
基于Storm的多租户槽感知调度策略∗
2019-03-12 02:43师康利
新疆大学学报(自然科学版)(中英文) 2019年1期
师康利,于 炯,†,鲁 亮
(1.新疆大学 软件学院,新疆 乌鲁木齐830047; 2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046 )
0 引言
近几年,社交网络[1−5]、股票预测[6,7]、天气预测、交通监控[8]等产生大量的数据.现在,数据以每秒超过30TB的速率生成[9].海量数据的形成,推动了大数据时代的到来.海量的数据需要快速、高效的处理,因此,分布式计算系统应运而生.分布式计算系统主要采用批量计算和流式计算两种计算模式,以Hadoop[10]为代表的批量计算具有高精度、处理海量数据的特性,但是Hadoop主要是处理历史数据,而目前人们对实时处理数据的需求逐渐增长,Hadoop处理实时数据不能满足人们的需求.为了解决人们的需求,高吞吐、低延迟的实时计算系统Storm[11]、S4[12]、SQLstreams-Server[13]、Flink[14]、Spark Streaming[15]等流式计算框架应运而生.其中Storm是Apache最受欢迎的项目之一,它极大地吸引了行业和研究人员的关注.Storm是流式计算的一种开源的、分布式的框架,它以其高扩展性、高容错性、高效性等良好特性得到了众多国内外大公司的支持,例如:Twitter、Yahoo、GRoupon、京东、阿里巴巴等.本文主要是针对Storm的调度进行相关研究.
目前针对Storm默认调度采用轮询算法(Round-Robin)出现的问题,已有不少国内外学者进行了相关的研究.文献[16]主要提出了在线调度策略和离线调度策略:在线调度策略主要是通过监控CPU的负载,降低节点间、节点内的开销;离线调度策略主要是分析拓扑结构和适时的部署拓扑.文献[17]P-Scheduler是根据数据流的传输速率和任务键值对的开销分为两个阶段进行图划分.文献[18]R-Storm提出了资源感知调度的优化策略,其主要是根据CPU、内存、网络带宽三种资源进行实验评估.其中CPU和网络带宽作为软约束条件,内存作为硬约束条件进行测试实验.R-Storm实现了最大化的资源利用率,但是这些都是需要人为的设置而不是自适应的实时监测,不能很好的应用到现实的场景中.文献[19]T-Storm流量感知调度策略是通过最小化节点之间、进程之间,对工作节点的合并采用细粒度控制.文中提出一个工作节点只设置一个槽,虽然这样解决了节点内进程与进程之间的开销,但是也增大了节点间的开销,这样增大了节点间网络传输的负载,并且一个工作节点只设置一个槽在现实应用场景中也不现实,违背了分布式计算的高并发计算.文献[20]S-Storm 提出了槽感知的调度算法,确保每个工作节点分配的槽相对均衡,但是每个工作节点分配的优先策略并未提出,这样和默认调度的轮询算法相似,但是未考虑到每个槽中的负载和线程的负载.文献[21]提出了基于权重的调度算法,主要是根据CPU的使用情况和数据流传输的大小是边权和点权最大增益化,通过降低网络间的开销和确保负载均衡的条件下实现的.文献[23]提出了任务调度策略等.上述的调度算法除了文献[20]提到了多个拓扑提交的负载均衡,其它的调度算法都没有涉及到多个业务拓扑同时运行的情况.虽然文献[20]提出了多个拓扑提交后的节点负载槽的均衡,但是未考虑到局部的负载以及开销的问题.针对以上问题本文中提出了改进的调度策略.
1 相关工作
本章节主要介绍Storm的集群框架、Storm执行数据流的拓扑结构、基于权重的优先调度算法.
1.1 Storm介绍
1.2 Storm的拓扑结构
Storm 的数据流即拓扑是以DAG(有向无环图)的形式展现的.如图2所示,一个作业拓扑是由Spout和Bolt组成.其中,Spout是数据源编程单元,主要是读取数据;Bolt是数据处理编程单元,主要是处理数据.Spout和Bolt都被称为组件,每个组件被认为一个任务线程,一个拓扑包括多个任务线程,工作节点中的槽可以执行多个任务线程.Bolt 从上游的Spout读取数据则按照数据流组进行数据处理,Storm提供7种数据流组:Shuffle Grouping(随机分组)、Fields Grouping(字段分组)、All Grouping(广播分组)、Non Grouping(不分组)、Global Grouping(全局分组)、Direct Grouping(直接分组)、Local Or Shuffle Grouping(本地分组).本文中实现代码是按照字段分组实现的.

图1 Storm架构图Fig. 1 Storm architecture diagram

图2 数据流拓扑模型Fig. 2 Data stream topology model
1.3 Storm调度问题分析与提高
Storm默认的调度算法未考虑到在多个拓扑同时运行的情况下,导致工作节点的负载不均衡以及开销过大的问题.默认的调度只是将拓扑任务按照轮询的策略分配到每个工作节点中,但是当拓扑被终止,或者提交新的拓扑时,容易导致每个节点的槽占用量分布不均衡.如图3所示,4个工作节点分别为N1、N2、N3、N4,提交拓扑T1、T2、T3后,如图3(a)所示,N2节点占用3个槽,N1、N3、N4三个工作节点分别占用2个槽,此时拓扑的分布所占用的槽相对均衡.但是当终止T2拓扑后,如图3(b)所示,N1、N2、N3之前分配给拓扑T2的槽空闲,当提交拓扑T4时,默认调度又重新分配任务到每个工作节点中的槽,如图3(c)所示,N2工作节点占用3个槽,N1、N4工作节点分别占用2个槽,而N3工作节点只占用1个槽.从图3(c)中可以看出使用默认调度在提交多拓扑的情况下容易导致工作节点分配槽不均衡的现象.为了解决这类问题,本文提出了多租户槽感知调度策略[24],均衡的分配拓扑任务到每个工作节点中.本文中提出的算法是按照优先级原则均衡分配槽的机制实现的.

图3 Storm默认调度Fig. 3 Default scheduling in Storm
2 算法模型与分析
本章节主要是针对默认调度下提交多个作业拓扑中出现的槽分配不均衡以及工作节点负载不均衡问题,建立了均衡分配模型并详细介绍.
2.1 均衡分配模型
初始化工作节点的优先权重,即开启Storm集群,除Nimbus主控节点,根据从节点的启动顺序赋予从节点即工作节点权重.设定任意一个节点Ni的权重ω为i,则有

由公式(1)赋予的权重值,即某一节点的权重越小,越优先将拓扑任务分配到该节点上.设epq为第p个拓扑的第q个线程,若该线程分配到了第i个节点的第j个槽中,则可表示为

由公式(2)提交的作业拓扑,记每个拓扑所需要分配的workers(worker即为Slot)为WTp,拓扑集合T={t1,t2,t3,···,t|T|},p∈T,则提交的所有的拓扑所需要分配的workers为个工作节点均衡分配给提交的作业拓扑所需要的workers的数量即为:

对于∀i,j如果任意的两个工作节点被占用槽的数量相等,槽的集合记为S={s1,s2,s3,···,s|S|},且Sik∈S,Sjk∈S,则,其中表示任意一个工作节点所分配给拓扑占用槽数量的总和,Sik表示第i个工作节点中的第k个槽被占用.同理,Sjk亦是如此.并且任意一个工作节点被占用的槽不能超过公式(3)中的,即,
采用MRS培养基[17],分别接种10-5、10-6、10-7、10-8 四个稀释梯度的悬浮液,将接种好的培养皿于37 ℃培养24 h后进行乳酸菌菌落计数。计数时选取培养基上光滑,圆形的灰白色菌落进行计数。

则Storm集群每个工作节点均衡分配worker进程给作业拓扑,否则重新遍历分配槽.
记任意一个节点i中的任意一个Slotj的负载为LoadSij,则任意一个工作节点的所有槽负载为通过监控CPU的负载,设置工作节点的最大负载为α×Loadcpu,则工作节点i的最大负载量为:

3 算法的实现与测试评估
根据上述提出的均衡分配模型,本章节提出了基于多租户调度的均衡分配工作进程的算法,并且分析了算法的可实施性以及算法的部署与评估.
3.1 算法描述
将多拓扑所有的任务分配到每个工作节点,使每个工作节点Slot均衡的被占用.首先,每个工作节点赋予权重值,表示工作节点被分配任务的优先级,其次按照Slot的优先级均匀的分配拓扑任务.因此,本文提出的多租户调度均衡分配算法的实现,用户需要执行默认调度,当默认调度执行时间大于触发多租户调度均衡分配算法的时间τ时,或者不符合算法模型中的公式(4)、(5)时,触发多租户均衡分配调度.
算法1Slot均衡分配算法
1)获取每个工作节点的supervisor-id,根据公式(1)以及获取的supervisor-id,赋值每个工作节点的权重ω;获取每个工作节点的CPU的最大负载信息,即公式(5)中的Loadcpu;
2)提交拓扑,在默认调度下执行拓扑任务;
3)遍历每一个工作节点分配的拓扑信息;获取公式(3)中每个工作节点最大可承载的槽数量W;计算每个工作节点执行拓扑任务的总负载,如公式(5)中
4)根据第3)步,当每个工作节点槽的数量大于时,此工作节点不再分配槽,当大于时,将其任务分配到其它的工作节点中.否则,按照第2)步执行拓扑;
5)计算每个工作节点的槽数量,集群中所有被占用的槽按照数量的大小、队列的形式进行排序并赋值优先级,每个节点占用槽的数量越小,优先级越高,当再次提交拓扑的时候优先分配给优先级高的槽,则按照公式(2)中分配拓扑;
6)终止其中的任意一个或多个拓扑时,按照第3)步重新获取计算更新信息,重新分配;
7)若提交新的拓扑,第3)、4)步重新计算,依次计算每个工作节点实际的负载信息;按照第5)步,进行任务分配.
3.2 算法分析与评估
算法1在Storm集群环境运行的过程中,第1)步根据从工作节点启动的先后顺序按照supervisor-id进行优先权值划分,通过监控物理机的CPU获取CPU的负载赫兹;第2)步是在默认调度算法下运行,初始化调度信息;第3)步根据提交拓扑的执行信息计算出每个工作节点的最大可以分配多少个槽以及每个工作节点总CPU 的负载;第4)、5)步遍历所有节点中被占用槽的量以及工作节点的负载,并且实时更新每个节点以及槽的优先级即当任意两个工作节点占用槽的数量相等时,按照工作节点的优先级分配任务,否则按照槽的优先级分配任务;第6)、7)步是如何记录终止拓扑和提交新的拓扑以及执行更新后的拓扑信息.通过分析上述算法的执行,多租户均衡分配算法的最大时间开销是每个工作节点中分配拓扑的情况,获得更新记录信息的时间复杂度为O(|N|×|S|),其中|N|表示共N个工作节点,|S|表示每个节点共S个槽.由于遍历每个节点以及其所使用的槽,并且赋其优先级权重,根据优先级分配任务拓扑,所以空间复杂度较小,在本文中忽略不计.本文中的算法只是均衡的将拓扑分配到每个工作节点的槽中,算法主要是以槽的使用为依据,因此,本文不依据提交的拓扑遍历信息.
3.3 算法的实现与部署
为了实现本文中提出的算法1,本节主要是基于图4即Storm调度架构图实现的.本文中实现算法1的代码是通过Apache Storm提供的IScheduler接口实现的,该接口提供的prepare()方法主要作用是初始化,schedule(Topologiestopologies,Cluster cluster)方法则是实现算法1的自定义调度器,如图4所示,本文中的自定义调度器主要是通过以下三个方面实现的:1)负载监视模块:主要负责监控作业拓扑的执行分布信息,记录拓扑中的线程分配到每个节点槽中的信息,通过监控每个槽的CPU的负载计算出每个工作节点总的CPU负载;2)MySQL数据库存储:将负载监视模块监测的所有工作节点的信息写入到数据库中,并且根据调度信息实时变化进行实时更新;3)均衡分配模块:根据数据库中记录的调度信息,获取工作节点数、占用槽数、节点负载量均衡的分配每个工作节点的槽.

图4 Storm调度架构图Fig. 4 Scheduling architecture diagram in Storm
4 实验结果分析
基于Storm1.0.3版本的集群环境,对本文中提出的调度策略进行测试.
4.1 实验环境分析
为了验证本文中提出的调度策略的有效性,搭建了Storm集群,如表1所示.表1展示了本文中搭建Storm实验环境所需要的硬件配置和软件配置.实验中共使用5个节点,其中包含一个主控节点(Nimbus)和4个工作节点(Supervisor).主控节点除了启动Nimbus进程外,还负责启动Zookeeper、UI、 Mysql进程.Nimbus主要负责分配任务,Zookeeper 协调管理主控节点和工作节点,UI是观察作业拓扑的页面,Mysql 存储作业拓扑的调度信息.Storm的搭建是基于操作系统CentOS6.8,实验代码是基于Java语言使用Myeclipse 集成环境写的,所需的JDK为1.8的环境,Maven主要下载依赖包和编译,nmon是监控CPU、内存、网络带宽等资源的使用.主控节点和工作节点使用的硬件配置是一样的,即本文中的实验是基于同构环境下进行的.

表1 Storm集群软硬件配置Tab. 1 Hardware and software configuration of Storm cluster
本文的实验在上述环境下通过benchmark 基准测试进行实现的.在实验中,分别提交作业拓扑T1、T2、T3,其中三个拓扑所需要的workers进程分别为4、3、2个进程,其中终止T2拓扑,然后再提交T4拓扑,其中T4拓扑所需要的workers进程为2.本文中每次提交作业拓扑后,通过负载监控模块监控槽的负载,并且通过nmon获取CPU的使用信息.
4.2 实验结果分析
通过实验结果从节点占用的槽、节点的CPU负载两方面进行评估本文提出的多租户调度策略.实验测试获取的数据是基于benchmark基准测试通过metric API获取的,实验数据的收集是通过每5秒的频率采集的,每个拓扑运行的时间为10min.
4.2.1 均衡分配槽的测试
通过实现本文中提出的多租户槽感知调度策略,提交多个拓扑和在默认调度下提交的拓扑以及每个拓扑所需的workers数量.Spout和Bolt的并行度等参数一致的情况下,如图5所示,在提交T1、T2、T3拓扑后如图5(a)所示,每个拓扑任务按照工作节点和槽的优先级平均的分配到工作节点的槽中.如图5(b)所示,当终止拓扑T2后,工作节点N1、N4分别占用2个槽,而工作节点N2、N3分别占用1个槽,此时更新工作节点的优先级,则N1、N2、N3、N4按照优先级高低排序是N2、N3、N1、N4.当提交拓扑T4时,根据拓扑T4所需要分配2个槽,则N2、N3工作节点分别分配一个槽;若拓扑T4需要分配3个槽,则N2、N3、N1分别分配一个槽;若拓扑T4需要分配4个槽,则N2、N3、N1、N4分别分配一个槽.每个工作节点所分配的槽的总数量必须符合公式(4)的要求.图5(c)中所示,在终止拓扑T2后,遍历所有工作节点槽占用的信息,若任意两个节点中占用的槽不相等,工作节点中占用槽数量最小被分到任务的优先级越高,若出现多个工作节点中占用槽的数量相等,并且节点中所占用槽的数量和最小占用槽的节点相等,则按照节点的优先级分配任务.如图5和图3所示,从两个图的(c)中可以明显观察到均衡分配调度比默认调度分配的槽更加均衡.
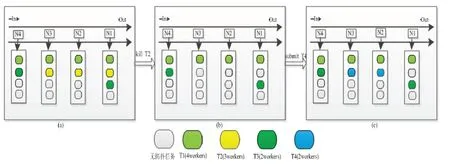
图5 多租户槽感知调度Fig 5 Multi-tenant slot-aware scheduling
4.2.2 性能评估
实验结果如图6所示.在默认调度和本文中提出的多租户感知调度的实验结果分析,其中,图6(a)和(b)分别展示了提交拓扑T1、T2、T3的CPU的平均使用率和终止T2提交T4拓扑后CPU的平均使用率,图6(c)和(d)所示是提交完T4拓扑之后通过Metric获取拓扑T4的平均延迟和吞吐量.图6(a)展示在提交多拓扑的情况下,在默认调度的情况下每个工作节点的CPU占用率相差比较大,而在多租户调度下CPU的占用相对均衡,其中图6(a)中node1 CPU的占用相对高,从图5(a)可以看到节点node1被占用槽的数量比其它节点多一个,其它三个节点被占用槽的数量相等,因此节点node1 CPU的占用会相对高点.当终止T2拓扑,再提交T4拓扑后,从图5(b)中可以看到在默认调度情况下节点node3工作节点CPU的占用率只有39.4%,而其它的三个工作节点CPU的占用高达91.2%,甚至更高.在本文中提出的多租户调度的情况下每个工作节点CPU的占用在84%左右.从图6(c)和(d)中所示,本文中的采集延迟和吞吐量的频率是每10s采集一次,共采集10min.图6(c)展示了在默认调度下最高的平均延迟670ms,多租户调度下最高延迟是550ms,默认调度是在160s后延迟开始下降,多租户调度是在120s后延迟开始下降,并且在多租户调度下的延迟比在默认调度下的延迟值都低.图6(d)所示在110s后多租户调度的吞吐量开始提高,而默认调度则是在140s后提高,从图6(d)图中观察多租户调度的吞吐量明显高于默认调度下的吞吐量,从整体的吞吐量,多租户调度下的吞吐量高于默认调度下的吞吐量.从图6(a)和(b)分析证明了本文中提出的调度策略是每个工作节点CPU的负载相对均衡,CPU平均降低了15.1%,平均延迟降低了29%,吞吐量提高了24.2%.

图6 实验效果图Fig 6 Experimental results
5 结论
本文提出的多租户负载均衡调度研究主要解决了用户提交多个业务拓扑的情况下导致工作节点的负载不均衡和默认调度采用轮询方法导致工作节点资源未充分利用造成吞吐量降低,延迟时间长的问题.本文中通过提出的优先分配算法和负载均衡算法实现了多租户调度的资源利用最大化、降低延迟、提高吞吐量.实验表明本文提出的调度策略比默认调度有所改善和提高.下一步的研究工作,主要有以下几方面:(1)本实验是基于性能相等的物理机集群中实现的,下一步在异构环境下实现;(2)控制节点的工作进程,适时动态分配槽,使槽的使用更具灵活性;(3)进一步的优化算法,将此调度算法广泛应用到现实的应用场景中.
猜你喜欢
微型电脑应用(2020年12期)2020-12-26
铁道通信信号(2020年10期)2020-02-07
铁道通信信号(2020年9期)2020-02-06
电子技术与软件工程(2020年12期)2020-02-04
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
计算机应用与软件(2017年8期)2017-08-12
