
近红外光谱与自组织竞争神经网络联用快速鉴别牛乳与复原乳
2019-03-25 10:57荣菡甘露菁
中国乳品工业 2019年2期
荣菡,甘露菁
(北京理工大学珠海学院材料与环境学院,珠海广东519088)
0 引 言
鲜牛乳富含蛋白质、脂肪、乳糖,以及各种维生素和矿物质,营养价值较高,被誉为“白色理想食品”。目前在我国乳品市场中,一些奶农或奶站为谋取利润在牛乳中加入复原乳、乳清粉,甚至加入植物奶油、粉末油脂、糊精等非乳物质,勾兑出与牛乳成分相似的假乳。
近红外光谱技术是基于近红外光谱信号量丰富、测量形式多样化的特点,对所包含物质信息对检测物进行定性和定量分析的一种技术,具有操作便捷、无损检测、绿色环保、分析准确等优势,目前已广泛用于食品及农产品、生物医药、石油化工等领域。
自组织竞争神经网络是一类无教师学习的神经网络模型,其无需期望输出,根据数据样本进行学习并调整自身的权重以达到训练的目的。它在工程、船舶雷达、遥感图像、环境气体等领域有相关研究[1-4],在食品定性模式识别研究中应用较少。
国内外有关近红外光谱技术应用于牛乳掺假的研究多采用与化学计量学方法联用,通过不同的聚类算法建立定性判别模型[5-7],而与自组织竞争神经网络联用,应用于食品掺伪研究,特别是牛乳掺伪鉴别方面并不多见。本方法能够实现相似度较高的鲜牛乳与复原乳的定性判别,为牛乳的品质指标的快速评价,提供一种新方法;为牛乳生产企业在线控制产品质量提供一定的技术支持。
1 实 验
1.1 仪器与试剂
傅里叶变换拓展近红外光谱仪及近红外光纤探头(美国,Thermo Nicole公司);OMNIC7.0、TQ7.0、Matlab2017a软件;生鲜乳,厂家从奶源产地提供;奶粉,市售。
1.2 实验方法
从不同来源的生鲜乳奶源产地取样,每天下午定时采样,采集后放入4℃便携冰箱中冷藏运回,立即进行光谱采集。
1.2.1 配制复原乳
复原乳样品由市场购得的四种不同品牌的奶粉兑水,按奶粉的含量配制成浓度梯度范围在1%~100%之间的复原乳。
1.2.2 采集谱图
采集全部样品共540个,分为训练校正集500个,预测集40个。
石英杯装约占容积1/4的样品,置于光纤架上扫描近红外光谱。每个样品采集6次谱图,取其平均光谱图参与建模,扫描条件为:扫描范围4 200~10 000 cm-1,扫描次数为72次,分辨率为8 cm-1。
样品谱图如图1所示。从谱图可知,鲜乳与复原乳谱图形状曲线及其相似,谱图无明显差异,因此难以用常规理化检验的方法对其加以区分。
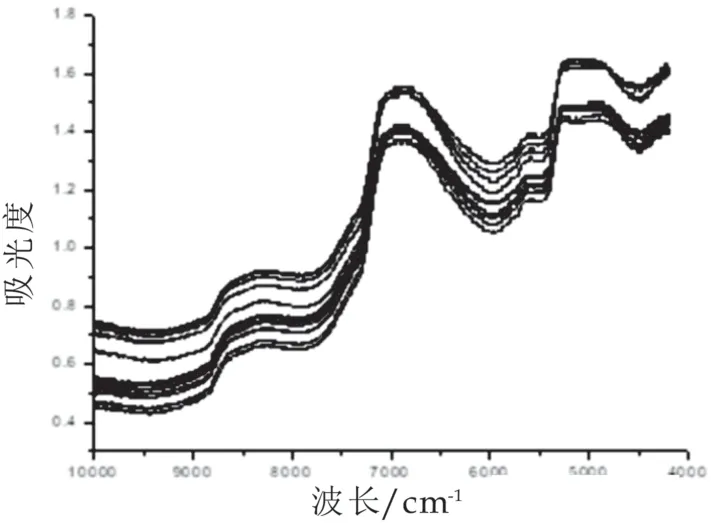
图1 鲜乳和复原乳的近红外谱图
1.3 构建自组织竞争神经网络的模式识别模型
采用光谱分析软件OMNIC7.0将训练集光谱转换成数据,用偏最小二乘法(PLS)对原始数据压缩,提取主成分。取前4个主成分的96个吸收峰值作为网络的输入向量。并采用预测集样品对模型进行验证。
2 结果与讨论
2.1 偏最小二乘法(PLS)提取主成分
样品全波长段的光谱量巨大,信息繁杂冗余,因此需使用光谱分析软件OMNIC7.0和TQ 7.0软件对样品数据进行压缩,采用偏最小二乘法(PLS)确定能够代表样品信息的最适主成分因子数。
样品光谱数据经过PLS法压缩后主成分得分如表1所示。由表可知,当提取4个主成分时,累计贡献率信度得分达99.562%,几乎可涵盖样品所有信息。
本实验取前4个主成分的96个吸收峰值作为网络的输入向量。
2.2 优化学习速率
根据样本量,基于网络稳定性考虑,按学习速率从小到大的顺序分别取0.01、0.05、0.1做网络稳定性优化实验,实验发现,当学习速率0.01时,学习速率过小,无法包含所有的样品信息;当学习速率0.1时,样本数据训练容易过度,无法代表有效的样品信息。当学习速率0.05时,此时网络性能最好,预测误差达到最小。因此本实验在对网络进行训练时,学习速率取0.05。
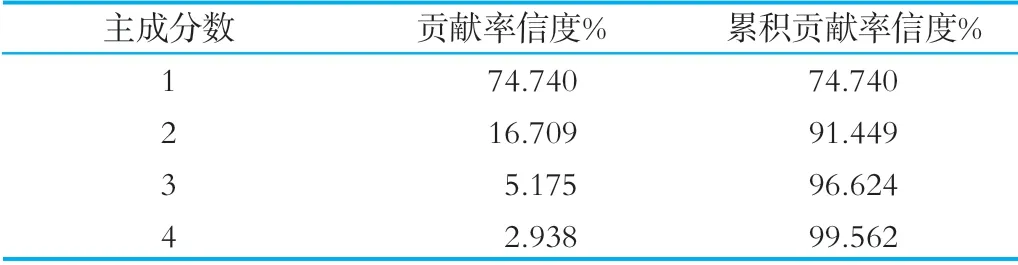
表1 经偏最小二乘法处理后主成分贡献率信度得分情况
2.3 训练步数
训练步数是神经网络的重要参数,训练次数过多会造成网络的过拟合,训练次数过少则使网络难以收敛,达不到训练要求。样品数据经PLS法压缩主成分后,用Matlab2017a软件对网络进行训练,实验表明,当网络训练200步左右即可完成鲜乳和复原乳的模式识别训练,如图2所示。

图2 网络训练过程
2.4 自组织竞争神经网络模型对预测集的预测结果
表2是自组织竞争神经网络模型对40个预测集样品的模式识别结果,以1、2分别代表复原乳样品和鲜乳作为目标输出,模型预测识别率为100%。
3 结 论
3.1 自组织竞争神经网络模型适用性总结
本实验以不同奶源基地的鲜牛乳为基础构建牛乳真伪模型,与单一奶源数据建模相比,模型包容性更好,且对来自不同奶源基地的鲜乳均能正确识别,预测结果准确。充分证明采用自组织竞争神经网络,即使在样本数量不大的情况下,仍能调整自身权重以达成训练,在逼近能力、分类能力方面优势明显。
3.2 近红外光谱技术对牛乳真伪进行模式识别需考虑检测限
在牛乳真伪的鉴别中,基于近红外光谱与自组织映射神经网络联用,经偏最小二乘法(PLS)处理后,提取4个主成分,使用96个吸收峰数据输入网络,网络学习速率为0.05,训练步数200步时,所建模型性能稳定,预测精度良好,在复原乳含量浓度的梯度范围在1%~100%之间,对预测集样品识别准确率达100%。
近红外光谱技术与非线性模式识别的神经网络联用时,预测结果良好,但仍需考虑技术检测限的限制,当掺假物浓度含量高于近红外光谱检出限时方能取得较好效果。
3.3 作为输入向量的敏感吸收峰的选择是建立模式识别模型的关键
经PLS法提取的可代表样品信息的前几个主成分,网络输入向量必须选择敏感吸收峰数据予以建模,这样才能充分反映样品光谱信息与样品组成或性质间的相关关系。笔者研究近红外光谱技术与自组织竞争神经网络联用,在鲜乳和掺假乳鉴别研究中发现[8-9],选择敏感吸收峰数据作为网络的输入向量是构建模型关系到预测准确率的关键因素,在本研究中之所以采用96个吸收峰数据予以建模,这是因为鲜乳与复原乳组成成分已并无大异,需要足够数量的吸收峰数据作为网络的输入向量才能较好反映两者的差异性。

表2 模式识别模型对预测集样品的预测结果
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
北京航空航天大学学报(2022年8期)2022-08-31
食品安全导刊(2021年21期)2021-08-30
空间科学学报(2021年1期)2021-05-22
自我保健(2020年8期)2020-01-01
食品界(2019年2期)2019-03-10
燕山大学学报(2015年4期)2015-12-25
海军航空大学学报(2015年1期)2015-11-11
航天返回与遥感(2014年4期)2014-07-31
食品工业科技(2014年23期)2014-03-11
