
基于社会网络分析方法的书目二次归类研究
2019-03-20 06:52:10姜彩云孟亚琪王忠义
图书馆理论与实践 2019年2期
姜彩云,孟亚琪,王忠义△
(1.南通航运职业技术学院学生工作处;2.华中师范大学信息管理学院)
在这个信息爆炸的时代,信息过载[1,2]问题日益凸显,导致用户越来越难检索到自己真正需要的信息,特别是对于学习型用户来说,仅仅通过简单的书目检索难以找到自己所需要的相关书籍。就目前的网络阅读社区以及数字图书馆的书目分类体系而言,并没有很好的方法将其融入到书目检索系统中,也无法以分类体系为基础实现效果明显的书目推荐机制。因此,本文基于书目特征向量和社会网络分析方法实现书目的二次分类,主要目的是将其运用到书目检索和推荐系统中,为学习型用户提供更广的检索维度和推荐维度,优化用户的检索体验。
1 研究现状
目前,国内关于书目分类体系的研究主要集中于三个方面:① 书店的书目分类体系,这个部分又可以分为实体书店和网上书店两部分;② 数字图书馆的书目分类;③ 网络阅读社区的分类体系。
对于实体书店的书目陈列方法,王建强提出了构建基于《中国图书馆分类法》而不囿于《中国图书馆分类法》(以下简称《中图法》)的分类体系,根据营销需求或地域特征,对某些类目进行适当地更改。[3]吴永贵认为对丛书的处理宜采用集中归类与分散归类并行的办法,调整《中图法》的相关类目级别,[4]因为《中图法》类目划分的主要依据是书目的学科属性,而忽视了书目主题信息的重要性。尹云岚提出了“主题书架”的概念、作用、以及设立方法,这种《中图法》结合主题陈列法的应用,很好地弥补了书目分类陈列的弊端。[5]而网上书店的书目分类体系,更多地倾向于服务性与商业性。王益等发现“亚马逊”的书目分类体系多是从读者的兴趣出发,并且以销售为目的。[6]梁世敏在比较了中国各大网上书店的书目分类体系后发现,它们大都是按照个人的理解来设计分类,直观、易用,但通用性较差。[7]马小莉等人比较了中美网上书店的区别,发现我国的网上书店更重思想性、科学性,美国的网上书店更重服务性、商业性。[8]
数字图书馆大多按照《中图法》对书目进行分类,这种分类方法的主要弊端是忽视了书目主题之间的联系,常常导致主题相同的书被分在不同的类目。如,摄影艺术作品、理论属于“J4摄影艺术类”,但摄影学、摄影原理属于“TB一般工业技术类”。除此之外,《中图法》已经过多次修订,很多高校图书馆选择将新书按照新版分类法分类,旧书保持原来的分类,导致同类的书被分在了不同的类目,[9]所谓“同书异号”[10]就是指这种现象。
研究网络阅读社区分类体系的文献很少,因此通过对几个有代表性的网络阅读社区的亲身体验,笔者做出了如下归纳。“豆瓣读书”[11]是目前国内最受关注的网络阅读社区平台,它并不注重书目的标准分类,而是倾向于让读者自己分类,如标签分类法,在简单的几个大类下通常有读者自行编辑和选择的数以万计的标签,读者还可以自己创建书单进行分享,很好地结合了读者兴趣与书目主题两个维度。“网易云阅读”[12]整合了旗下的几个不同风格的阅读网站,如“国风中文网”“采薇书院”“QQ阅读”[13-15]更注重书目热度,以类目排行榜作为首页板块,同时,“QQ阅读”也重视对于读者的分类,如以性别为维度创建类目。
总的来说,相比书店和数字图书馆,网络阅读社区偏向于根据读者兴趣和书目主题进行分类。这与阅读社区用户不稳定性和社区之间的竞争有很大关系。尽管各种平台的书目分类体系有较大的区别,但是,其书目分类原则都是基于平台自身的发展需求。数字图书馆的归类严格遵循《中图法》,书店偏向商业化与利益化,网络阅读社区则偏向“讨好”读者,但无论是基于何种目的的书目分类体系,都没有很好地考虑到学习型用户的需求。目前,关于书目分类体系的优化研究集中于书店,其中,除了考虑读者兴趣和利于销售的建议之外,梁世敏建议在传统分类体系的基础上构建一个便于用户使用的多维分类体系。[7]本文提出的基于书目特征向量的书目二次分类方法并不是为了改变传统的书目分类体系,而是要在传统书目分类体系上,将二次分类的结果与书目检索机制相结合,从内容覆盖率、预测性等方面优化书目检索和检索推荐效果,使得学习型用户能够从更多维度检索到自己需要的书目。
2 书目二次归类实现方法
为了实现书目二次归类的目的,本文提出基于书目特征向量计算书目相似度以构建判断矩阵,再根据判断矩阵,利用社会网络分析方法对书目进行二次归类的方法(见图1)。该方法大致包含三个层级的处理:数据采集层、数据处理层、数据分析层。
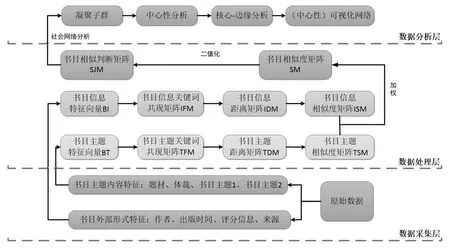
图1 书目二次归类方法的实现方法的过程
(1)数据采集层。数据采集层的主要工作是收集原始数据,包括书目外部形式特征和书目主题内容特征两个部分。书目外部形式特征包括书目的外部基本信息,书目主题内容特征包括能体现书目主题、内容的词条。
(2)数据处理层。数据处理层的主要任务是接收数据采集层得到的原始数据并对其进行整合、处理,最终形成书目相似判断矩阵。首先,将书目外部形式特征和书目主题内容特征进行整理、合并形成书目外部形式特征向量BI和书目主题内容特征向量BT,再对其进行关键词共现计算,构建关键词共现矩阵IFM和TFM;然后,基于此进行欧氏距离计算得到书目欧氏距离矩阵IDM和TDM,并通过标准化公式形成相似度矩阵ISM和TSM;接着,加权整合为相似度矩阵SM;最后,通过选取合适的阈值进行判断并最终形成相似度判断矩阵SJM(这是一个0-1矩阵)。
(3)数据分析层。数据分析层的主要任务是接收数据处理层得到的书目相似判断矩阵,并通过社会网络分析方法对其进行分析得到分类结果。具体包括凝聚子群分析、中心性分析、核心-边缘分析和基于中心性的网络可视化分析。其中,凝聚子群分析主要根据书目特征(不仅仅是学科领域的特征)找到书目数据库中的“小群体”,使得“小群体”内部书目相似度较高,[16]初步得到书目二次归类结果;中心性分析主要是根据节点的点度、接近中心性分析对各子群中的书目进行加权分析得到最终归类结果;核心-边缘分析和中心性可视化分析,分别从学习型用户和无检索目的用户两个角度说明了分析结果对书目二次归类结果的支撑意义。
3 实证过程
3.1 数据收集
为了在数据处理层建立书目特征向量,需要在数据采集层收集合适、完整的数据。书目特征向量由书目外部形式特征和书目主题内容特征两个维度组成。
(1)书目外部形式特征包括书目的基本信息,对这些信息的基本要求是:① 区分度适中,区分度过低的指标(如书目载体)和区分度过高的指标(如书目ISBN号)都不适合作为书目分类的数据;② 具有分类方面的意义,没有分类意义的指标(如出版社)或分类意义很低的指标(如书目篇幅)也不适合作为书目分类的数据。
(2)书目主题内容特征主要包括能体现书目主题内容的词条,对这些词条的基本要求是:① 对书目的区分度中等或中等偏上,对于书目主题来说,区分度中等偏上的词条是值得考虑的,区分度过低(如“文学”)并不适合作为书目主题的特征词;② 词条之间相关度要尽可能趋向于零,这是由于相关度接近1的词条会影响书目分类的准确性。
笔者利用爬虫技术采集了豆瓣读书TOP 250排行榜中225本符合要求的书的信息[17](检索日期:2017年11月9日)。依据对书目信息的基本要求,有关书目外部形式特征的信息,本文采集的书目外部形式特征数据为书名、作者、评分信息(评分与评分人数)、出版时间;书目主题内容特征的信息为(前十个)热门标签、“有用”数量前三的短评内容、“赞”数量前三的长评内容。
3.2 数据处理
(1)书目特征向量。书目特征向量分为两个维度,即书目外部形式特征和书目主题内容特征。由于对于学习型用户来说,用户的兴趣并不是一个重要的维度,因此并没有纳入书目特征的考虑。
书目外部形式特征向量如下
BIi=
其中,“BIi”表示编号为i的书目的信息特征向量,“aID”表示书目作者编号,“period”表示书目出版年代,“assessment”表示书目的评价情况(综合了豆瓣评分情况、评价人数、评论数量),“origin”表示书目来源(国内/国外)。
书目主题内容特征向量如下
BTi=
其中,“BTi”表示编号为i的书目的主题特征向量,“type1”表示书目体裁,“type2”表示书目题材,“theme1”表示书目主题1,“theme2”表示书目主题2。相比短评和长评的内容,热门标签的适用性更高,因为热门标签无需预先处理,而且热门标签的参评人数是书评内容的5-10倍左右,甚至更多。
确定书目主题内容特征值的步骤如下。① 筛选热门标签。将每本书的10个热门标签按如下原则筛选,删除长句子;删除作者名与作者的国籍信息;删除重复信息,如“明史”“明朝”“历史”同为某书热门标签,则删除“明史”标签;删除区分度几乎为零的标签,如“文学”;合并同义词、近义词,如“爱情”与“言情”,“大学”与“校园”;合并学术领域标签,如“心理学”与“心理”,“政治学”与“政治”;拆分组合词,如“古典名著”标签拆分为“古典”和“名著”两个标签。② 将标签填入相应主题特征维度。将所有剩余热门标签根据属性分别填入主题特征的题材、体裁、主题维度后,所有书目题材和体裁都已填充完毕,部分书目的书目主题部分没有值或只有一个值。③ 提取主题词。利用中文分词软件对书目的长评和短评内容进行分词并归纳共现频数,去掉停用词和无意义词。[18]按照频数大小选择词语作为书目主题内容特征值填入书目主题内容特征向量。最终形成的书目主题内容特征向量(部分)见表1。
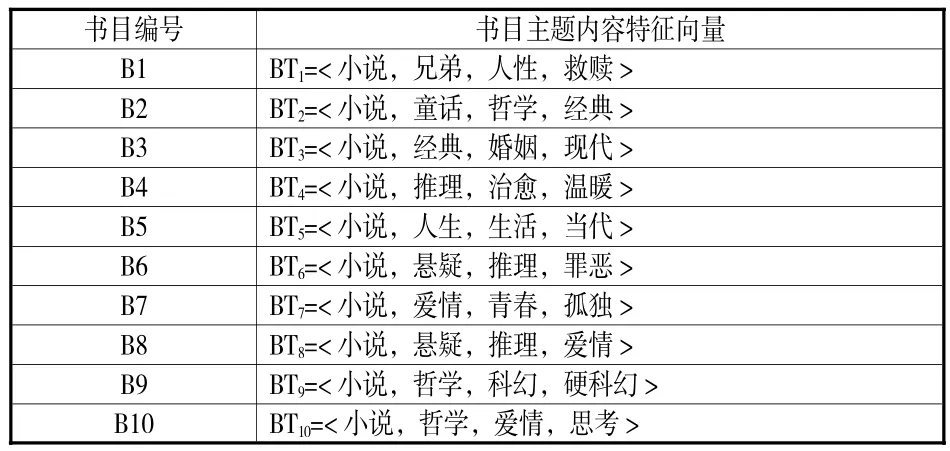
表1 书目主题内容特征向量(部分)
(2)建立共现矩阵。根据书目外部形式特征向量和书目主题内容特征向量分别建立关键词共现矩阵。首先,统计α个特征向量中出现的β个词,以这β个词构建β×β的矩阵,则矩阵中第i行、第j列的值就是第i个词和第j个词一起出现在特征向量中的频次。这一处理过程在MATLAB中的代码(以IFM的实现代码为例)为
A=arraySet;%图书信息特征向量集
B=zeros(173);%图书信息特征词共有365个
for i=1:225%书的数量225
for j=1:5
for m=j:5
%双向频数矩阵
B(A(i,j),A(i,m))=B(A(i,j),A(i,m))+1;
B(A(i,m),A(i,j))=B(A(i,m),A(i,j))+1;
end
end
end
for i=1:225%矩阵同行同列除以2
B(i,i)=B(i,i)/2;
end
IFM=B;%B矩阵即书目信息关键词共现矩阵
最终形成的共现矩阵IFM如表2所示。
表2 书目信息关键词共现矩阵(部分)
书目主题关键词共现矩阵TFM的构建代码类似,最终形成了422×422的双向矩阵。
(3)建立欧氏距离矩阵。这一步需要根据IFM、TFM和欧氏距离公式来构建书目信息距离矩阵IDM和书目主题距离矩阵TDM(见公式(1))。
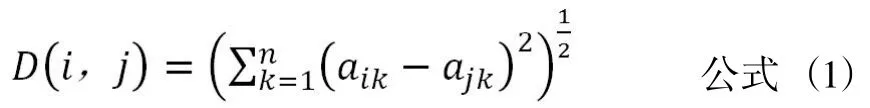
D(i,j)表示书目编号为i、j的两本书之间的欧氏距离,其中n为欧式空间维数,在IDM中n=196,在TDM中n=365,a_ik表示第i个点的第k维坐标值,a_jk表示第j个点的第k维坐标值。这个处理过程在MATLAB中的代码(以书目信息欧氏距离为例)为
A=sum(IFM.*IFM,2);%IFM 为关键词共现矩阵
B=IFM*IFM';
D=bsxfun(@plus,A,A')-2*B;
D=sqrt(D);
IDM=D;%D矩阵即为书目信息欧式距离矩阵
最终形成的书目信息欧氏距离矩阵IDM见表3。
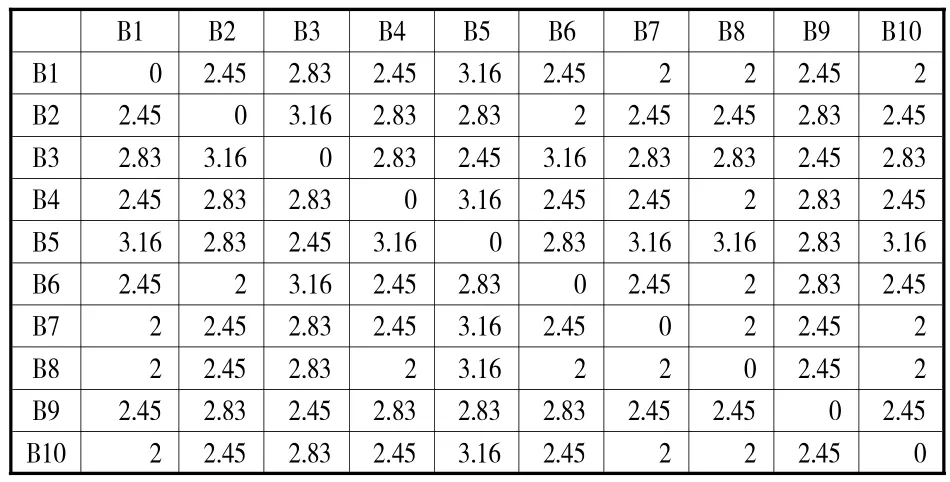
表3 书目信息欧氏距离矩阵(部分)
书目主题欧氏距离矩阵TDM与IDM的构建代码类似,最终IDM与TDM的矩阵规格不变。
(4)建立书目相似度矩阵。得到了距离矩阵之后,需要通过特定的方面将其标准化,使得矩阵数据被控制在[0,1]之间,建立相似度矩阵(见公式(2))。

其中c是一个常数,本文将c取值为1.4。D(i,j)表示书目编号为i、j的两本书之间的欧氏距离。这个过程在MATLAB中的代码为
A=zeros(225);%书目距离矩阵提取为 225×225矩阵
A=reshape(X,1,50625);
B=reshape(IDM,1,50625);
for i=1:50625
A(i)=1/1.4^B(i);
end
ISM=reshape(A,225,225);%ISM 即为书目信息相似度矩阵。
书目主题相似度矩阵TSM与ISM的构建代码类似,最终ISM与TSM都为225×225矩阵。
下一步将对ISM与TSM进行加权处理,形成书目相似度矩阵SM。考虑到学习型用户的需求,书目主题的重要性将大于书目信息,但是书目信息中的作者、年代维度又是书目检索与推荐的必备考虑因素,故将书目主题的权重定为w_1=0.6,将书目信息的权重定为w_2=0.4。对其进行加权处理所形成的书目相似度矩阵SM如表4所示。
(5)数据二值化。这一步的基本方法是选择一个合适的阈值对标准化后的相似度矩阵进行二值化,形成二值化判断矩阵,将其作为书目是否相似的判断标准。①二值化后独立节点——判断结果为“不与任何一本书相似”的书目占比15%左右。这是基于允许书目具有鲜明的特色而从信息和主题角度难以找到相似书目的目的。② 二值化后每本书的相似书目数量的均值、标准差、中间数合理。本文认为,均值在5-15、标准差在15以下、中位数在5-10是一个好的指标。这里对标准差的要求比较低,这是基于允许某些书的相似书目很多,也允许某些书几乎没有相似书目的目的,是根据书目本身属性来制定的,因此在选择阈值的时候,以上指标中的均值和中间值将是重点考虑的因素。③ 推广要求:数据量的因素,实证书目数量是225本,当实验数据增多甚至是应用于专业的数据库时,阈值应做出相应地改变;标准化公式的因素,在公式(2)中,常数c的取值如果改变,阈值也应该做出相应地改变。

表4 书目相似度矩阵(部分)
本文对不同阈值的二值化相似书目数量结果进行分析和比较,得到了分析结果如表5所示。

表5 二值化阈值取值结果比较
显然,0.44-0.46的取值结果是本文所期待的。本文最终确定了δ=0.45,应用这个阈值所得到的二值化的结果均值为10.9289,标准差为10.6038,中间数为6。应用δ阈值所得到的二值化相似判断矩阵SJM如表6所示。
3.3 书目二次归类
数据分析部分对书目相似判断矩阵SJM应用社会网络分析方法。首先,进行凝聚子群分析,得出书目初始归类结果;然后,经过中心度分析对每个子群中的书目依据号召力进行排序;接着通过核心-边缘分析对书目进行分层,识别出书目中一些特殊的沉默节点,找到边缘书目;最后,通过中间中心性分析识别书目中控制能力较强的书目,最终得到书目二次归类结果。
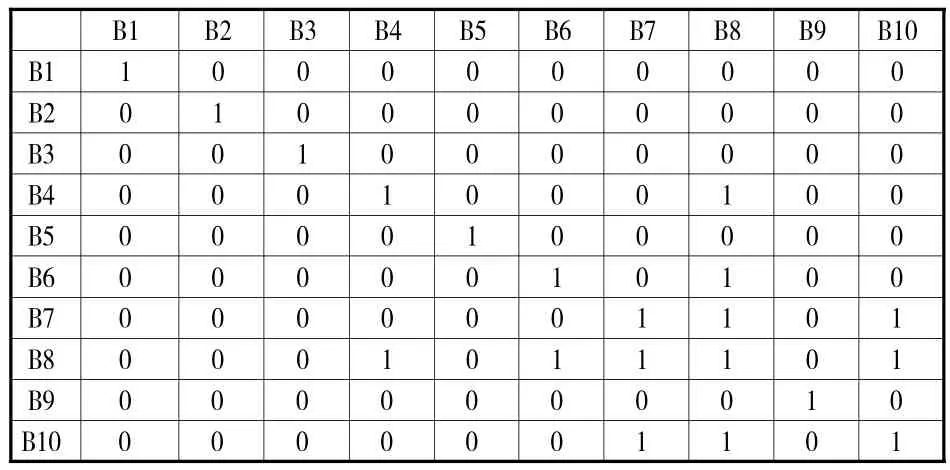
表6 二值化相似判断矩阵SJM(部分)(δ=0.45)
(1)凝聚子群分析。本文利用UCINET工具进行凝聚子群分析(CONCOR方法),并将分析结果作为书目二次归类的初步结果。书目二次归类(部分)结果见图2。
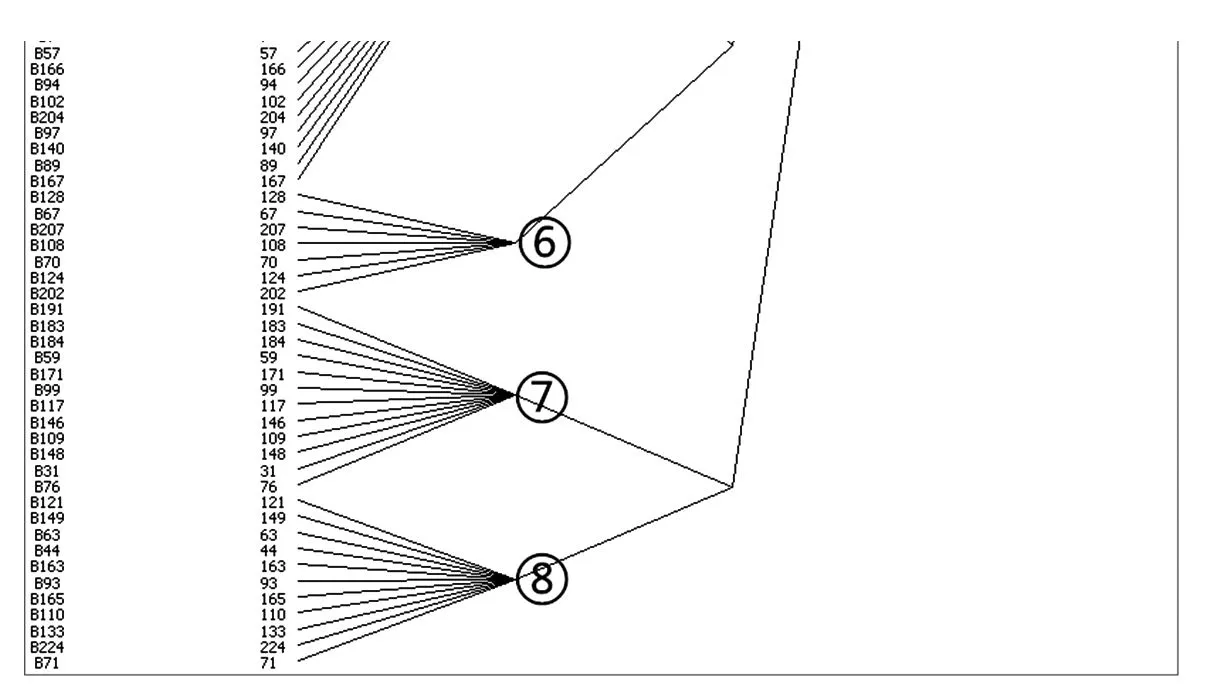
图2 书目二次归类凝聚子群分析结果图示(部分)
从最终的分类结果来看,225本书的一级分类有四类,二级分类有八类。数量最多的分类有53本书,最少的有9本。在本实验中,类别号从上到下分为①至⑧组,其中类别④为孤立节点的集合。
(2)点度中心度分析。在得到书目二次归类初步结果后,需要分辨每个类别中“号召力”更强的书目,即更适合推荐的书目。考虑到学习型用户的用书特点,对这些书目的基本要求是:① 该书目与本类别的书目相似度较高,联系密切;② 该书目与其他类别书目的交流相对方便。
要筛选达到要求①的书目可以使用社会网络分析方法中的点度中心度分析。点度中心度反映了与某节点直接相关(相连)的节点数,[16]可以筛选出某群体的中心节点,而中心节点一定程度上可以说明它们与类别内其他书目普遍相似度较高。要筛选达到要求②的书目可以使用社会网络分析方法中的接近中心度分析。接近中心度反映了某节点与所有节点的距离之和,[16]一定程度上可以认为该节点与其他类别中的点交流的方便程度。
因此,对每个类别的书目“号召力”进行排序时,以节点的点度中心度与接近中心度加权求和的结果为标准,权值为0.5∶0.5(因为要求①和②对于学习型用户来说都是非常重要的)。表7是利用UCINET对数据进行点度中心度、接近中心度分析的结果。

表7 点度、接近中心度分析(部分)结果
由于点度和接近中心度的计算方式不同,在加权时需要先对两种中心度的值进行标准化,将其都控制在 [0,1] 之间 (见公式 (3))。

其中i为书目编号,TCi表示“号召力”,Di为其点度中心度,Dmax为所有数据样本中点度中心度最大值,在本文中Dmax=16.518,Ci为接近中心度,Cmax为数据样本中接近中心度最大值,在本文中Cmax=1.64。书目“号召力”的计算结果如表8所示。

表8 节点综合“号召力”(部分)计算结果
在计算出所有书目在整体书目中综合“号召力”的量化数值后,便得到了书目二次归类结果(见表9)。
以上归类结果将书目共分为8类,其中类别④中全部为孤立节点,不与其他任何节点有明显联系。以“号召力”为依据将归类后的书目排序,若将该排序结果作为书目推荐列表,则用户对前列书目的点击将有效扩大检索维度和提高查全率。
(3)核心-边缘分析。利用UCINET的核心-边缘分析,可以找到数据集中的沉默节点,这些节点所表示的书目与其他书目的相似度普遍较低,这恰好可以说明这样的书目主题鲜明、扣题紧密。根据分析结果来看,可以找到如表10所示的边缘书目。

表9 书目二次归类(部分)结果(以类别⑧为例)

表10 边缘书目列表
在进行推荐时,与其他书目相似度普遍较低的书目通常不会被提起,但是学习型用户并不需要大量相似的书目,相反,主题契合度是一个很重要的条件。因此,这些书目不应该被忽略。
(4)中间中心性可视化分析。前面的研究使用点度中心度分析和接近中心度分析量化了书目的“号召力”。然而数据集中书目的位置、地位难以通过绝对的数字来表示。故本文利用UCINET的Visualize功能对书目二次归类结果进行可视化,并且以中间中心性为依据,区分书目网络中处于网络中心或边缘的书目。中间中心度可以体现节点对其他节点的控制程度,[19]可以通过可视化结果从整体上了解数据集中的聚类情况和不同聚类之间的联系。分析结果见图3(为了提高可视化网络的可读性,这里用书目编号代替了书目名)。
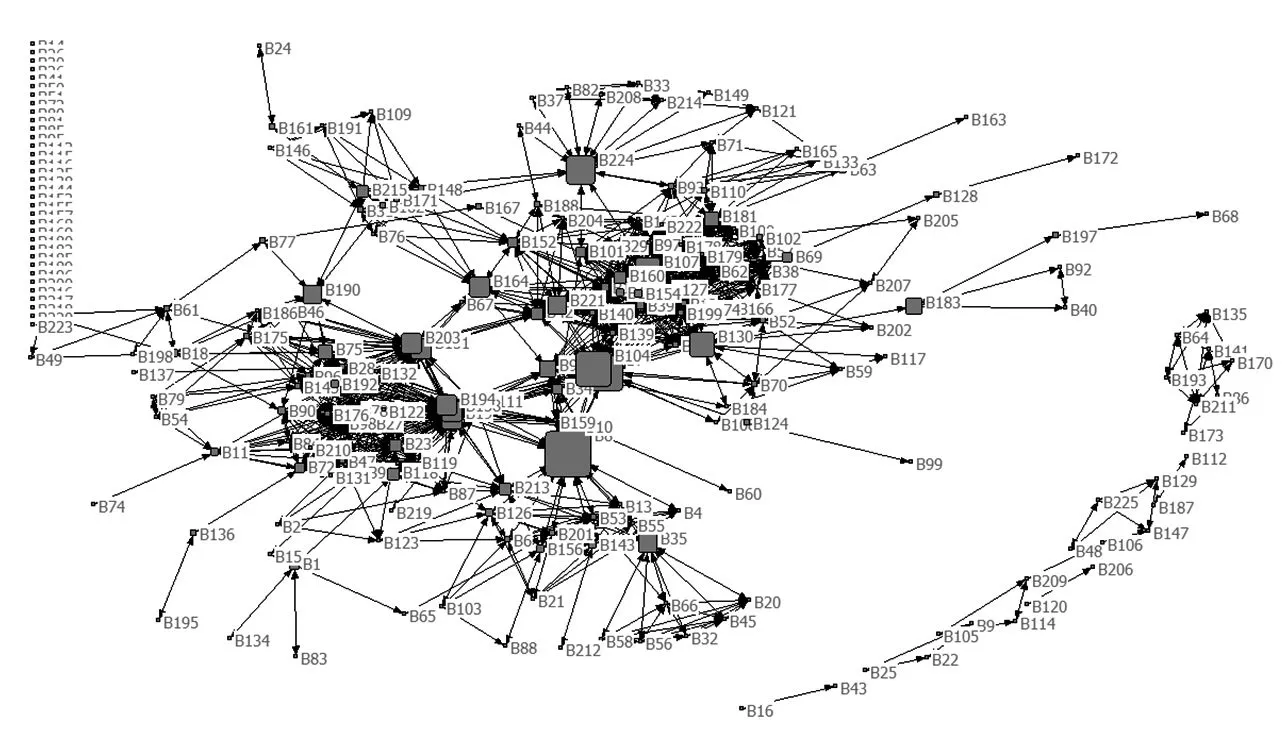
图3 中间中心性可视化网络
由图3可知,除了孤立节点外,整体网络可以分为四个区域,其中处于中心的书目有B7、B8、B104、B224等。在书目信息和书目主题的双重考量下,这些书目仍然地处中心区域,有两个可能:① 它们具有当代书目出版物的主流特征;② 它们的主题太过普通,不具特殊性。另外,除了孤立节点,存在一个区域(图示右下角)的书目与其他区域完全没有联系,在书目节点的条件下,如学科性质、体裁完全不同则有可能出现这种结果。
对于没有检索目的(即对书目没有特征要求)的用户来说,这些处于网络中心的书目节点可以帮助他们更快地确定一个检索方向。除此之外,相比从网络边缘出发,从网络中心出发找到一本用户满意的书所需要的检索次数和时间更加理想。
4 结语
本文利用豆瓣读书的225本书的信息构建了书目特征向量并建立关键词共现矩阵,通过标准化过程形成书目相似度矩阵、二值化过程形成书目相似判断矩阵,并通过社会网络分析方法实现对书目的二次归类。本文研究成果的意义在于,可以将图书分类结果运用到书目检索机制中,为扩展检索提供建议;也可以运用到一个针对学习型用户的图书推荐系统中,结合推荐机制构成一个不依赖于用户日志和检索历史的书目推荐机制,同时在推荐机制介入中心性分析结果的考察和计算,进而从书目覆盖率、预测性等方面优化学习型用户的使用体验。本文的局限性在于书目特征向量的维度不算非常完备,在未来的研究中需要进一步丰富书目特征向量的维度。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
都市人(2022年3期)2022-04-27 00:44:57
保定学院学报(2022年2期)2022-04-07 02:26:50
中学生数理化·中考版(2021年10期)2021-11-22 07:26:40
疯狂英语·新读写(2018年2期)2018-11-29 17:59:24
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
中学生数理化·七年级数学人教版(2017年12期)2017-04-18 11:22:16
中国民间疗法(2012年1期)2012-07-27 09:31:30
全国新书目(2009年1期)2009-04-13 06:58:24
