
基于改进遗传算法的配电网故障定位方法*
2019-03-22 12:00蒯圣宇朱晓虎高传海
沈阳工业大学学报 2019年2期
谢 涛, 蒯圣宇, 朱晓虎, 高传海
(国网安徽省电力有限公司 a. 发展策划部, b. 经济技术研究院, c. 合肥供电公司, 合肥 230022)
分布式电源(如风电、光伏发电、天然气发电等)具有低能耗、低污染的特点[1-2],近年来得到了迅速的发展,虽然分布式电源的接入能带来巨大的经济效益,但也严重地影响了配电网的安全稳定运行[3-4].
据统计,95%的用户侧停电是由配电网故障所引起的[5].为了保证配电网的安全性和稳定性,需要快速准确地定位故障线路,并恢复正常线路的供电,以使经济损失最小化[6].但随着分布式电源的接入,传统的辐射型单电源配电网络变成了用户和电源互联的多电源复杂网络.传统的潮流计算、继电保护和故障定位方法也受到不同程度的影响,为配电网故障定位的准确性和效率带来了新的挑战[7-8].
诸多专家和学者提出了不同的故障检测与定位方法,如行波法[9-12]、阻抗法[13-15]和基于人工智能的方法[16-18].行波法基于输电线路终端与故障点之间的行波传输与反射特性确定故障的位置.该种方法需要高速的数据采集设备、传感器、故障检测器和全球定位系统来捕捉故障位置的瞬态波形,然而由于配电网存在各种分支结构,故较少使用行波法进行故障定位[11-12].阻抗法根据节点处的电压和电流值来计算阻抗值,从而确定故障位置[13],其根据测量方式的不同,可以分为单端测量法和双端测量法[14].单端测量法使用变电站的电压和电流进行故障定位,双端测量法则使用配电系统两端的电压和电流进行故障定位与识别.虽然双端测量法具有更高的精度,但需要花费更多代价和通讯链路[15].尽管阻抗法在众多系统中取得了较高的定位精度,但文献[15]指出其精度可能受到多种因素的影响,如系统不均匀、线路参数的测量误差、不准确的继电器测量值和故障电阻等.基于人工智能的方法通过分析馈线与变电站的开关状态以及沿馈线和大气条件安装的故障检测设备所提供的信息进行故障定位.此类方法包括人工神经网络[16]、支持向量机[17]、遗传算法[18]以及其他各种机器学习方法[19-21],通常具有较高的精度与检测速度.其中,基于人工神经网络的方法实现简单,只需检测独立或非独立变量的非线性关系,但其精度依赖于训练数据的质量,且训练过程收敛较慢[16,19];基于支持向量机的方法即使在处理大规模配电网时仍具有较快的定位速度,但核函数和超参数的选择将极大地影响模型性能[17,20];而基于遗传算法的故障定位方法不仅能大幅提高检测速度,还能减小问题规模,但在分布式电源不同投切情况下,需要更改适应度函数与开关函数,从而降低了故障定位的稳定性及精度[21].
针对上述问题,本文提出了一种基于改进遗传算法的含分布式电源配电网故障定位方法.该方法通过改进传统遗传算法的变异算子、交叉算子、适应度函数和开关函数等来更好地适应分布式电源的不同投切情况.仿真结果表明,该算法可以适应配电网结构多变的特点,与传统的遗传算法相比具有更优的稳定性和定位精度.
1 遗传算法故障定位
遗传算法的基本流程如图1所示,其使用选择、交叉和变异3个基本操作搜索解空间,来求解优化问题.

图1 遗传算法基本流程Fig.1 Basic flow chart of genetic algorithm
选择操作即根据适应度值的大小从解集中淘汰劣质个体,选出优质个体,并经遗传或交叉操作遗传到下一代.交叉操作通过模仿生物进化的基因重组过程来产生新个体,一般只交换两个有较高适应度个体的部分基因来产生新个体,即单点交叉,示例如图2所示.变异操作则以小概率随机改变某个个体的基因来构造新个体,包括二进制变异与实值变异两种方式.

图2 单点交叉示例Fig.2 single point cross example
基于遗传算法的配电网故障定位首先通过分析馈线终端设备(feeder terminal unit,FTU)和数据采集与监视控制系统(supervisory control and data acquisition,SCADA)获取故障过流信息,并得到各馈线开关的过流状态;其次使用如图2所示的二值编码方式编码线路状态和开关状态,并定义开关函数联系线路状态与开关过流状态;然后根据线路的故障状态得到个体的基因表达,并生成初始化种群;最后使用上述遗传算法寻找适应度函数取最大值的个体,并定位故障区域.
该种方法主要针对传统配电网的故障定位问题,当分布式电源接入配电网后,网络的拓扑结构发生了改变,传统的适应度函数和开关函数已不再适用.此外,当配电网接入多个分布式电源时,需要使用N次遗传算法定位故障区域,因而效率低、速度慢.
2 改进遗传算法故障定位
针对传统遗传算法存在的问题,通过改进变异算子、交叉算子、适应度函数和开关函数等来更好地适应分布式电源的不同投切情况,有效解决含分布式电源的配电网故障定位问题.当配电网发生故障时,系统将接收到FTU和SCADA获取的故障过流信息,并启动故障定位算法流程.经过迭代求解可以直接获取故障区域,具体处理流程如图3所示.
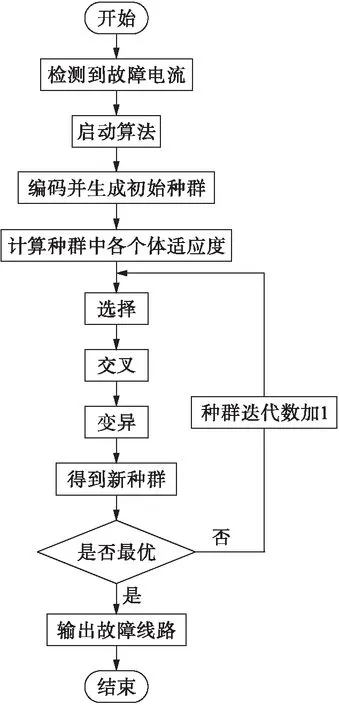
图3 基于改进遗传算法的配电网故障定位算法流程Fig.3 Flow chart of fault location algorithm of distributionnetwork based on improved genetic algorithm
2.1 交叉和变异算子
传统的遗传算法使用固定的交叉和变异概率,导致不同适应度的个体具有相同的变异概率,从而不易于保存具有较大适应度的个体.因此,本文提出了一种自适应的交叉、变异概率,其定义分别为
(1)
(2)
式中:Pcmax、Pcmin和Pmmax、Pmmin分别为交叉和变异概率最大值及最小值;f为个体的适应度值;fmax、favg为种群最大适应度和平均适应度.式(1)、(2)表明,交叉与变异概率在适应度的最大值和平均值间按照sigmoid函数进行非线性调整,以压低最大适应度附近个体的交叉、变异概率,并尽可能多地遗传到下一代.
2.2 开关和线路编码
随着分布式电源接入配电网,配电网的运行方式变得复杂多样.传统的基于电源位置的开关正方向定义方式需要将多电源网络分成多个单电源网络并反复计算定位,降低了算法的自适应能力,因此,本文提出了一种基于潮流流向的开关正方向定义方式.当分布式电源的投切状态发生改变时,可直接根据网路的潮流值来定义各开关正方向,该种方式不仅可以提高算法的自适应能力和定位速度,还能简化适应度函数与开关函数的定义方式.
传统算法使用0、1值编码线路,即开关正常时编码为0,而流过故障电流时编码为1.当分布式电源接入配电网后,开关可能流过与规定正方向相反的电流,已无法再使用0、1值来编码.因此,本文引入了中间状态编码方式,用-1表示开关正流过与规定正方向相反的故障电流.
含分布式电源配电网的电流方向如图4所示,电网中包含1个主电源S和3个分布式电源DG1、DG2和DG3,使用PSCAD仿真可以得到系统潮流如图4中实线所示(图中1~14表示开关,(1)~(14)表示馈线).当馈线2出现故障时,可得到此时电流方向如图4中虚线所示.使用本文编码方法,可得到14个开关的状态编码值为1,1,-1,-1,-1,-1,-1,1,1,1,0,0,1,0.
2.3 开关函数
针对分布式电源经常投切的问题,本文根据分布式电源的开关函数来表示各电源的投切情况,并引入了含分布式电源的开关函数,即
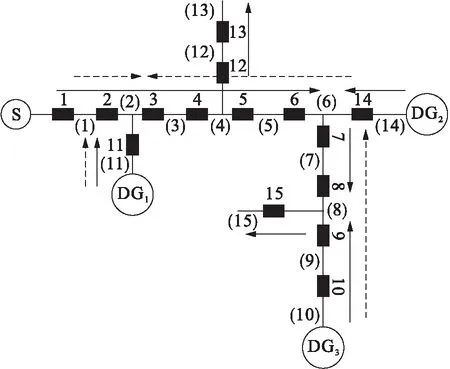
图4 含分布式电源配电网的电流方向Fig.4 Current direction of distribution networkwith distributed power generation
(3)
式中:s(i)为第i个开关的期望函数;‖为逻辑或运算;cj和ch为开关的投切系数;p、q分别为开关i上半区与下半区馈线区段总数;xi,p、xi,q分别为开关i上半区与下半区馈线的故障状态;xi,k、xi,h分别为开关i上半区和下半区所经过的馈线区间的故障状态.该开关函数可适用于单电源和多电源配电网,同时还可适应分布式电源的不同投切状态.
2.4 适应度函数
传统适应度函数应用于含分布式电源的配电 网时,易出现误判的问题.本文根据最小集理论,在原始适应度函数的基础上加入了一个正则项,即
(4)

使用对偶原理可将式(4)所示的求最小适应度问题转化为求最大适应度问题,即
(5)
式中,M一般取开关总数的两倍以保证适应度恒正.
2.5 分级处理
本文针对我国配电网具有开关运行、闭环结构和呈辐射状的特点,提出了一种分级处理的方式,以解决FTU监测点过多导致种群规模变大、处理效率低的问题.具体流程为:首先确定配电网的主干线路;然后沿这条主干线路将配电网分成一系列不相交的子区域,以减小可行解数目;最后使用改进的遗传算法对各子区域进行故障定位,该种方法能有效地减小种群规模、提高计算速度.
3 算例分析
本文结合文献[20]的配电网,选用如图5所示包含1个主电源S、3个分布式电源DG1、DG2和DG3的33节点配电系统进行算例仿真,分析单故障与多故障时算法的性能.
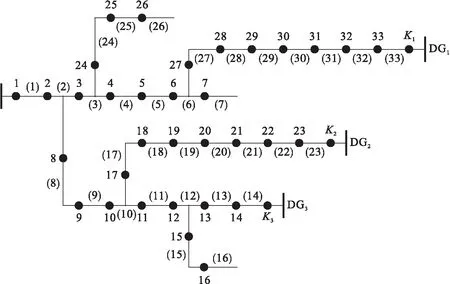
图5 含分布式电源33节点配电网Fig.5 Distribution network with distributed power generation with 33 nodes
本文通过设置投切开关K1、K2和K3的不同开闭状态来改变系统的潮流方向,如K1=1表示接入DG1,K1=0表示未接入DG1,同时电网在不同的开关状态下具有不同的主干电路.本文使用改进遗传算法对在多种不同情况下发生的单个或多个故障状态进行仿真分析.实验过程中设置算法的最大迭代次数为50,种群规模为100,M为70,仿真结果如表1所示.

表1 不同故障情况下的测试结果Tab.1 Test results under different fault conditions
从表1中可以看出,在单个或多个分布式电源接入配电网以及存在单故障与多故障的情况下,所提出的算法均可根据各开关的故障状态准确定位出故障区间.
为了进一步证明所提出算法的优越性,将提出的改进算法与传统的遗传算法进行了适应性比较.假设图5中配电系统的4、18处开关出现了故障,此时,系统获取的各开关的状态信息为[1,1,1,0,1,1,1,-1,-1,-1,-1,-1,1,1,0,0,-1,1,-1,-1,-1,-1,0,0,0,-1,-1,-1,-1,-1,-1,-1,-1],分别使用两种算法运行3次,得到的仿真分析结果如图6、7所示.

图6 改进遗传算法的3次测试结果Fig.6 Three test results of improved genetic algorithm
由图6、7可知,改进遗传算法所需的迭代次数明显比传统遗传算法要少.同时,提出算法3次测试结果较相近,而传统遗传算法易陷入局部最优解.由此表明,改进的遗传算法具有更优的稳定性和适应度.
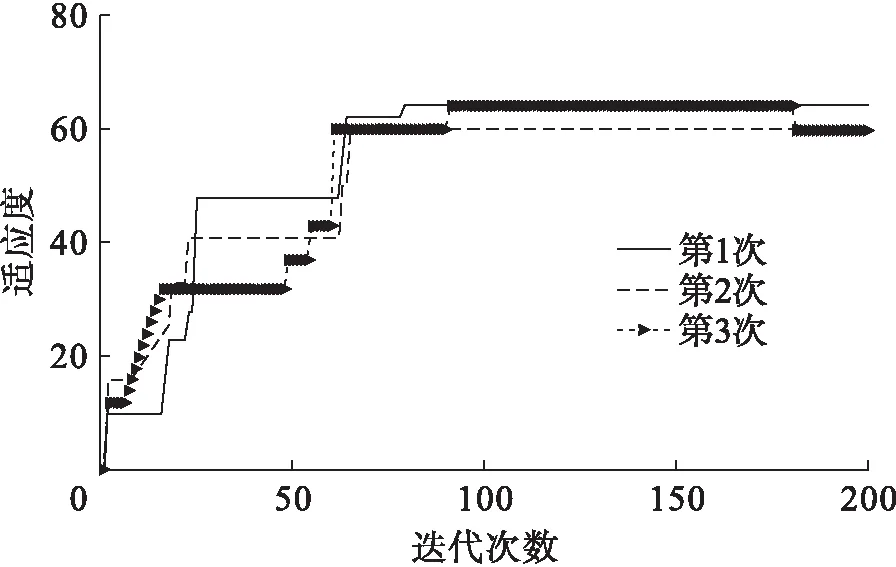
图7 传统遗传算法的3次测试结果Fig.7 Three test results of traditional genetic algorithm
综上所述,本文提出的改进遗传算法能有效定位含分布式电源配电网的单重或多重故障,具有收敛速度快、迭代次数少以及计算效率高的优点.相比于传统的遗传算法,本文提出的算法还具有更优的稳定性与适应度,可以更好地适应配电网结构多变的特点.
4 结 论
虽然分布式电源接入配电网能带来巨大的经济效益,但也严重地影响了配电网的安全稳定运行.本文针对传统遗传算法在分布式电源不同投切情况需要改变适应度函数与开关函数,从而导致故障定位稳定性与精度降低的问题,提出了一种基于改进遗传算法的含分布式电源配电网故障定位方法.通过改进变异算子、交叉算子、适应度函数和开关函数等来更好地适应分布式电源的不同投切情况,有效解决含分布式电源的配电网故障定位问题.实例与仿真结果表明,所提出的方法能有效定位含分布式电源配电网的单重或多重故障,具有收敛速度快、迭代次数少和计算效率高的优点.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
卫星电视与宽带多媒体(2022年10期)2022-07-01
通信电源技术(2021年23期)2021-05-25
浙江电力(2020年9期)2020-09-30
探索科学(学术版)(2019年5期)2020-01-18
电机与控制学报(2018年9期)2018-05-14
郑州大学学报(工学版)(2018年2期)2018-04-13
山东工业技术(2016年15期)2016-12-01
中国塑料(2016年11期)2016-04-16
中国铁道科学(2015年6期)2015-06-21
