基于朴素贝叶斯降噪的协同过滤算法
2019-03-29 08:01邓立国何明训
沈阳师范大学学报(自然科学版) 2019年1期
邓立国, 何明训
(沈阳师范大学 数学与系统科学学院, 沈阳 110034)
0 引 言
随着互联网技术与电子商务的高速发展,个性化、精准化的信息推荐形式慢慢取代了依靠“广撒网,多捞鱼”的传统高成本、低效率的推荐形式,成为了各大行业目光聚集的焦点。个性化推荐系统出现于上世纪九十年代,并在近年在电子商务网站如当当网、亚马逊、电影视频网站和信息交互网站,均得到了广泛的应用。依托于现今大数据时代规模庞大的数据信息,推荐算法能够通过其中蕴含的具体用户的行为特征或购买偏好,找到真正吸引用户眼球的信息或产品,同时可以侧面屏蔽掉许多用户不感兴趣却又深受其害的流氓广告,提高用户的整体浏览体验。协同过滤推荐算法(CF)是最早出现同时也应用最广的一种推荐算法[1]。它通过计算收集的数据之间的相似性来找到最相似的集合,推荐给用户。但收集到的用户数据,作为用户在使用网络过程中产生的痕迹,错综复杂,良莠不齐,其中存在着大量的垃圾数据和用户的误操作。据2017年统计显示,在点评分享类网站“大众点评”和电商网站“淘宝网”上,用户根据所购买商品情况或服务体验对店家和商品进行评论与打分[2],可识别出的无效和垃圾评论比率均高达40%。大量的无意义单纯凑字数的垃圾信息或者“水军”留下的或褒或贬的干扰信息充斥于这些评论之中,将这些数据直接拿来进行推荐会产生巨大的误差和不必要的额外损耗,极大的影响推荐结果的精准性和时效性。因此,如何准确地筛选出无效信息,更好地对初始数据集进行降噪处理,减少垃圾信息对推荐结果的干扰这一课题一直是推荐算法研究者心中的重中之重。
经过多年的发展,对于如何给用户文本型数据进行降噪处理,研究者们已经有了一些相对成熟的方法:基于规则的方式常见于很多社交网站,这种方法强制用户在发表评论之前输入验证码,通过验证才可以正常发表评论,但这种做法极大地影响了用户的操作体验,也不能区分那些水军和用户的无关随意评论;基于黑白名单方式检验用户Ip是否存在于黑名单,大多使用ISCBL对IP进行实时监控[3],若用户在某时间段内重复提交有相同数字或者相同域名的外网地址,则将此用户IP列入黑名单之中。此种方法准确率较高,但网站的监控规则被获知后,非法者可针对此规则改变文本的广告形式或使用软件形式[4]。其他一些方法如Jindal和Liu[5-6]将此类垃圾信息分成非评论信息、不相关评论和欺骗性评论,通过对选取评论文本、评论者和商品3个方面36个特征建立逻辑回归模型ACU来应对这种问题;Peng等[7]以评论内容和文本情感分析的方法将其分为3类,确立了3条垃圾评论规则;Savage等[8]通过计算垃圾评论的评分与正常评分平均分的差异,筛选出不符常态的评分项加以排除;Lai[9]通过模型计算2个不同评论之间的相似性,找出是否有一条评论出自于另一条评论,最后使用向量积来进行区分。这些方法都有着各自的优势,但均有着自身成本太高、局限性太强等缺陷。
本文拟采用朴素贝叶斯分类来对推荐系统数据集进行前期降噪处理,再运用协同过滤的方法进行推荐。朴素贝叶斯分类算法是贝叶斯分类中最具代表性的一种分类方法,它稳定高效,适合处理多分类数据,对缺失数据也不敏感,通过这种方法对获取到的用户行为数据集进行筛选,降噪处理之后再进行推荐会得到更精准的推荐结果,用户满意度也会更高。
1 朴素贝叶斯分类
1.1 朴素贝叶斯算法
贝叶斯定理是英国数学家贝叶斯提出的一种计算概率的方法,其原理是通过对过去事物发生的概率(先验概率)计算出事物当前出现的概率(后验概率),然后选择当前出现概率最大的类作为该事物的所属的类。贝叶斯定理如下:
(1)
其中:P(A)是A的先验概率,即不考虑B情况发生与否时A发生的概率;P(A|B)是已知B发生后A的概率,即A的后验概率;P(B|A)是B的后验概率,P(B)是B的先验概率。
贝叶斯定理在机器学习领域衍生出了很多种分类方法,其中最为基本的、应用最为广泛的分类方法是朴素贝叶斯算法[10]。朴素贝叶斯算法是在贝叶斯算法的基础之上进行条件独立假设,先找到一个已分类的样本组成训练样本集,设待分类项x(a1,a2,…,am),其中每个a为x的一个特征属性,并假设特征之间相互独立;类别集合C(y1,y2,…,yn),需计算特征属性属于各个类别的概率P(yi|aj),因为每个特征之间是相互独立的,所以根据贝叶斯定理:
(2)
因为各特征之间是相互独立的,所以可得该样本属于yi类的概率为样本中各属性出现时属于yi类的值之积。公式为
(3)
所得所有概率中最大值对应的类别就是该待分类项所属的类别。公式如下:
P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)},则x∈yk
(4)
1.2 构建贝叶斯分类器的训练模型
1.2.1 分解语句并提取关键词
本节对淘宝中的评论进行朴素贝叶斯分类,试找出其中的垃圾评论。因为是区分评论是否属于垃圾评论,所以可以把它视为简单的二分类问题,即C(y1,y2)。C=y1,评论为垃圾评论,C=y2则为非垃圾评论。使用爬虫软件从淘宝中爬取商品评论,整理之后选取一下6条主题为“外套”的评论作为训练样本进行分析与建模。
1) 质量不错,款式很好看,尺码标准,穿着很舒服,很满意!
2) 衣服太薄了,质量也不好,不值这个价格。
3) 衣服性价比太低,邻居买的别家的价格好便宜才80还送长袖,他家的贵好多,衣服很薄而且不送的长袖质量不好,下回我也去狼途买了。
4) 质量感觉一般吧。衣服薄,天稍微凉一点这衣服就不适合了。
5) 给老公买的,款式很好看,显年轻,而且款式质量也很不错,非常满意!
6) 月末了,该确认收货的商品记得确认收货。记得写评价的时候多凑点字数,最好附上晒图,加积分。 淘宝有个88会员,积分1 000以上的淘宝用户可以每年88元的价格购买,淘宝买东西打88折!很快就能回本!
其中1)、2)、4)、5)条评论为非垃圾评论,3)、6)两条评论为垃圾评论。依次提取几条文本中的关键词:Item1[“质量”“款式”“尺码”];Item2[“量”“薄”“值”]等特征数据,取它们并集得到的特征数据为[“质量”“款式”“尺码”“薄”“别家”“值”“评价”“晒图”“会员”“字数”“积分”“回本”]。
1.2.2 构建矩阵
利用得到的特征数据构建矩阵,矩阵的列为样本编号,矩阵的行为关键词特征属样本包含此特征属性,则在对应处标1;样本不包含此属性,则标0。最后一列为本评论文本是否属于垃圾评论,是为y1,否为y2。
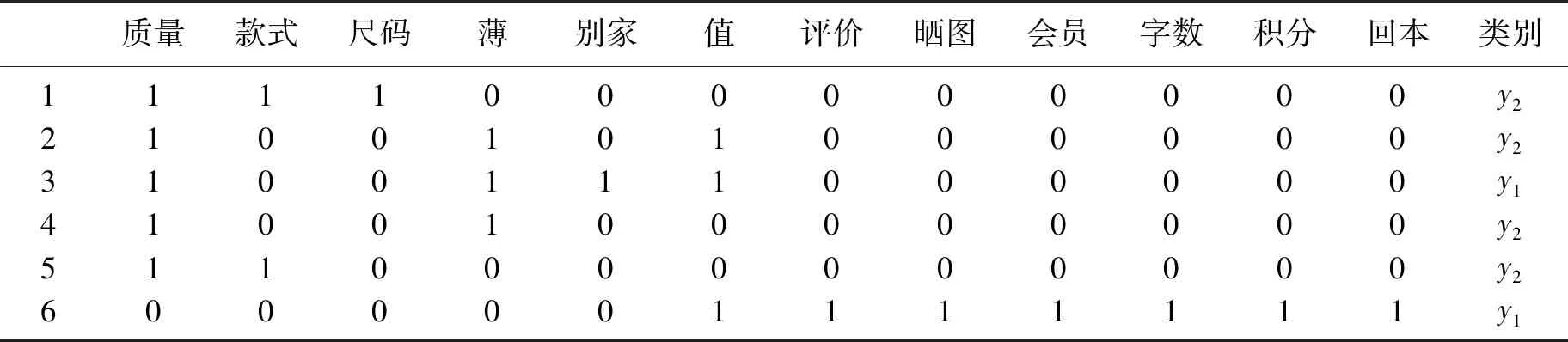
表1 样本特征矩阵Tab.1 Characteristic matrix
其中评论样本1所对应的特征属性向量为[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]。
1.2.3 朴素贝叶斯分类
首先计算出每一个特征属性出现时分别为垃圾评论和非垃圾评论的具体概率。根据贝叶斯定理可求:P(y1丨质量)=2/5,P(y2丨质量)=3/5;P(y1丨款式)=0,P(y2丨款式)=1;P(y1丨尺码)=0,P(y2丨尺码)=1;P(y1丨薄)=1/3,P(y2丨薄)=2/3;P(y1丨别家)=1,P(y2丨别家)=0;P(y1丨值)=2/3,P(y2丨值)=1/3;P(y1丨评价)=1,P(y2丨评价)=0;P(y1丨晒图)=1,P(y2丨晒图)=0;P(y1丨会员)=1,P(y2丨会员)=0;P(y1丨字数)=1,P(y2丨字数)=0;P(y1丨积分)=1,P(y2丨积分)=0;P(y1丨回本)=1,P(y2丨回本)=0。
当一个新的样本例如“质量一般吧。衣服薄,天稍微凉一点这衣服就不值了。”出现时,先初始化一个和词库等长的特征数据[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],之后按上面步骤对特征属性进行遍历得到新的特征数据为[1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0],假设关键词特征值之间是相互独立的,用朴素贝叶斯公式计算出新样属于垃圾评论的概率P(y1丨x)和属于非垃圾评论的概率P(y2丨x)。
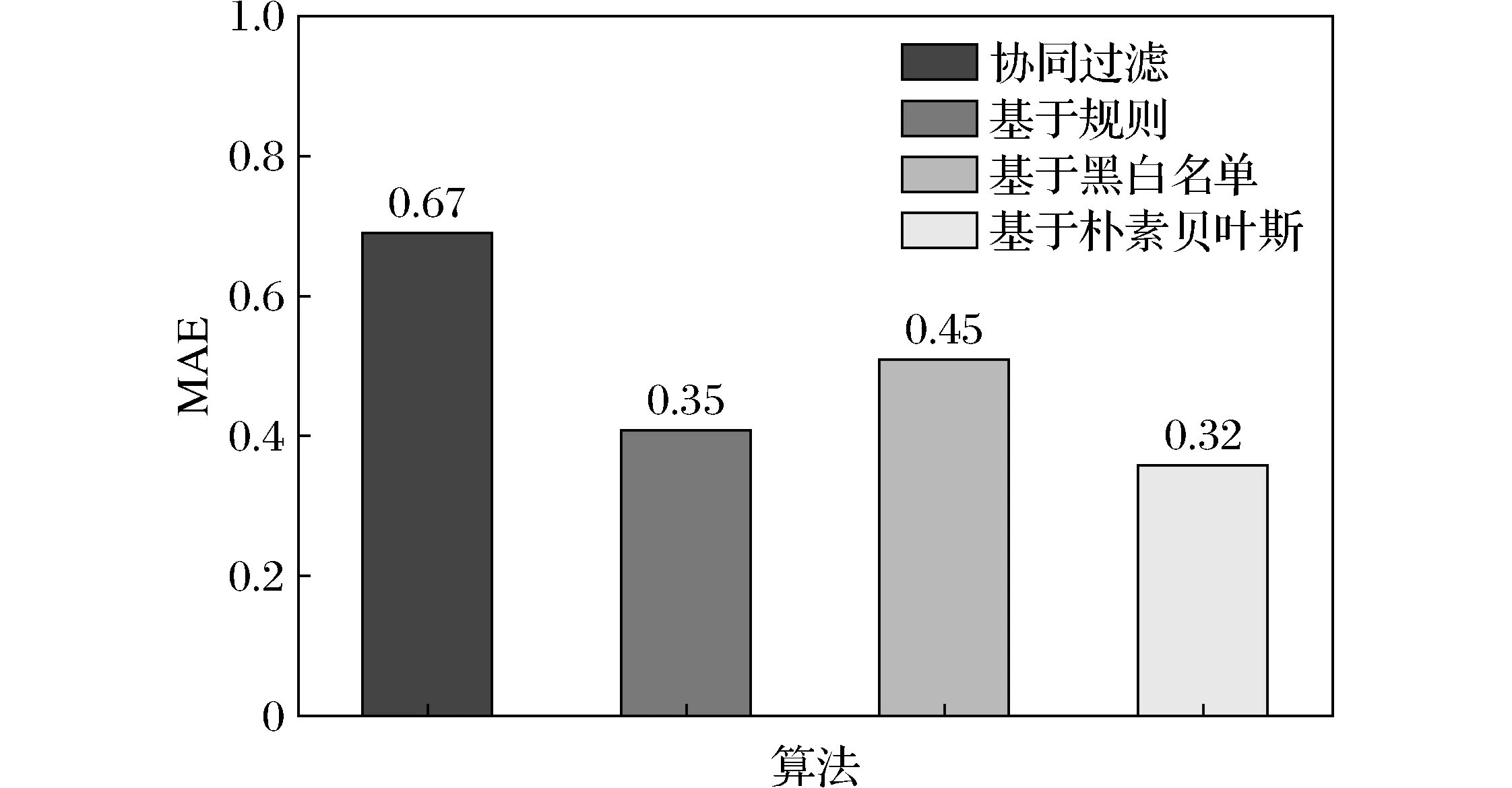
P(y1丨x)=0.088 888 889 协同过滤是一种基于一组最相似用户或项目的集合进行推荐的方法,在现今各大推荐算法之中,它的推荐效率非常高,并且应用范围最为广泛。协同过滤的中心思想是“物以类聚,人以群分。”协同过滤推荐算法一般分为2种,一种是基于User(用户)的协同过滤推荐算法,另一种是基于Item(项目)的协同过滤推荐算法[11]。基于用户的协同过滤推荐算法通过探究用户的行为特征和偏好来发掘出用户和用户之间的联系,找到用户的最近邻集合,将相似用户喜欢的物品互相推荐给别的用户;而基于项目的协同过滤则通过用户的行为特征和偏好信息,计算出物品与物品之间的相似度,然后找到物品的最近邻集合,最后根据用户的历史偏好信息,将此集合中的其他物品推荐给用户[12]。本文采用基于Item(项目)的协同过滤推荐算法。基于项目的协同过滤算法假设用户A喜欢电影1和电影3,用户B喜欢电影1、电影2和电影3,用户C喜欢电影1,从这些用户的历史喜好可以分析出电影1和电影3是比较类似的,喜欢看电影的人都喜欢看电影3,基于这个数据可以推断用户C很有可能也喜欢电影3,所以系统会将电影3推荐给用户C[13]。 协同推荐系统首先要获取用户以前的消费、评价、浏览信息以及项目属性信息,并对这些数据进行数据预处理得到一个User-Item-Rating(用户-项目-评分)用户项目评分。如图:其中,m表示用户数,n表示项目数,rui,j则表示用户ui对项目j的评分值,通常情况下这个评分值的范围为1~5,其中1代表不喜欢,数值变大好感度依次递增,数值5代表非常喜欢,如果没有对该项目进行评分的话,评分值取0。评分矩阵中的行表示用户的评分向量,列表示物品的评分向量。 表2 用户评分矩阵Tab.2 User-rating-data matrix 2.3.1 余弦相似性 余弦相似性把用户评分矩阵看作n维项目空间中的向量,如果用户对项目没有评分,则将该评分值设为0。余弦相似性方法通常被应用于文本对象,使用向量所指的夹角值来表示相似性,计算用户之间的相似性时,把评分矩阵中的数据看成向量,二向量之间的夹角余弦值则为2个用户之间的相似值,并且与用户的相似值成正比, 计算两向量x,y之间的夹角余弦值为 (5) 则余弦相似性计算的公式如下: (6) 其中:cos(a,b)表示用户a与b的余弦相似度;Ra,j和Rb,j分别代表用户a和b对j项的评分;Iab表示用户a和b共同评价过的所有项目。 余弦相似性的特点是将0赋值给用户未评分的所有项,这么做有优有劣:优点是一般情况下有效地提高了计算效率,缺点是未充分考虑到数据稀疏性的问题,即用户对未评分项目的评分不可能都为0。而且,有的用户普遍给的高一些,有的用户普遍给的低一些,没有一个统一的尺度来对用户评分进行把控。在这些情况下,单纯的使用余弦相似性就不太适宜了,应该采用修正的余弦相似性来计算[14]。 2.3.2 修正余弦相似性 余弦相似性认为所有用户的评分习惯都一样,但考虑到上文说到的评价尺度不同的原因,应该对其进行区别处理。修正余弦相似性度量方法通过减去用户对项目的平均评分,改善了余弦相似性度量方法的这个缺陷。公式如下: (7) (8) 本文采用的数据集为2018年2月从豆瓣电影网站上爬取下来的豆瓣电影短评数据集,豆瓣电影具有国内最权威的电影评分和精彩影评,包含着中国千万影迷的真实观影感受和体验。目前豆瓣电影用户规模已超过亿人,用户评分的电影已超过8 000部。该豆瓣电影短评数据集包括电影ID(MOVIEID)、用户信息(ID/IP)、评论时间(TIME)、用户评分(RATING)和用户短评(CONTENT)5个部分,数据存储使用的是SQLite数据库,其中用户评分为1~5分,总计差评1~2分评论177 714条,中评3分评论107 687条,好评4~5评论224 229条。 选择其中的3 000条评论信息测试集进行实验,首先采用朴素贝叶斯算法和基于规则的方法对该集合进行降噪处理, 然后将得到的有效数据集重新划分为训练集和测试集2个部分。其中80%为训练集,剩下的20%为测试集。 评价推荐系统推荐质量的度量标准一般有2种:统计精度度量方法和决策支持精度度量方法,其中应用最为广泛的是出自于统计精度度量方法中的平均绝对误差MAE(mean absolute error),公式如下: (9) MAE通过计算预测的用户评分与实际的用户评分之间的偏差来度量预测的准确性,MAE越小,推荐质量越高。预测的评分集合表示为{p1,p2,…,pn}实际的评分集合表示为{q1,q2,…,qn}。 图1 MAE表Fig.1 MAE Table 为了检验本文提出方法的有效性,以通过朴素贝叶斯算法进行降噪处理再通过基于项目的协同过滤算法与基于规则的协同过滤推荐算法和常见的通过黑白名单方法降噪处理再进行推荐的方法作以比较,计算其MAE,实验结果如图1所示。 由图1可知,基于朴素贝叶斯降噪再进行推荐的方法得到的MAE最小,因此,与单纯通过协同过滤推荐算法的结果和经过基于黑白名单和其他规则的方式降噪再进行推荐相比,本文所采用的方法可以显著地提高推荐的精度和质量。基于这种更优的结果进行广告投放,会起到更加良好的效果。 通过在进行基于项目的协同过滤推荐算法前,用朴素贝叶斯算法对数据集进行降噪预处理,可以有效减少垃圾评论和无效评分对其的干扰,更优化协同过滤的推荐质量,再进行广告投放可以显著地提高投放的精度,达到更优的效果。2 协同过滤推荐算法
2.1 算法概述
2.2 用户评分矩阵

2.3 计算项目相似性
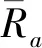
2.4 最终推荐

3 实验结果及其分析
4 结 论
猜你喜欢
数学物理学报(2022年5期)2022-10-09
法律方法(2021年4期)2021-03-16
河北画报(2020年8期)2020-10-27
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
浙江大学学报(工学版)(2016年2期)2016-06-05
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05