
基于大数据历史医疗档案检索系统的设计与应用分析
2019-03-25 03:57亓晓芳杨凌燕
中国医学装备 2019年3期
亓晓芳 杨凌燕
医疗档案作为记录患者从出生到死亡的所有生命体征的变化,以及自身所从事过的与健康相关的一切行为与事件的档案,其内容主要包括患者生活习惯、既往病史、诊治情况、家族病史、现病史、体检结果及疾病过程记录等。医疗档案具有即时性、碎片化、非结构化、数据量大、结构复杂、来源多样等特点。随着信息化、物联网技术的发展,特别是自动化采集技术在临床的广泛采用,医疗档案数据呈现暴增趋势,且来源于不同的业务系统。传统的检索技术难以满足海量数据实时检索的功能需求,医疗档案大数据检索技术研究具有较大的现实需求。
随着分布式存储、内存计算、云计算等大数据管理技术的发展及应用,基于分布式检索技术构建海量数据管理系统逐渐成为研究及应用的热点,目前已应用于图书管理、科研管理等领域。本研究基于构建医疗档案检索系统,着力解决当前存在的海量医疗档案数据检索效率低下的技术问题,完善数据管理功能,进而为数据应用及挖掘分析提供支持,实现医疗档案数据管理标准化、自动化[1-2]。
1 大数据历史医疗档案检索研究现状
1.1 需求分析
大数据历史医疗档案检索系统能够整合不同业务系统存储及组织管理形式,构建海量数据存储,实现数据采集、整理及存储等基础功能,降低档案数据采集的复杂性,增强系统可扩展性,并在此基础上构建医疗档案检索系统,实现跨业务系统档案数据关联检索、数据挖掘等功能,提高数据利用效率[3]。实现档案数据价值从档案数据本身变为档案数据深层挖掘以及数据组合;档案采集从被动的数据收集变为主动档案数据抽取;档案管理从档案记录管理变为海量数据集合管理;档案服务从被动式满足临床查询需求变为主动式服务提供,内容从查询扩展到统计、建模等多项内容。
1.2 数据采集与集成
(1)数据采集。数据资源采集技术是实现医疗档案数据管理的基础,建立数据采集机制是构建档案数据采集组织模式的重要前提,实现多接口数据对接、档案数据抽取、清洗转换及数据加载过程,即从各个不同的数据源抽取到数据存储(operational data store,ODS)中,完成数据采集过程[4]。
(2)数据集成。大数据环境下,数据集成是医疗档案数据管理需要解决的首要问题。由于各个业务系统间缺乏直接数据关联,无法构建数据集合,从而限制了数据规模的增长[5]。同时,医疗机构内业务系统间无法形成数据交换。
1.3 信息提供
在大数据环境下,医疗业务系统间实现了数据连接及共享,为更高层次的数据应用创造了条件。医疗档案信息从提供档案数据本身变为档案数据深层挖掘以及数据组合,即转变原有管理模式,将直接数据查询转变为数据关联分析,加速档案信息一体化进程[2]。
1.4 海量数据存储
在大数据时代,医疗档案数据急剧增长,既包括结构化记录又包括了大量非结构数据。如何迁移业务系统数据,实现海量数据的集中存储,动态分配存储资源,降低数据管理的复杂性,提高存储资源的利用率,并增强各业务系统的可扩展性,保障各业务工作的连续性和数据安全性,成为当前面临的重要问题[4]。
1.5 数据检索
随着业务系统的整合,医疗档案数据量急剧增长,原有的医疗档案信息检索方法已经无法适应当前需求,需要提升检索算法效率,提升数据检索的响应速度[4]。
1.6 数据统计分析
医疗档案数据不仅数据量剧增,信息复杂度也逐渐提高,既增加了档案存储的难度,又带来了数据分析的新需求。采用大数据技术,可针对海量数据进行统计、分类、聚类、回归以及协同过滤等操作,分析数据特征,挖掘应用价值,达到提高数据集的利用率的目的。
2 大数据历史医疗档案检索系统设计
2.1 系统结构
大数据历史医疗档案检索系统将不同业务系统中结构化数据经抽取转换加载(extract transform load,ETL)过程关联装配后存储到关系型数据库系统,独立文档等存储入Hadoop分布式文件系统(Hadoop distributed file system,HDFS)后经分词处理后生成关键词库,并在此基础上建立索引。当用户发出请求后,系统根据用户需求判断应用类型,调用对应功能。其中,采用ETL工具Kettle实现业务系统数据抽取、转换及载入功能,采用HDFS技术实现档案数据的分布式存储[5];采用Elasticsearch分布式的关联检索技术实现检索应用,数据挖掘及分析功能由Apache Spark实现。系统结构如图1所示。
2.2 数据抽取
数据抽取采用开源工具Kettle实现,该工具可以在Window、Linux及Unix上运行,绿色无需安装,数据抽取高效稳定。可通过图形化的用户环境,实现管理来自不同数据库的数据。通过编制transformation和job脚本实现抽取过程,其中通过transformation完成数据转换,job则完成整个工作流的控制[6-7]。可实现在应用程序或数据库之间进行数据迁移、从数据库导出数据到文件、导入大规模数据到数据库以及数据清洗并集成入应用程序等功能。并使用job作业方式或操作系统调度,来执行一个转换文件或作业文件,通过集群的方式在多台机器上部署,实现分布式检索功能[6]。
建立字段映射表,将业务系统数据与抽取数据建立对应关系。按照数据过滤条件,过滤并转换数据后载入存储结构(如图2所示)。
2.3 大数据存储
建立大数据存储是实施医疗档案应用的首要问题。面对海量数据,首先需要解决存储空间不足的状况,空间不足无法确保数据集的完整性。同时,还需要解决容量扩充、容灾备份等现实需求。
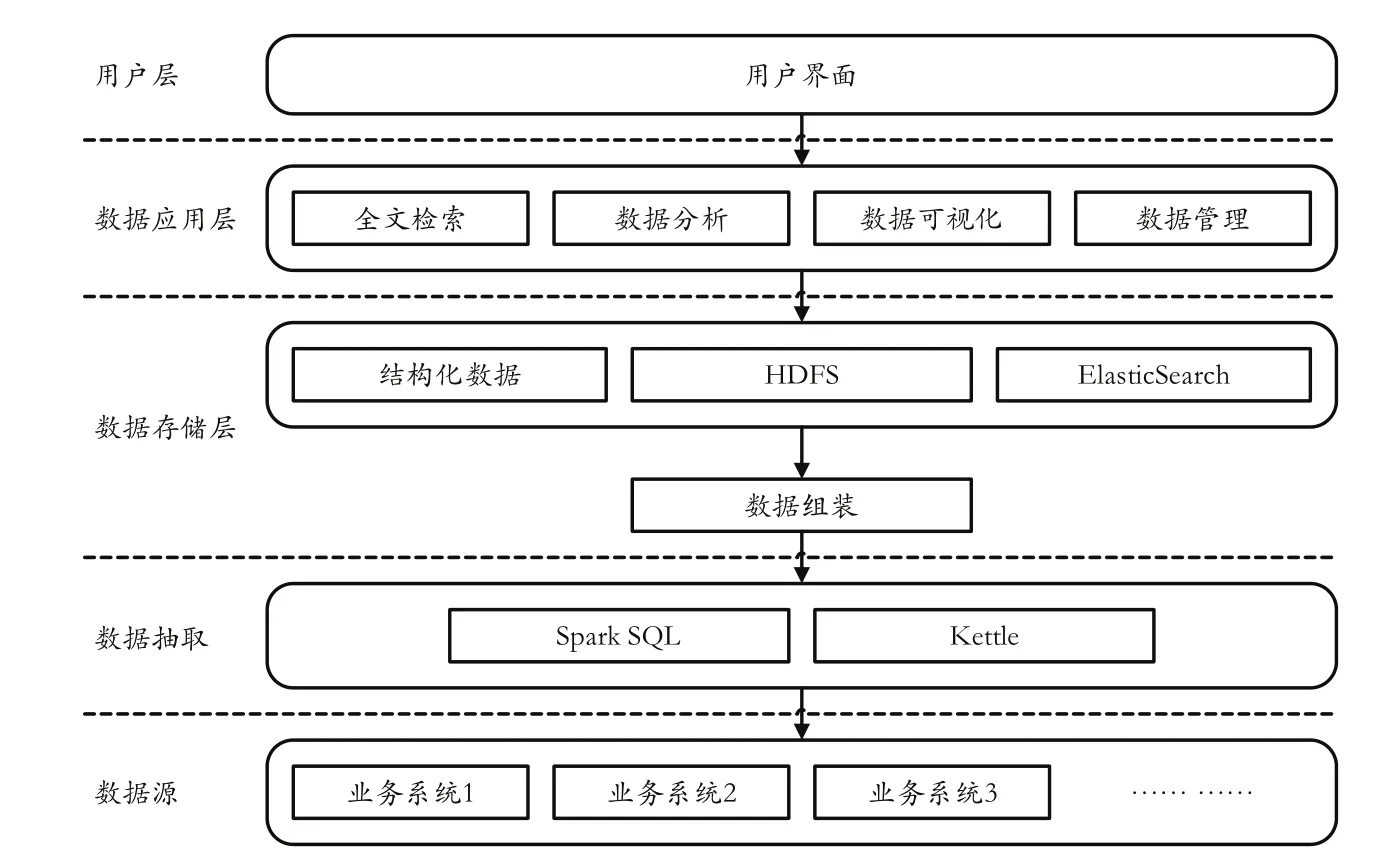
图1 大数据历史医疗档案检索系统结构图
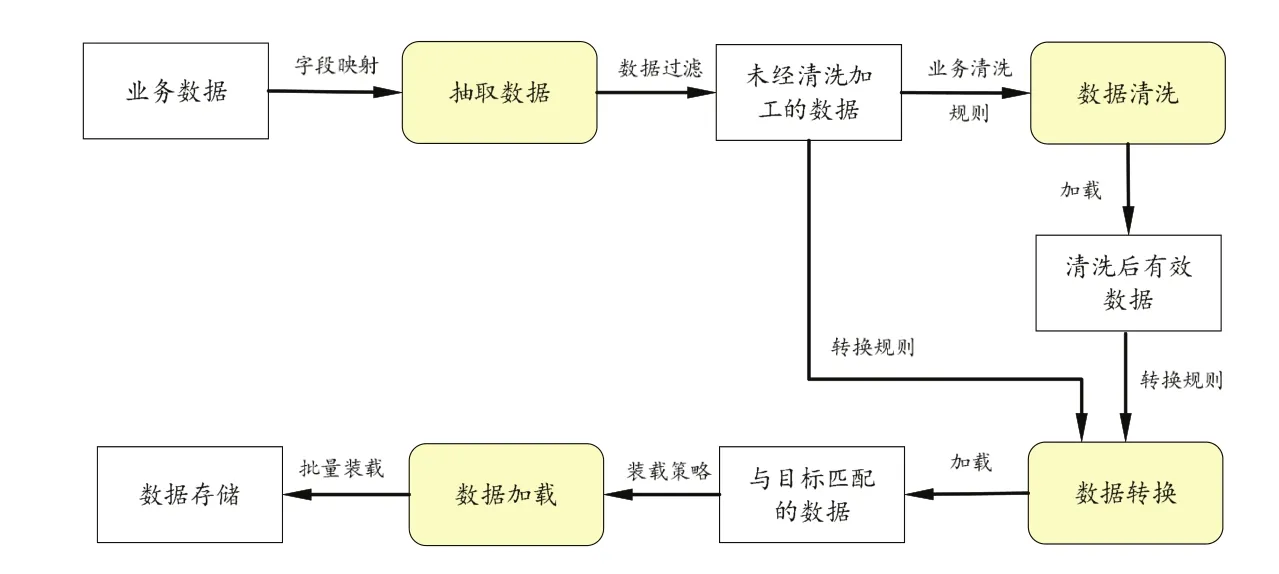
图2 大数据历史医疗档案检索系统数据ETL流程图
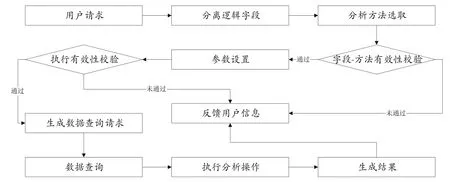
图3 大数据历史医疗档案检索系统数据分析流程图
系统存储采用Hadoop HDFS实现,作为高度容错性的系统,HDFS能提供高吞吐量的数据访问,适合大规模数据集上的应用[4]。可实现流式读取文件系统数据的目的,该系统有着高容错性的特点,并且适合部署在低廉的硬件上。可提供高吞吐量访问应用程序的数据,适合医疗档案大数据集的应用系统。与此同时,HDFS支持大文件存储,同时满足文本信息以及图片、视频等媒体信息的存储需求[5]。
2.4 数据分析
系统数据分析功能包括:统计分析及部分机器学习功能。用户选取需要分析的逻辑字段名,设置字段间关联,系统根据字段间连接建立逻辑组合。系统执行操作校验,针对字段类型、字段数量以及记录数进行核验,核验无误后用户选取分析方法,选择对应参数。系统生成查询记录请求并执行分析算法,生成结果后存储模型并显示报告。系统操作流程如图3所示。
在传统的机器学习算法训练及应用中,由于技术和单机存储的限制,只能在少量数据上使用。即传统统计和(或)机器学习依赖于数据抽样,而实际中样本难以实现随机,导致学习模型及测试精准度不足。系统采用HDFS等分布式文件系统,存储海量数据成为可能[8-9]。通过建立分布式数据分析工具,从根本上解决了统计随机性的问题。然而,由于Hadoop分布式机器学习过程资源迭代消耗巨大,特别是持久化过程,成为多次迭代的算法性能瓶颈[9]。Spark采用的内存计算模式以及实时批计算功能,克服了Hadoop MapReduce模式的瓶颈。同时,Mlib囊括了常用的机器学习算法和工具,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API等功能。
以构建Spark Mlib支持向量机(support vector machine,SVM)为例描述算法流程:


2.5 数据可视化
数据可视化工具采用Echarts2.0实现,该工具具有可视化类型丰富、刷新速度快的优点,可直接支持二维数据表、键值对、TypedArray等数据类型,兼容性高,支持IE、Chrome、Firefox等多种浏览器类型。当用户发出可视化请求时,前端页面向后端发出数据请求,完成检索后将查询结果组装后输出到可视化组件,向用户呈现检索结果。
2.6 数据管理
Hadoop Web UI作为HadoopHDFS分布式数据管理工具,但其功能及操作习惯难以符合医疗机构管理人员的要求。本研究基于HDFS java API接口开发了基于HDFS的医疗档案数据管理工具,实现HDFS下容灾备份、文件系统访问、文件创建、删除文件、条件检索文件、文件上传、文件下载、文件重命名等方法,便于数据管理。同时,提供了采用HDFS JAVA API功能接口实现针对HDFS操作的二次开发。
如下所示,以实现文件系统访问功能为例描述开发流程:

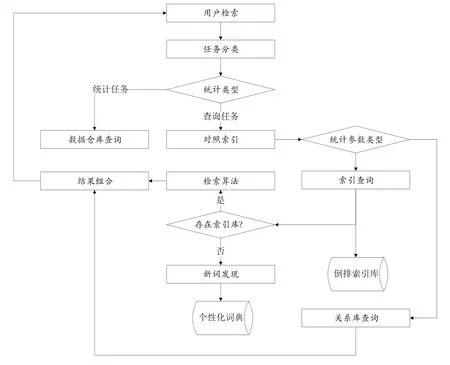
图4 大数据历史医疗档案检索系统数据检索流程图

3 大数据历史医疗档案检索系统应用
3.1 检索系统
系统数据检索采用结构化数据多维数据查询,结合全文数据库关联检索实现。其中:①Elasticsearch实现,Elasticsearch基于Lucene实现,可提供分布式搜索、分布式索引功能;②无需配置即可实现分布式功能,可根据预先设置的分片数、冗余,对索引文件进行分片;③根据当前节点数量以及节点上索引分片数,实现自动负载均衡;④提供restful接口并支持多种持久化策略。
当用户发出检索请求时,系统判断请求任务类型,为统计查询任务时,可选用数据仓库查询方法或Spark mlib统计查询算法;当为普通查询任务时,对照索引在数据集合中分别实施查询。在结构化数据集中,采用Spark SQL直接执行对应查询任务;在非结构数据集合中,采用Elasticsearch完成检索,两部分检索结果经组合后呈现至用户。系统流程如图4所示。
Spark SQL作为Spark数据查询组件,能够兼容常规数据库查询,同时也能够符合大数据条件下多种数据访问要求,其语法接近SQL语句,因此,系统通过该组件开发实现了关系数据库、HDFS及HIVE等数据源访问功能。Elasticsearch检索通过构建个性化词典、建立数据索引、开发数据检索算法等步骤实现[10-11]。分词采用Ansj分词组件实现,词典基于分词比对及发现机制构建,继而通过分词词元倒排后构建索引[11-12]。系统采用分布式搜索及词元关联机制构建检索算法,将用户输入分词后,通过检索算法实现检索功能[13]。
3.2 系统功能界面
传统档案数据管理通过档案文件收集、整理、存储、统计等操作,实现档案的集中化管理。基于大数据技术构建的历史医疗档案管理模式采用面向用户需求提供信息服务的应用平台。采用大数据医疗档案信息化管理可实现医疗档案数据抽取、整合、检索及分析工作,改变了传统应用模式,将原有的被动式数据服务模式转换为主动式服务提供模式。而在医疗档案信息化进程中,随着众多业务系统广泛使用,数据呈现丰富和动态化,在大数据技术的支撑下,实现数据接口统一规范、统一标准,档案信息资源可有效地实现采集、整合,构建大数据集合。系统功能界面如图5所示。
图5 大数据历史医疗档案检索系统界面图
3.3 系统查询功能测试
系统在关联检索技术的应用下,实现对档案信息的全文查询、组合查询、分类查询等,优化检索过程,较之传统查询方法,在单表查询、复合查询、跨库查询以及多维数据表检索性能均有所提高,同时弥补了传统方法难以实现非结构化数据检索的状况[14]。此外,先进的大数据存储技术克服了档案持久化的问题,最大限度地提高了存储空间的利用率,解决了传统档案完整性受限于存储空间的难题。大数据背景下的复合医疗档案数据集分析难度加大,原有的档案信息分析方法和模式已经无法适应大数据时代的需要,系统采用Spark Mlib算法工具包提升了分布式环境下档案信息的挖掘和分析利用效率,提升对用户需求的响应速度[15]。由此可见,基于大数据的档案信息化建设极大地拓展了医疗档案数据来源,提升了应用范围和医疗机构整体的应用管理水平。查询功能测试如图6所示。
图6 大数据历史医疗档案检索系统查询功能测试界面图
4 结论
随着信息技术的发展,医疗档案管理中数据资源如何获取及高效应用逐渐成为研究的焦点,随之而来的业务数据关联、信息检索、数据资源挖掘分析、数据检索以及数据服务提供均面临新的挑战。随着大数据技术发展,尤其是在图书档案、科研平台等领域的成功应用,引发了相关学科管理模式的变革,并以高效、全面、快捷及安全的特点,印证了其在海量数据管理及应用的巨大优势[12,16]。针对医疗档案数据集采集、海量存储、关联查询、分析应用等现实需求,本研究以大数据领域技术为手段,构建基于大数据检索系统构建的历史医疗档案管理系统。经测试运行,该系统可有效提高医疗档案数据集数据处理效率,在满足原有业务的基础上,扩展信息服务能力,在医疗档案信息化建设过程中,加强了业务系统中信息共享及数据集成,减少信息孤岛的现象。同时,采用大数据方法构建数据检索及分析工具,能够降低数据利用难度,提高查询效率。同时,该系统对于其他相关领域的海量数据管理具有一定的借鉴作用,有待在后续研究中逐渐扩展应用,助力学科发展。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
铁道通信信号(2020年4期)2020-09-21
文化创新比较研究(2019年33期)2019-12-26
当代陕西(2019年14期)2019-08-26
铁道通信信号(2019年12期)2019-05-21
科技与创新(2016年23期)2017-03-30
决策与信息(2016年30期)2016-11-26
