
基于聚类算法的ERT污染区域识别方法
2019-03-29 07:40王玉玲宫淑兰
中国环境科学 2019年3期
王玉玲,王 蒙,闫 岩,宫淑兰,汪 明,徐 亚
基于聚类算法的ERT污染区域识别方法
王玉玲1*,王 蒙1,2,闫 岩1,宫淑兰1,汪 明1,徐 亚3
(1.山东建筑大学信息与电气工程学院,山东省智能建筑技术重点实验室,山东 济南 250101;2.林雪平大学科学工程学院,瑞典 林雪平 58183;3.中国环境科学研究院,北京 100012)
本文提出将聚类算法引入到ERT监测系统中,采用K均值(K-means)聚类、模糊C均值算法(FCM)以及混合高斯模型(GMM)3种常用聚类算法对ERT检测结果进行污染区域识别,通过一个数值模型分析了3种算法的识别效果.研究结果表明当污染区域与背景土壤的电阻率区分度较大时(电阻率差异性大于30%),采用3种聚类算法都可以识别出污染区域,K-means和FCM的识别效果优于GMM算法.最后,给出一个实际场地调查的应用案例.
ERT检测;污染场地;聚类算法;污染区域识别
我国存在大量污染场地,这些污染场地会造成对土壤和地下水污染,对人类健康和环境产生危害[1-2],因此,对污染场地的检测和修复是亟待解决的问题.由于电阻率成像(ERT)方法具有快速、费用低等优点,近年来开始尝试将ERT应用于场地污染及修复进程监测领域[3-4].在采用ERT进行场地监测时,通常会周期性地对场地进行ERT检测,这些检测数据需要被实时地分析处理.然而,目前对ERT检测数据的分析处理主要依靠人工完成,因此很难保证识别的效率和准确性,这成为制约ERT监测系统应用的关键问题之一.
近年来人工智能技术取得了高速发展,涌现出了许多新技术新方法,这些方法已被用来解决医学图像处理、自动驾驶等领域的问题,获得了良好的应用效果[5-7].其中,聚类算法用于在事先并不知道任何样本的类别标号的情况下,按照个体或样本的特征通过某种算法来把一组未知类别的样本划分成若干类别,使同一类别内的个体具有尽可能高的同质性,而类别之间则应具有尽可能高的异质性.
常用的聚类算法包括:K均值(K-means)算法、模糊C均值算法(FCM)、混合高斯模型(GMM)等.国内外学者对这些算法开展了大量研究[8-9].针对K-means算法对初始中心点的选择十分敏感,易陷入局部最优解的问题,Bradley等[10]提出了基于分布模式估计初始中心的方法,该方法使得迭代求解收敛于更优的局部最小值;Bagirov[11]研究了一种改进的最小平方和聚类问题的全局K-means算法,改善了K-means算法中初始中心点的选择问题; Tzortzis[12]提出了一种MinMax K-means算法,该算法根据类别的方差对每个类别赋予不同权重,得到一个优化的K-means目标函数,解决了对初始值的依赖.模糊C均值算法(FCM)[13]是在C均值基础上的一种改进算法,采用隶属度函数表示样本点隶属于某一类别的程度,通过优化各个样本点对不同类别中心的隶属度,使不同类之间的相似性最小化,同类之间的相似性最大化,从而决定各样本点的类别.Wang等[14]在FCM算法的基础上增加了空间信息,基于局部空间相似性度量模型自适应地确定初始聚类中心和初始隶属度.然后根据其固有的像素间的相关性,对模糊隶属度函数进行修正. GMM是由多个高斯分布函数的线性组合建立的模型.Huang等[15]提出了一种基于高斯混合模型搜索图像全局阈值的有效方法,该方法具有较强的鲁棒性,但是对于对比度较差的图像处理效果不精确.这些聚类算法被应用于医学图像处理领域: Baid[16]对K-means算法、高斯混合模型和模糊C均值聚类算法在脑肿瘤分割中的应用进行了比较研究;Kannan等[17]利用FCM算法对乳房以及大脑核磁共振图像进行了有效分割,其中该算法可将乳腺分为四个集群:脂肪、正常组织、良性病变以及恶性病变; Janssen等[18]采用GMM算法对人脑图像进行分割;徐立等[19]提出一种新的基于脑部MR图像的肿瘤诊断方法,该方法通过多阈值分割形态学操作检测图像的畸形区域,提取用于分类的高斯混合模型(GMM)特征,利用决策树分类器对肿瘤图像类型进行分类;Lalaoui等[20]提出了一种改进的期望最大化(MEM)算法并且对比了五种算法(K-means、FCM、MS、ES以及MEM算法)在分割人脑图像中的效果.除此以外,Li等[21]采用K-means算法对为岩石间断集进行识别.然而目前尚未有将聚类算法用于ERT检测结果中土壤污染区域的识别的报道.
研究表明,土壤的电阻率受到多种因素的影响,例如土壤类型、含水率、孔隙水离子浓度等[22-23],这使得在对ERT检测得到的电阻率数据进行解释时,没有一个普适的电阻率值可以用来划分污染土壤以及未受污染的土壤,不合理的阈值会导致错误的污染区域判定.针对此问题,本文研究了采用聚类算法,利用数据之间的相似性和差异性将ERT数据划分成若干类别,从而实现污染区域自动识别.
1 方法
1.1 K-means算法
K-means算法是聚类算法中使用最广泛的算法之一,它把个对象根据属性分为个类别,使得聚类结果满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小.定义损失函数如下:
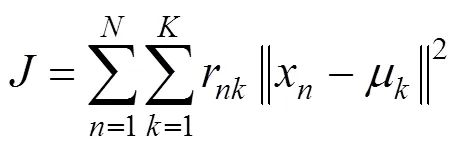
式中:x为待分类的数据点;为第个类别的聚类中心;r∈{0,1}来表示数据点x对于聚类的归属(其中=1,...,;=1,...,),如果数据点x属于第聚类,则r=1,否则为0.
K-means通过迭代求解,得到使得损失函数最小的所有数据点的归属值{r}和聚类中心{}.
1.2 FCM聚类算法
模糊C均值聚类(FCM)用隶属度确定每个数据点属于某个聚类的程度.它是硬C均值聚类(HCM)方法的一种改进.FCM把个向量x(=1,2,…,)分为个模糊组,隶属矩阵的元素允取的取值范围为[0,1].
FCM定义了目标函数如下:
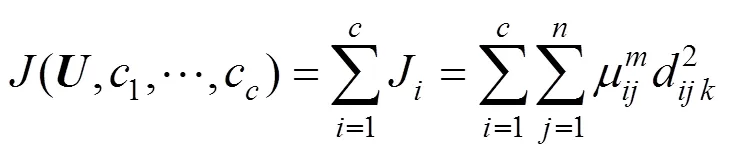
式中:u介于0,1间;c为模糊组的聚类中心,d=||c-x||为第个聚类中心与第个数据点间的欧几里德距离,是隶属度因子.一个数据的隶属度之和等于1:
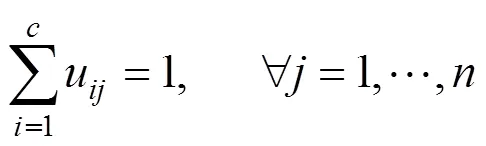
基于(4)和(5),构造新的目标函数如下:

式中:是约束式的拉格朗日乘子.对所有输入参量求导,使式(6)达到最小的必要条件为:
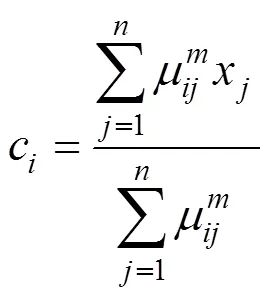
猜你喜欢
物探与化探(2022年2期)2022-04-28
防爆电机(2021年3期)2021-07-21
煤气与热力(2021年3期)2021-06-09
少儿画王(3-6岁)(2020年4期)2020-09-13
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
中国石油大学学报(自然科学版)(2014年2期)2014-02-28
