
东张水库蓝藻水华BP人工神经网络模型演算研究
2019-03-04 06:05张明峰苏玉萍陈杨锋李赫龙陈宇昕
渔业研究 2019年1期
覃 苗,张明峰,洪 颐,苏玉萍,4*,陈杨锋,李赫龙,陈宇昕
(1.福建师范大学环境科学与工程学院,福建 福州 350007; 2.福建师范大学地理科学学院,福建 福州 350007; 3.法国巴黎高科路桥大学城市与水环境实验室,法国 巴黎 77455; 4.福建师范大学,福建省污染控制与资源循环重点实验室,福建 福州 350007)
社会的进步以及工、农业的迅速发展,给湖泊水库的水质带来了污染。在陆地上贫瘠的氮、磷等元素,在水中却过多的存在,从而引起了一种有害的自然现象——水华暴发。水华暴发是一种由于水体富营养化等多种原因综合影响而引发的自然现象,当气候和水质有利于藻类生长和聚集时,藻类呈现暴发性繁殖和聚集,通常伴有水面变色[1]。水中存在的过多的氮、磷等营养物质是水华产生的主要原因,而诸如pH、气候等条件也会对其暴发造成一定的影响[2-3]。本文的研究对象——福清市东张水库为饮用水地表水源保护区,于2007—2017年的10年间在大坝区域多次暴发蓝藻水华[4-7]。因此,通过一定的监测预警模型,预见性地提醒相关部门及时采取相应的防控措施,对有效防治水华的暴发就显得尤为重要。
近年来,随着人工智能的迅速发展,基于数理统计和人工神经网络的预警模型系统在水华预警预报研究中得到了一定的应用。研究人员以BP模型作为手段,建立了各种水华预警模型,Maier等通过人工神经网络建立了预测模型,预测了澳大利亚River Murray流域蓝藻水华的暴发[8];Lee等则以ANN预测了香港沿海流域藻类水华的发生[9];仝玉华运用RBF/BP网络藻类水华预测模型,分析运算了其研究流域中的水华分布时空规律,针对性建立了多元线性回归预测模型[10]。
在建立水体富营养化和因其所致的水华暴发预警模型时,BP人工神经网络作为一个十分合适的工具,具有许多独有的优点,例如方法简单、无需建立复杂的数学计算模型、具有很强的适应性和容错性、具有较强的处理非线性问题的能力等。BP人工神经智能网络作为一种以数据作为驱动的模型,其最大的特点是具有自学习、记忆联想和判别功能。而这种学习、判别功能需要大量的环境参数和水质检测数据。因此收集足够数量的样本数据成为BP人工神经网络模型解决水华预测成败的关键。本文通过长期对东张水库的监测所获取大量的数据,运用人工神经网络模型进行运算,探讨了预测蓝藻水华暴发的可能性,旨在为蓝藻水华暴发的预警提供新的方法,为相关部门在蓝藻水华的防控提供参考。
1 材料与方法
1.1 数据来源
本研究数据来自福清市东张水库(图1,119°29′20″E、25°46′6″N)自动监测站2016—2017年水体大坝断面数据,共295组有效数据,包括水温、溶解氧、电导率等在线水质检测数据(表1)。且该数据样本包含大坝断面水华期间的数据。
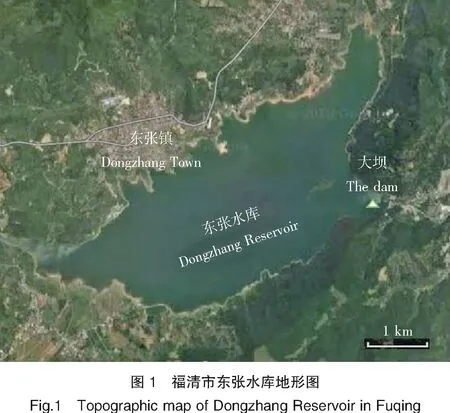

表1 主要的检测参数和单位
1.2 BP建模方法
为建立BP人工神经网络模型,将水质参数做交叉对比,选出输出结果较好的水质输入指标,综合比对福清市的气象数据(气温、风速),将水质参数与气象数据组合作为自变量输入模型,以叶绿素a浓度为因变量,通过BP人工神经网络模型来探究水质与水华暴发之间的相关性,并选出输出结果较好的输入参数组合应用于后期水库蓝藻水华的预测。
在模型的构建过程中,采用的取样方法是对295组样本做随机排序,抽取后80%的数据进行模型训练,前20%作为测试数据进行检验。在模型训练完成后,以测试数据检测该模型的训练结果,并输出训练拟合结果,且获取训练值与测试数据的误差,获得误差比值,模型运行结束。
1.2.1 模型的建立和演绎过程

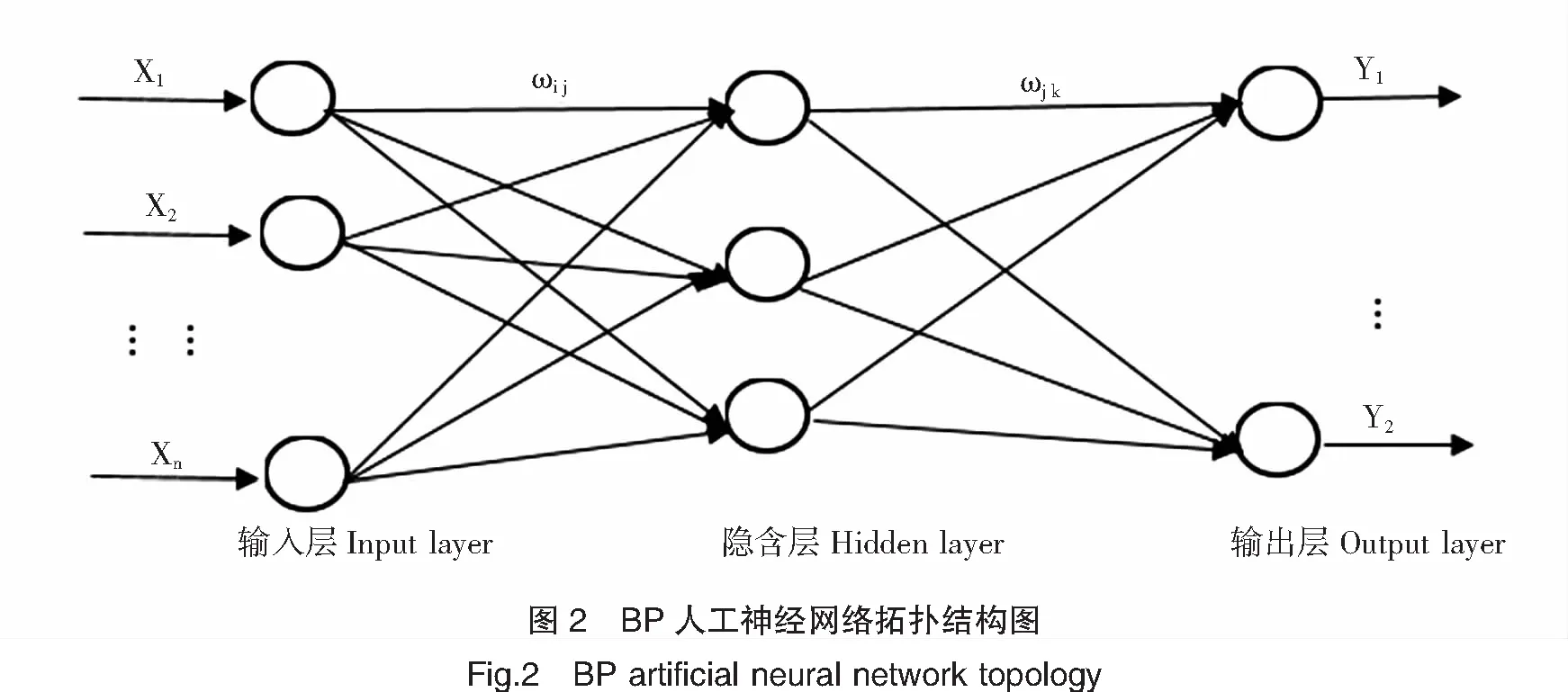
假设在模型中的任意一个节点输入信号为xi,输出信号为yi。
j=1,2,……,l;
hj=fvj,j=1,2,……,j;
因此,如果有n层,并且第n层指且仅指输出层级,而第一层为输入层级。则该模型的BP算法则由以下推演而出:
首先,初始化连接权重值ω1,同时初始化激活阈值(初始化偏置)a1、b1;接着,重复以下的过程直到输出结果收敛:

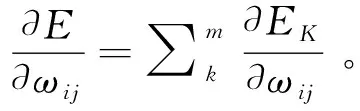
1.2.2 数据处理
采用SPSS 23.0软件进行Spearman相关分析。利用 MATLAB R2016b 建立东张水库蓝藻水华BP 人工神经网络模型。
2 结果与分析
2.1 Spearman相关性分析结果
对本次研究所用的295组数据进行了相关性分析。结果如表2所示。
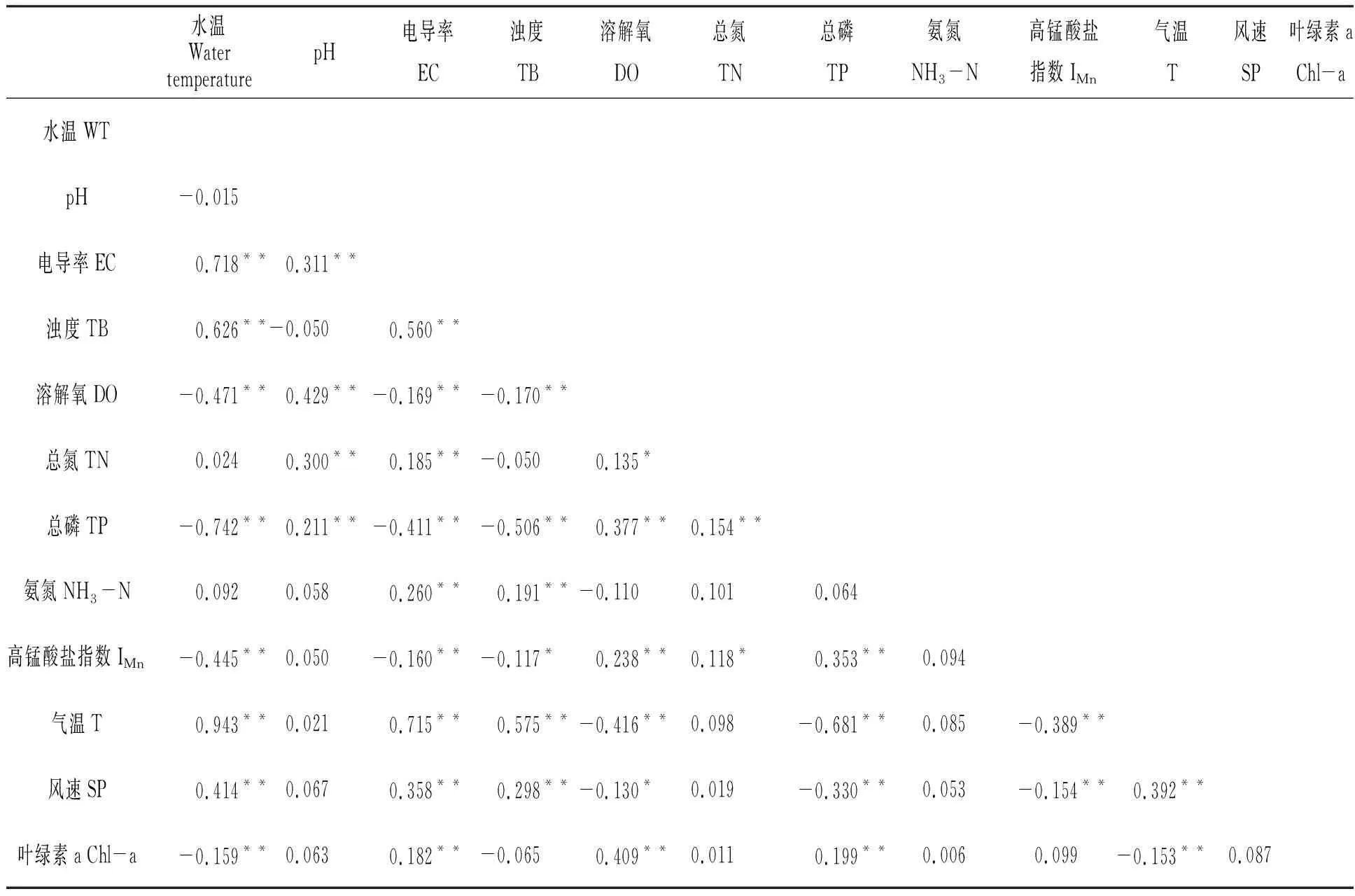
表2 东张水库各指标因子间的Spearman相关关系
注:*表示显著相关(P<0.05,2-tailed),**表示极显著相关(P<0.01,2-tailed)。
Notes:*indicates significant correlation(P<0.05,2-tailed),**indicates extremely significant correlation(P<0.01,2-tailed).
在淡水湖库中,浮游植物的生长受多种环境因子的制约,而湖库水中存在的叶绿素a则在一定程度上反映该流域内浮游植物的生长情况[11]。根据表2的相关性分析结果,可以知道,在东张水库水体的水质检测建模数据中,水温、溶氧等在线监测指标数据与叶绿素a之间存在较好的相关性(P<0.05)。并且气温、风速等气象指标对藻类的生长也存在着协同效应。因此叶绿素a数值会伴随着各个相关数值的改变而变化。因此选取相关性结果较好的因子进行模型演算是合适的。
2.2 BP人工神经网络样本训练与模型拟合结果
选取了可以在线监测、数值准确的水质指标,以不同的数据组合作为输入参数,经大量的重复试验运算,不同的数据组获得的输出结果如表3所示。从中筛选出最优的参数组合。从表3各参数组合指标输出结果的误差及拟合度的结果可以看出,以水温和溶解氧(组合2)作为输入参数,其输出结果叶绿素a的预测值的均方根误差(RMSE)为0.10 μg/L,均方根与实测值标准偏差比(RSR)为0.84,R2=0.34;而增加了电导率作为输入参数(组合3),其输出结果有了较大提升,均方根误差(RMSE)为0.09 μg/L,均方根与实测值标准偏差比(RSR)为0.56,R2=0.74。但当再加入浊度作为输入参数(组合4)时,输出结果叶绿素a的预测值的均方根误差(RMSE)为0.11 μg/L,均方根与实测值标准偏差比(RSR)为0.59,R2=0.68,误差反而变大,拟合更低。因此选择了指标数量较少且结果较好的水温、溶解氧和电导率作为模型水质输入参数(组合3)。由于在一般性认知中,认为蓝藻水华的暴发与一定条件的氮、磷含量等水体理化性质、温度和光照等气象条件、水文条件和生态环境有关,是水体环境因素(如总氮、总磷、pH、溶解氧)和气象因素(如气温、光照、风向、风速等)综合作用的结果[12-13]。因此本研究将浊度、pH、气温和风速等因子逐步作为输入参数加入模型,分别得出了组合4、5、6和7的数据结果。可以看出,模型的最优参数输入组合为水温、溶解氧、电导率、气温即组合6,该组合的输出结果叶绿素a的预测值的均方根误差(RMSE)为0.08 μg/L,均方根与实测值标准偏差比(RSR)为0.43,R2=0.83。
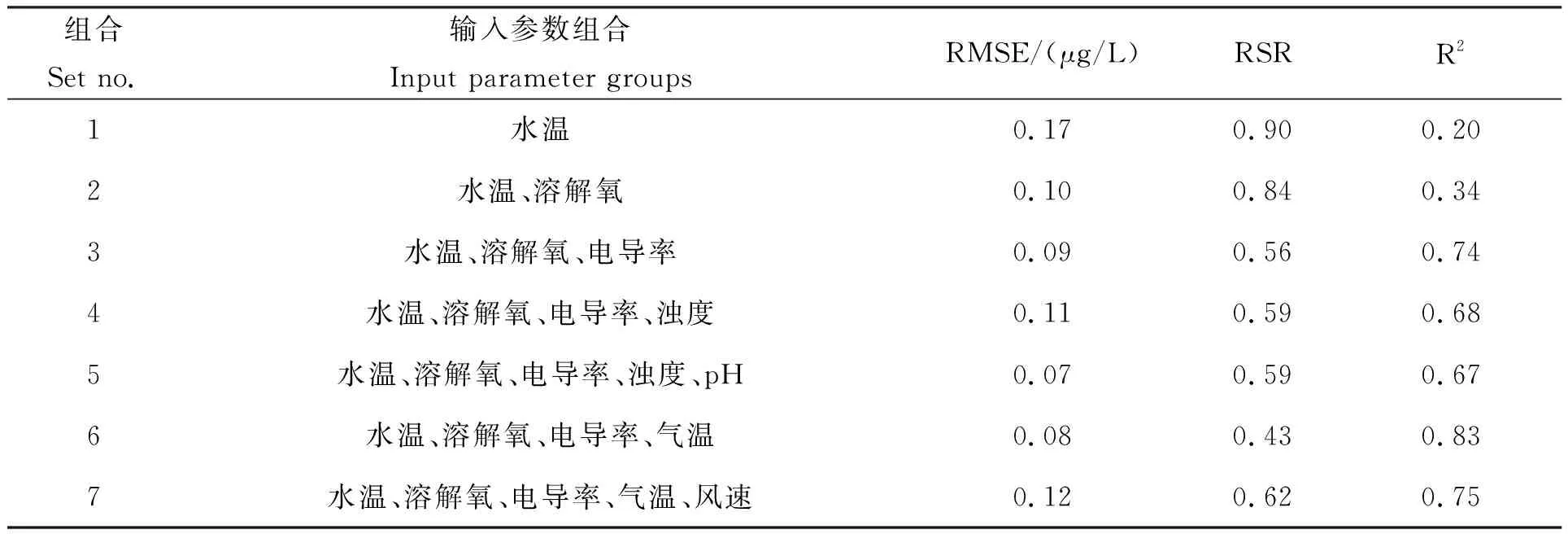
表3 各水质指标输入参数组合的模型运算输出结果的RMSE、RSR、R2
对各组合的结果中较有代表性的组合3、组合6和组合7做进一步分析,结果如图3、图4、图5所示。



可以看出在三组叶绿素a的模拟结果中,预测值和实测值在数据的各个峰值与数据的趋向性上都具有一定的相似性。但组合6的拟合结果(图4)是最好的,该组合的模拟结果不仅在各个峰值涵盖了实际数据,并且在整体数据的相似度上与其他组合相比,数据更为接近。因此可以认为BP人工神经网络模型在以东张水库的水温、溶解氧、电导率和气温这4个指标作为输入参数时,模型的学习训练结果可以提取有效的学习经验,并做出具有针对性的预测。模型训练的运行结果符合试验训练预期。
3 讨论
从经过模型的模拟预算结果可以看出,输入端因子经优化组合后输出端的结果更好,并且结合气象数据作为输入因子后模型输出结果的精度明显高于仅以水质作为输入因子的模型预测结果。但是所有组合的模型输出结果均与传统意义上较好的拟合度(R=0.999)存在着一定的差距,这可能是由于人工神经网络模型的数据训练量不足以及参数过多所致,并且许多参数并没有绝对公认的最佳取值,仅仅只有相对最优值。在建模过程中,仅靠建模者的经验和主观判断,在试验的时候需要不断地调整与试验才能取得相对较为理想的结果。
从图3、4、5可以看出,在三组模型输出的数据结果中,有些点位呈现跳跃式增长,这是由于在2016—2017年水质检测数据中,部分月份水华暴发,导致各个指标都呈现明显的变化,尤其是总磷、总氮的数值增长更明显,这种迅猛增长在其他月份是不存在的。由于本次模型的训练样本的有限性,对于模型的识别和预测造成了一定的局限。并且水华暴发时期一般为夏、秋季,库区不同区域水深的水温存在较大差异。此外,降雨等因素也对水体水质造成一定的影响。因此在后续的改进模型中,应着重对于输入参数进行分类,将数据波动较大的数据与波动较为不明显的数据分开,以增加模型预测的准确性。
不同气象因子的输入也对预测结果的拟合度有不同的影响,可能的原因是气象数据不足,本次研究仅采用气温、风速这两个参数,还缺风向、光照强度、日照时间、降雨量等对于水华有影响的气象因子作为输入数据供筛选。因此,在今后的模型改进中,应该尽量多地考虑其他气象因子和环境影响因子,以减少模型运算误差。
4 结论
本研究建立了一种可以应用于湖库水华暴发的BP人工神经网络预警模型。利用BP人工神经网络理论,以福清市东张水库为例,得到了以水温、溶解氧、电导率和气温为输入参数的指标组合,使得以叶绿素a为输出指标的预测结果拟合度达到0.83,得到了较好的结果,符合试验预期。
猜你喜欢
中国资源综合利用(2022年4期)2022-05-09
中国水利(2022年7期)2022-04-28
环境技术(2022年1期)2022-03-21
当代水产(2021年8期)2021-11-04
飞天(2019年6期)2019-07-08
电子制作(2019年10期)2019-06-17
中学生物学(2016年12期)2017-04-06
科学与财富(2016年34期)2017-03-23
北京航空航天大学学报(2016年3期)2016-02-27
新高考·高二数学(2015年2期)2015-05-27
