基于卷积神经网络的场景级云分类算法
2019-03-29 08:01于志成杨秉新
沈阳师范大学学报(自然科学版) 2019年1期
于志成, 张 晔, 杨秉新, 李 涛
(北京空间机电研究所, 北京 100094)
0 引 言
遥感技术因其能够快速、及时、便捷的提供多种对地观测、跟踪、定位和导航等各种服务,在国防现代化和经济建设等各个方面发挥了越来越重要的作用,带来巨大的军事效益、社会效益和经济效益[1]。不同行业使用遥感图像的目的不尽相同,以风云系列为代表的气象卫星主要用于拍摄云图,以分析天气和气候变化;陆地勘测卫星主要用于拍摄地表,为国土、林业、环保等行业应用提供数据支撑,但对于非气象类遥感卫星,如果拍摄区域上空存在较多的厚云,遥感相机所拍摄遥感图像中的有效地表信息量就会减少,大量下传此类图像将严重浪费卫星对地数传资源,因此如何消除云对光学遥感图像卫星数据的影响,分析判断遥感图像的可利用程度就成为了一个非常重要的研究方向[2]。
遥感图像可利用程度划分实质上属于效率管理,在航天光学遥感器设计中,避免云覆盖影响陆地勘测卫星使用效能的最好的办法就是在轨对云覆盖情况进行定量化、分等级的评估分类,进而判断所拍摄图像的可利用程度。具体来说,就是在轨对未知遥感图像信息进行有效的特征提取,通过定性和定量的分析,在轨预估遥感图像被云覆盖的严重程度,定量化的划分等级,在遥感图像通过数传发送给地面接收系统前,根据不同等级采取有效的措施,避免可利用程度较低的遥感数据占用数传资源[3]。对于分类的标准,主要是遥感图像中云覆盖的区域能否正常提供地表的真实有效的信息,或者能提供多少有效信息,以及信息的可用性和有效性。因此,针对遥感有云图像的准确、有效的分类准则,以及高效、精确的分类算法是在轨云判需要解决的2个关键问题[4]。
目前已有很多学者针对遥感图像的云覆盖问题做了很多研究,多数的研究集中在确定整幅遥感图像中云遮挡的各种情况所占比重,结合遥感图像的实际应用场景,对遥感图像的可利用程度进行等级的划分,并给星载计算机以确定的阈值,进而判断是否需要在轨实施有效措施。郁凡和陈渭民根据不同类型的云在红外和可见光波段的不同光谱特性,能够检测7种主要云类及晴空区[5];马芳等探讨了常用通道阈值云检测方法,并尝试建立了红外分裂通道差值法和通道综合运算法的云检测方法[6];何全军等将不同云的大气辐射特性与MODIS数据的光谱特性相结合,综合考虑可见光的反射率、红外波段的亮温值及亮温差等方面,提出了一种多光谱综合的云检测方法[7]。但上述算法的研究更关注“云”占整幅图像的比例问题,即更关注像素级分类的精度,而这类算法带来的弊端是,一旦该比例低于图像可利用的阈值,则整幅图像都不能得以数据下传,这样会浪费掉很多其实整幅图像云量占比很大、但局部地区信息却清晰可见的图像[8]。因此,本文首先将一景整幅图像拆分成若干局部场景,并针对局部场景提出一种新的云覆盖度等级场景分类准则,利用该准则进一步提出基于深度卷积网络的云图像场景分类算法,最终实现整幅卫星遥感图像可利用程度的分块精细分类。与传统判断整幅图像是否下传的方法相比,本文提出的算法可以为卫星数据下传提供更精细的指示信息,从而实现图像信息利用最大化。
1 云覆盖度等级的场景分类准则
本文针对遥感图像可利用程度分类问题,重点关注遥感图像的云覆盖程度这个重要因素,以云的厚度能否影响遥感相机获取地面信息,以及是否能通过算法对云进行去除并恢复出部分地面图像作为判断依据,提出将遥感图像局部场景分为4个类别,3个等级,最终根据裁定的等级要求,来判断是否能够作为有效遥感图像数据下传使用。具体准则中,将云图像按照覆盖程度一共分为4类:即厚云完全覆盖,厚云部分覆盖,薄云覆盖,无云覆盖,根据图像是否有下传的必要又分为3个等级:可直接下传、可条件下传、不可下传[9],具体如表1所示。

表1 遥感图像云覆盖度分类等级
其中,零覆盖度为完全无云覆盖的遥感图像,是陆地勘测行业遥感应用领域重点使用的数据,需要尽量多、尽量快的下传到地面,或者进一步在轨检测图像中的目标;低覆盖度,即有较少厚云覆盖,或者被薄云覆盖,可透过薄云云层看到部分云层下的地物信息,这类图像中含有一定的有价值信息,可以下传到地面后经过云去除等图像增强算法处理后进一步使用;中覆盖度,即较多区域被厚云覆盖,这类情况则需要根据实际情况判断,满足阈值的认为有利用价值的再进行下传;而高覆盖度的遥感图像,即几乎全部被厚云覆盖,则已基本无法获取任何有效的地面信息,可以考虑在轨丢弃,不再下传。各覆盖度等级对应的图片示例如图1所示。

(a)—高覆盖度; (b)—中覆盖度; (c)—低覆盖度; (d)无云覆盖图1 各覆盖度等级对应的图片示例Fig.1 Image examples corresponding to each coverage level
2 基于深度卷积神经网络的云图像场景分类

图2 面向场景级云覆盖图像块分类流程图Fig.2 Scene oriented cloud cover image block classification flow chart
深度卷积神经网络(Deep Convolutional Neural Networks)的特征提取能力已经席卷了整个图像分类领域,由于CNN分类网络避免了对图像复杂的人工设计特征工作,可以直接输入原始图像,依靠其超强的特征提取能力,通过迭代过程中不断优化网络所需参数,直接在输出端的分类器获得准确的分类结果,而体现了极高的实用价值[10]。因此,笔者将CNN图像分类引入云覆盖遥感图像的场景分类研究中,配合所提出定义的4类有利于机器学习的场景类型,可以准确对笔者所需的面向不同云覆盖等级的图像块进行准确的场景分类[11],原理如图2所示。
2.1 卷积神经网络结构
卷积神经网络一般由卷积层(convolutional)、池化层(max pool)、全连接层(fully connected)和1个输出层或分类器(softmax)组成。每层由多个二维平面块组成,每个平面块由多个独立神经元组成。网络通过逐层的特征提取学习输入图像的高层特征,然后将其输入到分类器中对结果进行分类。CNN是将卷积运算引入到深度学习模型,属于多层前馈神经网络模型,但与传统不同的是它的输入是二维模式,可以直接处理二维模式,其连接权是二维权矩阵,称为卷积核,基本操作是二维离散卷积和池化。简单地说,CNN就是能够自动的对于1张图片学习出最好的卷积核以及这些卷积核的组合方式。卷积神经网络的发展主要得益于海量数据以及多种隐藏层神经元的提出,主要的隐藏层神经元操作描述如下[12]:
1) 卷积操作conv(convolutional):卷积操作使用滑动窗口分割原始图像,在每个滑窗内使用相同的参数进行线性计算得到输出图像。在1张图像上使用一个卷积核的进行卷积运算的计算如式(1):
(1)

2) 批规范化操作bnorm(batch normalization):批规范化操作通过对神经网络隐藏层的输出进行归一化处理防止反向传播过程中的梯度弥散,加速神经网络在训练时的收敛速度[13]。其计算如式(2):
(2)
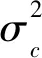
3) 修正线性操作ReLU(rectified linear unit):修正线性操作是网络中使用到的激活函数,其计算如公式(3)所示:
yh,w,c=max{0,xh,w,c}
(3)
其中,x∈RW×H×C为输入图像;y∈RW×H×C为输出图像。
4) 最大池化mp(max pool):最大池化操作采用滑动窗口分割图像,在每个滑窗内取最大值作为输出,其计算如公式(4)所示:
(4)
其中,x∈RW×H×C为输入图像;y∈RW×H×C为输出图像;f∈RW×H×C为滑窗大小,窗口每次滑动1个窗口大小的步长。
5) 全连接操作FC(fully connected):全连接操作对输入图像的所有数据进行加权求和的线性运算,可以通过卷积操作的方式来实现。公式(1)中窗口大小f∈RW×H×C修改为f∈RW×H×C即可将卷积操作变为全连接操作。
卷积层后一般接入池化层来减小数据量,通过池化把输入的特征图像分割为不重叠的矩形区域,而对相应的矩形区域做运算,常见的有最大池化和均值池化。经过交替的卷积层和池化层之后,已经获得了高度抽象的特征图像,全连接层把得到的多个特征映射转化为一个特征向量以完全连接的方式输出,最后对提取的特征进行分类。
卷积神经网络工作原理,即在卷积神经网络中,通过神经网络的梯度反向传播算法实现对参数的学习训练,属于有监督学习[14]。在进行学习训练过程中,输入信号的训练输出和实际输出会有一定误差,误差在梯度下降算法中逐层传播,逐层更新网络参数。假设样例(x,y)的损失函数为C(W,b;x,y),如式(5)。
(5)
为防止过拟合,需增加L2范数,如式(6)。
(6)
其中,hW,b(x)为输入样本x经过CNN后的输出,y为样本的标签真值,λ为控制强度。为了使代价函数尽可能的小,因此需要不断更新每一层的权重W和偏置项b,任意一层(假设为γ层)的权重更新如式(7)。
(7)
2.2 迁移学习
迁移学习并不是一种特定的机器学习模型,而是一种优化技巧。理论上,机器学习任务要求测试集和训练集有相同的概率分布,然而在某些应用中,通常会出现缺乏足够大的有针对性的数据集来满足特定训练任务的情况。迁移学习提出可以在一个通用的大数据集上进行一定量的训练后,再用针对性的小数据集进一步强化训练。迁移学习的思想允许人们利用现有的模型加上少量数据和训练时间,取得较好的结果。如VGG网络将224×224×3维数据转化为4 096维,提高每一个维度的信息量,降低了计算资源的消耗[4]。
由于云覆盖图像数据集中样本数量有限,目前已有的云图像数据集与ImageNet库相比都相差甚远,且受到硬件条件的限制,很难完全重新训练一个完整的神经网络,并且将其的权重训练到最优。同时,从卷积网络的本质上来看,不同的卷积网络就是一个图像特征提取器,其中浅层卷积网络主要实现的是低级视觉特征的提取,深层卷积网络才实现高级的语义特征提取,无论任何场景分类主要区别都在于深层的高级语义特征,而浅层提取的点、线、面等低级特征都为共性特征,因此可以认为前面卷积网络层和池化层几乎都是训练好的,保持初始权重不变,针对不同的分类任务,替换最后一层全连接层的维数为目标分类的类别数。综上,本文采用基于ImageNet数据集(1 000类、一千万张图像)训练好的预训练网络进行迁移学习,将全连接层的维度改成4(与云覆盖图像的种类数相同),重新训练其权重,使得重新训练好的网络模型更适用于云覆盖数据集,从而实现精度比较高的图像分类效果。
3 实验与分析
3.1 数据描述
数据库是学习和评估传统神经网络的基础。数据库包括训练样本,测试样本和相应标签,训练样本通过训练卷积核参数来学习神经网络的特征,通常情况下,训练样本越多、越丰富,其训练出的卷积神经网络就能够提取更合适的抽象特征,识别精度也更高。测试样本旨在检测训练后的卷积神经网络的识别能力。测试样本通常是训练样本以外的样本,以测试卷积神经网络的泛化能力。数据库开发实际上是训练样本和测试样本的构建,样本标签通常是手动标记完成的,所有图片都需要逐一标记。本文中的训练样本和测试样本实际上是遥感图像。在本文中使用的云场景样本遥感图像为卫星拍摄,每幅图像的尺寸为12 280×10 000。
如表2所示,本文所使用遥感数据的拍摄地点位于宁夏自治区,地物范围包括城市、农田、植被、江河等典型地物类型,拍摄时间分别为2014年3月、5月、9月、11月,上述4组数据的图像大小为12 280×10 000,分辨率为2米,四组数据都有被云覆盖的情况,但云覆盖量不同,本实验选取4组时间不同、光照情况不同的数据制作样本数据库。下述所有实验中,将裁取300×300图像作为一个基本图像块单元,进行场景识别。

表2 遥感数据库信息Tab.2 Remote sensing database information
由于搜集的样本具有随机性,且重复人工标定工作量过大,为了尽量避免过度拟合的情况,本文对样本做如下划分:将80%的图像分到主训练集,保留10%的样本用于训练模型验证,剩下的10%样本作为测试集,用来准确预测分类器的实际分类性能。
仿真环境方面,硬件平台使用惠普工作站搭配GTX1080显卡对深度学习算法进行加速;软件方面使用Matlab开发环境配合MatconvNet工具包实现网络模型的搭建、训练和验证。
3.2 基于辐射预处理改善的云图像场景分类

表3 原始云覆盖图像分类精度Tab.3 Classification accuracy of original cloud cover images
在上文制作的云覆盖图像数据集中,按照本文提出的云覆盖场景分类准则,以图1中定义的4种不同类别的图像为标准,从数据集中选取相应类别图像作为训练样本。为了保证模型训练精度,最终选取的训练样本数量达到1 982个,测试样本数量为200个。经过模型训练和验证后,云覆盖图像局部图像块的场景分类实验结果如图3和表3所示。

图3 预处理之前的分类精度Fig.3 Classification accuracy before preprocessing
通过对比分析表3和图3中的数据可以看出,不同类别样本的分类结果的差异性比较明显:无云覆盖图像的分类精度比较高,得到的分类结果比较好;低覆盖度图像的分类错误率比较高。同时,由于不同图像的对比度和亮度可能存在一定的差别,导致在相同的分类标准下,也会出现分类错误的情况。因此,在对原始图像的预处理中,应先将图像的亮度和对比度进行统一化处理,然后再训练网络模型。
从训练集中选出用于预测的4类图像,利用遥感图像中像元的灰度值分别统计其亮度范围,统计完成后,再采用图像灰度变换函数对图像的亮度进行折中处理,直接改变图像的对比度,以选取均值范围附近的亮度值。
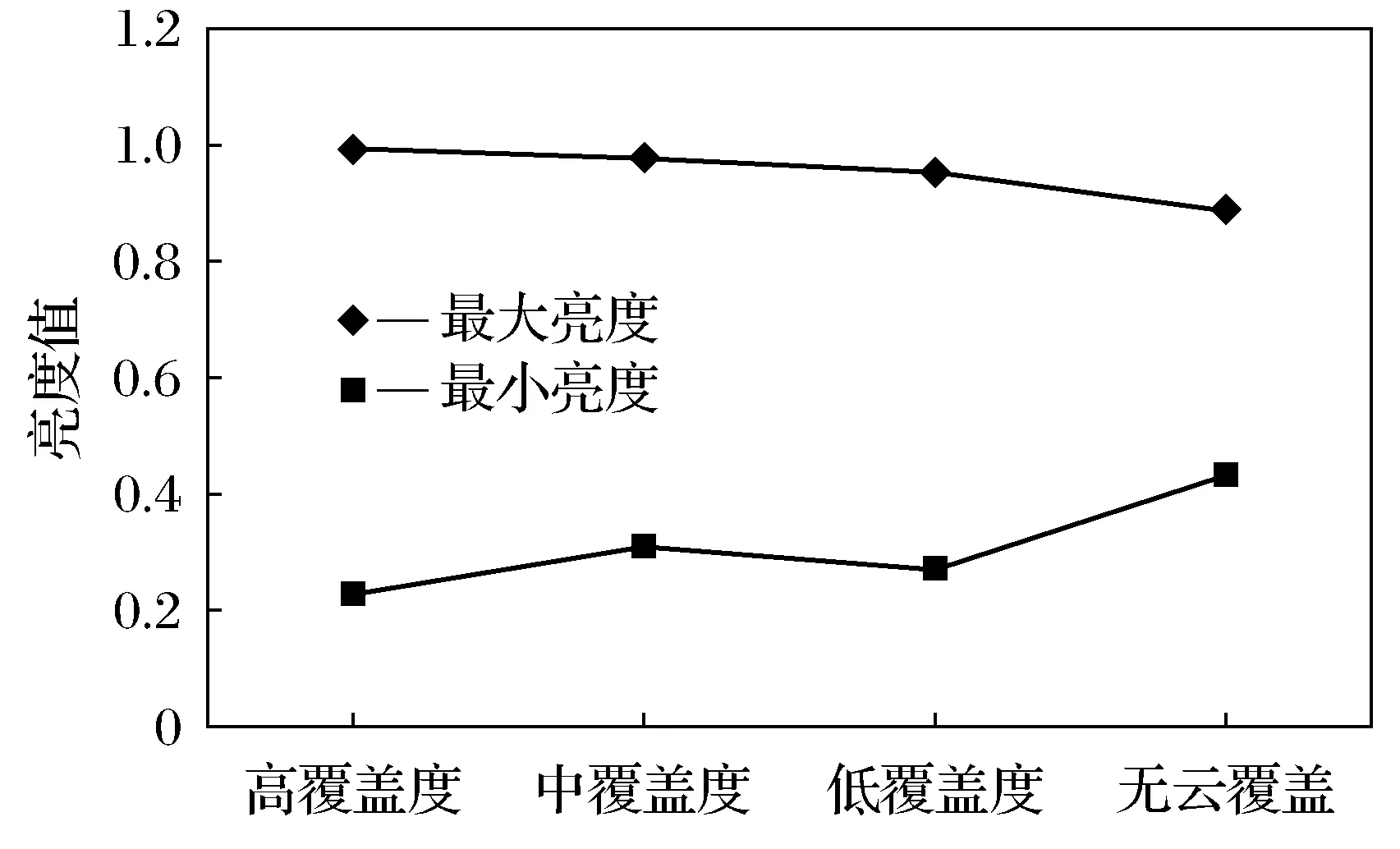
图4 预处理之前的亮度Fig.4 Brightness before preprocessing
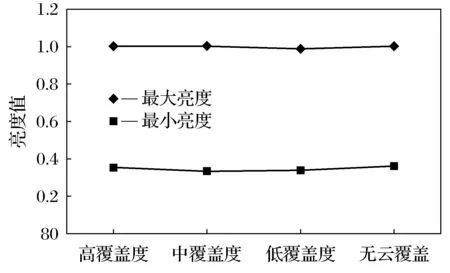
图5 预处理之后的图像亮度Fig.5 Brightness after preprocessing

类别高覆盖度中覆盖度低覆盖度无云覆盖精度/%92.1492.3392.2992.49
通过对比分析图4和图5可以看出,经过处理后,图像的其亮度范围一致性更好,也不再会出现过亮或过暗的现象,而且对比度也得到了统一,改善了样本自身的误差,也直接影响到后续图像分类的结果。分类结果见表4。

图6 预处理后的精度对比折线图Fig.6 Comparison of broken lines after pretreatment
通过分析上述数据可以发现,与原始图像的分类结果相比,图像预处理在一定程度上提高了训练集图像的分类精度,而且整体的变化幅度明显变小。在将遥感图像按云覆盖程度分为4类的情况下,因为是获取地面有效信息的1个主要参考,所以比较关注厚云与薄云的分类。在这里,需要注意的是:如果分类器没有将厚云分到薄云中,也就是说整个过程是正确的。分类器的作用是提高识别云层厚度,由此进一步提高整体精度,依此下一步展开针对样本优化的实验分析。

表5 数据集优化后的云覆盖图像场景分类精度Tab.5 Cclassification accuracy after data set optimization
3.3 训练样本数据优化对于云图像场景分类的影响分析
在前面开展的实验的基础上,对数据集中的样本进行优化,主要通过肉眼找出容易分类错误的图片,将其剔除,同时增加数据集的样本数量(由原有的1 980张增加至3 172张),并对其进行更细致的分类。之后,重复上述训练和测试等实验步骤,得到的分类精度如表5~表7所示。

表6 优化数据集增加样本数量下的精度

表7 原数据集增加样本数量下的精度
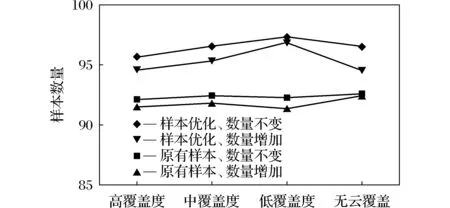
图7 样本数目改变以及样本重新选取精度曲线图Fig.7 Accuracy after datasets expanded and data set optimization
上述实验通过增加训练样本数量和优化数据集中的样本2个方面的工作,来验证其对分类精度的影响。从实验数据可以看出,单纯增加样本数量并不能直接影响到分类精度。经认真分析后,主要原因是本实验中只有4类样本,类别较少,因此受到样本数量的影响也较小,无法体现样本数量与分类精度之间的关系。同时,在实验过程中,考虑到星上有限的硬件资源和处理能力,最终确定了比较合适的样本量,并通过实验进一步证明在实际选取样本的过程中,需要针对特定卫星的数据进行多次的优化组合筛选,以提高分类精度。
3.4 不同卷积网络对于云图像场景分类的影响
表8 Inception V2网络下的分类精度Tab.8 Accuracy of Inception V2
表9 InceptionV3网络下的精度Tab.9 Accuracy of Inception V3
本文考虑了云覆盖图像块的场景分类要考虑在轨实现的可能性,既要保证精度满足要求,又要兼顾星上有限的硬件资源,网络深度不能太大,因此在场景分类常用的Lenet-5、Alexnet、GoogleNet、VGG等网络中,本文选取了2014年Google提出的GoogleNet网络(也叫Inception)。该网络主要通过“降维”(卷积分解的一种)来提升性能,同时尽量减少计算参数的数量和内存的占用。考虑到网络邻近的激活单元高度相关,因此聚合之前进行降维可以得到类似于局部特征的东西。Inception网络是全卷积,卷积计算变少也就意味着计算量变小,这些多出来的计算资源可以来增加filter-bank的尺寸大小。本文针对Inception两种不同的卷积神经网络进行分类精度分析实验,采用的均是经过辐射预处理,但并未做数据删减优化的数据集,进行的对比实验结果如表8、表9所示。
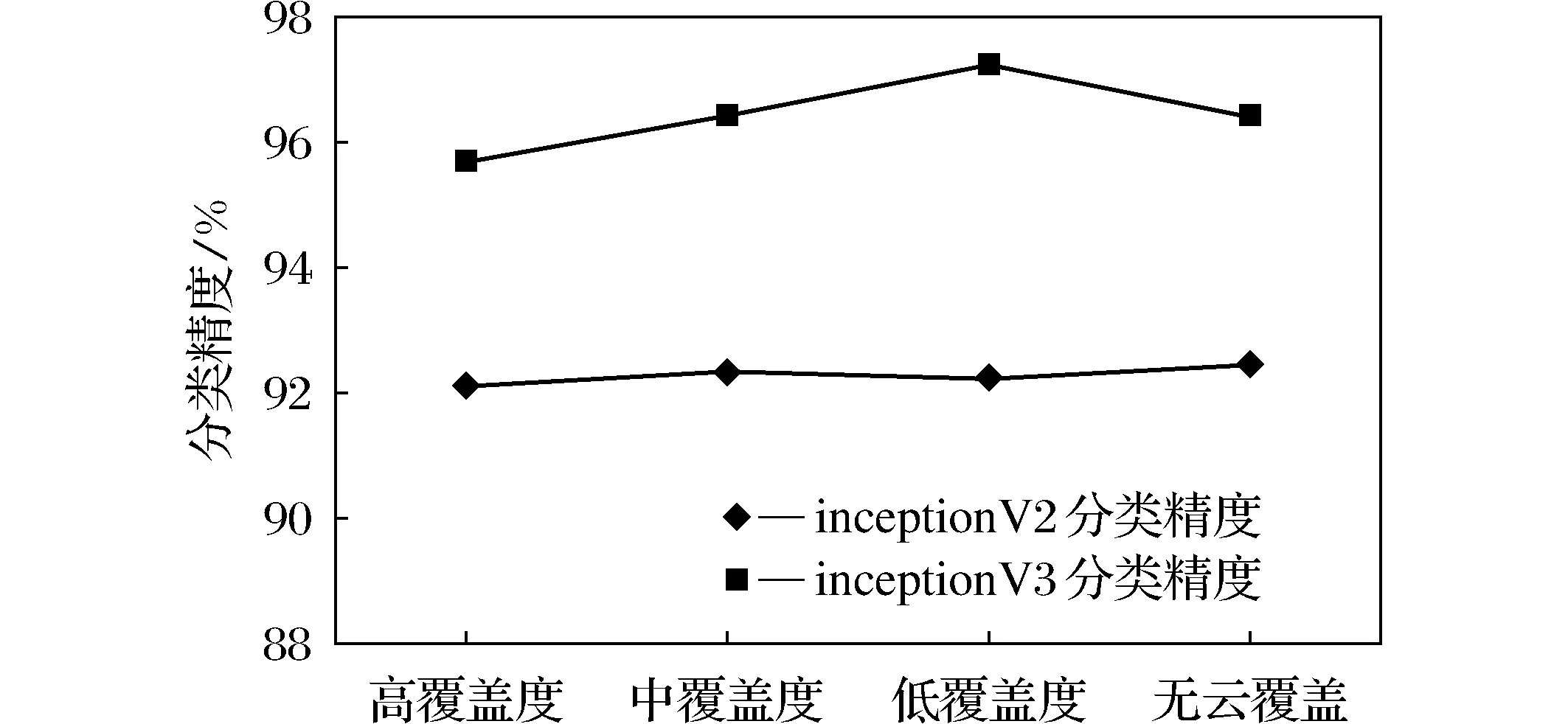
图8 2种不同网络下识别分类精度对比曲线Fig.8 Accuracy of two different networks
综合分析数据表8、表9的数据和图8的曲线,可以看出inception V3网络的分类精度要优于inceptionV2网络的分类精度,因此可以说明,对于本次遥感云场景分类,inceptionV3网络更加适用。
inceptionV2网络的特点是卷积核大,计算量也是成平方的增加。比如有一个5×5的卷积核,可以将其分成2次3×3卷积,这样输出的尺寸就一样了。虽然5×5的卷积可以捕捉到更多的邻近关联信息,但2个3×3组合起来,其“视野”就和5×5相同了。分解之后,训练的参数从5×5=25变成了2×3×3=18。
另外,相对于V2网络,V3网络加深了网络深度,从原来V2中的二维的卷积结构变成了2个一维的卷积结构,即原本3×3的网络结构变成了3×1与1×3两个,这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性。同时,网络输入从V2网络的224×224变为了V3网络的299×299,更加精细设计了35×35/17×17/8×8的模块。所以在inceptionV3卷积神经网络下的分类精度更加高。
4 总 结
本文基于不同云覆盖程度提出了新的4个遥感云覆盖图像场景类别,并对应3个级别来对卫星下传信息进行精确指示,并依据该准则提出了基于深度卷积神经网络的图像场景分类算法,可最终实现卫星图像的局部场景精细云判。相比较传统的整图是否下传,可以为卫星数据下传提供更精细的指示信息,实现图像信息利用最大化。实验分析充分考虑了未来算法在轨实现的可行性,选择了合适的网络和样本数据量,本文最终得到以下结论,为以后在轨实现云判功能奠定基础:1)辐射预处理可以整体改善图像的辐射亮度分布情况,并且可最终提高云覆盖图像场景分类精度;2)针对本文场景定义类别,当数据样本达到2 000左右,继续增加数量对分类精度的提升不明显,但样本精细筛选还可以提高分类精度;3)通过分析对比多种卷积神经网络,证明GooglenetV3网络既满足相对较低的复杂度,又满足高精度检测,更适合用于未来在轨遥感图像云检测应用。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2019年24期)2019-02-23
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20