
基于深度神经网络的城市声音分类模型研究
2019-03-19 03:57:16,
浙江工业大学学报 2019年2期
,
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
城市环境声音事件的自动分类有各种应用,包括上下文感知计算[1]、监控[2],或基于内容的多重检索技术,如对城市事件的高亮提取[3]、视频摘要[4](确定重大城市事件)等。更为重要的是,人们每天都暴露在各种不同的声音中,通过对城市声音和噪音的数据驱动理解,可以改善城市居民生活质量,所以提高环境声音分类的准确性具有十分重要的理论意义及实际应用前景。
虽然在语音、音乐和生物声学等相关领域有大量关于声音分类的研究,但城市环境声音分析工作相对较少。现有的研究也主要侧重于听觉场景类型(例如街道、公园)[1,5-7]的分类,缺少对汽车喇叭、发动机空转或鸟鸣之类的场景中特定声源的识别。同时环境声音(不包括音乐或语音的日常音频数据,其结构通常更混乱和多样化)的分类仍然主要基于应用一般分类器:高斯混合模型、支持向量机、隐马尔可夫模型等手动提取特征,如Mel频率倒谱系数。最近的研究[8-9]详细分析了最常见的方法。而深度神经网络的学习辨别Spectro-temporal模式能力使其非常适用于环境声音分类。最新的神经网络声音分类研究中[10-11]利用卷积神经网络进行城市声音分类达到73.7%~79%的精确度。笔者设计深度神经网络模型(DNN)和卷积神经网络模型(CNN)对公共城市环境声音数据进行网络训练分类,评估连续小卷积核卷积神经网络对短音频的分类能力,并与其他先进声音分类方法的结果进行对比。深度神经网络提取5 类常用音频特征作为输入,分类精读达88.6%优于目前的其他方式,而卷积神经网络不同于Piczak提出的57×6长卷积,而是使用3×3多次连续卷积,达到的分类精度与其他研究基本持平,也证明了连续小卷积核卷积神经网络对短音频分类具有一定的潜力。
1 深度神经网络理论研究
人工神经网络也被称为层感知机是只含1 层隐藏层的节点的浅层模型,而深度神经网络是通过构建具有多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性(图1)。突出了特征学习的重要性,也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。目前神经网络的应用十分广泛[12-14],根据应用情况不同,深度神经网络的形态和大小也各异,卷积神经网络(CNN)也是深度神经网络的一种流行变种。
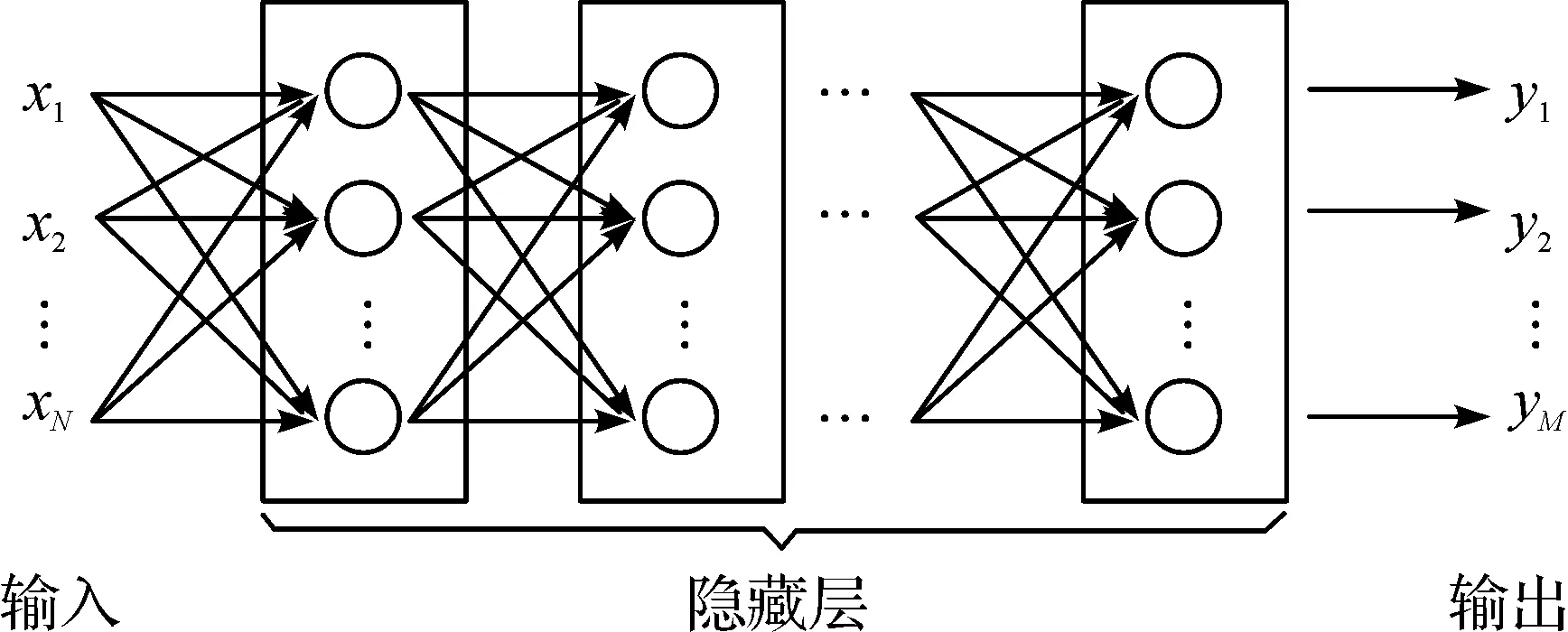
图1 深度神经网络的网络结构Fig.1 Network structure of deep neural network
典型的卷积神经网络是由多个不同层堆叠在一起的深层结构:输入层、一组卷积、池化层(可以不同方式组合)、一定数量全连接隐藏层、输出层。
卷积层引入组织隐藏单元的特殊方式来利用二维输入数据中存在的局部结构。每个隐藏单元不是连接来自上一层的所有输入而是仅处理整个输入空间的一小部分,该区域为其感受野。利用创建的卷积核以一定步长平铺整个输入空间产生一个特征图。
通常图像处理中应用二维卷积运算。二维卷积运算可被如下定义:给定一个图像Xij(1≤i≤M,1≤j≤N),和滤波器fij(1≤i≤m,1≤k≤n),则卷积运算为

(1)
假设第l层的输出特征映射为Xl∈i(wl×hl),第l-1层的输出特征映射为xl-1∈i(wl-1×hl-1),则卷积运算过程为
Xl∈f(wl⊗Xl-1+bl)
(2)
式中:wl为第l层的卷积核;b为偏置矩阵;⊗为卷积运算;f为该层的激活函数。
为了卷积层有更好的泛化能力,通常会在卷积层之后加上池化层(Pooling)用来降低了各个特征图的维度,并保持大部分重要的信息。若l层产生了k个特征映射X(l,k),l+1层为池化层,则产生的k个特征映射为
X(l+1,k)=f(down(Xl)+bl+1)
(3)
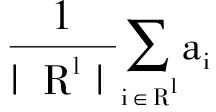
2 基于神经网络的声音分类模型
本实验使用的是keras高层神经网络库,Google开源框架tensorflow作为后端,涉及包括特征提取、基于神经网络的数据处理与训练以及softmax分类器进行分类等过程。
2.1 数据来源及数据结构
监督学习训练深层神经网络的主要问题之一是需要有正确标记的数据来进行有效的学习。由于手动注释成本很高,目前公开的环境数据集无论是在数量还是数据大小上都非常有限。笔者使用目前可用于研究的标签城市声音事件的最大数据集UrbanSound8K[15]。UrbanSound8K是各种城市声源(空调声、汽车鸣笛、儿童玩耍声、狗叫声、钻孔声、发动机空转声、枪声、警笛声和街头音乐等)共8 732 份短音频(每段少于4 s),10 类声音被分为10 份文件,如表1所示。

表1 城市环境声音数据Table 1 The sound data of urban environment
2.2 数据处理及特征提取
Matplotlib将10 类声音进行可视化处理:绘制波形图(Wave plot),如图2(a)所示;用短时傅里叶变换绘制信号频谱图(Septrogramt),如图2(b) 所示;绘制对数功率频谱图(Log power septogram),如图2(c) 所示。可以看出不同声音之间的明显差异。

图2 声音可视化图谱Fig.2 Sound visualization map
声音分类问题中,提取合适的特征是决定分类效果的关键。有许多特征可用于表征声音信号。常用的有Mel频率倒数参数(MFCC)、线性预测倒谱系数(LPCC)、短时能量、基频和带宽等。在DNN中选择提取以下5 类特征:1) melspectrogram,计算Mel缩放功率谱图;2) mfcc,Mel频率倒谱系数,能够充分表征人耳的非线性感知特性;3) chorma-stft,从波形或功率谱图计算色标;4) spectrum_contrast,使用文献[16]中定义的方法计算光谱对比度;5) tonnetz,按照文献[17]的方法计算色调质心特征。提取特征和使用模型架构如图3所示。

图3 数据处理架构Fig.3 The structure of data processing
在CNN中,通过对环境声音分帧、傅里叶变换、Mel滤波器组滤波以及log尺度变换等步骤生成Mel能量谱。Mel能量谱片段采样,生成Mel能量谱片段集作为CNN模型的输入。如图4所示,对产生的能量谱PMel(t,f)采用滑动窗口进行分片采样,图4中窗口的宽度为96 像素,滑动距离256 像素。

图4 分片采样过程Fig.4 Fragment sampling process
2.3 深度神经网络声音分类模型
环境音频数据如2.2节所述进行声音信息特征提取后,作为神经网络的输入层,其后经过2 层全连接的隐藏层,第1 层隐藏层神经元数为280,使用tanh激活函数,第2 个隐藏层300 个神经元,使用sigmoid激活函数,最后输入到softmax分类器中进行分类。笔者使用的学习率为0.01,训练20 000 次,得到的误差曲线如图5所示。其分类精度将在下节中具体与其他实验结果对比分析。
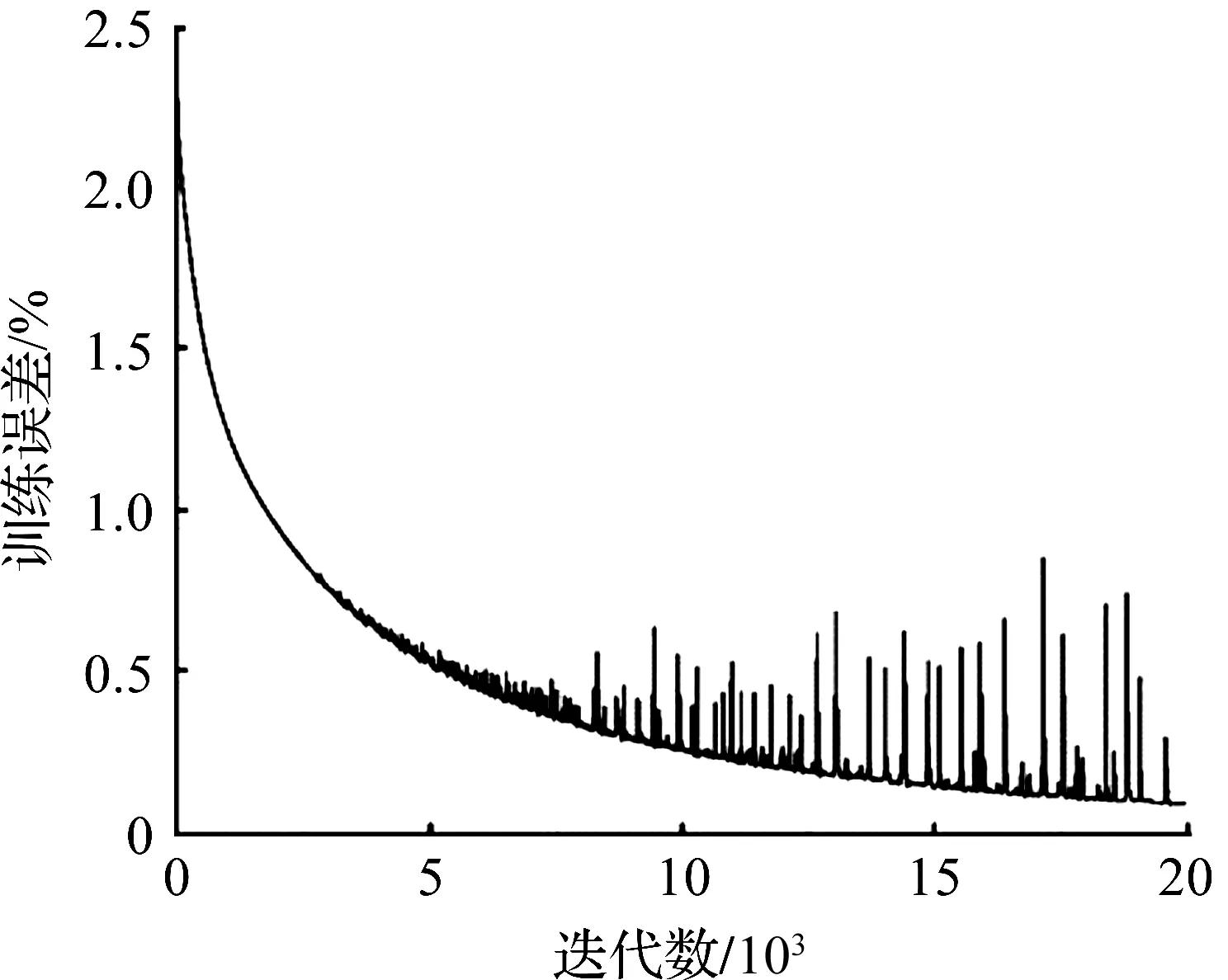
图5 DNN训练误差曲线Fig.5 Training error curve of DNN
CNN结构如图6所示,由5 层卷积层conv、4 层最大池化层max-pooling、全连接层和输出层等构成。输入的采样Mel能量谱大小为96×188,所有卷积层的卷积核个数均为32,均用3×3大小的卷积核进行卷积,卷积滑动步长为3。池化层池窗大小分别为2×4,3×3,2×2。全连接层的神经元个数为32,输出层神经元个数为10(分类数)。各层激活函数采用ELU(Exponential linear unit)[18]函数。在CNN结构中激活函数后对激活值进行标准化(Batch normalize,BN)[19]。为了让CNN不易过拟合,在各卷积层之后采用0.2概率的Dropout训练策略,即在训练中随机让该层一定比例的神经元保留权重而不作输出。在第5 层卷积层之后使用的是2×2平均池化,之后用flatten将多维输入一维化,作为从卷积层到全连接层的过渡。
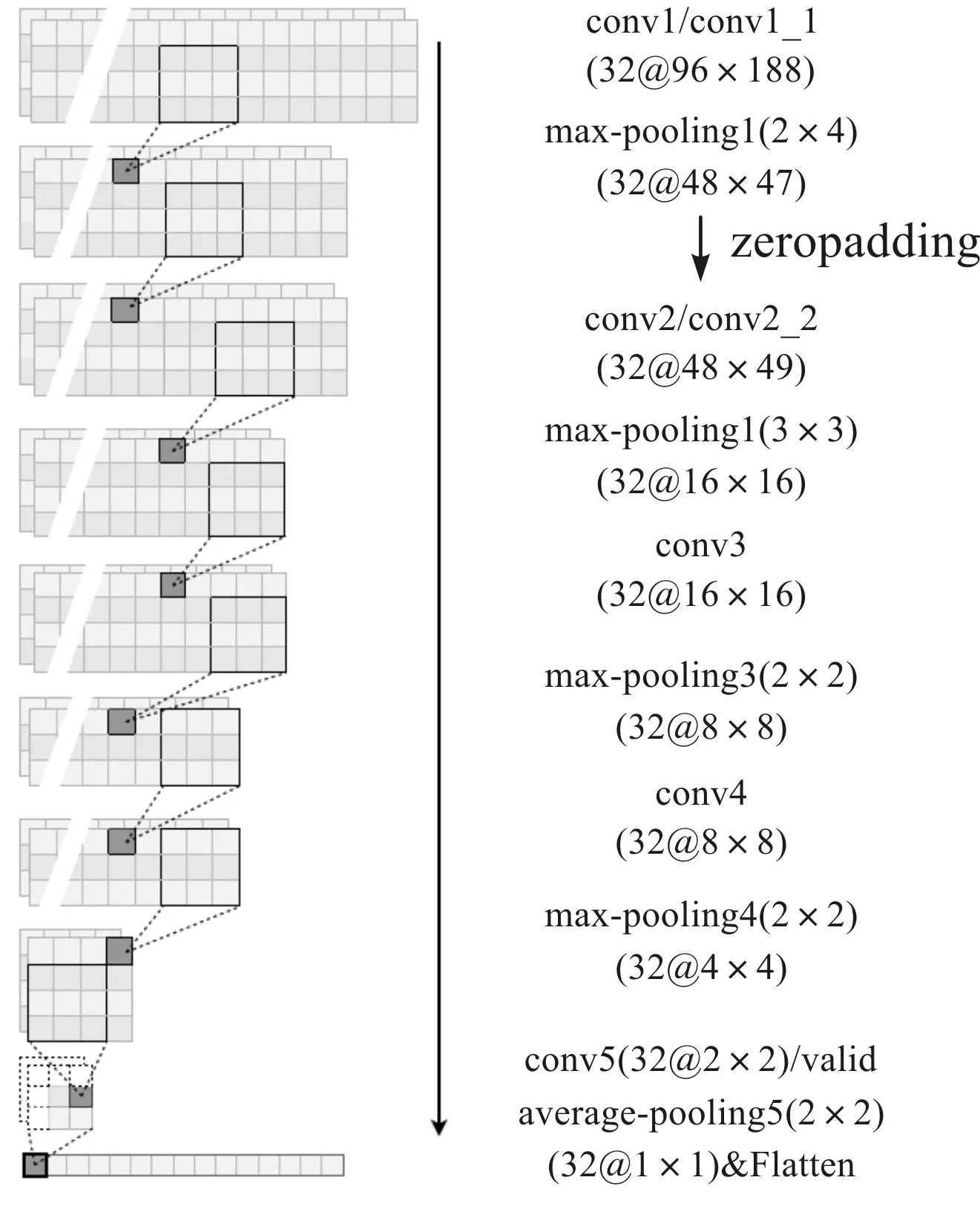
图6 笔者使用的CNN结构Fig.6 CNN model architecture for the article
3 实验结果与分析
如图7所示,实验结果中横纵坐标缩写代表的分类为:air conditioner(AI),car horn(CA),childern playing(CH),dog bark(DO),drilling(DR),engine idling(EN),gun shot(GU),jackhammer(JA),siren(SI),street music(ST)。
在DNN中,本实验随机将70%的音频数据作为训练集,将30%的音频数据作为测试集,可得到图7(a)所示的混淆矩阵,CNN实验以前8 个fold共7 079 份音频作为训练集,以第9 个fold共816 份音频数据作为验证集,第10 个fold作为测试集,得到的实验结果混淆矩阵如图7(b)所示。由于数据集中不同音频数据量不完全相同,所以在混淆矩阵中颜色深浅不能最直观体现分类精确度,但从图7(a,b)均可看出:在分类中容易将ST街头音乐和DO犬吠错分为CH孩童玩耍的声音。在卷积神经网络中还有一定数量的EN发动机转动声音错分为空调、电钻的声音,而这些声音在日常生活中也比较容易被混淆。
表2前2 列分别为使用的神经网络分类模型,而后3 列列举了当前使用同一数据集的其他分类模型,其中SKM为使用球面k均值聚类算法进行分类的模型,Piczak-CNN为使用57×6超长条形卷积核进行卷积的神经网络分类模型,SB-CNN为进行了音频数据增强后的3 层卷积加1 层全连接层模型。整体来看,其他所有模型都对gunshot枪击声的分类准确度高,而DNN对枪击声分类低于其他模型,一方面为枪击声较为短促,另一方面在所有音频数据中收集到的枪声数据量也相对最少,对DNN没有优势。但是在精确度的平均水平上DNN明显优于其他模型。CNN分类精度对比可看出:笔者使用连续小卷积核卷积的深层次卷积神经网络模型具有一定的音频分类潜力,在儿童玩耍声上分类准确性要高于其他论文中的CNN模型。

图7 DNN和CNN混淆矩阵Fig.7 Confusion matrix for the proposed DNN and CNN model

声音样本 DNN CNN SKM Piczak-CNN SB-CNN air_conditioner 92.8 60.0 51.3 55.7 48.9 car_horn 75.8 63.6 63.4 78.8 88.3 children_playing 88.1 88.0 76.6 82.0 83.0 dog_bark 80.0 64.0 79.5 84.0 90.4 drilling 91.1 78.0 79.9 66.3 80.2 engine_idling 94.4 57.0 77.2 67.9 79.8 gun_shot 80.2 93.8 91.7 92.5 94.1 jackhammer 92.4 72.9 70.2 62.7 67.3 siren 91.3 53.0 75.7 81.0 85.8 street_music71.084.077.076.084.4平均值 86.9 71.4 73.7 73.1 78.7
4 结 论
针对短音频城市环境声音分类问题,研究并提出了两类神经网络分类模型。分析音频特点提取5 类音频特征作为神经网络的输入,该分类模型分类准确性能够达到88%,高于目前提出的其他卷积神经网络分类模型。而卷积神经网络模型无需提取多类特征,将音频特征通过Mel能量谱图体现,采样图片像素通过多层卷积进行分类,即使在没有音频增强的情况也有良好的分类能力,也证明了经过多次连续小卷积核卷积可进一步提高模型性能。今后可通过音频数据增强来克服数据稀缺问题,探讨数据扩充对深度神经网络架构的影响。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子制作(2017年9期)2017-04-17 03:00:46
重型机械(2016年1期)2016-03-01 03:42:04
人间(2015年8期)2016-01-09 13:12:42
大连工业大学学报(2015年4期)2015-12-11 04:06:52
