
关联数据驱动的学术资源语义检索推荐系统框架
2019-03-20 06:52:08上海财经大学人事处
图书馆理论与实践 2019年2期
田 野(上海财经大学人事处)
1 相关研究概述
1.1 关联数据应用系统的一般框架
近年来,伴随着 Thomson Reuters、MIT、JISC、美国国会图书馆、美国政府、英国政府及英国广播公司、纽约时报等机构出版发行关联数据,[1]关联数据的应用研究逐渐引起学术界和工业界的广泛关注。关联数据允许用户发现、关联、描述并利用各种数据,它已经成为推动语义Web发展的重要力量之一,从关联数据中获取的数据既可以来自一个组织内部的不同系统,也可以来自不同组织的不同系统,这些数据在内容、存储地点及存储方式等方面可能是完全不同的。关联数据作为语义网的重要特征之一,提供了一种基于可链接的URI发布、分享和连接Web页面中各种资源的有效方法,[2]其目的在于构建一种计算机和用户都能理解的结构化语义数据网络。它把原来相互孤立的数据通过语义关联的形式连接在一起,形成一个巨大的数据网络中心,实现了可动态关联的知识对象网络,并支持构建各种智能化的应用系统及各种知识挖掘与应用。[3,4]
Hausenblas[5]指出,关联数据应用主要包括两方面:关联数据在特定领域的应用;基于关联数据的各种Web应用系统。黄永文等[1]从目前已进行关联数据发布和实践应用的多个国家型图书馆、大学图书馆及图书馆联盟机构案例角度分析,指出在图书馆领域关联数据的应用主要包括改善检索服务系统的效果、增强资源发现服务、提供灵活的跨领域数据存取和重用。
Health等人[6]指出,关联数据应用系统的一般体系框架主要包括关联数据的发布层,关联数据的获取、集成和存储层及应用层(见图1)。基于关联数据的应用系统包含以下几个特点:① 使用遵循关联数据发布原则的数据,对可访问数据发出请求、检索和处理指令;② 根据不同数据源间的关联关系,进一步挖掘知识信息;③ 把关联数据与已有数据(可能是非关联数据)结合;④ 根据关联数据的创建原则,把融合后的数据再发布到Web页面上;⑤ 为用户提供增值服务。[7]
1.2 学术资源语义检索推荐应用
目前,推荐系统已经广泛应用于多种学术资源信息库中。如,万方数据知识平台会根据用户输入的单一关键词,推荐相似论文、引证文献、读者关联阅读文献及相关博文等;Elsevier数据库同样也有检索相似文献的推荐功能。
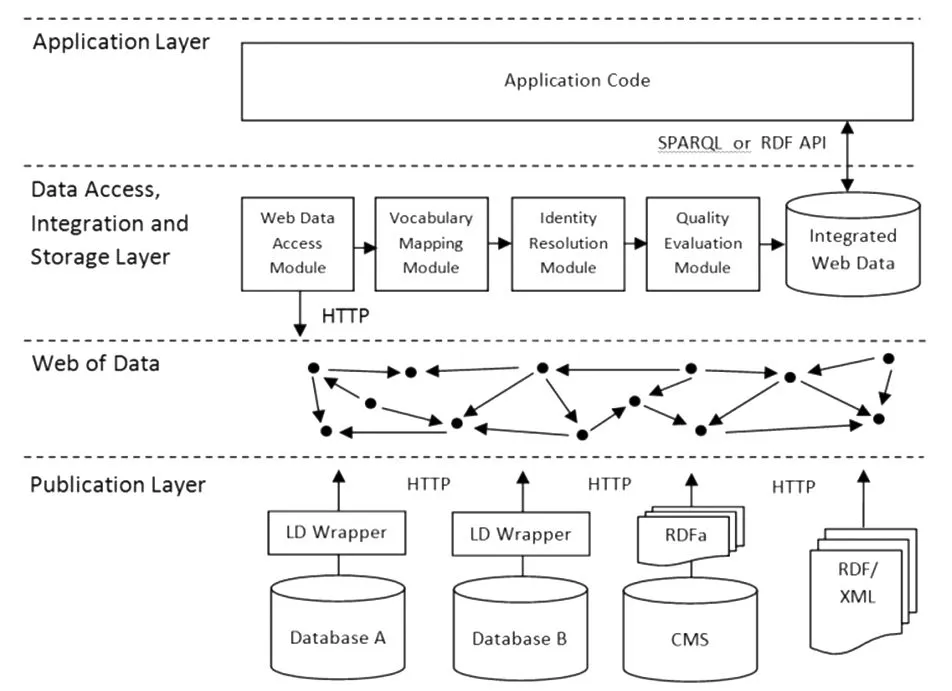
图1 关联数据应用的一般体系框架[6]
学术资源信息库中所有文献间的关联性主要包括以下几个方面:① 类别关联性,即在学术资源数据库中的所有资源可以划分成多种类型,相同类型的资源归于同一集合中;② 引用关联性,即在学术资源数据库中所有资源间的相互引用关系;③ 语义关联性,即在学术资源数据库中所有资源间在文本语义上的关联性;④ 时间关联性,即在学术资源数据库中所有资源出现时间的先后顺序。
学术资源数据库推荐系统大都以用户阅读行为为基础,利用所有文献在类别、引用、语义及时间上的关联性,为用户推荐学术资源。Watanabe等[8]开发了文献支持系统Papits,该系统具有论文共享、论文推荐、论文抽取、论文分类等功能,基于用户的浏览记录利用Scale-free网络构建用户模型,然后通过计算用户模型与文献模型之间的相似度,将具有较高相似度的文献推荐给用户。这属于基于内容的推荐方法,只需要考虑用户模型与文献模型间匹配度,不需要关注用户对文献的任何评价,对于浏览记录比较稀少的用户,此推荐方法是失效的。Huang等[9]提出了基于图模型的文献推荐系统,系统包括两层:第一层是书与书之间的关联,第二层是用户与用户之间的关联,两层节点之间的链接是用户对书的打分或者预测打分。Gori等[10]根据文献之间的引用关系,以图表形式展示了整个文献数据库,将相应的图矩阵进行归一化处理后,使用改进的PageRank算法进行推荐。Sullivan等[11]将激活-扩散模型应用于文献推荐中,用户输入的不再是一些关键词,而是其感兴趣的文档,发现基于文本信息的算法要优于基于引文信息的算法,基于文本信息和引文信息的算法要优于仅仅基于单一信息的算法。李琳娜等[12]和Goodrum A[13]利用文献共引关系实现文献的查找与推荐。
虽然这些推荐方法灵活地利用了学术资源信息库中所有文献间的关联关系及用户查询浏览文献时的历史行为数据,在推荐效果与用户体验方面取得了较好的效果,但是,这些方法大都忽略了学术资源信息库中所有文献间最重要的一种关联关系——语义关联性。几乎所有的文献都是以文字形式存储在学术资源信息库中,对文献内容的文字语义及文献间文字语义关联性的认知和研究就显得至关重要,特别是随着语义网技术的发展及关联开放数据源的不断扩大,原来相互隔离的数据源逐步以语义关联性串联在一起,这使得用户可以实现跨多数据源的信息检索与查询,有效扩展了用户检索查询的范围。Zarrinkalam等[14]把外部关联数据与本地数据相融合,填补本地出版物数据在介绍文本、引用列表、参考列表、作者名单和出版年份等方面的缺失,把参考关系、引用关系及作者的共著关系作为建立出版物关联机制的准则,提出一种基于用户输入文件相关联的混合式引文推荐方法。其中,文献间的语义关联性是通过文献间引用关系反衬出来的,并没有真正利用文献内容的文本语义关联性。
已有的大多数学术资源推荐系统利用了学术资源间的类别关联性、互引关联性和学术资源本身的语义关联性。[8,10,14]在这些学术资源检索推荐系统中,学术资源相关性的计算通常仅通过单一的本地数据源,不能为用户推荐与查询关键词匹配度更高的学术资源信息。为了克服上述缺陷,笔者在本地数据源的基础上,以本体关联的形式引入外部关联数据,提出一种基于本体的文本语义关联性计算方法,构建一个关联数据驱动的学术资源语义检索推荐系统。关联数据一方面能够帮助提高文本语义相关联的匹配度,提高用户对推荐结果的满意度;另一方面能够缓解单一数据源而导致的数据稀疏性推荐的冷启动问题。
2 关联数据驱动的语义检索推荐系统框架设计
把关联数据和推荐系统应用到学术资源检索过程中,能够进一步改善学术资源检索系统的效果,并实现多数据源系统的检索查询功能,同时推荐给用户与检索内容相关的文献资源,扩展检索功能。根据关联数据应用的一般框架,[6]笔者把推荐系统及关联数据应用到学术资源检索推荐中,设计关联数据驱动的学术资源语义检索推荐系统的框架模型,本文的创新点是探索关联数据的引入对语义相似性计算的改进(见图 2)。
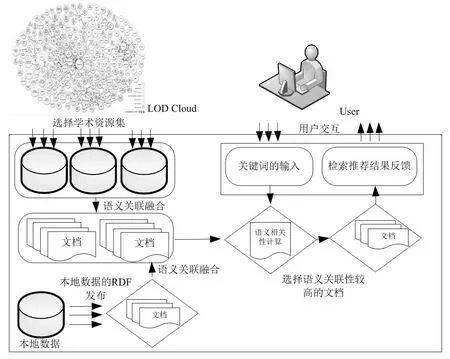
图2 关联数据驱动的语义检索推荐系统框架
① 关联数据的融合。首先,将中科院机构知识库网格平台中的本地数据发布成五星级的关联数据(http://5stardata.info),这种由本体支持的关联数据形式可以直接与LOD云中其他学术资源数据进行融合;其次,从LOD云中挑选出可用的学术资源,采用恰当的关联数据融合手段实现外部关联数据与本地数据的融合,形成最终的检索推荐数据集。② 语义相关性的计算。计算出与用户输入关键词语义相关的检索文献和推荐文献,笔者选择直接在融合关联数据上采用基于本体的语义相关性计算方法,避免了在单一本地数据集上的语义相关计算而产生低匹配度问题。③推荐引擎。选择合适的推荐算法,并把推荐结果反馈给用户。
如,在Elsevier和万方知识服务平台中,当用户在对话框中输入检索关键词之后,检索系统把数据库与用户输入关键词匹配度最高的学术资源文献反馈给用户,同时还把与每一个反馈文献相似度较高的文献资源形成推荐列表,反馈给用户。在此应用背景下,结合关联数据,学术资源检索推荐系统主要由如下模块构成:① 学术关联数据的整理和数据库的构建,包括检索数据库的设计与构建、学术关联数据的融合、数据的导入;② 用户交互界面,主要包括检索关键词的输入界面和检索推荐结果的呈现界面;③检索推荐过程。
3 文本语义相关性计算
在学术资源检索推荐系统中,用户输入检索关键词发起检索查询请求,系统要根据用户输入的关键字从资源库为用户返回语义相关性较高的文献资源,同时把文献资源语义相关性较高的其他文献资源以推荐列表的形式推荐给用户。此过程主要涉及两方面的语义相关性:用户输入关键词与文献文本的语义相关性、文献资源文本的语义相关性。其中,文献资源可以用多维关键词向量表示。
假设是一文档资源,那么此文档资源的多维关键词为:D={w1,w2,w3,…,wn}。因此,如果能够计算两个词语间的语义相关性,那么就可以解决用户输入的关键词与文献文本的语义相关性的计算问题。一般来说,两个词语间的语义相关性被定义为一个0-1之间的实数值,当两个词语语义完全一样时,他们之间的语义相关性为1,当两个词语属于两个完全不同语义概念时,它们之间的相关性为0。
词语间的语义相关性与语义距离之间存在着密切关系:两个词语间的语义距离越大,其语义相关性越低;两个词语间的语义距离越小,其语义相关性越大。[15]
设w1和w2是两个词语,记sim(w1,w2)为其语义相关性,dis(w1,w2)为其语义距离,那么sim(w1,w2)和dis(w1,w2)之间存在反比关系,即dis(w1,w2)越大,sim(w1,w2)就越小。① 当dis(w1,w2)为0时,则sim(w1,w2)为1,表示两个词语在语义上完全相关的;② 当趋于无穷大时,则sim(w1,w2)为0,表示两个词语间在语义上完全无关。两者之间的对应关系计算方法见式(1):
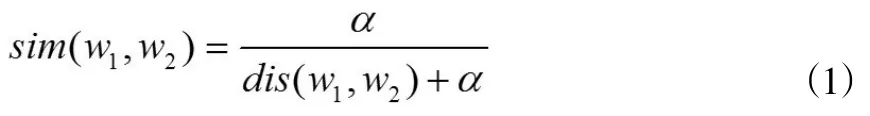
其中,α为调节因子。词语的语义距离有两种常见的计算方法:基于某种世界知识的或者分类体系的计算方法、基于大规模语料库的统计计算方法。基于分类体系语义距离计算方法又称为基于树的语义相关性计算方法,此类方法可以分为基于距离的语义相关性测度和基于信息内容的语义相关性测度。一般情况下,利用一部语义词典将所有的词组织在一颗或者几颗树状的层次结构中,[16]任意两个节点(词语)之间有且只有一条路径,那么这条路径的长度可以作为这两个词语概念间语义距离的一种度量,词语概念在树结构中的节点越深,其包含的语义信息就越深,也越能准确地决定概念的性质。基于语料库的词语相关性度量的研究大都采用上下文语境的统计描述方法,即认同如下论断:词语的上下文可以为词语定义提供足够信息。[17]词语向量空间模型是目前基于统计的词语相关性计算策略使用比较广泛的一种。
Lin[18]利用信息理论,提出通过树状结构中两个节点所含的信息量的大小来计算语义相关性。设s1和s2是两个义原,sp为距离它们最近的共同祖先,P(s)为节点s的子节点个数(包括其本身)与树中所有节点个数的比值。则s1和s2之间的相关性计算方法见式(2):

Rudi L C等利用信息论、压缩原理、柯尔莫哥洛夫复杂性、语义学等知识,把Internet作为一个大型的语料库,以Google搜索的结果数为计算的数据依据,提出了一种语义相关性计算方法。[19]设NGD(Normalized Google Distance,0-1之间)表示标准谷歌距离,用以衡量语义相关性的大小,f(x)和f(y)分别表示包含概念x和y的网页数,N表示Google引用网页总数,那么概念间的语义相关性计算方法见式 (3):

在关联数据中,领域本体提供共享词表,用来表示特定领域中存在的个体概念和个体间的相互关系。每个个体包含多种属性信息,不同属性信息对个体相似性会有不同的影响力。如,在文献相关性计算过程中,文献标题明显比文献出版年份更重要。设文献i和文献j的基本属性集分别为{ia1,ia2,…,ia}I和{ja1,ja2,…,ja}J,其中I和J分别表示文献i和文献j的属性数目。那么文献i和文献j的属性相似权重和定义为如下形式:

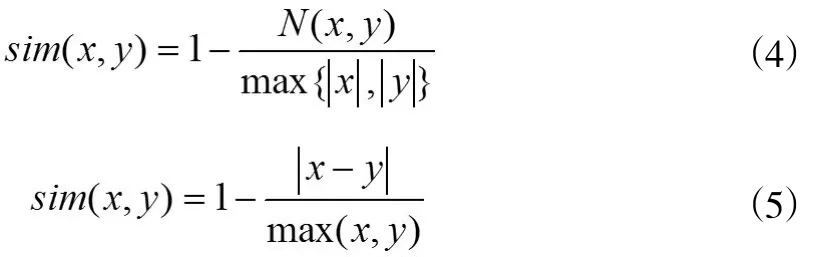
文献和文献间本体语义相关性计算方法为:

大多数文本语义相关性的计算都会涉及本体语义相似性的计算。刘宏哲等[21]把基于本体的语义相似性计算粗略分成基于树状本体结构的语义相似性计算方法和基于有向图的语义相关度计算方法。前者是基于概念语义分类词典WordNet构建的本体树型结构图,树中节点称为本体概念,将文本的每一个关键词映射到本体树型结构的概念节点,从而把文本语义相关性的计算转化成多维关联词组的语义相关性计算,两个关键词之间的语义相关性通常采用关键词在本体树型分类体系中的路径长度来度量,路径长度越大,关键词的语义相似性就越小;后者是基于Wikipedia中的页面网和类别网的抽象有向图结构,包含多种本体语义相关性计算方法。[22,23]
许多文献[24,25]把文本表示成一个个相关孤立的关键词列表,在文本语义相关性的计算过程中忽略了概念本体间的语义关联和语义扩展。本文把构成文本的每一个关键词在本体概念树中的映射节点的父节点和子节点的集合称为语义扩展集,并将其应用到语义相关性的计算过程中。
在如图3所示的本体概念层次树中,文本中的任意两个关键词为worda和wordb,它们在本体概念层次树中的映射对象分别为C3和C4,用dis(worda,wordb)表示它们之间的本体语义距离。此外,对C3和C4进行本体语义扩展:如果向上扩展,那么概念节点的本体语义扩展集合由该节点的父节点组成;如果向下扩展,则概念节点的本体语义扩展集合由该节点的子节点组成;把这两种扩展方式形成的本体语义扩展集合的并集称为此概念节点的本体语义扩展集。概念节点C3父节点本体语义扩展集为{C1},子节点的本体语义扩展集为{C7,C8,C9,C10};同样的,C4的父节点本体语义扩展集为{C1,C2},子节点的本体语义扩展集为空。那么,概念节点C3和C4的本体语义扩展集分别为 ={C1,C7,C8,C9,C10}和 ={C1,C2}。
笔者结合概念节点的本体语义距离和本体语义扩展集的相似性,计算两个关键词在本体语义上的相似性。采用Jaccard系数来计算两个关键词在本体概念层次树中的本体语义扩展上的相似性,具体计算方法如下:
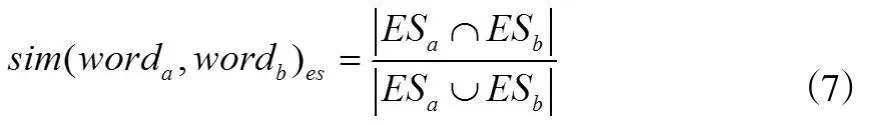
基于本体语义距离的相似度为:

笔者采用加权平均法,计算两个关键词的最终的本体语义相似度:
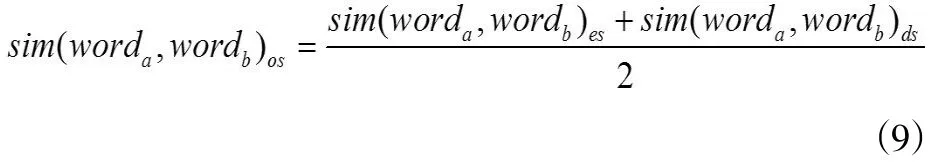
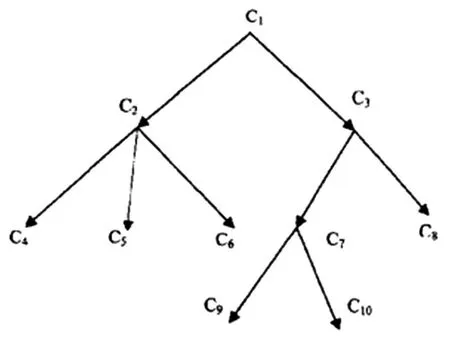
图3 本体概念层次树
在没有涉及关联数据条件下,文本(本体)语义相关性的计算方法只会涉及本地单一数据库中的文档信息,如果存在缺失或遗漏,就很难计算出此类文档的语义相关文档,这容易导致推荐系统冷启动问题的出现。此外,在计算本体语义相关性的过程中,还需要领域专家参与领域本体的定义。在关联数据中,语义相关性的算法过程就不会存在此类问题。关联数据条件下的语义相关性计算方法融合了文献间的互引关系和本体语义性,充分利用了关联数据学术资源数据库中固有的属性本体语义关联性和相互引用关联性,提高了文献的查准率。
4 语义检索推荐策略
推荐算法是推荐系统的核心部分,能够直接影响推荐系统的效率和性能。推荐算法的类型大致可以分为3种:基于内容的推荐方法、协同过滤方法、组合推荐方法。为了适应学术资源检索推荐系统的要求,笔者采用基于内容的推荐方法,该方法不需要存储用户历史浏览日志,能够有效降低系统的存储空间,也不需要建立用户模型,更不涉及其他用户的历史数据。因此,该方法不存在用户冷启动问题。学术资源检索推荐算法的简化流程见图4。
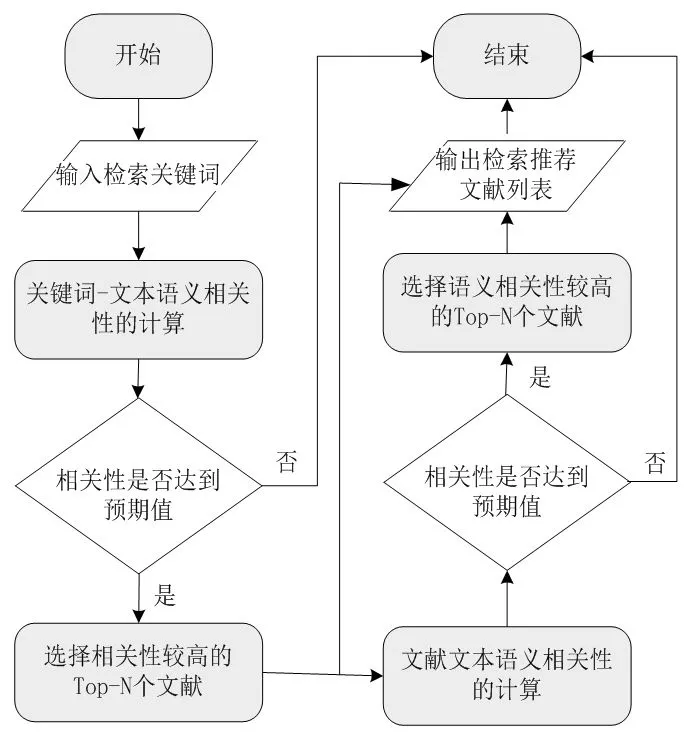
图4 学术资源检索推荐算法简化流程
① 用户输入检索关键词。② 采用分类体系语义距离计算方法,计算关键词与学术资源文献词语向量中每个元素间的语义相关性。③ 根据预设的语义相关性阈值,判断学术资源信息库中的每个文献与用户输入关键词间的语义相关性是否大于预设相关性阈值。如果成立,把这些学术资源文献进行排序,选出相关性最大的前Top-N项文献,称之为检索文献;如果不成立,舍弃。④ 采用文献文本语义相关性的计算方法,计算之前选出的Top-N项文献与学术资源信息库中其他文献的相关性,并为每个文献挑选出语义相关性较高的Top-M项文献资源,称之为推荐文献。⑤ 把与用户输入关键词语义相关性较高的前Top-N项检索文献及每个检索文献的Top-M项推荐文献反馈给用户,完成检索推荐任务。
5 总结
伴随着关联开放数据的不断增加,基于关联数据的应用研究逐渐成为热点。为了便于数据的融合,本文把中科院机构知识库网格(CAS IR GRID)平台中的本地数据发布成五星级的关联数据,提出一种基于本体语义的文本语义相关性计算方法,并构建了基于文本语义的文献检索推荐方法和具体实现框架模型。在此推荐模型中,实现了本体数据与关联数据的语义融合,避免了一般推荐系统因数据源单一而造成的数据稀疏性和冷启动问题,同时扩大了用户检索查询的范围,能够有效提高检索查询的效率。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
中国音乐学(2020年4期)2020-12-25 02:58:06
当代陕西(2019年15期)2019-09-02 01:52:00
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
专利代理(2016年1期)2016-05-17 06:14:36
文学教育(2016年27期)2016-02-28 02:35:15
卷宗(2013年6期)2013-10-21 21:07:52
当代修辞学(2011年2期)2011-01-23 06:39:12
