
佤语语音语料端点检测算法
2019-03-27 03:13和丽华潘文林杨建香解雪琴余彩裙
云南民族大学学报(自然科学版) 2019年2期
和丽华,江 涛,潘文林,杨建香,解雪琴,王 璐,余彩裙
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
佤语是跨边境少数民族语言,没有通用的文字,目前国内的佤族主要分布在中国云南省西南部的沧源县、西盟县、孟连县、耿马县、澜沧县等地区,国外的佤族主要分布在缅甸的东北部山区,例如佤邦、掸邦等地区.佤族是一个跨国界居住的少数民族[1],且佤语是佤族主要的交流工具,所以佤语的研究对国家安全和文化传承有重要的意义.
在这个网络信息化飞速发展的时代,语音是人们信息交流最直接、最快捷的方式,因此语音信号处理扮演着越来越重要的角色.20世纪50年代最早开始了对语音信号处理的研究,当时主要是为了解决检测语音段和非语音段问题,所提出的算法名称为VAD(voice activity detection)[2].在语音信号处理的过程中,端点检测是一项特别重要的语音处理技术.常见的端点检测方法主要基于以下特征:短时能量[3]和短时过零率[4]、熵[5]、倒谱[4]等,这些方法通常只注重特征参数的提取,却忽略了语音增强方面的工作,这对于语音端点检测的准确率产生一定的影响,并且这些方法在高信噪比的环境下进行端点检测可以取得较好的效果,但在自然带噪的语音环境中,因信噪比较低,此时的检测效果就大不如前.
基于上述考虑,结合之前的研究工作[6-7],本文使用了一种基于多窗谱估计谱减法和能熵比的语音端点检测复合算法对佤语语音进行端点检测.多窗谱估计谱减法可以在一定程度上对含噪语音进行减噪,从而获得较高的信噪比,其次对去噪后的语音使用能熵比算法进行语音端点检测.通过仿真实验证明:同常规能熵比算法相比较,本文使用基于多窗谱估计谱减法和能熵比的语音端点检测复合算法可以提高对佤语语音端点检测的正确率.
1 佤语的语音特征
佤语属南亚语系孟高棉语族佤德语支,没有声调,以下分别从元音,辅音,音节结构3个方面来分析其特征[8]:
1) 佤语的元音分为单元音与复合元音,单元音共有18个,复合元音又有二合元音和三合元音之分,二合元音有28个,三合元音有4个.
2) 佤语的辅音分为单辅音与复辅音,单辅音共有38个,复辅音则是由双唇和舌根塞音p、ph、b、bh、k、kh、g、gh等与边音l、擦颤音r组成的,共有16个.
3) 佤语的音节结构数目较多,但是结合形式较为整齐规律,主要可以归纳为12种基本形式(C代表辅音、V代表元音,其音节结构为V、VV等不计算在内).

表1 佤语的音节结构
2 研究方法
2.1 多窗谱估计谱减法去除背景噪音
Thomson在1982年提出了多窗谱估计[9],它是一种非参数直接谱估计法,首先该方法对同一数据序列加上多个正交的数据窗,其次分别求直接谱,最后求平均得出谱估计.相较于传统的周期图法[10]只用一个数据窗而言,多窗谱可以的得到较小的估计方差,是一个更加准确的谱估计法.
多窗谱定义:
(1)
式(1)中,L为数据窗个数;Smt为第k个数据窗的谱:
(2)
式(2)中,x(n)为数据序列;N为序列长度;ak(n)为第k个数据窗,它满足多个数据窗之间的相互正交:
(3)
数据窗是一组相互正交的离散椭球序列 DPSS (discrete prolate spheroidal sequences).
多窗谱估计谱减法[11]具体步骤如下:
Step 1 对带噪语音信号为x(n)进行加窗和分帧处理之后记为xi(m);
Step 2 对xi(m)做FFT后计算其幅度谱|Xi(k)|和相位谱θi(k);
Step 3 使用多窗谱估计并计算xi(m)平滑功率谱密度Py(k,i),并由已知的NIS帧的噪声段计算出噪声的平均功率谱密度值Pn(k);

因为被检测语音段一般都含有噪声干扰,传统的语音端点检测算法不能有效地检测出语音的起始点,所以使用多窗谱估计谱减法去除背景噪音,以提高被检测语音的信噪比.
2.2 能熵比法检测语音端点
2.2.1 对数能量[12]关系
设带噪语音信号为x(n),进行加窗、分帧后得到的第i帧语音信号为xi(m),帧长为N.则每一帧的能量为
(4)
引入一种新的对数能量
LEi=lg(AMPi+a)+lga.
(5)
式(5)中AMPi是计算出的每帧短时线性能量,a是一个常数.
2.2.2 谱熵[13]
设带噪语音信号为x(n),进行加窗、分帧后得到的第i帧语音信号为xi(m),通过FFT变换后,设第k条谱线频率分量fk的能量谱为Yi(k),则每个频率分量的归一化谱概率密度函数为
(6)
式(6)中,Pi(k)为第i帧第k个频率分量fk对应的概率密度;N为FFT长度.
每个语音帧的短时谱熵定义为
(7)
2.2.3 能熵比
能熵比指的是对数能量与谱熵的比值,其定义为
(8)
对于能量来说,有话段语音的能量数值较大,噪声段语音的能量数值较小;而对于谱熵而言,有话段内的谱熵数值要小于噪声段的谱熵数值,所以用能量比上谱熵可以突出有话段的数值,减小噪声段的数值,有效地拉开了有话段语音与噪声段之间的差距,更容易检测出语音的端点.
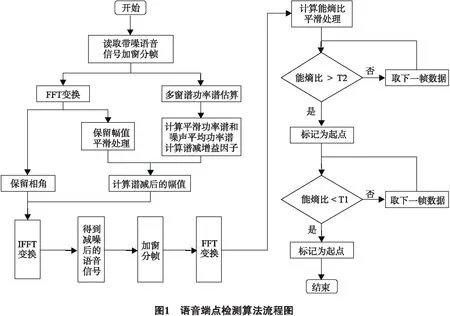
2.3 端点检测算法的实现
具体实现过程如下:
1) 带噪语音信号为x(n),在进行加窗和分帧处理之后的第帧i语音信号为xi(m),相邻帧之间有重叠.
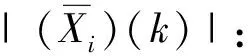
(9)
式(9)中以i帧为中心前后各取M帧,共有2M+1帧进行平均.
3) 对加窗分帧处理后语音信号xi(m)进行多窗谱估计,计算出多窗谱功率谱密度P(k,i)(其中i表示第i帧,k表示第k条谱线):
P(k,i)=PMTM[xi(m)].
(10)
式(10)中PMTM表示进行多窗谱功率谱密度估计.
并且对P(k,i)也做相邻帧的平滑处理和计算其平滑功率谱密度Py(k,i):
(11)
式(11)中以i帧为中心前后各取M帧,共有 2M+1 帧进行平均.
4) 由已知的NIS帧的噪声段,能够计算出噪声的平均功率谱密度值Pn(k):
(12)
5) 通过谱减关系来计算出增益因子
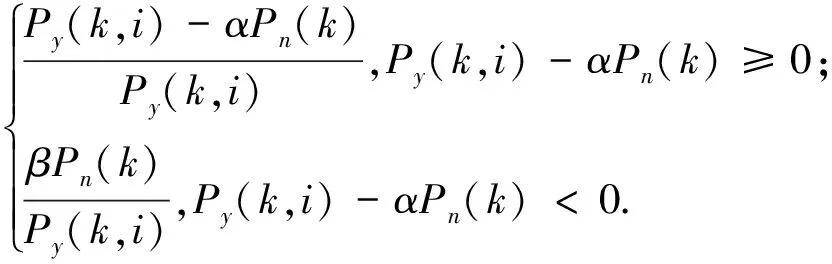
(13)
式(13)中α为过减因子(α>1,α的值越大,同时剩余的噪声衰减越大,语音的失真也会越大),β为补偿增益因子(0<β<1,β的值越大,同时剩余的噪声越小,语音的背景噪声也会变得越大).
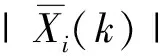
(14)
(15)
8) 由式(5)和式(7)计算减噪后的语音信号的对数能量LEi和谱熵Hi,再通过式(8)得出能熵比EEFi并且进行平滑处理.
9) 设置高阈值T2,若当前帧的能熵比高于T2时确定为语音段的起始点,若当前帧的能熵比不高于T2时,则取下一帧的能熵比与T2比较,重复步骤9),直到检测到语音起始点.
10) 检测到语音的起始点后,设置低阈值T1,若当前帧的能熵比低于T1时确定是为语音段的终止点,若当前帧的能熵比不低于T1时,则取下一帧的能熵比与T1比较,重复步骤10),直到检测到语音终止点.
11) 重复步骤9)、10)直至语音段结束.
3 实验
3.1 实验环境
实验环境:Windows10操作系统,CPU为Inteli3,内存为8GB,运行软件为Matalab2018.
3.2 实验数据
实验选用50个佤语孤立词音频文件进行测试,均在录音棚内录制.一共是由2位不同发音人(1男1女)共同录制,每人25个词.
3.3 实验结果与分析
为了验证本文算法对于佤语语音端点检测的准确率,使用Matalab工具对50个佤语孤立词音频文件进行仿真实验.实验分别采用常规能熵比法和基于多窗谱估计谱减法及能熵比法的复合算法对50个佤语孤立词的音频文件进行端点检测,通过比较其准确率可以看出两个算法在低信噪比环境下端点检测的性能.
下面以佤语“今天”的录音文本为例.(横坐标表示幅值,纵坐标表示时间,实线表示语音段的起始点,虚线表示语音段的终止点)
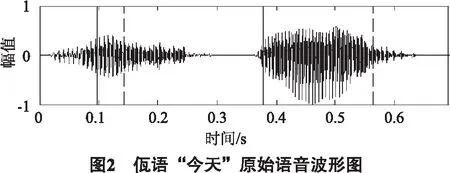
图2为佤语语音“今天”的原始语音波形图,从图2中可以清楚看到佤语语音“今天”的起始点(实线标注)和终止点(虚线标注),不难看出起始点和终止点前后都有一段噪音的波形,同时这段噪音音波形也覆盖在待检测的语音波形上,这会使端点检测算法将噪声检测为有效语音段,导致算法对语音起始点与终止点的误判.
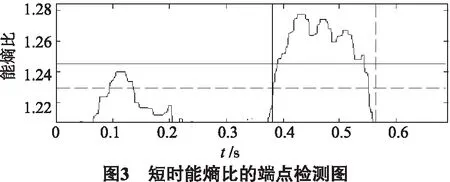
图3为佤语“今天”的短时能熵比的端点检测图,图中横着的实线表示高阈值T2,横着的虚线表示低阈值T1.从图3中可以明显看出佤语“今天”的前半段语音完全被漏检,造成漏检的主要原因是实验所使用的语音是含有一定噪声的且佤语“今天”前半段语音的对数能量值较小,导致其短时能熵比(能量与谱熵的比值)的值没有高于高阈值T2,所以端点检测算法没有将其检测为有效语音段.这样得到的佤语语音端点检测结果会导致语音切分的不完整,对后续佤语语音识别工作存在较大的影响.
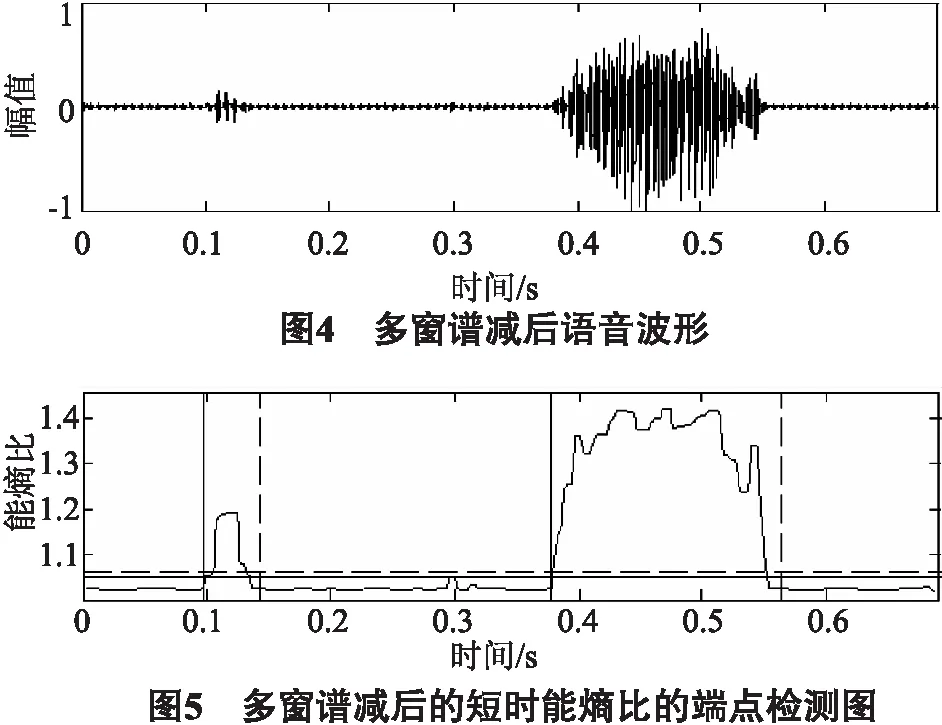
图4、图5分别为佤语语音“今天”多窗谱减后语音波形图和短时能熵比的端点检测图,图中横着的实线表示高阈值T2,横着的虚线表示低阈值T1.对比图2原始语音波形图与图4中的谱减后语音波形图,可以明显看出使用多窗谱估计谱减法对原始语音减噪后,能有效避免端点检测算法将噪声段检测为有效语音段。再使用能熵比算法进行端点检测时,对于佤语“今天”前半段语音的漏检的问题得到了明显的改善,检测结果的准确率明显提高。
从图3和图5中可以看出,在低信噪比环境下,常规能熵比端点检测算法并没有完整地检测到语音中所有的有效语音段,但是由于语音的完整性对于后续的语音识别工作尤为重要,所以本文采用多窗谱估计谱减法对语音进行减噪以提升信噪比,再结合能熵比法进行端点检测,能将每一个音都完整地检测到.
通过对50个佤语音频文件进行多次仿真实验,可以得到采用能熵比法和本文算法对佤语语音端点检测的准确率如表2所示

表2 采用不同算法的准确率
通过表2看出,常规能熵比算法对50个佤语音频文件检测正确的个数有24个,准确率仅为48%,而本文算法检测正确的个数有41个,准确率为82%.本文算法与常规能熵比算法相比,准确率提高了34%.由此可见,采用多窗谱估计谱减法对语音进行减噪后,再结合能熵比法进行佤语语音的端点检测,能有效避免噪音对佤语语音检测的干扰,较大程度上提高算法的准确率,为后续语音识别工作奠定了基础.
4 结语
目前的语音端点检测算法在无噪环境下的准确率已经达到令人满意的效果,但在实际应用中由于噪声和环境的影响会使其性能显著下降.为了提高在低信噪比环境下佤语语音端点检测的准确率,本文算法将多窗谱估计谱减法降噪以提升信噪比和能熵比端点检测相结合,综合了多窗谱估计谱减法保留了降噪后的清音、摩擦音和能熵比法突出语音段与噪声段区别的优点,改善了常规能熵比算法在低信噪比环境下准确率低的情况.通过理论分析和借助Matlab工具对佤语语音进行仿真实验,实验结果表明:同常规的能熵比法相比,准确率提高了34%,验证了其可行性和有效性,有利于后续语音识别工作的准确性.后续的工作是对于语音中两个基元粘连的情况进行有效的端点检测并进行切分,为以后的语音识别工作做前期准备.
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
石油地球物理勘探(2022年3期)2022-06-11
数学物理学报(2022年2期)2022-04-26
中学生数理化·八年级物理人教版(2021年9期)2021-11-20
文萃报·周二版(2020年17期)2020-05-09
中学生数理化·教与学(2019年8期)2019-09-18
微型电脑应用(2019年4期)2019-04-26
计算机应用与软件(2017年3期)2017-04-14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
装备环境工程(2015年1期)2015-02-06
