
基于遗传算法和二进制蚁群算法的DV-Hop定位算法的优化
2019-02-22 12:01林凤德陈佳品李振波
仪表技术与传感器 2019年1期
林凤德,陈佳品,丁 凯,李振波
(1.上海交通大学电子信息与电气工程学院,薄膜与微细技术教育部重点实验室,上海 200240;2.无锡近地面探测技术重点实验室,江苏无锡 214035)
0 引言
近年来,随着微机电系统(MEMS)、集成电路系统技术、通信技术以及计算机软件的巨大进步,带动了大规模分布式无线传感器网络的快速发展。无线传感器网络(wireless sensor network,WSN)是由部署在检测区域内的大量低成本传感器节点通过无线通信方式形成的一种多跳自组织的网络系统。其目的是协作地感知、采集和处理网络覆盖区域中感知的对象信息,并发送给观察者。WSN 提供了一种新颖的信息获取和处理方法,在医疗卫生、环境监测、军事作战等方面具有广泛的应用,所以,WSN已经成为21世纪最受瞩目的科技之一[1-2]。
在WSN中,将现有定位算法分为基于测量距离的定位算法和基于非测距定位算法方法2类。基于测量距离的定位算法定位精度较高,需要测距硬件,功耗、成本也相对较大,不适合应用到大规模的网络环境中。常用的测距方法有TOA、TDOA、AOA和RSSI等[2-4]。而非测距定位算法利用连通情况来估测未知节点的位置,常见的非测距算法如质心、DV-Hop、APIT以及MDS-MAP等。由于非测距定位算法直接使用连通信息,硬件要求更低,在功耗和成本上具备更大优势,并且定位精度可以满足多数传感网络的应用要求,更适合应用于低成本、低功耗的无线传感网络。其中DV-Hop定位算法[5-6]技术以其方便性、可操作性等优点得到了广泛的应用,而传统的DV-Hop定位算法在由已知节点得到未知节点的位置时存在很大的误差,并且算法的收敛性性能也较差,导致传统的DV-Hop算法精度不够、计算时间较长,无法达到一些工程要求。针对以上问题,本文提出了一种基于遗传算法和二进制蚁群算法改进的DV-Hop定位算法,其中遗传算法采用复制-交叉-变异算子的方式进行循环搜索,在产生新个体的基础上,利用改进的蚁群算法进行进一步搜索,蚁群算法采用二进制编码的方式遍历搜索能力更强,并且提高了收敛的速度,从而提高了节点定位精度和缩短了节点定位所消耗的时间。
实验结果显示,本文提出新的算法比传统的DV-Hop算法和基于遗传算法的DV-Hop算法有更好的收敛性,而且通过改变未知节点个数、锚节点密度、通信距离R等条件,本文提出的算法比传统的DV-Hop算法、基于遗传算法的DV-Hop算法有更好的定位精度。
1 定位模型设计理论
1.1 DV-Hop定位算法
DV-Hop[5-6]是一种利用距离矢量路由和GPS定位思想提出的定位算法,这个算法由3个阶段组成[5-6]。第一个阶段:网络中的每个未知节点计算到每个锚节点的最小跳数值;第二阶段:通过一个简单的公式估计每跳的平均距离,然后广播到全局网络让所有的节点都得到每跳的平均距离,这样未知节点将估计到锚节点的距离。第三阶段:利用三边测量法或极大似然估计法计算出未知节点的位置。
1.1.1 计算最小跳数值
每个锚节点向其邻居节点广播信标数据包,数据包的格式是{id,xi,yi,Hi},其中标识符id每个节点的唯一标识,锚节点i的坐标为(xi,yi),到锚节点最小跳数的值为Hi,其中Hi初始值为0。在邻居节点接收到具有较小跳数值的特定锚节点的信标包之后,它们保存锚节点的位置,并在将其发送到其他相邻节点之前将其计数值增加1。具有到特定的锚节点有较高跳数值的信标包,将被定义为过时的信息,并且被忽略。通过这种机制,网络中的每个节点都会得到每个锚节点的最小跳数值。
1.1.2 估计节点间距离
首先,利用式(1)计算每个锚节点之间的一跳的平均距离为HopSizei:
(1)
式中:(xi,yi)和(xj,yj)为锚节点i和j的坐标;Hij为锚节点i和j之间的最小跳数;m为锚节点的个数。
计算完HopSizei后,每个锚节点在整个网络中广播HopSizei,当未知节点从锚节点得到HopSizei后;应用式(2),计算他们之间的距离:
di=HopSizei×Hij
(2)
1.1.3 确定的位置
根据每个锚节点的坐标以及在第二阶段中未知节点到锚节点之间的距离,通过多点定位的方式来计算未知节点的坐标。设未知节P点的坐标为(x,y),锚节点i的坐标为(xi,yi)。因此,未知节点P和m个锚节点之间的距离关系如式(3)所示:
(3)
展开后可以被写成矩阵Ax=b
(4)
(5)

(6)
可以得出:
X=(ATA)-1ATb
(7)
1.2 遗传算法
遗传算法[7]是模仿自然生物进化思想而衍生出来的一种自适应启发式全局搜索算法[8]。在本质上,它是一个由选择、交叉、变异算子构成的循环过程[7-9]。在这个过程中寻找全局最优解,算法不需要梯度信息和微积分计算,它可以只通过操作选择、交叉、变异算子的操作,以很高的概率找到全局最优解或接近最优解的解空间。因此,它可以减少陷入局部的解空间。
1.3 二进制蚁群算法
蚁群算法[10]是一种新的模拟进化算法。蚂蚁在寻找食物时会释放出一种特殊的信息素,使其他蚂蚁感受到这种特殊性,并趋向于高密度的方向。蚁群算法通过信息素的积累和更新收敛最优路径,并通过适当的迭代次数实现优化。二进制蚁群算法[10-11]直接用二进制编码来表示参数,与十进制编码相比,该算法占用的存储空间小,算法复杂度低。此外,二进制编码的遍历搜索能力优于十进制编码。
2 基于遗传-二进制蚁群算法的DV-Hop算法的定位
2.1 WSN定位算法数学模型
在DV-Hop算法[5-6]中,距离是一个估计值,所以必然有误差。WSN定位问题的主要目标是最小化误差。在本文中,我们提出了一种基于遗传-二进制蚁群算法的DV-Hop算法[11-12]。
假设在传感器网络中有M+N个传感器节点,包括M个锚节点(坐标已知)和N个待测节点(未知节点)。已知锚节点的坐标为(xi,yi),(i=1,2,…,m)和未知节点的坐标为(x,y),(i=1,2,…,n)。根据DV-Hop算法的第二个阶段。可以获得未知节点和锚节点i,(i=1,2,…,m)之间的距离di,所以可以得到以下的公式:
(8)
因为距离di是一个估计值,那么必定存在误差。为此,改进算法是将WSN定位问题的误差降到最小,定位问题可以归结为
(9)
根据式(9)所示的目标函数,设置适应度函数如下:
(10)
式中α为正实系数。
2.2 算法的步骤
步骤1:计算每个节点到每个锚节点的最小跳数值,根据式(1)估计每个锚节点的一跳的平均大小,通过使用最小跳计数值和一跳的平均大小,每个未知节点根据式(2)估计到锚节点的距离;
步骤2:确定每个未知节点的种群可行域,并在可行域内生成初始种群;为了提高定位精度或收敛速度,我们限制了一个样本种群的可行区域,如图1所示:假设未知节点N有3个最近的锚节点K1,K2,K3;他们的坐标是(x1,y1),(x2,y2)和(x3,y3),并且锚节点K1,K2,K3与未知节点N之间的最小跳数值分别为(H1,H2,H3)。所有传感器节点的通信半径为R。我们构建了用3个锚节点为中心的3个正方形,分别以2RH1、2RH2、2RH3为3个正方形边长。如图1所示,初始种群是在可行域中随机生成的,未知节点N的坐标上界和下界可以定义如式(11)所示。
(11)
式中(xN,yN)为未知节点N的坐标。

图1 初始种群区

(12)
而后根据适应性函数进行逆转变异,设交叉搜索产生的种群中个体为Bn,其中Bn∈(Cn,Dn)。按式(13)进行变异产生下一代:
(13)
式中random(0,1)表示随机取0或者1。
Δ(t,α)=α[1-r(1-h/L)b]
(14)
式中:r为[0,1]范围内符合均匀概率分布的一个随机数;h为当下进化代数;L为最大进化代数;b为一个系统参数。
(15)
式中:α(α≥0)为一个移动路径的参数,取α=1;β(β≥0)为每只蚂蚁可见性的参数,取β=2;τij为在节点i,j连接t时刻残留的信息量;ηi,j为在i,j连接的可见性;allowedk={0,1}为下一个选择的状态。
M只蚂蚁开始遍历N个节点,在遍历的过程中按照式(15)更新所有路径的信息素τi,j。随着时间的流逝,留下的信息逐渐消失。N分钟后,蚂蚁完成一个循环,则:
τi,j(t+1)=ρ·τi,j(t)+Δτi,j
(16)
式中ρ(0≤ρ≤1)为一个移动路径的持久性,1-ρ表示的是信息损失程度。
Δτi,j=1/fbest(x,y)
(17)
式中fbest(x,y)为迭代最优解或者全部的最优解。
步骤5:按照如上从步骤3到步骤5迭代次数为300次时候则终止,则得到最优解此时F(x,y)最小。
3 仿真与实验结果
为了评估该算法的定位性能,实验仿真是在window10环境下,用MATLAB 9.1.0来实现。然后分析了它的性能,并与传统的DV-Hop算法、基于遗传算法的DV-Hop算法进行了比较。我们使用的每个未知节点的定位误差,是由式(18)来定义误差:
(18)
式中:(xest,yest)为未知节点的估算坐标;(xi,yi)为未知节点的确切坐标。
定义了平均定位误差如式(19)所示:
(19)
实验中仿真的参数如表1所示:
在进行实验的时候,固定区域为200 m×200 m的正方形区域,在这个区域内随机部署300个传感器节点,其中有240个未知节点、60个锚节点,通信距离R
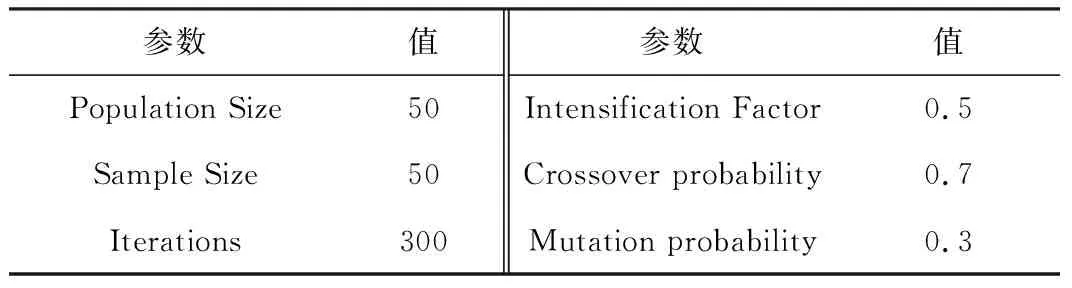
表1 仿真参数列表
为30 m,每个节点的通信半径是相等的。图2(a)是传统的DV-Hop算法的误差图,图中星号代表锚节点,实点代表未知节点的真实位置,圆圈代表未知节点的估计位置,线段代表未知节点估计位置和真实位置之间的误差。从图中可以看出传统的DV-Hop算法的定位误差总体来说比较大,还有一些点的定位与真实值之间的存在着很大的差距,图2(b)是利用本文提出的GABAC-DV-Hop算法定位,仿真结果的定位误差比图2(a)的定位误差总体上小了很多,而且不存在误差较大的点,因此可以看出本文提出的算法的定位比传统的DV-Hop算法的误差有很大的提高。

(a)传统的DV-Hop定位算法的误差

(b)GABAC-DV-Hop定位算法的误差图2 DV-HOP算法与GABAC-DV-Hop算法误差对比
图3是在200 m×200 m区域内随机部署节点,其中锚节点数为60个,每个节点的通信距离R为30 m,改变未知节点个数测定各算法平均定位误差。从图3可以得出GABAC-DV-Hop算法和GADV-Hop算法比传统的DV-Hop算法的精度高很多,平均误差大概是传统的DV-Hop算法的1/3~1/2,当未知节点较少的时候,GABAC-DV-Hop定位算法的准确性比GADV-Hop定位算法低,当未知节点较多的时候,GABAC-DV-Hop算法的精确度较好。可能的原因是当未知节点较少的时候,GABAC-DV-Hop定位算法中的二进制蚁群算法搜索对于结果有一定的干扰,所以其定位的精确度比GADV-Hop的精确度低。

图3 不同未知节点个数的各算法平均定位误差图
图4是在200 m×200 m区域内随机部署300个节点,每个节点的通信距离R为30 m,改变锚节点密度(即锚节点与节点总数的比例)测定各算法平均定位误差,从图4可以得出总体上GABAC-DV-Hop定位算法和GADV-Hop定位算法的精确度比传统的DV-Hop定位算法的精确度要高很多。但是随着锚节点的密度增加,GABAC-DV-Hop定位算法和GADV-Hop定位算法的平均误差先减小,而后增大,说明不是锚节点的密度越高,定位精确度就越高。对于GABAC-DV-Hop定位算法锚节点密度在0.2~0.5都是比较适合的,而从成本上看,锚节点个数一般要少,所以一般锚节点比例取25%。

图4 不同锚节点密度的各算法平均定位误差图
图5是在200 m×200 m区域内随机部署300个节点,其中锚节点个数为60,未知节点的个数为240,改变各个节点通信距离R,测定各算法平均定位误差。从图5可以得到,总体上来看GABAC-DV-Hop定位算法和GADV-Hop定位算法比传统的DV-Hop定位算法的平均定位误差小,随着通信距离R的增加,3种定位算法的平均定位误差都变大。并且GABAC-DV-Hop定位算法比GADV-Hop定位算法的平均定位误差更小,精确度更大。而从图5可知在通讯距离为30~40 m之间平均定位误差对于GABACDV-Hop定位算法影响不大,而一般考虑功率的因素,所以一般通讯距离取30 m。

图5 不同通信距离R的各算法平均定位误差图
从图2~图5中可以得到GABAC-DV-Hop定位算法比GADV-Hop定位算法和传统的DV-Hop定位算法有更好的定位精度,并且考虑算法精度和系统的功率来看,对于GABAC-DV-Hop定位算法一般取锚节点密度为25%,通信距离为30 m作为实际应用中的参数。
4 结论
无线传感器网络中的定位问题实际上是一个优化问题,其目标是最小化WSN定位问题的总估计误差。本文提出的GABACDV-Hop定位算法结合了遗传算法和二进制蚁群算法优势,不仅能够提高初始种群的质量,在迭代过程中后代的种群质量也能够相应提高,从而提高了算法的定位精度,而且应用二进制蚁群算法能更快地提高收敛性。仿真结果表明,GABAC-DV-Hop定位算法的定位效果优于GADV-Hop定位算法和传统的DV-Hop算法的定位效果,并且收敛速度也较快,是一种有较大应用价值的定位方法。
猜你喜欢
中等数学(2021年8期)2021-11-22
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
小学生导刊(2018年34期)2018-12-18
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
现代计算机(2016年34期)2016-02-28
山东青年(2016年3期)2016-02-28
火控雷达技术(2016年2期)2016-02-06
智能系统学报(2015年4期)2015-12-27
汽车科技(2015年1期)2015-02-28
