
来华留学生课程作文用词表现的阶段性考察
2019-03-15 09:39:56张丁月唐兴全
语文学刊 2019年1期
○ 张丁月 唐兴全
(1.北京语言大学 人文社会科学学部,北京 100083;2.对外经济贸易大学 中文学院,北京 100029)
近年来,计量语言学的发展推动了大量词语领域的研究。随着计算机技术的普及,各类统计方法与语言学现象的结合使定量分析方法走进语言学研究领域,弥补了定性分析的不足。目前对汉语教学领域的词汇计量研究较多集中在教材词汇分析、学习词表的编制和词汇产出统计等方面,涉及汉语作为第二语言学习者作文用词的研究也主要考察学习者的词汇偏误及原因。黄立、钱旭菁、吴继峰等对二语学习者汉语写作中的词汇丰富性的发展进行了研究[1][2];肖潇、陈默、任扬等考察了二语学习者汉语口语中的词汇丰富性发展情况。[3][4][5]但学界通过计量手段,对来华留学生在整个一学期内课程作文整体用词表现与学习时长的关系进行的分阶段考察研究较少。
因此,本文希望通过定量分析,从用词丰富性、准确性两个角度考察来华留学生一学期内在《汉语写作》课程作文作业中的用词表现,揭示学习时长与来华留学生作文用词的内在规律,建立相关模型,为教师合理把握来华留学生写作水平提供具体数据参考,并为教师开展汉语写作课程教学提供相关建议。
一、概念界定
词汇丰富性是学习者词汇质量研究的重要指标。中外学者对它的概念也做出了界定。Nation & Webb 明确定义“词汇丰富性是指文本中词汇知识的质量”,可以测量词汇运用的广度和深度,是衡量口语或书面语整体水平的重要依据。[6]张艳、陈纪梁提出,词汇丰富性就是指语言使用者在自由言语产出中使用词汇的丰富程度。[7]中外研究者对词汇丰富性概念的界定大体一致,在词汇丰富性具体测量维度的划分上虽存在争议,但基本集中在“词汇变化性、词汇复杂性、词汇密度、词汇个别性、词汇错误”等几个维度。本文在词汇丰富性的统计方面,主要依据的是不重复词语(词种)在作文中的比重,即:
词汇丰富性=词种数/词语总数*100%
第二语言表达的准确性根据不同层次可分为词汇准确性、句法准确性和语音准确性。对于准确性的度量,目前国内学界主要参照国外的做法,使用无错T单位百分比和平均T单位长度来进行测量。本文主要关注词汇准确性。由于国内目前对T单位的界定分歧较大,所以本文中主要采用词汇偏误数在作文用词中所占的比重来测量,即:
词汇偏误率=用词偏误数/词语总数*100%
二、研究对象与研究素材
(一)学习者信息
本文的研究对象为某大学经管类专业的一个班共17名来华留学生,学生属性如下:

表1 《汉语写作》课程学习者信息
(二)语料素材
1.语料来源。本研究所用语料全部为上述17名来华留学生本科生在大一下学期《汉语写作》课上的课下作文。该课程开始时间为3月2日,因3月3日和3月7日同属开学第一周,期间学生共写作11篇作文,写作间隔较小。为方便统计,将其合并为一组数据,学习时长记为3天。该学期的作文写作可以分为以下七个学习阶段:
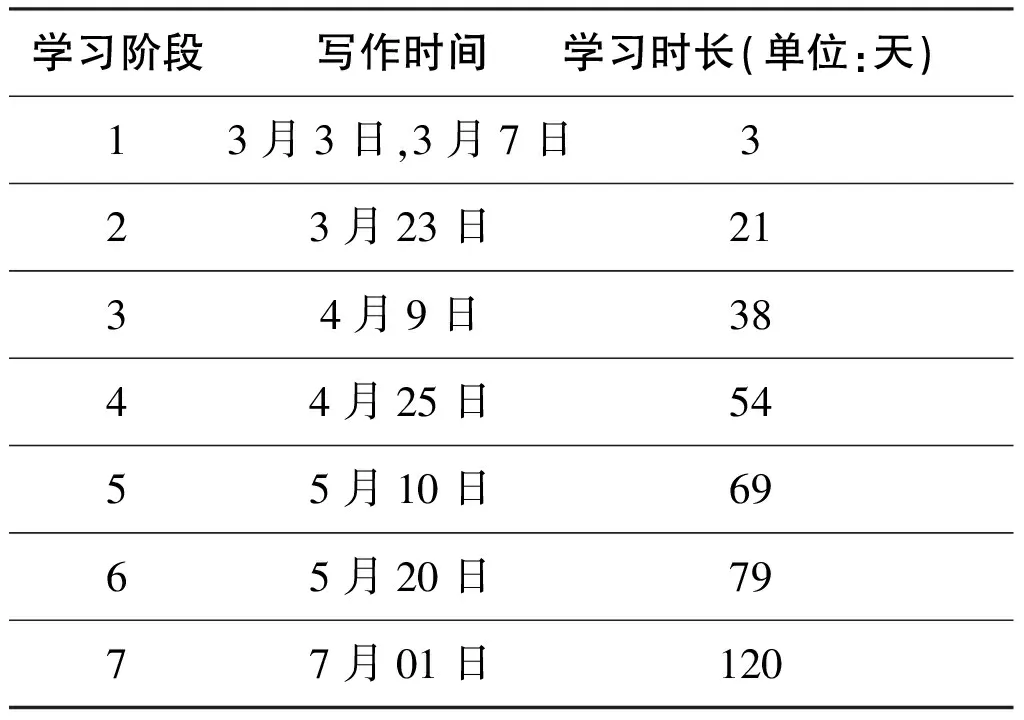
表2 写作课学习阶段与时长
因为每个阶段作文数量不一致,基本上在12-17篇,因此我们为保持一致,每阶段随机抽取10篇作文进行考察。
2.语料标注与处理。我们首先对七个阶段70篇作文进行了格式规范化处理,然后对作文原文进行了词汇偏误标注。本次标注内容主要为词语层面偏误,主要包括:词混淆、缺词、缺词素、词多余、词素多余、词素顺序错误、实词词序错误、虚词词序错误、生造词、拼音词、外文词、离合词错用、词重叠错误等。然后我们用北京理工大学张华平研制的ICTCLAS2015词处理软件对作文语料原文进行分词与词频统计,用统计软件Eviews 8.0构建回归模型。
我们的研究思路如下:
①通过统计、分析作文所用词种(不重复词语)的数量,分析用词丰富性。对比不同阶段用词信息差异、构建相关回归模型,分析学生用词丰富性的变化。
②通过统计、分析作文用词偏误数量、偏误率,分析用词准确性。对比不同阶段用词信息差异、构建相关回归模型,分析学生用词准确性的变化。
三、来华留学生课程作文用词的丰富性分析
(一)学期各阶段作文用词量统计分析
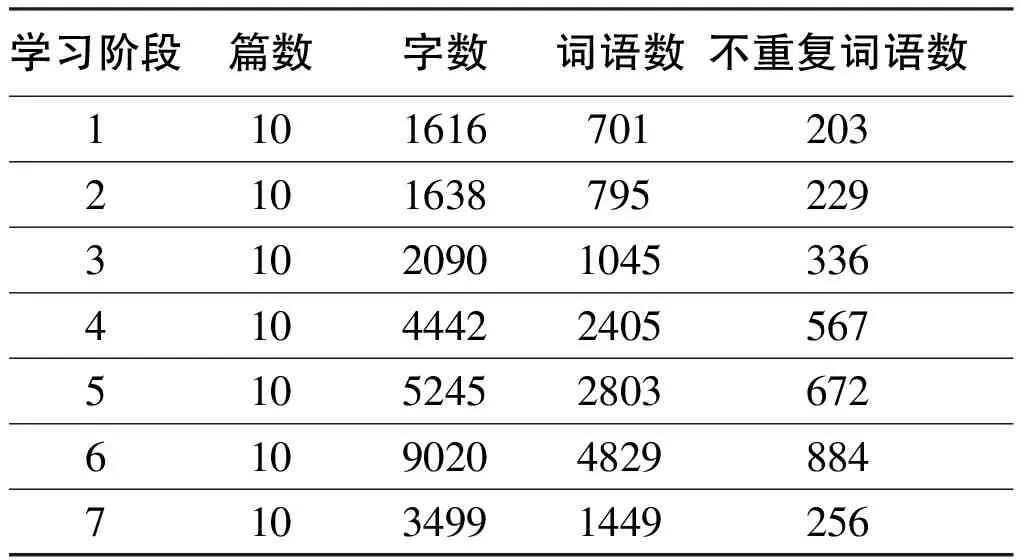
表3 学期各阶段作文用词量统计
因7月1日作文为期末考试作文,与学生其他时段的课下作文相比,写作环境差异过大,因此本文暂不讨论该阶段作文表现。
(二)基于EViews的词种数与学习时长相关性分析
(1)理论分析:在其他条件不变的情况下,随着学习时间的延长,学生的语言水平会有所提高。在作文用词丰富性上,表现为词种数会增多,即学生掌握了更多样复杂的词汇。因此我们假设,词种数与学习天数存在正相关关系。
(2)建立模型:Y=α1+α2X+μ,其中:Y为词种数,X为学习天数,μ随机扰动项。
(3)构建散点图:
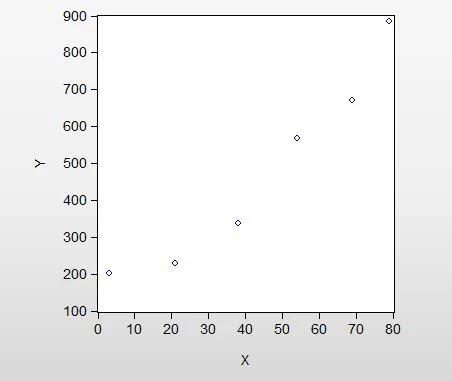
图1 词种数与学习时长相关性散点图
由上图可看出,随X(学习天数)的增加,Y(不重复词语数)增加,二者呈现正相关关系,符合初始假设。
(4)估计参数:利用EViews进行回归分析,结果如下:Y=9.0095X+85.4139,t值=(7.0388)(1.2998),R2=0.92, F=49.5441。
(5)模型检验:
①拟合优度检验:
R2=0.92,说明模型整体上拟合很好,样本回归线能够拟合、解释92%的样本数据。
②变量显著性检验:
给定α=0.05,查t分布表[8],在自由度为n-2=4时临界值为2.7764。其中,X的系数t=7.0388>2.7764,且其p值=0.0021<0.05,X通过显著性检验,表明学习时长对不重复词语数即用词丰富性有显著影响。
同理检验常数项C的t值,发现其p值=0.2635>0.005,且其t值未通过临界值检验,因此常数项C未通过显著性检验。
F检验衡量所有自变量对因变量的影响程度,该模型为一元模型,上述唯一自变量通过显著性检验,即该模型通过F检验。
③实际意义检验:
上述结果表明,学习时长对用词丰富性有显著影响。根据统计结果,当学习时长每增加一天时,学生所掌握的不重复词语数大约增加9个,这反映了该学期学生作文用词丰富性随学习时间而增加。
在变量检验时,模型方程常数项未通过显著性检验,表明常数项不能很好地反映学生在进行学习前已掌握的基础词汇数量。因此我们不能利用该模型预测一定学习天数下的学生具体掌握的词汇数量。这与学生个体基础差异较大、每人起初掌握的词汇数量不同有关。
四、来华留学生课程作文用词的准确性分析
(一)学期各阶段作文用词偏误率统计分析
随着学习时间的增加,课程对学生的学习要求随之提高,因此作文字词数持续增加。而随字词数的增加,学生出现偏误的数量往往也会增加。
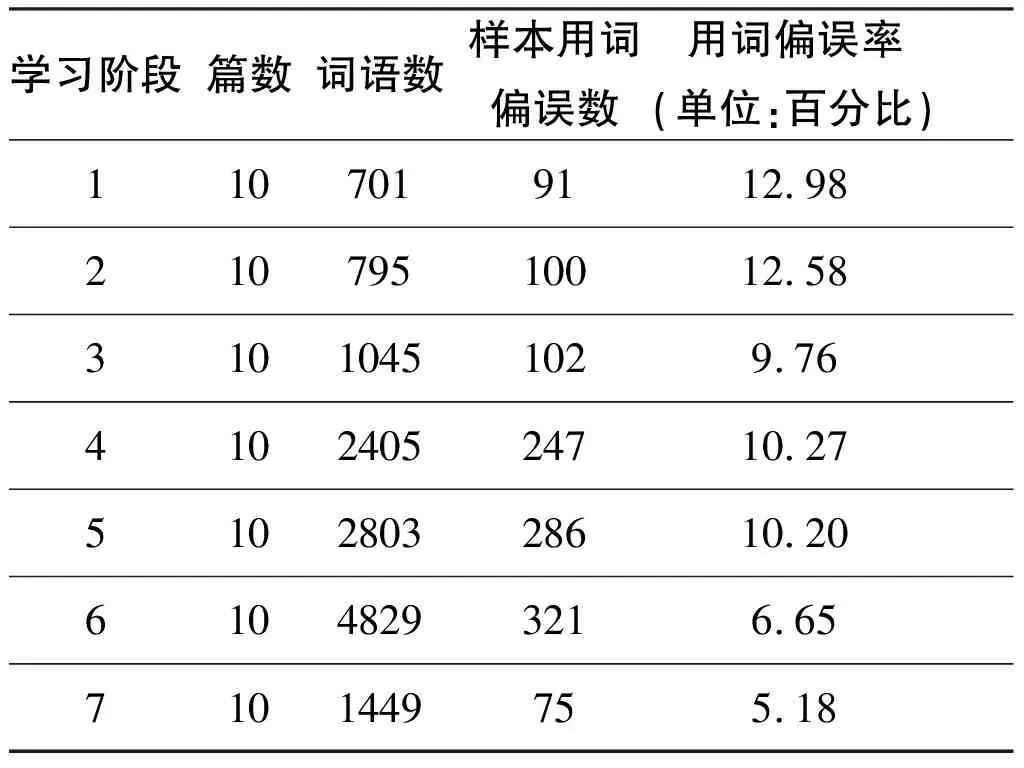
表4 学期各阶段作文用词偏误率统计
这里我们暂不讨论期末考试即第七阶段的作文用词表现。
(二)基于EViews的用词偏误率与学习时长相关性分析
(1)理论分析:在其他条件不变的情况下,随着学习时间的延长,学生的语言水平会有所提高。在作文用词准确性上,偏误率会下降,即用词准确性提高。因此我们假设,用词偏误率与学习天数存在负相关关系。
(2)建立模型:Y=β1+β2X+μ,其中:Y为偏误数,X为学习天数,μ随机扰动项。
(3)构建散点图:

图2 用词偏误率与学习时长相关性散点图
由上图可看出,除个别点外,随学习天数X的增加,用词偏误率Y基本呈现阶段下降的趋势。二者基本呈现负相关关系,符合初始假设。
(4)估计参数:利用EViews进行回归分析,结果如下:Y= -0.0690X + 13.4439,t值=(-3.6674)(13.9139),R2=0.77, F=13.4495。
(5)模型检验:
①拟合优度检验:
R2=0.77,说明模型整体上拟合较好,样本回归线能够拟合、解释77%的样本数据。
②变量显著性检验:
给定α=0.05,查t分布表,在自由度为n-2=4时临界值为2.7764。其中,X的系数
│t│=3.6674>2.7764,且其p值=
0.0214<0.05,X通过显著性检验,表明学习时长对偏误率即用词准确性有显著影响。
同理检验常数项C的t值,C的│t│=13.9139>2.7764,其p值=0.0002<0.05,C通过显著性检验。
F检验衡量所有自变量对因变量的影响程度,该模型为一元模型,上述唯一自变量通过显著性检验,即该模型通过F检验。
③实际意义检验:
上述结果表明,学习时长对用词准确性有较为显著的影响。根据统计结果,当学习时长每增加一天时,学生作文用词偏误率约下降0.069个百分点,这反映了该学期学生作文用词准确性随学习时间而增加。同时,当学习天数为0时,回归结果反映学生初始偏误率为13.4439%。这是学生未开始本学期学习时,自身学习基础的一个反映。此外,我们也可以利用该模型,大致预测一定学习天数下学生作文用词偏误率的数值。
五、研究结论及教学建议
通过统计分析,我们发现,随着学习时长的增加,该班级留学生作文用词表现如下:(一)在用词丰富性方面,当学习时长每增加一天时,学生所掌握的不重复词语数大约增加9个。(二)在用词准确性方面,当学习时长每增加一天时,学生用词偏误率约下降0.069个百分点。在学习天数为0,即本学期开始时,本班级学生作文用词初始偏误率为13.4439%。以上两方面都反映随学生学习时长的增加,该班级学生作文水平有所提高。
此外,除以上两方面,字数、词语数的增加反映了课程对学生写作要求的提高,一定程度也能反映学生写作水平的提高。
因此,汉语写作课教师在实际授课过程中,可以制定合适的写作练习频率,保证留学生得到充分、连续的写作练习。
本次研究中,我们侧重分析习得过程中学习时长对留学生作文用词的影响。整体上只关注了其用词丰富性中的不充分词语数量和准确性中的偏误率,侧重数量上的分析,而没有分析其具体表现,诸如作文中的用词等级、偏误种类等仍需要继续细分、量化研究。
猜你喜欢
中国中西医结合外科杂志(2024年1期)2024-02-25 09:10:46
中华诗词(2022年2期)2022-12-31 05:57:58
新世纪智能(高一语文)(2021年11期)2021-03-08 01:54:44
海外华文教育(2017年8期)2017-11-07 04:42:02
小学生作文(低年级适用)(2017年3期)2017-07-06 12:06:53
海外华文教育(2016年4期)2017-01-20 08:22:28
记者摇篮(2016年11期)2017-01-12 14:00:35
科技传播(2016年17期)2016-10-09 21:28:06
语文教学与研究(2014年7期)2014-02-28 21:54:33
海外华文教育(2012年3期)2012-03-20 14:05:01
