
复杂抽样调查设计多值名义资料一水平多重Logistic回归分析
2019-03-16 11:22刘媛媛李长平胡良平
四川精神卫生 2019年6期
刘媛媛,李长平,2*,胡良平
(1.天津医科大学公共卫生学院卫生统计学教研室,天津300070;2.世界中医药学会联合会临床科研统计学专业委员会,北京100029;3.军事科学院研究生院,北京100850*通信作者:李长平,E-mail:1067181059@qq.com)
在调查研究中,常见的结果变量及其取值除了二值资料、多值有序资料之外,还包括如血型“A型、B型、O型、AB型”或疾病分型“A型、B型、C型”这样的资料,称为多值名义资料。此类资料特指因变量或结果变量为多值名义变量,而自变量可以是定性的、定量的或混合型的资料[1]。现在,复杂抽样调查设计在实际调查研究中使用越来越多,对由此获得的复杂抽样数据进行统计分析时,需充分考虑由不同的抽样方法而产生的不同“抽样权重”。本文通过不同分析策略对复杂抽样调查设计多值名义资料进行多重logistic回归分析,并探讨不同策略之间的差异。
1 多值名义资料多重logistic回归模型简介
1.1 简单随机抽样下多值名义资料多重logistic回归模型的构建
对于结果变量为多值名义变量的logistic回归模型,其结果变量的多个取值之间是“无序的”,假设结果变量Y的取值的类别个数为(D+1)个,这时,总是以其中一个取值类别作为对照,将其他类别与对照类别进行比较,共生成D个logistic回归模型,所构建的logistic回归模型也被称为扩展的logistic回归模型或广义logit模型[2]。见式(1)。

其中,α1,…,αD是D个截距参数,β1,…,βD是D个参数组成的向量,βi代表第i类相对于第(D+1)类的回归系数向量,x代表协变量向量。此模型最早由McFadden[3]介绍,并被作为多项logit模型而熟知。
对上式进行转换可得式(2):

因为所有(D+1)类的概率之和必须为1,所以第(D+1)类的概率为式(3)[4]:
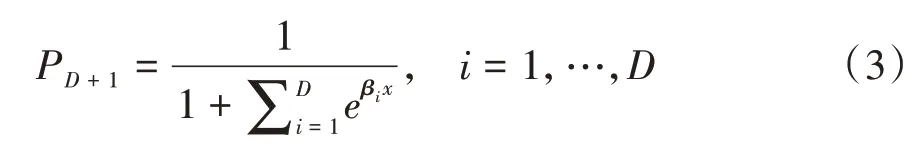
1.2 复杂抽样下多值名义资料多重logistic回归模型的构建
对于复杂抽样下多值名义资料多重logistic回归模型来说,建模时通过使用伪对数似然函数来估计模型参数。当结果变量为多值名义资料时,构建广义logit模型将使用logit连接函数拟合每个响应类别的预期比例与参考类别的预期比例的比值[2]。此时,广义logit模型即为式(4):

其中,d=1,2,…,D。模型参数向量为βd=(βd1,βd2,…,βdk)'。πhij为结果变量的期望向量。xhij为第h层第i个群集第j个单位解释变量的k维行向量。
利用伪对数似然函数对模型参数进行估计,求解最大似然估计值。见式(5):

在式(5)中,Dhij为连接函数关于θ的偏导数矩阵,θ为回归系数的列向量,θ=(β'1,β'2,…,β'D)',ωhij为抽样权重,yhij为变量Y的前D个类别的指示变量组成的一个D维的列向量[5]。
2 基于SAS的实例分析
2.1 问题与数据
本研究所使用数据为美国卫生与公众服务部开展的医疗支出面板调查(Medical Expenditure Panel Survey,MEPS)的数据,对医疗保健的各个方面进行评估[2]。该研究采用分层整群抽样,抽样权重根据无响应情况和当前人口调查的人口控制总量进行调整。在本例中,利用1999年全年数据来研究医保覆盖情况与人口学变量之间的关系。数据存储于SAS数据集MEPS,样本量为24 618,变量为8个,具体变量名及赋值见表1。

表1 数据集中变量名及赋值或单位
2.2 分析策略
2.2.1 按单纯随机抽样进行分析
既不考虑抽样设计,也不考虑抽样权重:将复杂调查设计资料视为“单纯随机抽样设计资料”。
2.2.1.1 SAS程序
基于表1及其具体数据创建临时SAS数据集MEPS所对应的SAS数据步程序从略。调用LOGISTIC过程来实现单纯随机抽样设计资料的广义logit模型。


【说明】class语句指定分类变量sex、race、income;model语句中响应变量为Y=insurance,以insurance=3为参考类别,解释变量(即自变量)为sex、race、income和expenditure。在MODEL语句中指定了LINK=GLOGIT选项,即指定拟合广义logit回归模型,即扩展的多重logistic回归模型。
2.2.1.2 主要输出结果及解释
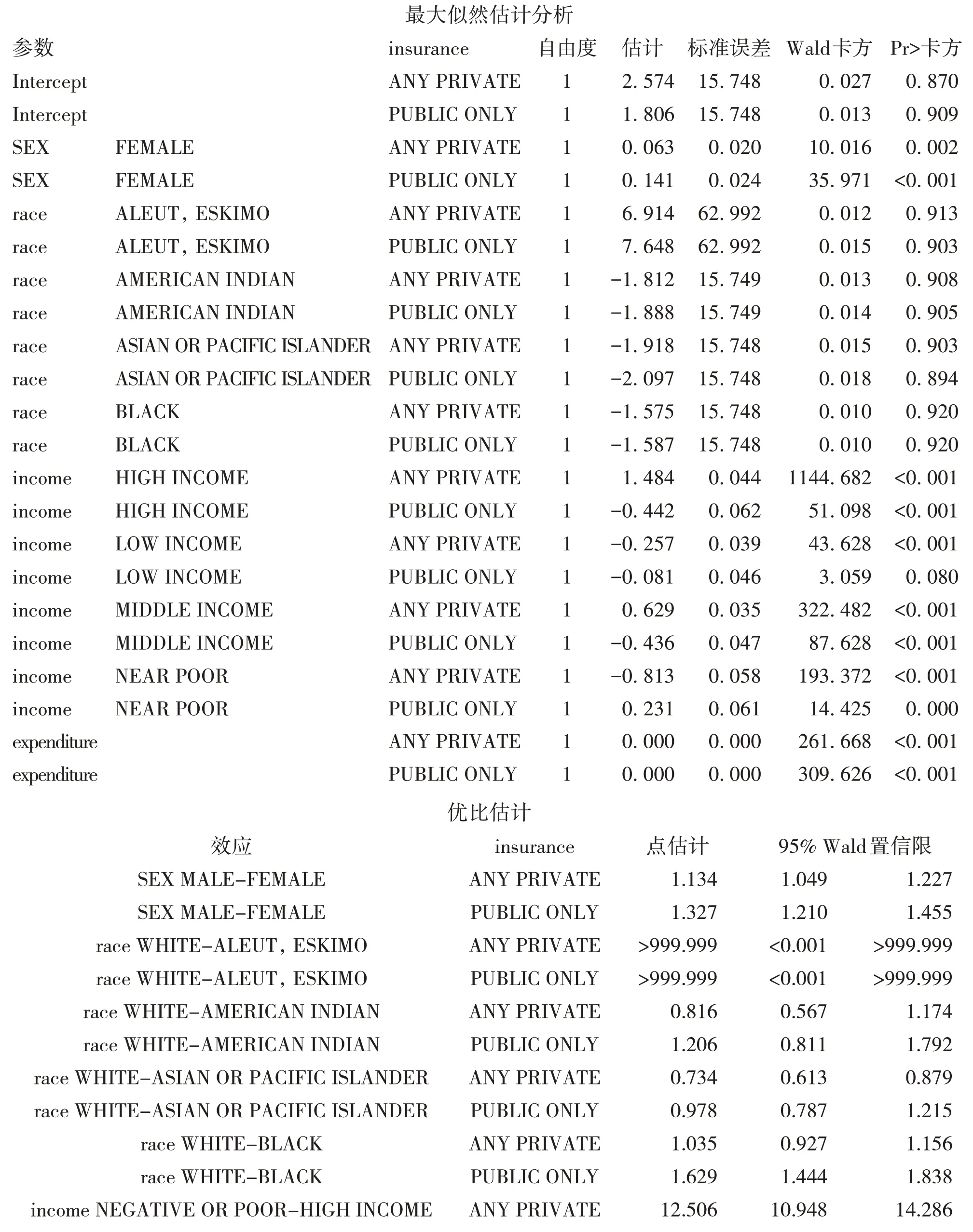

这里仅列出部分广义logit回归模型分析结果。其中模型参数的假设检验分别使用似然比检验、评分检验和Wald检验三种方法,结果显示回归模型有统计学意义。最大似然估计结果显示,性别、家庭收入水平和全年卫生保健总支出对健康保险覆盖情况的影响均有统计学意义;优势比估计结果显示,相对于全年没有保险者而言,女性、家庭收入水平非贫穷者、全年卫生保健总支出高者倾向于全年有私人保险;男性、家庭收入水平非贫穷者、全年卫生保健总支出高者倾向于全年只有公共保险。
2.2.2 考虑抽样设计,但不考虑抽样权重
2.2.2.1 SAS程序
调用SURVEYLOGISTIC过程来实现复杂抽样调查设计多值名义资料的广义logit回归模型。

【说明】STRATA语句用于指定在分层抽样设计中的分层变量,CLUSTER语句指定整群抽样设计中的群变量。其他解释同上。
2.2.2.2 主要输出结果及解释
SAS输出结果很多,由于篇幅限制,此部分结果从略。由输出结果得知:性别、人种、家庭收入水平和全年卫生保健总支出对健康保险覆盖情况的影响均有统计学意义。
2.2.3 不考虑抽样设计,但考虑抽样权重
2.2.3.1 SAS程序
调用SURVEYLOGISTIC过程来实现复杂抽样调查设计多值名义资料的广义logit回归模型。

【说明】WEIGHT语句指定权重变量,其他解释同上。
2.2.3.2主要输出结果及解释
由于篇幅限制,SAS输出结果从略。由输出结果得知:性别、人种、家庭收入水平和全年卫生保健总支出对健康保险覆盖情况的影响均有统计学意义。
2.2.4 同时考虑抽样设计和抽样权重
2.2.4.1 SAS程序
调用SURVEYLOGISTIC过程来实现复杂抽样调查设计多值名义资料的广义logit模型。
【说明】分别用STRATA语句、CLUSTER语句、WEIGHT语句指定复杂抽样中的分层变量、群变量、权重变量,CLASS语句指定分类变量;MODEL语句中结果变量为insurance,以insurance=3为参考类别,解释变量为sex、race、income和expenditure。在MODEL语句中指定LINK=GLOGIT选项,即指定拟合广义logit回归模型。
2.2.4.2 主要输出结果及解释
由于篇幅限制,SAS输出结果从略。由输出结果得知:性别、人种、家庭收入水平和全年卫生保健总支出对健康保险覆盖情况的影响均有统计学意义。相对于全年没有保险者而言,女性、爱斯基摩人(相对于白人)、家庭收入水平非贫穷者、全年卫生保健总支出高者倾向于全年有私人保险,而男性、人种为美国印第安人或亚洲或太平洋岛民或黑人(相对于白人)者、全年卫生保健总支出低者倾向于无保险;女性、人种非白人、家庭收入水平贫穷者、全年卫生保健总支出高者倾向于全年只有公共保险。
2.3 不同分析策略的结果比较
不考虑复杂抽样的普通广义logit回归模型与仅考虑抽样设计的广义logit回归模型所得回归系数及OR值的参数估计值相同,仅回归系数的标准误及OR值的95%CI不同,而其变化有的增大有的减小。说明是否考虑抽样方法对广义logit回归模型参数估计存在影响。
考虑抽样权重与同时考虑抽样设计和抽样权重之后构建的广义logit回归模型所得回归系数及OR值的参数估计值相同,却与前两种分析策略结果不同。而且这两种分析策略得到的回归系数标准误及OR值的95%CI也有增大或减小的区别。race变量在不考虑抽样权重时,对健康保险覆盖情况无影响;但在考虑抽样权重后,race变量的不同情况对健康保险覆盖情况的影响有统计学意义。说明在对复杂抽样调查设计多值名义资料构建广义logit回归模型时,首先应考虑研究采用的抽样方法,由此计算相应的抽样权重,否则可能产生较大偏差[5]。
3 讨论与小结
抽样调查是调查研究中相对简单易行且代表性较好的方法之一,但单一的抽样方法在实际应用中存在一些缺点,所以复杂抽样的思想和方法应运而生,由复杂抽样方法获得的样本称为复杂样本[6]。由于复杂随机抽样每个阶段的抽样方法可能不同,所以其抽样误差的计算相当复杂。因此,在对复杂样本进行统计分析时,既要充分考虑多种抽样方法联合使用对抽样误差的影响,又要注意不同抽样率下抽样权重的不同,否则会使参数及其置信区间等的估计产生偏差。
为了探讨在复杂抽样或单纯随机抽样基础上进行统计分析的差异,本研究分别采用SAS软件中的LOGISTIC过程和SURVEYLOGISTIC过程,按照是否考虑抽样设计与是否考虑抽样权重共4种分析策略对数据进行统计分析。由于LOGISTIC过程可采用逐步回归法对自变量进行筛选,而SURVEYLOGISTIC过程不支持,所以本研究并未使用该选项。结果显示,如果在统计分析中忽视“复杂抽样”或“抽样权重”,不仅会对参数估计值、回归系数标准误、OR值及其置信区间的估计产生影响[6],而且对纳入广义logit回归模型的解释变量也有影响。由于复杂抽样中的抽样权重包含进行参数点估计时所需的信息,但不包含标准误估计的信息,因此,在SURVEYLOGISTIC过程中需对方差进行估计。正确的方差估计包括每一个抽样阶段的方差估计和联合抽样概率[7]。SAS中可采用Taylor级数线性近似法(线性化)、重抽样等方法,如不进行设置,则默认前者方法,这也是该过程与LOGISTIC过程的主要区别。因此,在实际研究中,利用样本数据对总体进行统计推断时,必须对样本的设计类型加以考虑,不然即使样本量足够大,也会导致错误的推断结论[7]。
本文通过实例研究,按照不同的分析策略分别对结果变量为多值名义变量的分层整群抽样数据构建广义logit回归模型,通过对结果的解释和比较,发现在对复杂抽样调查设计多值名义资料进行多重logistic回归分析时,既要考虑抽样设计,又要兼顾抽样权重,以得到更准确的分析结果。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
小作家报·教研博览(2022年18期)2022-05-22
中国典型病例大全(2022年7期)2022-04-22
甘肃教育(2020年4期)2020-09-11
中国中医急症(2019年10期)2019-05-21
湖北教育·综合资讯(2018年7期)2018-10-18
好日子(2018年9期)2018-10-12
人大建设(2018年6期)2018-08-16
汉字汉语研究(2018年1期)2018-05-26
中国工程咨询(2017年10期)2017-01-31
