
南阳城区方言的声调格局
2019-03-15 09:39:52闫克
语文学刊 2019年1期
○ 闫克
(河南理工大学 文法学院,河南 焦作 454000)
一、南阳方言研究现状
南阳地处豫西南,因居河北江南的交界地带而成南北交通要道。在长期的南北交汇之后逐渐显现出以北方方言为主、杂糅南方方言的过渡性特征。在《中国语言地图集》(第2版)中,南阳大部分地区属中原官话南鲁片,唯有桐柏县属中原官话信蚌片。[1]56-57
学界关于南阳方言的研究,涉及语音、词汇、语法等各个方面,其中比较具有代表性的经典成果,是前辈学人关于南阳方言内部差异性的认识。徐奕昌的《南阳方言概要》一文,最早指出了南阳方言的内部差异,并根据南阳各地方言在语音、词汇和语法上的区别,提出了分南阳方言为 “东部—中部—西部”三个分区的主张,遂成为南阳方言研究的基本共识。[2]4-18其中,中部区以南阳市为中心,囊括周边众多区县,地域面积最大,因而历来最受关注,其相关研究成果也最为丰硕。
梳理关于南阳方言中部区语音特点的研究文献我们发现,不同学者在该区方言声调的认识方面存在一个不容忽视的问题,即:关于调类的认识比较一致,而在调值方面意见不一。比较有代表性的主张有徐奕昌[2]4-18、张启焕等[3]52-55、徐奕昌等[4]42-43、《南阳地区志》[5]485-486、王晓红[6]65-67、丁全等[7]66-67、贺巍[8]136-140、姚炎嫣[9]68-71、仵兆琪[10]8-9九种,今以表格形式陈列如下:
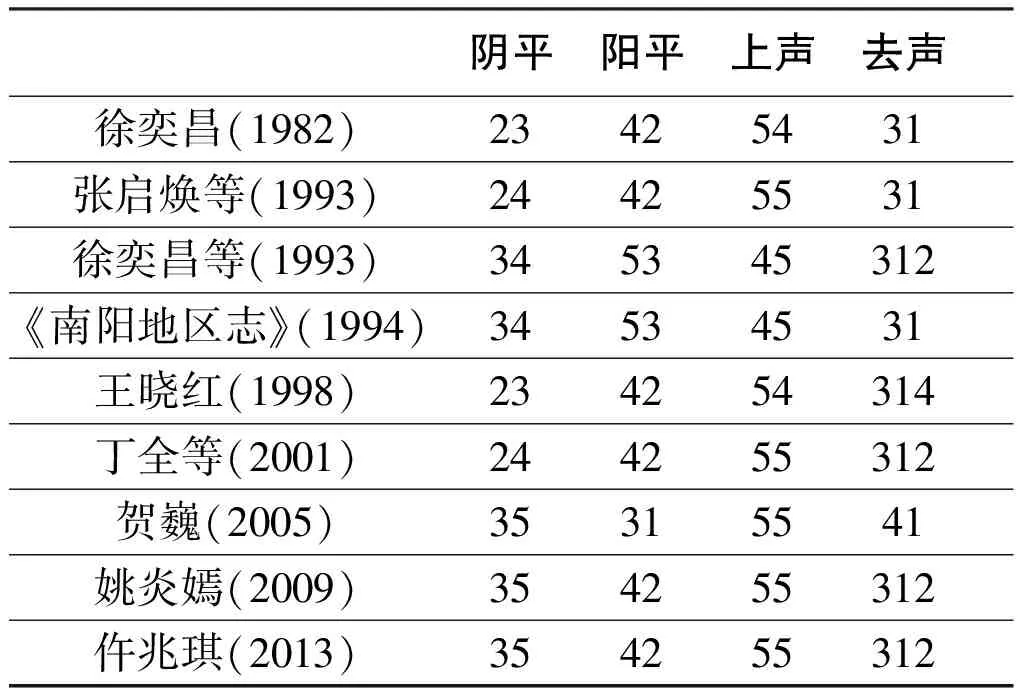
表1 南阳方言中部区的调类与调值
上述分歧状况的出现,存在深层次的原因。从客观条件来说,“早期汉语声调的研究,由于缺乏对调值的定量手段,只能作描写性的说明,自然无法进行精确的研究”,因而同类研究之间的种种大小差异就在所难免;就主观认识而言,在不少研究者看来,“调值不过是调类的一个记号,只讲区别,不求准确”,这就使得五度标调法在使用中出现了一定的主观性。[11]1-14为了解决这一分歧,以推动南阳方言语音研究更趋完善,我们拟尝试采用实验语音学的手段来探究以城区方言为代表的南阳方言中部区的调值格局。
二、实验设计
(一)理论依据
石锋先生认为,“声调格局就是声调的规格和布局。规格是指声调的高低升降等,布局是调型曲线在调域空间中的分布关系”;而一种语言或方言的声调格局,则是由它里面全部单字调所构成。为了实现同一框架下的有效对比,石锋先生在研究中提出了进行数据标准化处理的T值法,用以对声调进行静态描写,其计算公式为:
在公式中,a值为调域频率的上限,b值为调域频率的下限,x取值为测量点的频率;计算所得的T值即是测量点的五度值参考标度。这种归一化计算处理的优势在于,它能够确保不同个体的发音之间、同一个体的前后发音之间,能够实现有效对比。[12]189-194
(二)实验手段
1.语音实验字表。根据明茂修的介绍,“学界普遍认为声调负载段应该是在韵母段, 而且是在韵母段中的主要元音上”,而实验例字在韵母为单元音、声母为不送气清塞音的情况下,声调负载段的确定最为明确。[13]37-40结合南阳方言中部区的音系特征,我们将实验所需的调查例字确定如下(详见表2)。其中,每一调类十个例字,均为单元音韵母(a/o/e/i/u),声母以不送气清塞音(b/d/g)为主,少量是送气清塞音(p/t/k)。

表2 南阳方言中部区声调实验字表
2.语音实验软件。实验所用的语音分析工具是由荷兰阿姆斯特丹大学的保罗·博尔斯马和大卫·威宁克共同研制的Praat5.2.7;并经贝先明、向柠汉化修改。该修改版Praat语音分析软件可以对语音实验样本的基频数据便捷地进行测量和提取,为我们观测实验例字的音高信息提供了极大便利。统计运算工具为SPSS22.0,它可以帮助我们完成均值计算、T值计算和声调曲线制图等操作。
3.语音采集对象。根据语音实验对发音人数量和年龄的基本要求,本次语音实验的发音人确定为六人,均为南阳市宛城区黄台岗镇人。其中,老派方言组三人:闫海波,男,65岁;闫海宽,男,60岁;袁志林,女,58岁。他们都是小学学历,未曾长期离开乡土,不会说普通话,方言色彩相对纯正,是老派南阳话的代表。新派方言组三人:闫冲,男,40岁;闫炀,男,39岁;王吉铮,女,35岁。他们三人都是高中学历,有短暂外出打工的经历,普通话使用水平极为有限,是新派南阳话的代表。以上六人都是实验操作者的亲属,语音采样可以在比较自然的状态下完成。
4.实验过程。实验的第一步是采集语音样本,所用工具为索尼ICD-UX560F数码录音棒;在介绍实验目的之后,让实验发音人逐行读出实验字表中的例字,每位发音人每一调类的例字读音保存为一个独立的MP3音频文件,文件数量共计24个,总计包含240个单字声调。实验的第二步是使用汉化版Praat
5.2.7打开每个音频文件进行编辑,使用“基频”下拉菜单中的测量工具进行音高数据的测量和提取(系统默认在载调段提取九个测量点的基频数据)。对于语图中声调载调段的择取,我们根据石锋先生“声调的表现主要在韵母上面”[14]这一认识,借鉴张云云、李景红的实验操作方法,排除语图中弯头段和降尾段的干扰,将韵母的起点视为声调的起点,将韵母的终点视为声调的终点。[15]90-93实验的第三步是将提取到的所有实验例字九个测量点的基频数据导入SPSS22.0数据表格,计算出每一调类中每个测量点基频数据的平均数,找出四个调类中36个基频均值的最大值和最小值,然后代入T值计算公式求得每一测量点的T值,再根据T值跟五度标调的对应关系来进行转换描写。T值与声调五度区间的对应关系如表3所示[15]:

表3 T值与五度区间对照表
三、声调格局分析
通过对实验例字各测量点基频数据的提取和均值计算,我们运用T值计算公式,得出每一调类各测量点的T值,如表4所示:
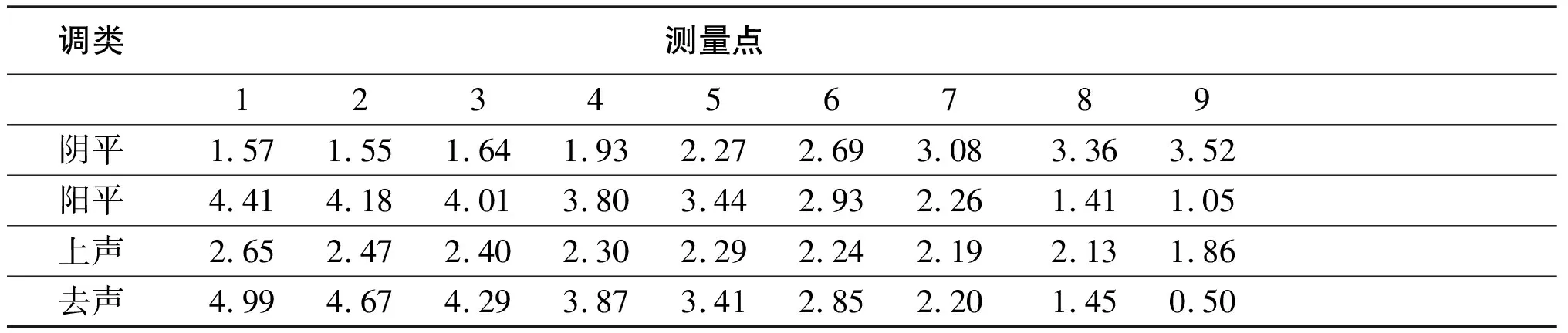
表4 每一调类各测量点T值一览表
根据表4数据,我们可以做出南阳城区方言单字调的音高曲线图;其中,横坐标是经过归一化运算后的韵母载调段发音时长,1~9是等距抽取的九个基频测量点,纵坐标是测量点所对应的T值(取值范围是0~5),对应着标记声调曲线的五度区间。详情如图1所示:
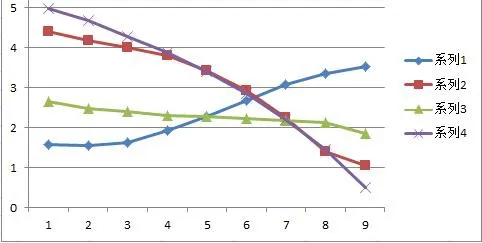
图1 南阳城区方言声调格局一览图
从图1我们可以看出,南阳城区方言各类单字调大体上呈现出以下分布特征:
1.阴平调是个中升调,音高曲线前段三个测量点(1.57,1.55,1.64)均处于第二区间中线附近,后端两个测量点(3.36,3.52)分别在第四区间中线上下,所以阴平调值可以记为24。
2.阳平调是个中降调,音高曲线前段三个测量点(4.41,4.18,4.01)均处于第五区间中线以下,比较接近四度和五度区间临界线,后端两个测量点(1.41,1.05)都处于第二区间中线以下,所以阳平调值可以记为42。
3.上声调是个中平调,音高曲线前八个测量点均处于第三区间内,最后一个测量点虽然略有下降,但仍接近第二和第三区间临界线,所以上声调值可以记为33。
4.去声是个高降调,音高曲线前两个测量点(4.99,4.67)居于第五区间内,且均在区间中线以上,末端测量点(0.50)虽然处于第一区间中线上,但从听感上来讲整个下降幅度并不像普通话的去声那样长,所以去声调值可以记为52。
根据上文实验分析结果,南阳城区方言的单字调依次是阴平(24)、阳平(42)、上声(33)、去声(52)。这一结果跟表1所列文献对照来看,阴平的实验结果24跟既往传统记音的23、34比较接近,一致反映出阴平乃是中升调的实质;阳平的实验结果42跟既往多数传统记音结果一致,跟53这一记音比较接近,均可以体现出阳平调起点偏高这一特征;上声的实验结果33跟既往传统记音结果55、54、45都存在距离,其显著区别是语音高度偏低;去声的实验结果52跟既往的传统记音31和312两类主张相比均有不同,一是起点音高偏高,基本上达到了调域区间的上限,二是调型曲线整体走向是下降,后段并无曲折上扬特征。综合来看,本次实验分析既验证了传统研究结论的可取之处,同时也发现了传统研究跟实验分析之间的较大出入。由于本次实验取样难免具有一定局限性,故而南阳城区方言的声调格局需要进一步认定,多调查点的大样本实验分析将会是一个重要选择。
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
航空学报(2022年5期)2022-07-04 02:24:32
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
山东交通科技(2020年2期)2020-08-13 09:24:06
模具制造(2019年10期)2020-01-06 09:13:08
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
自动化与仪表(2019年2期)2019-03-06 08:24:26
