得sR(β,α,θ):

6) 并对−lR(β,α,θ)关于θ求二阶偏导,得IR(θ),
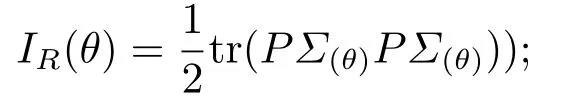
7) 假定θ初始值为0.通过得分算法对下式进行迭代,这里的a指第a次迭代过程,

8) 当迭代收敛时,我们得到θ的约束极大似然估计值
3.小域估计量的均方误差估计
我们采用文[12]对混合效应模型均方误差的求解方法对小域估计量的均方误差进行求解.得到如下结论:
定理3.1小域估计量是抽样集y的线性组合.两者有如下关系:A、B和D分别为


证

定理3.2小域估计量的均方误差其中

g3i(θ) =的渐进协方差,其中A、B含义同(3.1)式.
证和式(2.13)类似,当协方差变量θ=σb2已知时,我们可得到该估计量的地理加权最佳线性无偏估计量记t(θ) .

假设β真值已知,通过β真值估计的α(ui,vi) 和bi来表示该估计量设为t∗(θ).

假设β,α(ui,vi)和bi真值均已知,那么该统计量为

根据小域估计量的MSE定义式得到

式中第一项为已知β时小域估计量的方差,记为g1i(θ);第二项为回归系数时引起的方差部分,记为g2i(θ).
式(3.5)中

其中
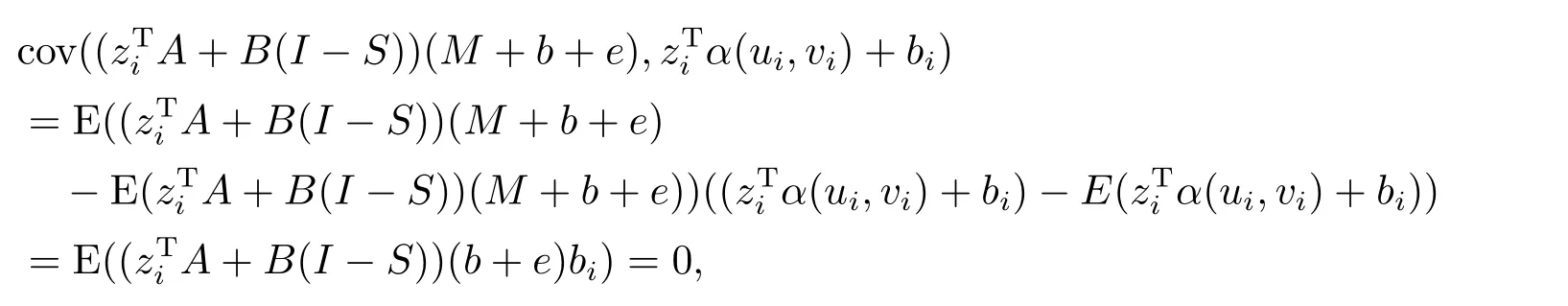
则

式(3.5)中

因此有

因为θ=σ2b未知,我们需要用估计值代替真值进行均方误差求解.所以

由于式(3.8)很难直接处理,因此借助文[5]中Taylor展开的方法得到近似估计,记d(θ) =得



首先采用REML算法对小域估计量的均方误差进行估计.由Rao(1975)我们知

结合式(3.11)有


且


4.数值模拟
本部分利用数值模拟来考察所提模型的有效性.为了进行比较,数值模拟实验假定在协方差参数已知和协方差参数需要估计的情况下,分别对模型参数进行估计.
模拟中假定模型形式为
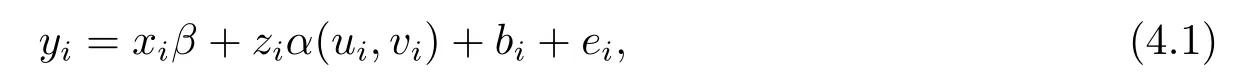
其中i=1,...,m2,研究区域是边长m −1个单位长度的正方形,n=m2个样本观测值正好落在分布均匀的m×m格子点上,则每个观测点的经纬度坐标(ui,vi) 为

其中mod(i −1,m)为i −1与m相除后的余数,的整数值部分.
假定固定系数β= 3,固定系数所对应的变量xi满足xi ∼N(1,1),变系数所对应的变量zi满足zi ∼U(0,1).其中zi的系数与小域的经纬度(ui,vi) 是相关的,满足α(ui,vi)=ui+vi.此外我们假定随机效应bi服从正态分布N(0,0.72),随机扰动项ei服从正态分布N(0,0.82),值得注意的是,随机扰动项的条件我们是已知的.模拟中采用Gauss 核函数作为权函数,窗宽h通过交叉验证法来确定.
设定模拟重复次数为T=500,样本容量m2分别为36,64和100.利用前面介绍的估计方法,基于以上数据分三种情况(协方差参数已知,ML方法估计协方差,REML 方法估计协方差)给出参数的估计.同时我们以符号“MEAN”“SD”分别表示固定系数进行500 次模拟实验的估计值均值、标准差.同时记yit和分别为样本中区域i第t次模拟的真实值和估计值.选取指标(平均绝对相对误差)和(平均相对根均方误差)来评估估计量的优劣.指标定义如下:

其中,

与此同时,我们给出三种情形下估计值在次模拟下的均方误差均值.模拟结果见表1至表3:

表1 参数β的估计结果

表2 小域估计量的指标对比

表3 小域估计量均方误差均值的比较
我们将协方差已知、协方差未知(ML算法估计)、协方差未知(REML算法估计)情况下β的估计值记为ˆβ.
表1为参数β在协方差参数σ2b已知、用ML方法估计协方差参数、用REML 方法三种情况下的估计结果.由此表可看出: 1)整体上,500次模拟中参数β的估计值趋近于真值3,且在真值3附近上下波动.估计值的标准差波动幅度较小,且均在区间[0,0.30]内浮动;2)当协方差参数σ2b已知时,估计值ˆβ0随着样本量的增大,越来越接近真值3,标准差也随着样本量的增大逐渐减小.当协方差参数σ2b未知时,通过采用ML 方法或者REML 方法估计协方差参数,我们同样发现随着样本量的增加,在相同方法中所得到的参数β估计值逐渐趋近于真值3,同时估计值的标准差逐渐减小.由此说明,样本量是影响参数估计的重要因素,样本量越大,参数的估计越接近真实值,同时也越稳定;3)当样本量相同时,协方差参数σ2b已知时得到的参数估计值最接近真值3,ML 方法估计协方差参数得到的参数估计值与REML方法估计协方差参数得到的参数估计值相比,更接近真值3.在标准差方面,REML 方法估计协方差参数所得到的标准差偏小一些,ML所对应的标准差偏大一些.这说明REML方法得到的估计值更加稳定.
表2为在协方差参数已知和协方差参数需要估计的三种情况下,所得小域估计量的平均绝对相对误差和平均相对根均方误差指标比较.两个指标反映了小域估计值的拟合程度.样本量相同时,协方差参数已知的ARE小于协方差参数未知时的ARE.同样协方差参数已知得到的小于协方差参数未知时的.相同条件下,ML与REML所得到的指标结果相差不大,REML方法得到的指标相对更偏小一些.此外,随着样本量的增加,逐渐递减,同时两种估计方法所得到的指标值越来越接近,说明两种估计方法对协方差参数σ2b估计效果相似.
表3是协方差参数已知、协方差参数需估计这三种情况下小域估计量n个区域T次模拟中均方误差均值的对比(确切的说,当协方差参数σ2b已知时,得到的是小域估计量均方误差.当协方差参数未知需用ML算法和REML算法估计时,得到的是小域计量均方误差的估计值.) 1)当协方差参数σ2b已知时,均方误差MSE(y)分为g1(y)和g2(y),g1(y)的取值反映了随机效应的估计影响,β的估计与g2(y)相关.当协方差参数σ2b需要估计时,g3(y) 反映的是协方差参数估计对总体均方误差估计的影响.2)g1(y)取值最大,对MSE(y)影响最大,说明随机效应估计对均方误差影响最大,这是由于随机效应设定时的标准差较大,存在一定的波动性,从而产生了较大的g1(y).g2(y)取值较小,说明β的估计对均方误差的影响较小,即β的估计是无偏的.g3(y) 有一定的取值,说明ML算法和REML 算法对协方差参数进行估计时有一定的偏差.3)协方差参数σ2b已知时,g1(y) 对均方误差的影响占比较大,协方差参数σ2b未知时,影响均方误差的主要是g1(y)和g3(y) 两个部分.4)协方差参数σ2b未知时,ML 算法的均方误差估计值与REML 的均方误差估计值差别不大,说明两种算法的估计没有明显差距.5)三种情形下,均方误差的估计值随着样本量的增大逐渐减小.同时三部分的取值也逐渐减少.
5.总结
为了更好的刻画区域之间的空间效应,本文提出了一类基于混合地理加权的Fay-Herriot模型用以小域估计.论文给出了目标参数的估计,并研究了其均方误差的估计问题.论文结果推广了小域估计的现有模型.
猜你喜欢
科技风(2021年19期)2021-09-07
温州大学学报(自然科学版)(2021年1期)2021-06-08
今日中国·法文版(2020年7期)2020-07-04
中学生数理化·高一版(2019年12期)2019-12-31
中国钢铁业(2018年6期)2018-07-26
现代营销·学苑版(2016年12期)2017-01-23
系统工程与电子技术(2016年4期)2016-08-24
探测与控制学报(2015年4期)2015-12-15
中国钢铁业(2014年4期)2014-08-22
中国钢铁业(2014年7期)2014-01-26
