
基于Apriori算法的高校Web日志挖掘系统构建
2019-03-14 05:49
中国林业教育 2019年2期
(北京林业大学信息学院,北京 100083)
伴随信息科技的持续推新,网站在人们获取信息的工作中发挥着更加重要的作用。高校网站兼具信息搜集、服务供应、娱乐生活等诸多功能,属于综合性质的网站。近年来,高校正投入大量资金来完善网站构建工作,以便更好地面向校内和校外提供服务。鉴于网站访问量呈现持续增长趋势,网站为满足高校师生所需导致站点结构日趋复杂,出现高校师生获取相关资源效率下降、浏览兴趣匮乏等问题。针对这一问题,笔者提出将传统Web日志挖掘同关联规则挖掘协同控制,构建基于Apriori算法的高校Web日志挖掘系统。
一、基于Apriori算法的关联规则挖掘
(一)关联规则
关联规则即为发掘到数据深层次的规则关系,最早由Agrawal等人提出,其在Web日志挖掘中发挥着重要作用。目前与关联规则相关的概念包括以下几个。
①项目和项集。设I={i1,i2,…,im},I是m个不同项目的集合,每个ik(k=1,2,…,m)称为一个项目,简称项。I就是项目的集合,即项集。
②事务和事务集。项对应着的集合就是事务,由事务相互联系获得的集合就是事务集D={t1,t2,…,tn},此处的ti∈I。
③关联规则。关联规则是形如X⟹Y的蕴含式,其中X∈I,Y∈I,且X∩Y=Φ。


⑥频繁项集。满足最小支持度的项集是频繁项集,记为Lk。
⑦强关联规则。满足最小支持度且满足最小置信度的规则是强关联规则。关联规则挖掘过程分为2个阶段:一是获取频繁项集;二是由频繁项集产生关联规则。
(二)Apriori算法
Apriori算法是用来发现频繁项集的一种算法。要想获得频繁k项集,必须通过频繁k-1项集迭代得到,以此类推,得到全部项集。Apriori算法主要有2个步骤。
①连接。要得到频繁项集Lk,首先找到候选项集Ck,通过Lk-1×Lk-1连接产生Ck。若假定l1和l2对应表现是Lk-1内存在的项集,则li[j]表征是li内存在的第j项。为方便,假定事务或项集中的项按字典次序排序,使得li[1] ②剪枝。Ck属于Lk的超集,故而全部的频繁k项集均是保存到Ck。借助扫描控制的实现就能获取Ck内全部项集的数目,得到支持度,取得Lk。只是鉴于Ck非常大,需要执行的运算分析任务很重,故而借助Apriori对其实施压缩控制[1]:若是有k-1子集不被Lm-1所包含,就能说明这个项集要从Ck内剔除。 本系统采用B/S体系结构模式,基于轻量级的Java SSM框架搭建。Java SSM框架以其开放、灵活、高效的优势成为大型互联网公司的首选。系统设计分为表现层、控制器层、业务逻辑层、数据持久层4部分,其系统架构见图1。 1.表现层 表现层负责数据呈现,主要是由HTML+CSS+JavaScript实现。用户依托浏览器对系统访问,经过后台业务处理将结果展现给用户。 2.控制器层 控制器层负责针对不同请求调用相应的业务逻辑层的方法做出不同的操作处理,并返回数据到表现层。 3.业务逻辑层 业务逻辑层负责所有的业务逻辑的处理,此层调用数据持久层与数据库交互。 4.数据持久层 数据持久层借助MyBatis框架来实现对数据库的操作。 系统功能分为以下4部分。①用户管理。根据用户权限分为普通用户和管理员。②数据导入。系统支持导入格式为.zip和.rar的压缩文件,压缩文件中的所有含有.log的文件都可以被导入。③数据预处理。该模块能够对原始数据进行数据清洗等预处理操作,并将最初的Web日志信息转变成事务型数据存储到MySQL数据库中。④关联规则挖掘。用户参照自身实际所需由前台输入最小置信度以及支持度参数信息,得到同需求相一致的关联规则内容,并就其展开探讨分析。它为网站管理者展现出有效的用户浏览特征,优化已有页面实现的链接控制,让用户获得更佳的服务感受。系统的功能结构见图2。 根据需求分析和系统设计,系统的部分实体图如下。 图2 高校Web日志挖掘系统的功能结构 图3 原始日志实体图 1.原始日志实体图 原始日志实体图包括id、创建日志时间、客户端ip、客户端名称、服务器端ip、服务器端端口、请求方法、请求url、请示参数、响应码、客户端浏览器。其中,id是主键,见图3。 2.置信度实体图 置信度实体图包括id、前项、后项、支持度数、支持度、置信度数、置信度。其中,id是主键,见图4。 图4 置信度实体图 在数据库表设计时,系统立足于需求实际,遵循数据库命名规则和设计原则,设计了置信度表等10个数据库表,在此笔者列出部分数据库表,见表1和表2。 数据预处理模块任务是将导入的原始日志中与挖掘无关的数据过滤掉,得到满足关联规则挖掘的事务数据集。数据预处理的过程见图5,数据预处理过程包括以下5个阶段。 表1 原始日志表 表2 置信度表 图5 数据预处理过程 1.数据清洗 数据清洗任务是清除无用信息,根据不同业务需求,数据清洗工作也略有不同。结合本系统需求,本文的数据清洗工作主要包括以下几点。①删除无关信息。用户浏览网页时,服务端不仅保留同用户请求相关的信息,而且还携带有不少附属日志内容,如图片以及动画内容等,用户并不关心这些对象记录。因此,需要删除cs_uri_stem字段中jpg、gif、avi、png等无关的记录。②删除Robot请求。像网络爬虫等代理发出的请求[2],也不能反应用户真实浏览意图,因此,这些请求记录也不是后期进行关联分析所要的数据。③删除访问出错的记录。用户浏览网页时有时会遇到访问资源出错,例如出现状态码为302、404等,这些记录对本系统来说没有任何用处。因此,根据用户请求状态码来识别错误,只保留sc_status字段值为200的记录。④删除无关字段。根据需要保留相关字段,删除无关属性字段。 2.用户识别 简单识别一个独立用户的方法就是通过独立IP,但是由于代理服务器、缓存的使用,让用户识别变得复杂。本文采用启发式规则来识别用户[3]:①若是IP相异,则判定用户是不一样的;②若是IP相同,但用户使用的Agent相异,则判定用户是不一样的;③若是IP以及Agent都相同,则需参照站点拓扑关系情况来明确访问页面间呈现出的链接表现,当不存在链接关联的时候,就认定实现分析的用户是新用户。 3.会话识别 用户会话代表一次会话时长内用户就该站点内持续操作的页面序列情况。会话识别常用方法有:序列长度法、最大向前序列法和Timeout法。本文采用Timeout法,Timeout值设置为30分钟,用户对页面实现的访问时长超出该值的情况下,就判定用户进入到新的会话内容。 4.路径补充 路径补充是将日志内存在缺省的用户请求做出有效补充,获得相对完整有序的访问路径。考虑到要对网站流量进行节约,并能够很好地应用网站资源,设计人员会将页面内容进行缓存,若是用户选定“后退”,那么就很快将信息展现给用户,不必再进行请求[4]。因此,访问这些缓存过的页面在服务器上就没有留下日志。 5.事务识别 事务识别是将路径补充后获取到的会话进行细分,从而得到用户会话事务的过程,以便获取到有价值的会话路径。事务识别实现方法有引用长度法、时间窗口法和最大向前引用法[5]。本文采用最大向前引用法,最大向前引用法实现事务区分的时候会借助对最大向前路径的分析来获得单个事务[6]。在获得向前引用期间,若是找到有向后引用的情况,那么此时的引用分析就停止,所得引用路径就被看成是一个最大向前控制的引用路径,它单独为一个事务,而会话终止也被看成一个最大向前引用。 经过数据预处理相关的操作后,最初的Web日志信息将转变成事务型效果的数据集,下面以某个用户访问序列为例,说明关联规则挖掘的实现过程,见表3。表3是从事务数据库中得到的某用户的12个事务,表中TID是事务编号,PI代表页面编号,I=1,2…,m。下面笔者针对这些事务对关联规则挖掘过程进行阐释。 表3 某用户的事务集 首先,在最初执行算法控制的时候,对事务数据库进行扫描处理,将每个事务完成累加后获得候选1项集C1,详见表4。设定此时最小支持度为min_sup=2,将低于该值的项目剔除,获得频繁项集L1,见表5。 表4 候选1项集C1 表5 频繁1项集L1 其次,候选2项集C2是由L1×L1生成,见表6。将该事务集内支持度不足2的剔除,获得频繁项集L2,见表7。 表6 候选2项集C2 表7 频繁2项集L2 最后,根据频繁2项集L2得到候选3项集C3,先连接,C3=L2×L2={{P1-P2-P3},{P1-P2-P5},{P1-P2-P6},{P1-P3-P5},{P1-P3-P6},{P1-P5-P6}}。考虑到Apriori算法具备反单调性质,那么频繁项集获取到的子集也具备频繁效果。在k项集中,若是(k-1)项子集不是频繁项集范畴,那么该k项集亦非频繁。此时Apriori算法就能够很快速地将此项集剔除备选项。例如,上面得到的P1-P3-P6项集,有3个P1-P3、P1-P6、P3-P6子集。其中,P3-P6不属于L2中的频繁2项集,所以通过剪枝P1-P3-P6就不是候选3项集里的项。这样,有5个候选项不具备频繁性质,需将其排出C3项集内,见表8,再根据C3获取频繁3项集L3,见表9。 对于频繁3项集P1-P2-P6,支持度数为2,根据支持度公式,求得支持度为2/12=16%。参照上文实现的关联规则分析,可以获取到6条有效的关联规则内容。这些规则不论是置信度还是支持度均超出设置的最低参数值。用户可以参照自身实际所需,由前台输入这2项参数信息,得到与需求相一致的关联规则内容。频繁项集有2个页面关联的,比如P1⟹P2,也有3个页面关联的,比如P1⟹P2∧P6,甚至有更多页面关联的。用户得到所需的关联规则以及对应的频繁项集后,还要就其实现处理的效果展开探讨分析,为网站管理者展现出有效的用户浏览特征,并优化已有页面的链接控制,增强站点设定的成效,让用户获得更佳的服务感受。 表8 候选3项集C3 表9 频繁3项集L3 本系统数据取自某高校2017-12-01—2017-12-31期间的原始服务器日志,共计228 896条。在经过数据预处理操作后,获取的能够和规则相契合的数据内容共7 662条。采用Apriori算法,得到的最小支持度为0.05,最小置信度为0.3,同时得到15条强关联规则,得到强关联规则后,对应用效果进行分析,得到用户的浏览习惯和偏好,从而有助于网站管理员改进站点结构、增加链接、优化站点设计。15条强关联规则中的规则P3,P593,P320->P595,其对应的页面为:/index.asp,/news/newsweb/call_news_top.asp,/news/newshtml/insideInform/index.asp->news/newsweb/call_notimenews.asp。该规则说明用户访问P3、P593、P320页面后,有63.32%的可能性访问P595。由于P3页面对应的页面是首页,如果在首页中没有这3个页面的链接,则可以在首页中加入页面的链接,这样既能提高用户查找资源的效率,又能减少网站拥挤,提升网站性能。 另外,强关联规则本身是由频繁项集产生的,说明大部分用户对这4个页面感兴趣。因此,在网站升级时,应重点优化这些页面,吸引用户,提升整个站点访问量。特别值得注意的是,“强关联规则不一定有趣”,也就是说强关联规则只是依据数据,通过数学方法作关联分析得到的,是否体现实际意义还需要网站管理员结合实际情况进行判断。因此,网站管理员在分析这些关联规则时,需要作出判断,让有实际意义的关联规则得以采用,否则会产生不符合实际情况的判断。 随着高校信息化建设深入推进,高校Web服务器上已经积累了大量日志数据,笔者借助关联规则Apriori算法实现了对高校Web日志内容的深入挖掘和处理,得到了高校师生实现访问处理的频繁模式,为网站管理员实现站点优化提供了有效的信息参照。同时,该系统让高校管理层能够通过系统报表及时了解师生浏览行为、习惯和访问网站的意图,为下一步高校信息化建设的方向和资金投入提供依据。 资助项目:北京林业大学教育教学研究项目——面向创新型人才培养的“计算机算法设计与实践”课程建设,项目编号BJFU2018JY087。二、高校Web日志挖掘系统的总体设计
(一)系统框架设计
(二)系统功能设计
(三)数据库设计

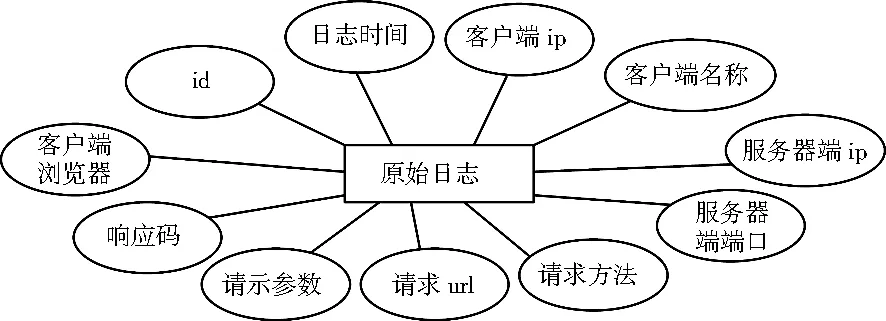

三、高校Web日志挖掘系统的实现
(一)数据预处理模块的实现
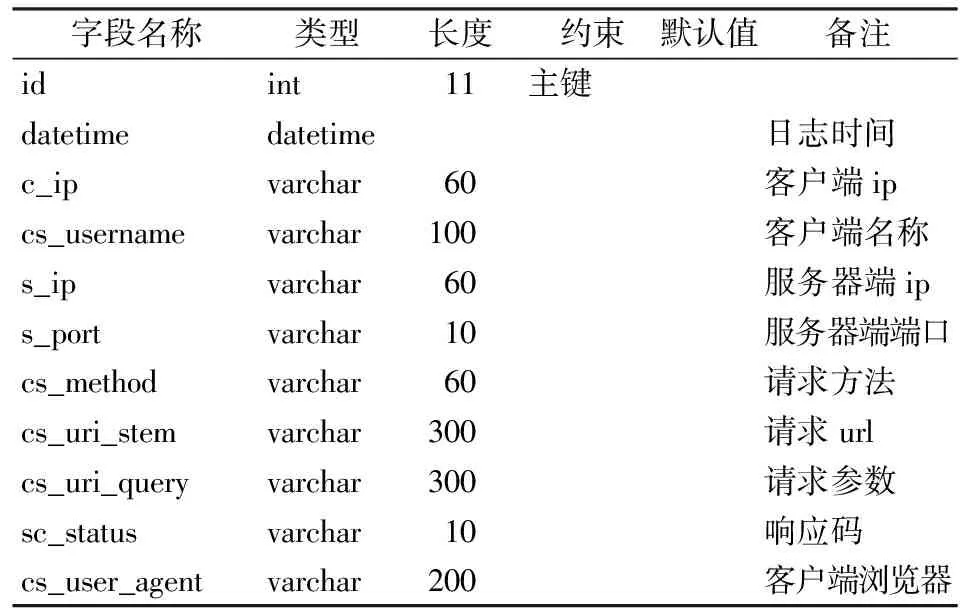


(二)关联规则挖掘模块的实现



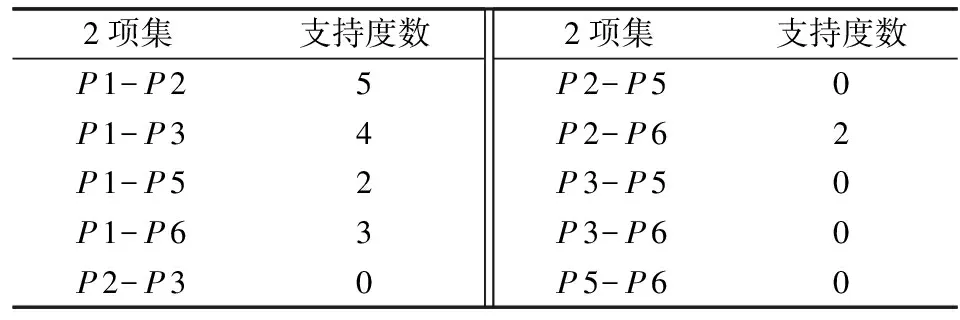


四、高校Web日志挖掘系统的应用和分析
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
核科学与工程(2021年4期)2022-01-12
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
计算机与数字工程(2018年10期)2018-10-23
思维与智慧·上半月(2018年9期)2018-09-22
计算机应用(2018年5期)2018-07-25
